
Metadata LiteRT menyediakan standar untuk deskripsi model. Metadata adalah sumber pengetahuan penting tentang apa yang dilakukan model dan informasi input / outputnya. Metadata terdiri dari
- bagian yang dapat dibaca manusia yang menyampaikan praktik terbaik saat menggunakan model, dan
- bagian yang dapat dibaca mesin yang dapat dimanfaatkan oleh generator kode, seperti generator kode Android LiteRT dan fitur Binding ML Android Studio.
Semua model gambar yang dipublikasikan di Kaggle Models telah diisi dengan metadata.
Model dengan format metadata
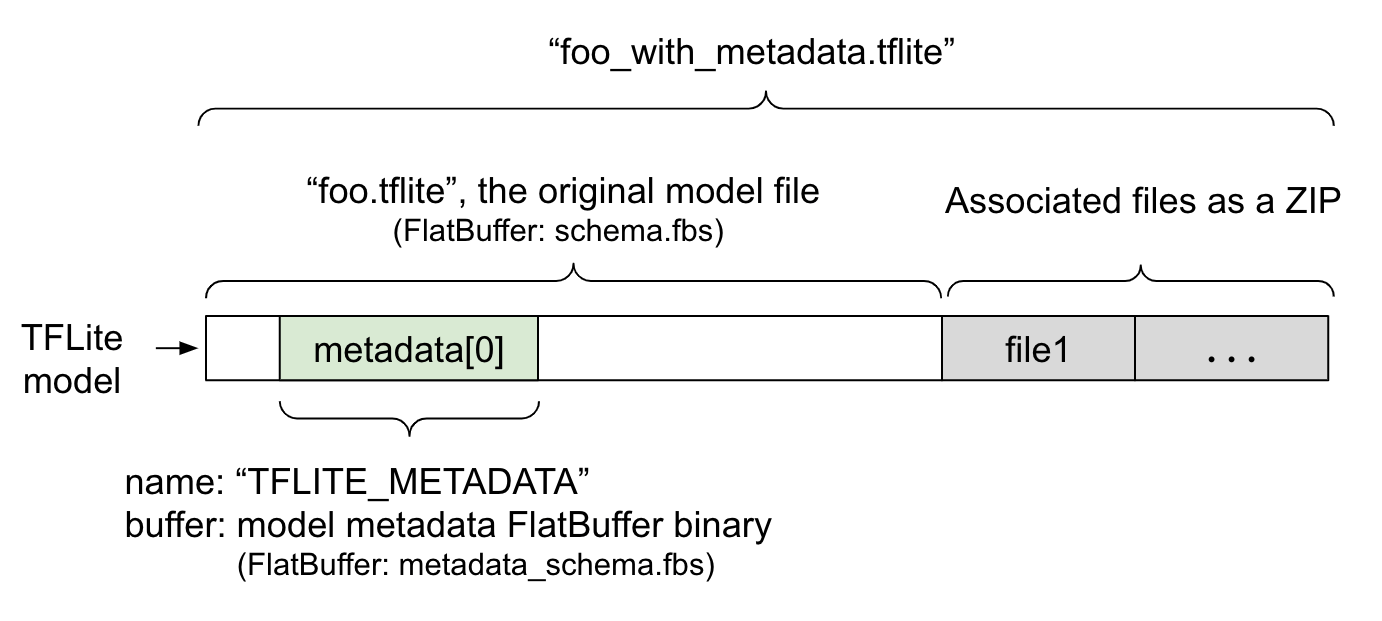
Metadata model ditentukan dalam
metadata_schema.fbs,
file
FlatBuffer. Seperti yang ditunjukkan pada Gambar 1, file ini disimpan di kolom
metadata
dari skema model TFLite,
dengan nama, "TFLITE_METADATA". Beberapa model mungkin dilengkapi dengan file terkait, seperti file label klasifikasi.
File ini digabungkan ke akhir file model asli sebagai ZIP menggunakan mode "append"
ZipFile (mode 'a'). Interpreter
TFLite dapat menggunakan format file baru dengan cara yang sama seperti sebelumnya. Lihat Mengemas
file terkait untuk mengetahui informasi selengkapnya.
Lihat petunjuk di bawah tentang cara mengisi, memvisualisasikan, dan membaca metadata.
Menyiapkan alat metadata
Sebelum menambahkan metadata ke model, Anda harus menyiapkan lingkungan pemrograman Python untuk menjalankan TensorFlow. Ada panduan mendetail tentang cara menyiapkannya di sini.
Setelah menyiapkan lingkungan pemrograman Python, Anda harus menginstal alat tambahan:
pip install tflite-support
Alat metadata LiteRT mendukung Python 3.
