
I dispositivi periferici spesso hanno una memoria o una potenza di calcolo limitate. È possibile applicare varie ottimizzazioni ai modelli in modo che possano essere eseguiti entro questi vincoli. Inoltre, alcune ottimizzazioni consentono l'utilizzo di hardware specializzato per l'inferenza accelerata.
LiteRT e il toolkit TensorFlow Model Optimization forniscono strumenti per ridurre al minimo la complessità dell'ottimizzazione dell'inferenza.
Ti consigliamo di prendere in considerazione l'ottimizzazione del modello durante il processo di sviluppo dell'applicazione. Questo documento descrive alcune best practice per l'ottimizzazione dei modelli TensorFlow per il deployment su hardware edge.
Perché i modelli devono essere ottimizzati
L'ottimizzazione del modello può contribuire allo sviluppo di applicazioni in diversi modi.
Riduzione delle dimensioni
Alcune forme di ottimizzazione possono essere utilizzate per ridurre le dimensioni di un modello. I modelli più piccoli presentano i seguenti vantaggi:
- Dimensioni di archiviazione più ridotte:i modelli più piccoli occupano meno spazio di archiviazione sui dispositivi degli utenti. Ad esempio, un'app per Android che utilizza un modello più piccolo occuperà meno spazio di archiviazione sul dispositivo mobile di un utente.
- Dimensioni di download inferiori:i modelli più piccoli richiedono meno tempo e larghezza di banda per il download sui dispositivi degli utenti.
- Minore utilizzo di memoria:i modelli più piccoli utilizzano meno RAM quando vengono eseguiti, il che libera memoria per altre parti dell'applicazione e può tradursi in prestazioni e stabilità migliori.
La quantizzazione può ridurre le dimensioni di un modello in tutti questi casi, potenzialmente a scapito di una certa precisione. Il pruning e il clustering possono ridurre le dimensioni di un modello per il download rendendolo più facilmente comprimibile.
Riduzione della latenza
La latenza è il tempo necessario per eseguire una singola inferenza con un determinato modello. Alcune forme di ottimizzazione possono ridurre la quantità di calcoli necessari per eseguire l'inferenza utilizzando un modello, con conseguente riduzione della latenza. La latenza può anche influire sul consumo energetico.
Attualmente, la quantizzazione può essere utilizzata per ridurre la latenza semplificando i calcoli che si verificano durante l'inferenza, potenzialmente a scapito di una certa precisione.
Compatibilità degli acceleratori
Alcuni acceleratori hardware, come la Edge TPU, possono eseguire l'inferenza in modo estremamente rapido con modelli ottimizzati correttamente.
In genere, questi tipi di dispositivi richiedono che i modelli vengano quantizzati in un modo specifico. Per saperne di più sui requisiti di ciascun acceleratore hardware, consulta la relativa documentazione.
Compromessi
Le ottimizzazioni possono potenzialmente comportare modifiche alla precisione del modello, che devono essere prese in considerazione durante il processo di sviluppo dell'applicazione.
Le modifiche all'accuratezza dipendono dal modello specifico che viene ottimizzato ed è difficile prevederle in anticipo. In genere, i modelli ottimizzati per le dimensioni o la latenza perdono una piccola quantità di precisione. A seconda della tua applicazione, questa operazione potrebbe influire o meno sull'esperienza dei tuoi utenti. In rari casi, alcuni modelli potrebbero guadagnare un po' di precisione a seguito del processo di ottimizzazione.
Tipi di ottimizzazione
Al momento LiteRT supporta l'ottimizzazione tramite quantizzazione, potatura e clustering.
Questi fanno parte del toolkit TensorFlow Model Optimization, che fornisce risorse per tecniche di ottimizzazione dei modelli compatibili con TensorFlow Lite.
Quantizzazione
La quantizzazione riduce la precisione dei numeri utilizzati per rappresentare i parametri di un modello, che per impostazione predefinita sono numeri in virgola mobile a 32 bit. In questo modo le dimensioni del modello sono inferiori e il calcolo è più rapido.
