
Uç cihazlarda genellikle sınırlı bellek veya işlem gücü bulunur. Modellerin bu kısıtlamalar içinde çalıştırılabilmesi için çeşitli optimizasyonlar uygulanabilir. Ayrıca bazı optimizasyonlar, çıkarım hızlandırma için özel donanım kullanımına olanak tanır.
LiteRT ve TensorFlow Model Optimization Toolkit, çıkarım optimizasyonunun karmaşıklığını en aza indirmeye yönelik araçlar sunar.
Uygulama geliştirme sürecinizde model optimizasyonunu göz önünde bulundurmanız önerilir. Bu belgede, TensorFlow modellerini uç donanımına dağıtım için optimize etmeye yönelik bazı en iyi uygulamalar özetlenmektedir.
Modeller neden optimize edilmelidir?
Model optimizasyonu, uygulama geliştirmeye çeşitli şekillerde yardımcı olabilir.
Boyut küçültme
Bazı optimizasyon türleri, modelin boyutunu küçültmek için kullanılabilir. Daha küçük modellerin avantajları:
- Daha küçük depolama alanı: Daha küçük modeller, kullanıcılarınızın cihazlarında daha az depolama alanı kaplar. Örneğin, daha küçük bir model kullanan bir Android uygulaması, kullanıcının mobil cihazında daha az depolama alanı kaplar.
- Daha küçük indirme boyutu: Daha küçük modellerin kullanıcı cihazlarına indirilmesi için daha az süre ve bant genişliği gerekir.
- Daha az bellek kullanımı: Daha küçük modeller çalıştırıldığında daha az RAM kullanır. Bu da uygulamanızın diğer bölümlerinin kullanabileceği bellek alanını boşaltır ve daha iyi performans ve kararlılık sağlar.
Kuantizasyon, bu durumların hepsinde modelin boyutunu küçültebilir. Bu işlem, doğruluktan biraz ödün verilmesine neden olabilir. Budama ve kümeleme, daha kolay sıkıştırılabilir hale getirerek indirilecek modelin boyutunu küçültebilir.
Gecikmeyi azaltma
Gecikme, belirli bir modelle tek bir çıkarımın çalıştırılması için geçen süredir. Bazı optimizasyon biçimleri, bir model kullanılarak çıkarım çalıştırmak için gereken hesaplama miktarını azaltabilir ve bu da daha düşük gecikmeye yol açar. Gecikme, güç tüketimini de etkileyebilir.
Şu anda nicemleme, çıkarım sırasında gerçekleşen hesaplamaları basitleştirerek gecikmeyi azaltmak için kullanılabilir. Bu işlem, doğrulukta bir miktar kayba neden olabilir.
Hızlandırıcı uyumluluğu
Edge TPU gibi bazı donanım hızlandırıcılar, doğru şekilde optimize edilmiş modellerle çıkarımı son derece hızlı bir şekilde çalıştırabilir.
Genellikle bu tür cihazlarda modellerin belirli bir şekilde nicelleştirilmesi gerekir. Donanım hızlandırıcıların gereksinimleri hakkında daha fazla bilgi edinmek için her birinin belgelerine bakın.
Avantajlar ve dezavantajlar
Optimizasyonlar, model doğruluğunda değişikliklere neden olabilir. Bu değişiklikler, uygulama geliştirme sürecinde dikkate alınmalıdır.
Doğruluktaki değişiklikler, optimize edilen modele bağlıdır ve önceden tahmin edilmesi zordur. Genellikle boyut veya gecikme için optimize edilmiş modellerde doğruluk oranı biraz düşer. Bu durum, uygulamanıza bağlı olarak kullanıcılarınızın deneyimini etkileyebilir veya etkilemeyebilir. Nadiren de olsa bazı modeller, optimizasyon süreci sonucunda doğruluk kazanabilir.
Optimizasyon türleri
LiteRT şu anda niceliklendirme, budama ve kümeleme yoluyla optimizasyonu desteklemektedir.
Bu araçlar, TensorFlow Lite ile uyumlu model optimizasyon teknikleri için kaynaklar sağlayan TensorFlow Model Optimization Toolkit'in bir parçasıdır.
Kuantizasyon
Kuantizasyon, bir modelin parametrelerini temsil etmek için kullanılan sayıların duyarlılığını azaltarak çalışır. Bu sayılar varsayılan olarak 32 bit kayan nokta biçiminde sayılardır. Bu, daha küçük bir model boyutu ve daha hızlı hesaplama ile sonuçlanır.