Menambahkan metadata menggunakan Flatbuffers Python API
Ada tiga bagian metadata model dalam skema:
- Informasi model - Deskripsi keseluruhan model serta item seperti persyaratan lisensi. Lihat ModelMetadata. 2. Informasi input - Deskripsi input dan pra-pemrosesan yang diperlukan seperti normalisasi. Lihat SubGraphMetadata.input_tensor_metadata. 3. Informasi output - Deskripsi output dan pasca-pemrosesan yang diperlukan seperti pemetaan ke label. Lihat SubGraphMetadata.output_tensor_metadata.
Karena LiteRT hanya mendukung satu subgraf untuk saat ini, generator kode LiteRT dan fitur Binding ML Android Studio akan menggunakan ModelMetadata.name dan ModelMetadata.description, bukan SubGraphMetadata.name dan SubGraphMetadata.description, saat menampilkan metadata dan membuat kode.
Jenis Input / Output yang didukung
Metadata LiteRT untuk input dan output tidak dirancang dengan mempertimbangkan jenis model tertentu, tetapi jenis input dan output. Tidak masalah apa yang dilakukan model secara fungsional, selama jenis input dan output terdiri dari berikut ini atau kombinasi dari berikut ini, model tersebut didukung oleh metadata TensorFlow Lite:
- Fitur - Angka yang merupakan bilangan bulat tanpa tanda atau float32.
- Gambar - Metadata saat ini mendukung gambar RGB dan skala abu-abu.
- Kotak pembatas - Kotak pembatas berbentuk persegi panjang. Skema ini mendukung berbagai skema penomoran.
Mengemas file terkait
Model LiteRT mungkin dilengkapi dengan file terkait yang berbeda. Misalnya, model bahasa alami biasanya memiliki file kosakata yang memetakan potongan kata ke ID kata; model klasifikasi mungkin memiliki file label yang menunjukkan kategori objek. Tanpa file terkait (jika ada), model tidak akan berfungsi dengan baik.
File terkait kini dapat dibundel dengan model melalui library Python metadata. Model LiteRT baru menjadi file zip yang berisi model dan file terkait. File ini dapat diekstrak dengan alat zip umum. Format model baru ini tetap menggunakan ekstensi file yang sama, .tflite. API ini kompatibel dengan framework dan Interpreter TFLite yang ada. Lihat Mengemas metadata dan file terkait ke dalam model untuk mengetahui detail selengkapnya.
Informasi file terkait dapat direkam dalam metadata. Bergantung pada
jenis file dan tempat file dilampirkan (yaitu ModelMetadata,
SubGraphMetadata, dan TensorMetadata), generator kode Android LiteRT
dapat menerapkan pra/pasca-pemrosesan yang sesuai
secara otomatis ke objek. Lihat bagian <Penggunaan codegen> dari
setiap jenis file terkait
dalam skema untuk mengetahui detail selengkapnya.
Parameter normalisasi dan kuantisasi
Normalisasi adalah teknik praproses data umum dalam machine learning. Tujuan normalisasi adalah mengubah nilai ke skala umum, tanpa mendistorsi perbedaan dalam rentang nilai.
Kuantisasi model adalah teknik yang memungkinkan representasi bobot dengan presisi yang lebih rendah dan secara opsional, aktivasi untuk penyimpanan dan komputasi.
Dari segi pra-pemrosesan dan pasca-pemrosesan, normalisasi dan kuantisasi adalah dua langkah independen. Berikut detailnya.