In LiteRT sono disponibili i seguenti tipi di quantizzazione:
| Tecnica | Requisiti dei dati | Riduzione delle dimensioni | Precisione | Hardware supportato |
|---|---|---|---|---|
| Quantizzazione post-training float16 | Nessun dato | Fino al 50% | Perdita di precisione non significativa | CPU, GPU |
| Quantizzazione dinamica dell'intervallo post-addestramento | Nessun dato | Fino al 75% | Perdita di precisione minima | CPU, GPU (Android) |
| Quantizzazione degli interi post-addestramento | Campione rappresentativo senza etichetta | Fino al 75% | Piccola perdita di precisione | CPU, GPU (Android), EdgeTPU |
| Addestramento consapevole della quantizzazione | Dati di addestramento etichettati | Fino al 75% | Perdita di precisione minima | CPU, GPU (Android), EdgeTPU |
Il seguente albero decisionale ti aiuta a selezionare gli schemi di quantizzazione che potresti voler utilizzare per il tuo modello, in base alle dimensioni e all'accuratezza previste.
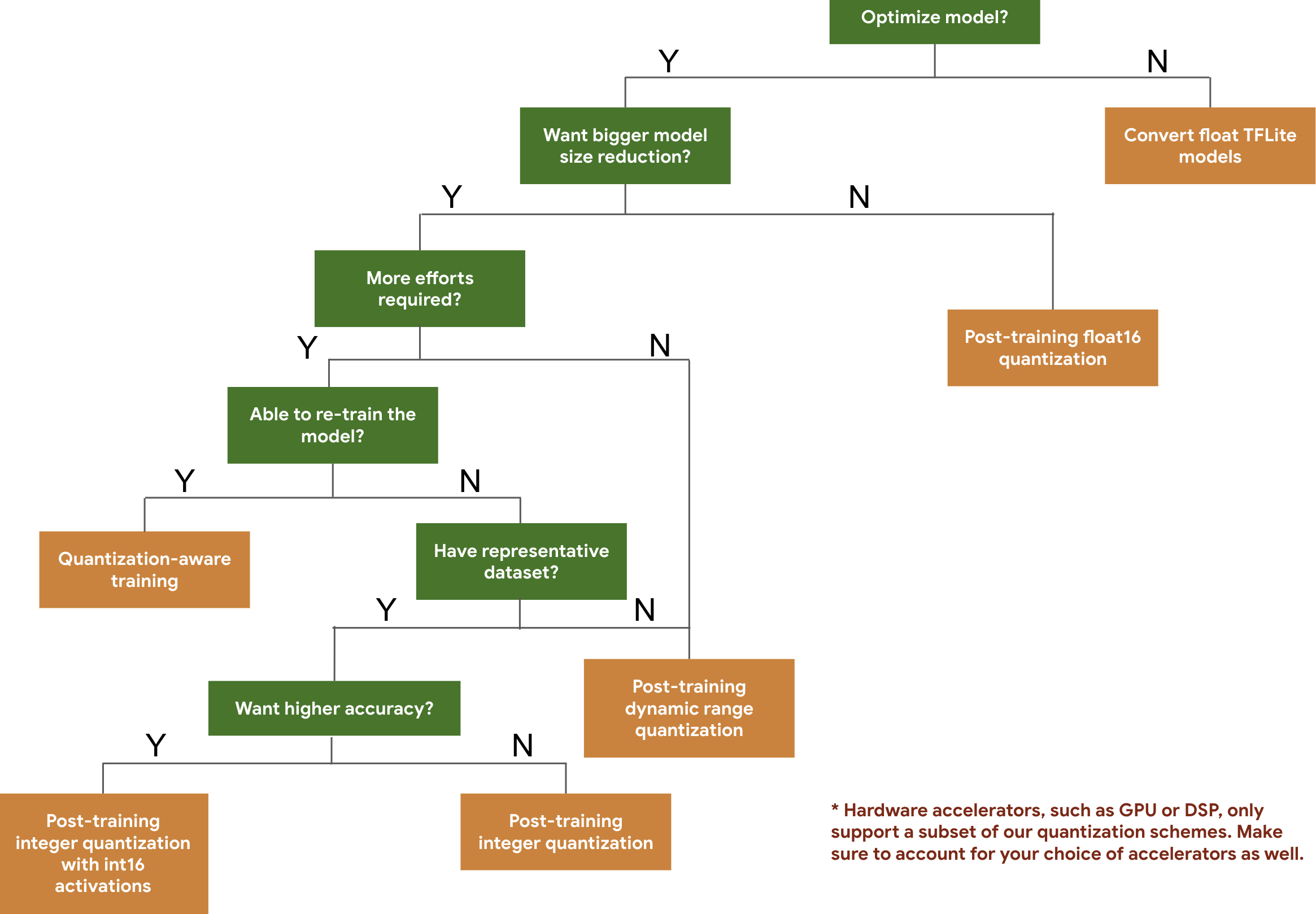
Di seguito sono riportati i risultati di latenza e accuratezza per la quantizzazione post-addestramento e l'addestramento consapevole della quantizzazione su alcuni modelli. Tutti i numeri di latenza vengono misurati su dispositivi Pixel 2 che utilizzano una singola CPU big core. Man mano che il toolkit migliora, aumenteranno anche i numeri qui:
| Modello | Accuratezza Top-1 (originale) | Accuratezza Top-1 (quantizzazione post-addestramento) | Accuratezza Top-1 (addestramento consapevole della quantizzazione) | Latenza (originale) (ms) | Latenza (quantizzazione post-addestramento) (ms) | Latenza (addestramento con riconoscimento della quantizzazione) (ms) | Dimensioni (originale) (MB) | Dimensione (ottimizzata) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0,709 | 0,657 | 0,70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0,719 | 0,637 | 0,709 | 89 | 98 | 54 | 14 | 3,6 |
| Inception_v3 | 0,78 | 0,772 | 0,775 | 1130 | 845 | 543 | 95,7 | 23.9 |
| Resnet_v2_101 | 0,770 | 0,768 | N/D | 3973 | 2868 | N/D | 178,3 | 44,9 |
Quantizzazione di interi completa con attivazioni int16 e pesi int8
La quantizzazione con attivazioni int16 è uno schema di quantizzazione intero completo con attivazioni in int16 e pesi in int8. Questa modalità può migliorare l'accuratezza del modello quantizzato rispetto allo schema di quantizzazione degli interi completo con attivazioni e pesi in int8 mantenendo dimensioni del modello simili. È consigliato quando le attivazioni sono sensibili alla quantizzazione.
NOTA:al momento in TFLite sono disponibili solo implementazioni del kernel di riferimento non ottimizzate per questo schema di quantizzazione, pertanto per impostazione predefinita il rendimento sarà lento rispetto ai kernel int8. I vantaggi completi di questa modalità possono essere attualmente accessibili tramite hardware specializzato o software personalizzato.
Di seguito sono riportati i risultati di accuratezza per alcuni modelli che traggono vantaggio da questa modalità.
| Modello | Tipo di metrica Accuratezza | Precisione (attivazioni float32) | Precisione (attivazioni int8) | Precisione (attivazioni int16) |
|---|---|---|---|---|
| Wav2letter | WER | 6,7% | 7,7% | 7,2% |
| DeepSpeech 0.5.1 (unrolled) | CER | 6,13% | 43,67% | 6,52% |
| YoloV3 | mAP(IOU=0,5) | 0,577 | 0,563 | 0,574 |
| MobileNetV1 | Accuratezza top-1 | 0.7062 | 0,694 | 0,6936 |
| MobileNetV2 | Accuratezza top-1 | 0,718 | 0,7126 | 0,7137 |
| MobileBert | F1(corrispondenza esatta) | 88,81(81,23) | 2,08(0) | 88,73(81,15) |
Potatura
La potatura funziona rimuovendo i parametri all'interno di un modello che hanno un impatto minimo sulle sue previsioni. I modelli sottoposti a pruning hanno le stesse dimensioni su disco e la stessa latenza di runtime, ma possono essere compressi in modo più efficace. Ciò rende il pruning una tecnica utile per ridurre le dimensioni di download del modello.
In futuro, LiteRT fornirà una riduzione della latenza per i modelli potati.
Clustering
Il clustering funziona raggruppando i pesi di ogni livello di un modello in un numero predefinito di cluster, quindi condividendo i valori del centroide per i pesi appartenenti a ciascun cluster individuale. In questo modo si riduce il numero di valori di peso unici in un modello, riducendone così la complessità.
Di conseguenza, i modelli in cluster possono essere compressi in modo più efficace, fornendo vantaggi di implementazione simili alla potatura.
Flusso di lavoro di sviluppo
Come punto di partenza, controlla se i modelli in modelli ospitati possono funzionare per la tua applicazione. In caso contrario, consigliamo agli utenti di iniziare con lo strumento di quantizzazione post-addestramento, poiché è ampiamente applicabile e non richiede dati di addestramento.
Per i casi in cui i target di precisione e latenza non vengono raggiunti o il supporto dell'acceleratore hardware è importante, l'addestramento quantizzazione consapevole è l'opzione migliore. Consulta altre tecniche di ottimizzazione nella sezione TensorFlow Model Optimization Toolkit.
Se vuoi ridurre ulteriormente le dimensioni del modello, puoi provare il pruning e/o il clustering prima di quantizzare i modelli.