LiteRT'de aşağıdaki nicelendirme türleri kullanılabilir:
| Teknik | Veri gereksinimleri | Boyut küçültme | Doğruluk | Desteklenen donanım |
|---|---|---|---|---|
| Eğitim sonrası float16 nicemleme | Veri yok | %50'ye kadar | Önemsiz doğruluk kaybı | CPU, GPU |
| Eğitim sonrası dinamik aralık nicemleme | Veri yok | %75'e kadar | En az doğruluk kaybı | CPU, GPU (Android) |
| Eğitim sonrası tamsayı kuantizasyonu | Etiketlenmemiş temsili örnek | %75'e kadar | Doğrulukta küçük kayıp | CPU, GPU (Android), EdgeTPU |
| Kuantizasyona duyarlı eğitim | Etiketlenmiş eğitim verileri | %75'e kadar | En az doğruluk kaybı | CPU, GPU (Android), EdgeTPU |
Aşağıdaki karar ağacı, yalnızca beklenen model boyutuna ve doğruluğuna göre modelinizde kullanmak isteyebileceğiniz nicemleme şemalarını seçmenize yardımcı olur.
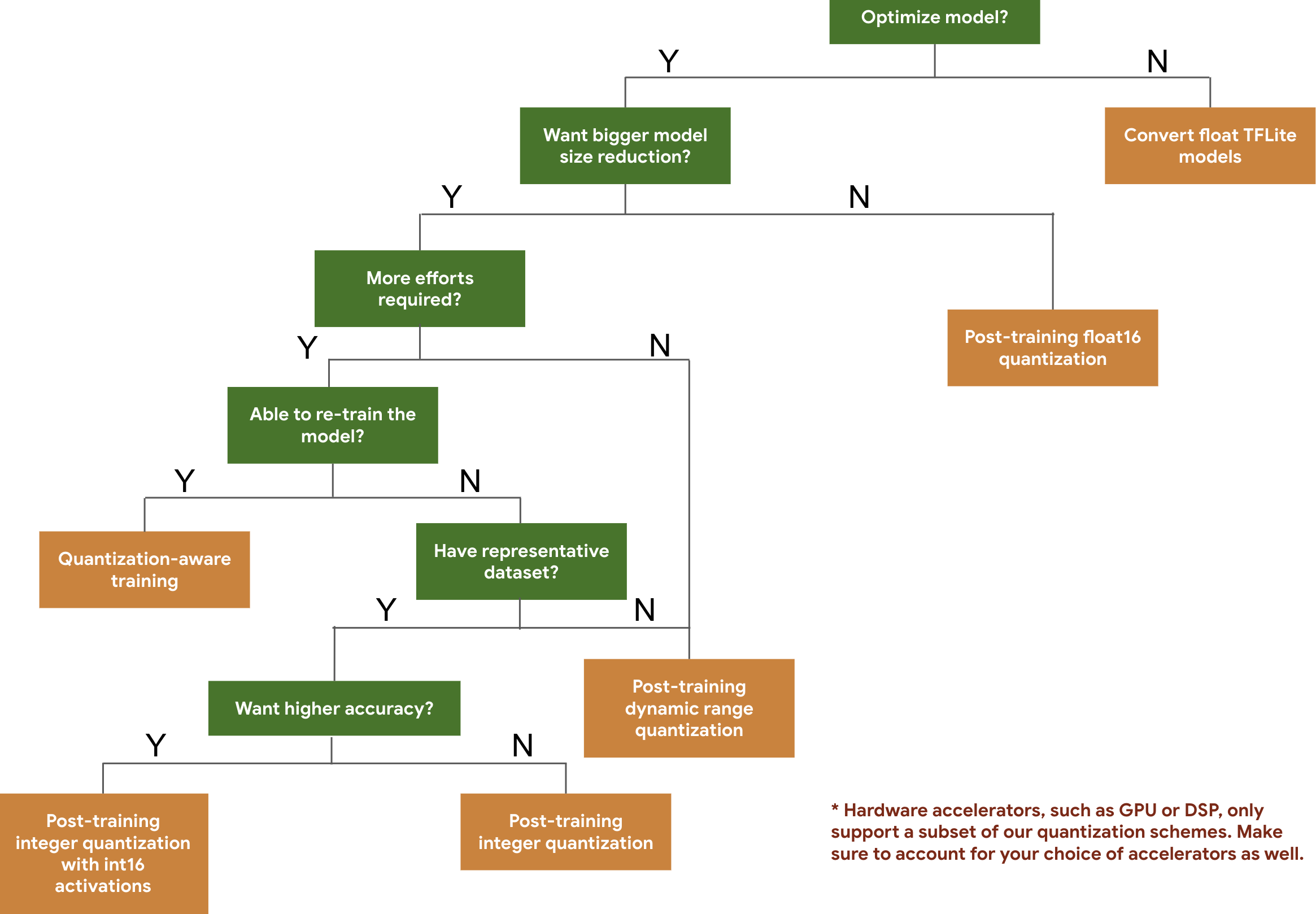
Aşağıda, eğitim sonrası nicemleme ve nicemlemeye duyarlı eğitim için bazı modellerdeki gecikme ve doğruluk sonuçları verilmiştir. Tüm gecikme süreleri, tek bir büyük çekirdekli CPU kullanan Pixel 2 cihazlarda ölçülür. Araç seti geliştikçe buradaki sayılar da artacaktır:
| Model | Top-1 Accuracy (Original) | En İyi 1 Doğruluk (Eğitim Sonrası Kuantize Edilmiş) | Top-1 Accuracy (Quantization Aware Training) | Gecikme (Orijinal) (ms) | Gecikme (Eğitim Sonrası Kuantize Edilmiş) (ms) | Gecikme (Kuantizasyon Farkındalığına Sahip Eğitim) (ms) | Boyut (Orijinal) (MB) | Boyut (Optimum) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0,709 | 0,657 | 0,70 | 124 | 112 | 64 | 16.9 | 4,3 |
| Mobilenet-v2-1-224 | 0,719 | 0,637 | 0,709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0,78 | 0,772 | 0,775 | 1130 | 845 | 543 | 95,7 | 23,9 |
| Resnet_v2_101 | 0,770 | 0,768 | Yok | 3973 | 2868 | Yok | 178,3 | 44,9 |
int16 etkinleştirmeleri ve int8 ağırlıklarıyla tam tamsayı nicemleme
int16 etkinleştirmeleriyle nicemleme int16'da etkinleştirmeler ve int8'de ağırlıklar içeren tam sayı nicemleme şemasıdır. Bu mod, benzer model boyutunu koruyarak hem etkinleştirmelerin hem de ağırlıkların int8'de olduğu tam tamsayı niceleme şemasına kıyasla niceleme yapılmış modelin doğruluğunu artırabilir. Etkinleştirmeler nicemlemeye duyarlı olduğunda önerilir.
NOT: Bu nicemleme şeması için TFLite'ta şu anda yalnızca optimize edilmemiş referans çekirdek uygulamaları mevcuttur. Bu nedenle, varsayılan olarak performans, int8 çekirdeklerine kıyasla yavaş olacaktır. Bu modun tüm avantajlarına şu anda özel donanım veya özel yazılım aracılığıyla erişilebilir.
Aşağıda, bu moddan yararlanan bazı modellerin doğruluk sonuçları verilmiştir.
| Model | Doğruluk metrik türü | Doğruluk (float32 etkinleştirmeleri) | Doğruluk (int8 etkinleştirmeler) | Doğruluk (int16 etkinleştirmeleri) |
|---|---|---|---|---|
| Wav2letter | WER | %6,7 | %7,7 | %7,2 |
| DeepSpeech 0.5.1 (unrolled) | CER | %6,13 | %43,67 | %6,52 |
| YoloV3 | mAP(IOU=0.5) | 0,577 | 0,563 | 0,574 |
| MobileNetV1 | En Yüksek Doğruluk | 0,7062 | 0,694 | 0,6936 |
| MobileNetV2 | En Yüksek Doğruluk | 0,718 | 0,7126 | 0,7137 |
| MobileBert | F1(Tam eşleme) | 88,81(81,23) | 2,08(0) | 88,73(81,15) |
Budama
Budama, bir modeldeki tahminleri yalnızca küçük bir etkiye sahip olan parametreleri kaldırarak çalışır. Budanmış modeller, diskte aynı boyuta ve aynı çalışma zamanı gecikmesine sahiptir ancak daha etkili bir şekilde sıkıştırılabilir. Bu nedenle budama, model indirme boyutunu küçültmek için kullanışlı bir tekniktir.
Gelecekte LiteRT, kırpılmış modeller için gecikme süresini azaltacaktır.
Kümeleme
Kümeleme, bir modeldeki her katmanın ağırlıklarını önceden tanımlanmış sayıda küme halinde gruplandırarak ve ardından her bir kümeye ait ağırlıkların merkez değerlerini paylaşarak çalışır. Bu, bir modeldeki benzersiz ağırlık değerlerinin sayısını azaltarak modelin karmaşıklığını azaltır.
Sonuç olarak, kümelenmiş modeller daha etkili bir şekilde sıkıştırılabilir ve budamaya benzer dağıtım avantajları sağlanabilir.
Geliştirme iş akışı
Başlangıç noktası olarak, barındırılan modellerdeki modellerin uygulamanızda çalışıp çalışmadığını kontrol edin. Aksi takdirde, geniş bir uygulama alanına sahip olduğu ve eğitim verileri gerektirmediği için kullanıcıların eğitim sonrası nicemleme aracı ile başlamasını öneririz.
Doğruluk ve gecikme hedeflerinin karşılanmadığı veya donanım hızlandırıcı desteğinin önemli olduğu durumlarda nicemlemeye duyarlı eğitim daha iyi bir seçenektir. Ek optimizasyon tekniklerini TensorFlow Model Optimizasyon Araç Seti bölümünde bulabilirsiniz.
Model boyutunuzu daha da küçültmek istiyorsanız modellerinizi nicel hale getirmeden önce budamayı ve/veya kümelemeyi deneyebilirsiniz.