| Normalisasi | Kuantisasi | |
|---|---|---|
Contoh nilai parameter gambar input di MobileNet untuk model float dan quant, masing-masing. |
Model float: - mean: 127,5 - std: 127,5 Model kuantisasi: - mean: 127,5 - std: 127,5 |
Model float: - zeroPoint: 0 - scale: 1.0 Model kuantisasi: - zeroPoint: 128.0 - scale:0.0078125f |
Kapan harus memanggil? |
Input: Jika data input dinormalisasi dalam pelatihan, data input inferensi harus dinormalisasi dengan tepat. Output: data output umumnya tidak dinormalisasi. |
Model float tidak memerlukan kuantisasi. Model terkuantisasi mungkin atau tidak memerlukan kuantisasi dalam pra/pasca pemrosesan. Hal ini bergantung pada jenis data tensor input/output. - tensor float: tidak perlu kuantisasi dalam pra/pasca pemrosesan. Operasi kuantisasi dan dekuantisasi disematkan ke dalam grafik model. - tensor int8/uint8: memerlukan kuantisasi dalam pra/pasca-pemrosesan. |
Formula |
normalized_input = (input - mean) / std |
Kuantisasi untuk input:
q = f / scale + zeroPoint Dequantisasi untuk output: f = (q - zeroPoint) * scale |
Tempat parameter berada |
Diisi oleh pembuat model dan disimpan dalam metadata model, sebagai NormalizationOptions |
Diisi secara otomatis oleh konverter TFLite, dan disimpan dalam file model tflite. |
| Bagaimana cara mendapatkan parameter? | Melalui
MetadataExtractor API
[2]
|
Melalui TFLite
Tensor API [1] atau
melalui
MetadataExtractor API
[2] |
| Apakah model float dan quant memiliki nilai yang sama? | Ya, model float dan quant memiliki parameter Normalisasi yang sama | Tidak, model float tidak memerlukan kuantisasi. |
| Apakah Pembuat Kode TFLite atau binding ML Android Studio secara otomatis membuatnya dalam pemrosesan data? | Ya |
Ya |
[1] LiteRT Java
API
dan LiteRT C++
API.
[2] Pustaka ekstraktor metadata
Saat memproses data gambar untuk model uint8, normalisasi dan kuantisasi terkadang dilewati. Anda dapat melakukannya jika nilai piksel berada dalam rentang [0, 255]. Namun secara umum, Anda harus selalu memproses data sesuai dengan parameter normalisasi dan kuantisasi jika berlaku.
Contoh
Anda dapat menemukan contoh cara mengisi metadata untuk berbagai jenis model di sini:
Klasifikasi gambar
Download skrip di sini , yang mengisi metadata ke mobilenet_v1_0.75_160_quantized.tflite. Jalankan skrip seperti ini:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
Untuk mengisi metadata model klasifikasi gambar lainnya, tambahkan spesifikasi model seperti ini ke dalam skrip. Bagian selanjutnya dalam panduan ini akan menyoroti beberapa bagian penting dalam contoh klasifikasi gambar untuk mengilustrasikan elemen-elemen penting.
Mempelajari contoh klasifikasi gambar secara mendalam
Informasi model
Metadata dimulai dengan membuat info model baru:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
Informasi input / output
Bagian ini menunjukkan cara mendeskripsikan tanda tangan input dan output model Anda. Metadata ini dapat digunakan oleh generator kode otomatis untuk membuat kode pra- dan pasca- pemrosesan. Untuk membuat informasi input atau output tentang tensor:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
Input gambar
Gambar adalah jenis input umum untuk machine learning. Metadata LiteRT mendukung informasi seperti ruang warna dan informasi pra-pemrosesan seperti normalisasi. Dimensi gambar tidak memerlukan spesifikasi manual karena sudah disediakan oleh bentuk tensor input dan dapat disimpulkan secara otomatis.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
Output label
Label dapat dipetakan ke tensor output melalui file terkait menggunakan
TENSOR_AXIS_LABELS.
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
Buat Flatbuffers metadata
Kode berikut menggabungkan informasi model dengan informasi input dan output:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
Mengemas metadata dan file terkait ke dalam model
Setelah Flatbuffers metadata dibuat, metadata dan file label akan ditulis ke dalam file TFLite melalui metode populate:
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
Anda dapat mengemas sebanyak mungkin file terkait ke dalam model melalui
load_associated_files. Namun, Anda harus mengemas setidaknya file yang didokumentasikan dalam metadata. Dalam contoh ini, pengemasan file label
wajib dilakukan.
Memvisualisasikan metadata
Anda dapat menggunakan Netron untuk memvisualisasikan metadata, atau Anda dapat membaca metadata dari model LiteRT ke dalam format json menggunakan MetadataDisplayer:
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio juga mendukung menampilkan metadata melalui fitur Binding ML Android Studio.
Pembuatan versi metadata
Skema metadata diberi versi berdasarkan nomor Semantic versioning, yang melacak perubahan file skema, dan berdasarkan identifikasi file Flatbuffers, yang menunjukkan kompatibilitas versi yang sebenarnya.
Nomor pembuatan versi semantik
Skema metadata diberi versi berdasarkan Nomor versi semantik,
seperti MAJOR.MINOR.PATCH. Fitur ini melacak perubahan skema sesuai dengan aturan
di sini.
Lihat histori kolom yang ditambahkan setelah versi 1.0.0.
Identifikasi file Flatbuffers
Versi semantik menjamin kompatibilitas jika mengikuti aturan, tetapi tidak menyiratkan ketidakcocokan yang sebenarnya. Saat menaikkan angka MAJOR, hal ini tidak berarti kompatibilitas mundur terganggu. Oleh karena itu, kami menggunakan identifikasi file Flatbuffers, file_identifier, untuk menunjukkan kompatibilitas sebenarnya dari skema metadata. ID file panjangnya tepat 4 karakter. Objek ini ditetapkan ke skema metadata tertentu dan tidak dapat diubah oleh pengguna. Jika kompatibilitas mundur skema metadata harus dihentikan karena alasan tertentu, file_identifier akan bertambah, misalnya, dari “M001” menjadi “M002”. File_identifier diharapkan berubah jauh lebih jarang daripada metadata_version.
Versi parser metadata minimum yang diperlukan
Versi parser metadata yang diperlukan minimum
adalah versi minimum parser metadata (kode yang dihasilkan Flatbuffers) yang
dapat membaca Flatbuffers metadata secara penuh. Versi ini secara efektif merupakan
nomor versi terbesar di antara versi semua kolom yang diisi dan
versi kompatibel terkecil yang ditunjukkan oleh ID file. Versi parser metadata minimum yang diperlukan akan otomatis diisi oleh
MetadataPopulator saat metadata diisi ke dalam model TFLite. Lihat
pengekstrak metadata untuk mengetahui informasi selengkapnya tentang cara
penggunaan versi parser metadata yang diperlukan minimum.
Membaca metadata dari model
Library Metadata Extractor adalah alat praktis untuk membaca metadata dan file terkait dari model di berbagai platform (lihat versi Java dan versi C++). Anda dapat membuat alat ekstraktor metadata sendiri dalam bahasa lain menggunakan library Flatbuffers.
Membaca metadata di Java
Untuk menggunakan library Ekstraktor Metadata di aplikasi Android Anda, sebaiknya gunakan
AAR Metadata LiteRT yang dihosting di
MavenCentral.
Library ini berisi class MetadataExtractor, serta binding Java FlatBuffers untuk skema metadata dan skema model.
Anda dapat menentukannya dalam dependensi build.gradle sebagai berikut:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
Untuk menggunakan snapshot malam, pastikan Anda telah menambahkan repositori snapshot Sonatype.
Anda dapat melakukan inisialisasi objek MetadataExtractor dengan ByteBuffer yang mengarah ke model:
public MetadataExtractor(ByteBuffer buffer);
ByteBuffer harus tetap tidak berubah selama masa aktif objek
MetadataExtractor. Inisialisasi dapat gagal jika ID file Flatbuffers metadata model tidak cocok dengan ID parser metadata. Lihat
pembuatan versi metadata untuk mengetahui informasi selengkapnya.
Dengan mencocokkan ID file, ekstraktor metadata akan berhasil membaca metadata yang dihasilkan dari semua skema lama dan mendatang karena mekanisme kompatibilitas maju dan mundur Flatbuffers. Namun, kolom dari skema mendatang tidak dapat diekstrak oleh ekstraktor metadata yang lebih lama. Versi parser yang diperlukan minimum metadata menunjukkan versi minimum parser metadata yang dapat membaca Flatbuffers metadata secara penuh. Anda dapat menggunakan metode berikut untuk memverifikasi apakah kondisi versi parser minimum yang diperlukan terpenuhi:
public final boolean isMinimumParserVersionSatisfied();
Model yang diteruskan tanpa metadata diizinkan. Namun, memanggil metode yang
membaca dari metadata akan menyebabkan error runtime. Anda dapat memeriksa apakah model memiliki metadata dengan memanggil metode hasMetadata:
public boolean hasMetadata();
MetadataExtractor menyediakan fungsi praktis bagi Anda untuk mendapatkan metadata tensor input/output. Misalnya,
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
Meskipun skema model LiteRT
mendukung beberapa subgrafik, TFLite Interpreter saat ini hanya mendukung satu subgrafik. Oleh karena itu, MetadataExtractor menghilangkan indeks subgraf sebagai argumen
input dalam metodenya.
Membaca file terkait dari model
Model LiteRT dengan metadata dan file terkait pada dasarnya adalah file zip yang dapat diekstrak dengan alat zip umum untuk mendapatkan file terkait. Misalnya, Anda dapat mengekstrak mobilenet_v1_0.75_160_quantized dan mengekstrak file label dalam model sebagai berikut:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
Anda juga dapat membaca file terkait melalui library Metadata Extractor.
Di Java, teruskan nama file ke metode MetadataExtractor.getAssociatedFile:
public InputStream getAssociatedFile(String fileName);
Demikian pula, di C++, hal ini dapat dilakukan dengan metode,
ModelMetadataExtractor::GetAssociatedFile:
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;