
อุปกรณ์ Edge มักมีหน่วยความจำหรือกำลังประมวลผลที่จำกัด คุณสามารถใช้การเพิ่มประสิทธิภาพต่างๆ กับโมเดลเพื่อให้โมเดลทำงานได้ภายในข้อจำกัดเหล่านี้ นอกจากนี้ การเพิ่มประสิทธิภาพบางอย่างยังอนุญาตให้ใช้ฮาร์ดแวร์เฉพาะทาง เพื่อการอนุมานที่รวดเร็วขึ้นด้วย
LiteRT และชุดเครื่องมือเพิ่มประสิทธิภาพโมเดล TensorFlow มีเครื่องมือที่ช่วยลดความซับซ้อนของการเพิ่มประสิทธิภาพการอนุมาน
เราขอแนะนําให้คุณพิจารณาการเพิ่มประสิทธิภาพโมเดลในระหว่างกระบวนการพัฒนาแอปพลิเคชัน เอกสารนี้จะอธิบายแนวทางปฏิบัติแนะนำบางส่วนในการเพิ่มประสิทธิภาพ โมเดล TensorFlow เพื่อการติดตั้งใช้งานในฮาร์ดแวร์ Edge
เหตุผลที่ควรเพิ่มประสิทธิภาพโมเดล
การเพิ่มประสิทธิภาพโมเดลช่วยในการพัฒนาแอปพลิเคชันได้หลายวิธีหลักๆ ดังนี้
การลดขนาด
การเพิ่มประสิทธิภาพบางรูปแบบสามารถใช้เพื่อลดขนาดของโมเดลได้ โมเดลขนาดเล็กมีข้อดีดังนี้
- ขนาดพื้นที่เก็บข้อมูลเล็กลง: โมเดลขนาดเล็กจะใช้พื้นที่เก็บข้อมูลในอุปกรณ์ของผู้ใช้ของคุณน้อยลง เช่น แอป Android ที่ใช้โมเดลขนาดเล็กกว่าจะใช้พื้นที่เก็บข้อมูลในอุปกรณ์เคลื่อนที่ของผู้ใช้น้อยกว่า
- ขนาดการดาวน์โหลดเล็กลง: โมเดลที่มีขนาดเล็กลงใช้เวลาและแบนด์วิดท์น้อยลงในการ ดาวน์โหลดไปยังอุปกรณ์ของผู้ใช้
- การใช้หน่วยความจำน้อยลง: โมเดลขนาดเล็กจะใช้ RAM น้อยลงเมื่อทำงาน ซึ่งจะ เพิ่มพื้นที่หน่วยความจำให้ส่วนอื่นๆ ของแอปพลิเคชันได้ใช้ และอาจ ส่งผลให้ประสิทธิภาพและความเสถียรดีขึ้น
การกำหนดปริมาณจะช่วยลดขนาดของโมเดลในกรณีเหล่านี้ทั้งหมดได้ ซึ่งอาจ ทำให้ความแม่นยำลดลง การตัดแต่งและการจัดกลุ่มจะช่วยลดขนาดของโมเดลสำหรับการดาวน์โหลดได้ด้วยการทำให้บีบอัดได้ง่ายขึ้น
การลดเวลาในการตอบสนอง
เวลาในการตอบสนองคือระยะเวลาที่ใช้ในการเรียกใช้การอนุมานครั้งเดียวด้วยโมเดลที่กำหนด การเพิ่มประสิทธิภาพบางรูปแบบจะช่วยลดปริมาณการคำนวณที่จำเป็น ในการเรียกใช้การอนุมานโดยใช้โมเดล ซึ่งส่งผลให้เวลาในการตอบสนองลดลง นอกจากนี้ เวลาในการตอบสนองยังอาจ ส่งผลต่อการใช้พลังงานด้วย
ปัจจุบันการควอนไทซ์ใช้เพื่อลดเวลาในการตอบสนองได้โดยการลดความซับซ้อนของ การคำนวณที่เกิดขึ้นระหว่างการอนุมาน ซึ่งอาจส่งผลให้ความแม่นยำลดลง
ความเข้ากันได้ของ Accelerator
ตัวเร่งฮาร์ดแวร์บางอย่าง เช่น Edge TPU สามารถเรียกใช้การอนุมานได้อย่างรวดเร็วด้วย โมเดลที่ได้รับการเพิ่มประสิทธิภาพอย่างถูกต้อง
โดยทั่วไปแล้ว อุปกรณ์ประเภทนี้กำหนดให้ต้องมีการควอนไทซ์โมเดลในลักษณะที่เฉพาะเจาะจง ดูเอกสารประกอบของตัวเร่งฮาร์ดแวร์แต่ละรายการเพื่อดูข้อมูลเพิ่มเติมเกี่ยวกับ ข้อกำหนด
ข้อดีข้อเสีย
การเพิ่มประสิทธิภาพอาจส่งผลให้ความแม่นยำของโมเดลเปลี่ยนแปลง ซึ่งต้อง พิจารณาในกระบวนการพัฒนาแอปพลิเคชัน
ความแม่นยำที่เปลี่ยนแปลงไปขึ้นอยู่กับโมเดลแต่ละรายการที่ได้รับการเพิ่มประสิทธิภาพ และคาดการณ์ล่วงหน้าได้ยาก โดยทั่วไปแล้ว โมเดลที่ได้รับการเพิ่มประสิทธิภาพเพื่อ ขนาดหรือเวลาในการตอบสนองจะมีความแม่นยำลดลงเล็กน้อย การดำเนินการนี้อาจส่งผลต่อประสบการณ์ของผู้ใช้หรือไม่ก็ได้ ขึ้นอยู่กับ แอปพลิเคชันของคุณ ในบางกรณีที่แทบจะไม่เคยเกิดขึ้น โมเดลบางรุ่นอาจมีความแม่นยำมากขึ้นอันเป็นผลมาจากกระบวนการเพิ่มประสิทธิภาพ
ประเภทการเพิ่มประสิทธิภาพ
ปัจจุบัน LiteRT รองรับการเพิ่มประสิทธิภาพผ่านการหาปริมาณ การตัดแต่ง และการจัดกลุ่ม
ซึ่งเป็นส่วนหนึ่งของชุดเครื่องมือเพิ่มประสิทธิภาพโมเดล TensorFlow ซึ่งมี แหล่งข้อมูลสำหรับเทคนิคการเพิ่มประสิทธิภาพโมเดลที่เข้ากันได้กับ TensorFlow Lite
การควอนไทซ์
การกำหนดปริมาณ ทำงานโดยการลดความแม่นยำของตัวเลขที่ใช้เพื่อแสดงพารามิเตอร์ของโมเดล ซึ่งโดยค่าเริ่มต้นจะเป็นเลขทศนิยมแบบ 32 บิต ซึ่งส่งผลให้ โมเดลมีขนาดเล็กลงและคำนวณได้เร็วขึ้น
การหาปริมาณประเภทต่อไปนี้พร้อมใช้งานใน LiteRT
| เทคนิค | ข้อกำหนดด้านข้อมูล | การลดขนาด | ความแม่นยำ | ฮาร์ดแวร์ที่รองรับ |
|---|---|---|---|---|
| การแปลงเป็นควอนไทซ์ float16 หลังการฝึก | ไม่มีข้อมูล | สูงสุด 50% | การสูญเสียความแม่นยำที่ไม่มีนัยสำคัญ | CPU, GPU |
| การหาปริมาณช่วงไดนามิกหลังการฝึก | ไม่มีข้อมูล | สูงสุด 75% | การสูญเสียความแม่นยำน้อยที่สุด | CPU, GPU (Android) |
| การแปลงจำนวนเต็มหลังการฝึก | ตัวอย่างซึ่งเป็นตัวแทนของทั้งหมดที่ไม่มีป้ายกำกับ | สูงสุด 75% | ความแม่นยำลดลงเล็กน้อย | CPU, GPU (Android), EdgeTPU |
| การฝึกที่คำนึงถึงการหาปริมาณ | ข้อมูลการฝึกที่ติดป้ายกำกับ | สูงสุด 75% | การสูญเสียความแม่นยำน้อยที่สุด | CPU, GPU (Android), EdgeTPU |
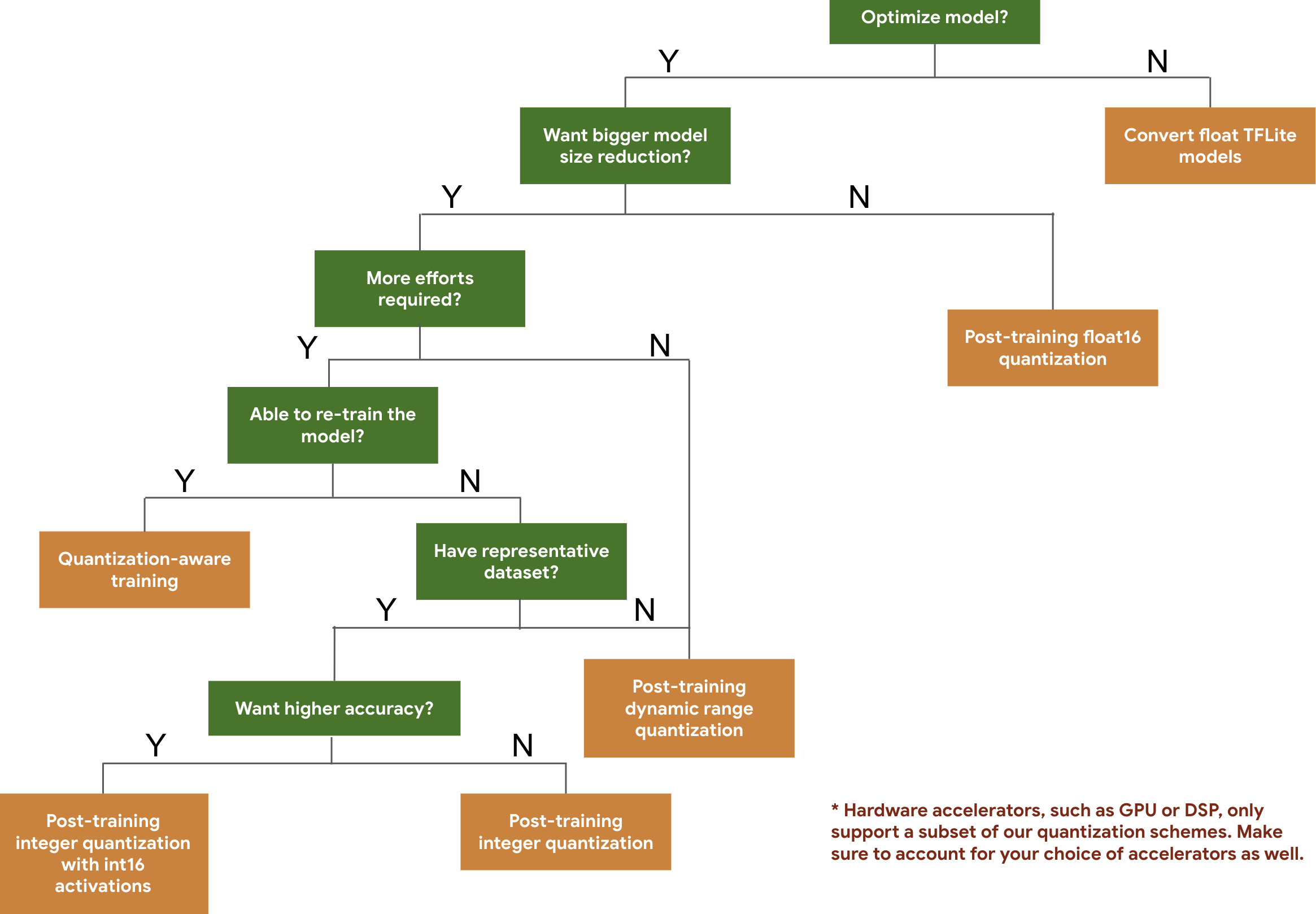
แผนผังการตัดสินใจต่อไปนี้จะช่วยให้คุณเลือกรูปแบบการหาปริมาณที่อาจต้องการใช้กับโมเดลได้ โดยพิจารณาจากขนาดและความแม่นยำของโมเดลที่คาดไว้
ด้านล่างนี้คือผลลัพธ์ของเวลาในการตอบสนองและความแม่นยําสําหรับการหาปริมาณหลังการฝึกและการฝึกที่คำนึงถึงการหาปริมาณในโมเดลบางรายการ ตัวเลขเวลาในการตอบสนองทั้งหมดวัดบนอุปกรณ์ Pixel 2 โดยใช้ CPU แกนใหญ่แกนเดียว เมื่อชุดเครื่องมือได้รับการปรับปรุง ตัวเลขต่อไปนี้ก็จะได้รับการปรับปรุงด้วย
| รุ่น | ความแม่นยำสูงสุด (เดิม) | ความแม่นยำระดับสูงสุด (หลังการฝึกแบบควอนไทซ์) | ความแม่นยำสูงสุด (การฝึกที่คำนึงถึงการหาปริมาณ) | เวลาในการตอบสนอง (เดิม) (มิลลิวินาที) | เวลาในการตอบสนอง (หลังการฝึกแบบควอนไทซ์) (มิลลิวินาที) | เวลาในการตอบสนอง (การฝึกที่คำนึงถึงการหาปริมาณ) (มิลลิวินาที) | ขนาด (ต้นฉบับ) (MB) | ขนาด (ปรับให้เหมาะสม) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | ไม่มี | 3973 | 2868 | ไม่มี | 178.3 | 44.9 |
การวัดปริมาณจำนวนเต็มแบบเต็มที่มีการเปิดใช้งาน int16 และน้ำหนัก int8
การหาปริมาณด้วยการเปิดใช้งาน int16 เป็นรูปแบบการหาปริมาณจำนวนเต็มแบบสมบูรณ์ที่มีการเปิดใช้งานใน int16 และน้ำหนักใน int8 โหมดนี้ช่วยปรับปรุงความแม่นยำของโมเดลที่แปลงเป็นจำนวนเต็มเมื่อเทียบกับ รูปแบบการแปลงเป็นจำนวนเต็มแบบเต็มที่มีทั้งการกระตุ้นและน้ำหนักใน int8 โดยยังคงขนาดโมเดลไว้คล้ายเดิม ขอแนะนําเมื่อการเปิดใช้งานมีความละเอียดอ่อน ต่อการหาปริมาณ
หมายเหตุ: ปัจจุบันมีเฉพาะการใช้งานเคอร์เนลอ้างอิงที่ไม่ได้เพิ่มประสิทธิภาพใน TFLite สำหรับรูปแบบการหาปริมาณนี้ ดังนั้นโดยค่าเริ่มต้นประสิทธิภาพจะช้าเมื่อเทียบกับเคอร์เนล int8 ปัจจุบันคุณจะใช้ประโยชน์จากโหมดนี้ได้อย่างเต็มที่ผ่านฮาร์ดแวร์เฉพาะทางหรือซอฟต์แวร์ที่กำหนดเอง
ด้านล่างคือผลลัพธ์ความแม่นยำของโมเดลบางรายการที่ได้รับประโยชน์จากโหมดนี้
| รุ่น | ประเภทเมตริกความแม่นยำ | ความแม่นยำ (การเปิดใช้งาน float32) | ความแม่นยำ (การเปิดใช้งาน int8) | ความแม่นยำ (การเปิดใช้งาน int16) |
|---|---|---|---|---|
| Wav2letter | WER | 6.7% | 7.7% | 7.2% |
| DeepSpeech 0.5.1 (unrolled) | CER | 6.13% | 43.67% | 6.52% |
| YoloV3 | mAP(IOU=0.5) | 0.577 | 0.563 | 0.574 |
| MobileNetV1 | ความแม่นยำสูงสุด | 0.7062 | 0.694 | 0.6936 |
| MobileNetV2 | ความแม่นยำสูงสุด | 0.718 | 0.7126 | 0.7137 |
| MobileBert | F1(การทำงานแบบตรงทั้งหมด) | 88.81(81.23) | 2.08(0) | 88.73(81.15) |
การตัดแต่ง
การพรุนทำงานโดยการ นำพารามิเตอร์ภายในโมเดลที่มีผลเพียงเล็กน้อยต่อ การคาดการณ์ออก โมเดลที่พรุนแล้วจะมีขนาดเท่ากันในดิสก์และมีเวลาในการตอบสนองขณะรันไทม์เท่ากัน แต่จะบีบอัดได้อย่างมีประสิทธิภาพมากขึ้น การตัดแต่งจึงเป็นเทคนิคที่มีประโยชน์ในการลดขนาดการดาวน์โหลดโมเดล
ในอนาคต LiteRT จะช่วยลดเวลาในการตอบสนองสำหรับโมเดลที่ตัดแต่งแล้ว
การคลัสเตอร์
การจัดกลุ่ม ทำงานโดยการจัดกลุ่มน้ำหนักของแต่ละเลเยอร์ในโมเดลเป็นจำนวนคลัสเตอร์ที่กำหนดไว้ล่วงหน้า จากนั้นแชร์ค่าเซนทรอยด์สำหรับน้ำหนักที่เป็นของแต่ละคลัสเตอร์ ซึ่งจะช่วยลดจำนวนค่าถ่วงน้ำหนักที่ไม่ซ้ำกันในโมเดล จึงลดความซับซ้อนของโมเดล
ด้วยเหตุนี้ โมเดลแบบคลัสเตอร์จึงสามารถบีบอัดได้อย่างมีประสิทธิภาพมากขึ้น ซึ่งให้ ประโยชน์ในการติดตั้งใช้งานคล้ายกับการพรุน
เวิร์กโฟลว์การพัