Imagen is Google's high-fidelity image generation model, capable of generating realistic and high quality images from text prompts. All generated images include a SynthID watermark. To learn more about the available Imagen model variants, see the Model versions section.
Migration to Nano Banana
Imagen models are deprecated and will shut down on August 17, 2026. We recommend migrating to Nano Banana for your image generation needs.
Migration involves the following changes:
- Model name: Use
gemini-2.5-flash-imageinstead of Imagen model names. - Method: Use
client.models.generate_contentinstead ofclient.models.generate_images. - Response handling: Nano Banana returns content parts, which may include image data, instead of a specific image response object.
See the Image generation guide for more details and examples.
Generate images using the Imagen models
This example demonstrates generating images with an Imagen model:
Python
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='Robot holding a red skateboard',
config=types.GenerateImagesConfig(
number_of_images= 4,
)
)
for generated_image in response.generated_images:
generated_image.image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateImages({
model: 'imagen-4.0-generate-001',
prompt: 'Robot holding a red skateboard',
config: {
numberOfImages: 4,
},
});
let idx = 1;
for (const generatedImage of response.generatedImages) {
let imgBytes = generatedImage.image.imageBytes;
const buffer = Buffer.from(imgBytes, "base64");
fs.writeFileSync(`imagen-${idx}.png`, buffer);
idx++;
}
}
main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateImagesConfig{
NumberOfImages: 4,
}
response, _ := client.Models.GenerateImages(
ctx,
"imagen-4.0-generate-001",
"Robot holding a red skateboard",
config,
)
for n, image := range response.GeneratedImages {
fname := fmt.Sprintf("imagen-%d.png", n)
_ = os.WriteFile(fname, image.Image.ImageBytes, 0644)
}
}
REST
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/imagen-4.0-generate-001:predict" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"prompt": "Robot holding a red skateboard"
}
],
"parameters": {
"sampleCount": 4
}
}'

Imagen configuration
Imagen supports English only prompts at this time and the following parameters:
numberOfImages: The number of images to generate, from 1 to 4 (inclusive). The default is 4.imageSize: The size of the generated image. This is only supported for the Standard and Ultra models. The supported values are1Kand2K. Default is1K.aspectRatio: Changes the aspect ratio of the generated image. Supported values are"1:1","3:4","4:3","9:16", and"16:9". The default is"1:1".personGeneration: Allow the model to generate images of people. The following values are supported:"dont_allow": Block generation of images of people."allow_adult": Generate images of adults, but not children. This is the default."allow_all": Generate images that include adults and children.
Imagen prompt guide
This section of the Imagen guide shows you how modifying a text-to-image prompt can produce different results, along with examples of images you can create.
Prompt writing basics
A good prompt is descriptive and clear, and makes use of meaningful keywords and modifiers. Start by thinking of your subject, context, and style.

Subject: The first thing to think about with any prompt is the subject: the object, person, animal, or scenery you want an image of.
Context and background: Just as important is the background or context in which the subject will be placed. Try placing your subject in a variety of backgrounds. For example, a studio with a white background, outdoors, or indoor environments.
Style: Finally, add the style of image you want. Styles can be general (painting, photograph, sketches) or very specific (pastel painting, charcoal drawing, isometric 3D). You can also combine styles.
After you write a first version of your prompt, refine your prompt by adding more details until you get to the image that you want. Iteration is important. Start by establishing your core idea, and then refine and expand upon that core idea until the generated image is close to your vision.

|

|

|
Imagen models can transform your ideas into detailed images, whether your prompts are short or long and detailed. Refine your vision through iterative prompting, adding details until you achieve the perfect result.
|
Short prompts let you generate an image quickly. 
|
Longer prompts let you add specific details and build your image. 
|
Additional advice for Imagen prompt writing:
- Use descriptive language: Employ detailed adjectives and adverbs to paint a clear picture for Imagen.
- Provide context: If necessary, include background information to aid the AI's understanding.
- Reference specific artists or styles: If you have a particular aesthetic in mind, referencing specific artists or art movements can be helpful.
- Use prompt engineering tools: Consider exploring prompt engineering tools or resources to help you refine your prompts and achieve optimal results.
- Enhancing the facial details in your personal and group images: Specify facial details as a focus of the photo (for example, use the word "portrait" in the prompt).
Generate text in images
Imagen models can add text into images, opening up more creative image generation possibilities. Use the following guidance to get the most out of this feature:
- Iterate with confidence: You might have to regenerate images until you achieve the look you want. Imagen's text integration is still evolving, and sometimes multiple attempts yield the best results.
- Keep it short: Limit text to 25 characters or less for optimal generation.
Multiple phrases: Experiment with two or three distinct phrases to provide additional information. Avoid exceeding three phrases for cleaner compositions.

Prompt: A poster with the text "Summerland" in bold font as a title, underneath this text is the slogan "Summer never felt so good" Guide Placement: While Imagen can attempt to position text as directed, expect occasional variations. This feature is continually improving.
Inspire font style: Specify a general font style to subtly influence Imagen's choices. Don't rely on precise font replication, but expect creative interpretations.
Font size: Specify a font size or a general indication of size (for example, small, medium, large) to influence the font size generation.
Prompt parameterization
To better control output results, you might find it helpful to parameterize the inputs into Imagen. For example, suppose you want your customers to be able to generate logos for their business, and you want to make sure logos are always generated on a solid color background. You also want to limit the options that the client can select from a menu.
In this example, you can create a parameterized prompt similar to the following:
A {logo_style} logo for a {company_area} company on a solid color background. Include the text {company_name}.In your custom user interface, the customer can input the parameters using a menu, and their chosen value populates the prompt Imagen receives.
For example:
Prompt:
A minimalist logo for a health care company on a solid color background. Include the text Journey.
Prompt:
A modern logo for a software company on a solid color background. Include the text Silo.
Prompt:
A traditional logo for a baking company on a solid color background. Include the text Seed.
Advanced prompt writing techniques
Use the following examples to create more specific prompts based on attributes like photography descriptors, shapes and materials, historical art movements, and image quality modifiers.
Photography
- Prompt includes: "A photo of..."
To use this style, start with using keywords that clearly tell Imagen that you're looking for a photograph. Start your prompts with "A photo of. . .". For example:

|

|

|
Image source: Each image was generated using its corresponding text prompt with the Imagen 4 model.
Photography modifiers
In the following examples, you can see several photography-specific modifiers and parameters. You can combine multiple modifiers for more precise control.
Camera Proximity - Close up, taken from far away

Prompt: A close-up photo of coffee beans 
Prompt: A zoomed out photo of a small bag of
coffee beans in a messy kitchenCamera Position - aerial, from below

Prompt: aerial photo of urban city with skyscrapers 
Prompt: A photo of a forest canopy with blue skies from below Lighting - natural, dramatic, warm, cold

Prompt: studio photo of a modern arm chair, natural lighting 
Prompt: studio photo of a modern arm chair, dramatic lighting Camera Settings - motion blur, soft focus, bokeh, portrait

Prompt: photo of a city with skyscrapers from the inside of a car with motion blur 
Prompt: soft focus photograph of a bridge in an urban city at night Lens types - 35mm, 50mm, fisheye, wide angle, macro

Prompt: photo of a leaf, macro lens 
Prompt: street photography, new york city, fisheye lens Film types - black and white, polaroid

Prompt: a polaroid portrait of a dog wearing sunglasses 
Prompt: black and white photo of a dog wearing sunglasses
Image source: Each image was generated using its corresponding text prompt with the Imagen 4 model.
Illustration and art
- Prompt includes: "A painting of...", "A sketch of..."
Art styles vary from monochrome styles like pencil sketches, to hyper-realistic digital art. For example, the following images use the same prompt with different styles:
"An [art style or creation technique] of an angular sporty electric sedan with skyscrapers in the background"

|

|

|

|

|

|
Image source: Each image was generated using its corresponding text prompt with the Imagen 2 model.
Shapes and materials
- Prompt includes: "...made of...", "...in the shape of..."
One of the strengths of this technology is that you can create imagery that is otherwise difficult or impossible. For example, you can recreate your company logo in different materials and textures.

|

|

|
Image source: Each image was generated using its corresponding text prompt with the Imagen 4 model.
Historical art references
- Prompt includes: "...in the style of..."
Certain styles have become iconic over the years. The following are some ideas of historical painting or art styles that you can try.
"generate an image in the style of [art period or movement] : a wind farm"

|

|

|
Image source: Each image was generated using its corresponding text prompt with the Imagen 4 model.
Image quality modifiers
Certain keywords can let the model know that you're looking for a high-quality asset. Examples of quality modifiers include the following:
- General Modifiers - high-quality, beautiful, stylized
- Photos - 4K, HDR, Studio Photo
- Art, Illustration - by a professional, detailed
The following are a few examples of prompts without quality modifiers and the same prompt with quality modifiers.

|

photo of a corn stalk taken by a professional photographer |
Image source: Each image was generated using its corresponding text prompt with the Imagen 4 model.
Aspect ratios
Imagen image generation lets you set five distinct image aspect ratios.
- Square (1:1, default) - A standard square photo. Common uses for this aspect ratio include social media posts.
Fullscreen (4:3) - This aspect ratio is commonly used in media or film. It is also the dimensions of most old (non-widescreen) TVs and medium format cameras. It captures more of the scene horizontally (compared to 1:1), making it a preferred aspect ratio for photography.

Prompt: close up of a musician's fingers playing the piano, black and white film, vintage (4:3 aspect ratio) 
Prompt: A professional studio photo of french fries for a high end restaurant, in the style of a food magazine (4:3 aspect ratio) Portrait full screen (3:4) - This is the fullscreen aspect ratio rotated 90 degrees. This lets to capture more of the scene vertically compared to the 1:1 aspect ratio.

Prompt: a woman hiking, close of her boots reflected in a puddle, large mountains in the background, in the style of an advertisement, dramatic angles (3:4 aspect ratio) 
Prompt: aerial shot of a river flowing up a mystical valley (3:4 aspect ratio) Widescreen (16:9) - This ratio has replaced 4:3 and is now the most common aspect ratio for TVs, monitors, and mobile phone screens (landscape). Use this aspect ratio when you want to capture more of the background (for example, scenic landscapes).

Prompt: a man wearing all white clothing sitting on the beach, close up, golden hour lighting (16:9 aspect ratio) Portrait (9:16) - This ratio is widescreen but rotated. This a relatively new aspect ratio that has been popularized by short form video apps (for example, YouTube shorts). Use this for tall objects with strong vertical orientations such as buildings, trees, waterfalls, or other similar objects.

Prompt: a digital render of a massive skyscraper, modern, grand, epic with a beautiful sunset in the background (9:16 aspect ratio)
Photorealistic images
Different versions of the image generation model might offer a mix of artistic and photorealistic output. Use the following wording in prompts to generate more photorealistic output, based on the subject you want to generate.
| Use case | Lens type | Focal lengths | Additional details |
|---|---|---|---|
| People (portraits) | Prime, zoom | 24-35mm | black and white film, Film noir, Depth of field, duotone (mention two colors) |
| Food, insects, plants (objects, still life) | Macro | 60-105mm | High detail, precise focusing, controlled lighting |
| Sports, wildlife (motion) | Telephoto zoom | 100-400mm | Fast shutter speed, Action or movement tracking |
| Astronomical, landscape (wide-angle) | Wide-angle | 10-24mm | Long exposure times, sharp focus, long exposure, smooth water or clouds |
Portraits
| Use case | Lens type | Focal lengths | Additional details |
|---|---|---|---|
| People (portraits) | Prime, zoom | 24-35mm | black and white film, Film noir, Depth of field, duotone (mention two colors) |
Using several keywords from the table, Imagen can generate the following portraits:

|

|

|

|
Prompt: A woman, 35mm portrait, blue and grey duotones
Model: imagen-4.0-generate-001

|

|

|

|
Prompt: A woman, 35mm portrait, film noir
Model: imagen-4.0-generate-001
Objects
| Use case | Lens type | Focal lengths | Additional details |
|---|---|---|---|
| Food, insects, plants (objects, still life) | Macro | 60-105mm | High detail, precise focusing, controlled lighting |
Using several keywords from the table, Imagen can generate the following object images:

|

|

|

|
Prompt: leaf of a prayer plant, macro lens, 60mm
Model: imagen-4.0-generate-001

|

|

|

|
Prompt: a plate of pasta, 100mm Macro lens
Model: imagen-4.0-generate-001
Motion
| Use case | Lens type | Focal lengths | Additional details |
|---|---|---|---|
| Sports, wildlife (motion) | Telephoto zoom | 100-400mm | Fast shutter speed, Action or movement tracking |
Using several keywords from the table, Imagen can generate the following motion images:

|

|
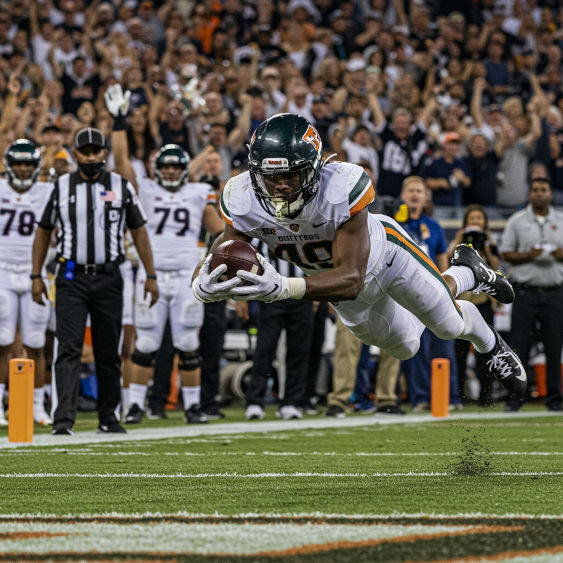
|

|
Prompt: a winning touchdown, fast shutter speed, movement tracking
Model: imagen-4.0-generate-001

|

|

|

|
Prompt: A deer running in the forest, fast shutter speed, movement tracking
Model: imagen-4.0-generate-001
Wide-angle
| Use case | Lens type | Focal lengths | Additional details |
|---|---|---|---|
| Astronomical, landscape (wide-angle) | Wide-angle | 10-24mm | Long exposure times, sharp focus, long exposure, smooth water or clouds |
Using several keywords from the table, Imagen can generate the following wide-angle images:

|

|

|

|
Prompt: an expansive mountain range, landscape wide angle 10mm
Model: imagen-4.0-generate-001

|

|

|

|
Prompt: a photo of the moon, astro photography, wide angle 10mm
Model: imagen-4.0-generate-001
Model versions
Imagen 4 (Deprecated)
| Property | Description |
|---|---|
| Model code |
Gemini API
|
| Supported data types |
Input Text Output Images |
| Token limits[*] |
Input token limit 480 tokens (text) Output images 1 to 4 (Ultra/Standard/Fast) |
| Latest update | June 2025 |
Imagen 3
The Imagen 3 model has been shut down.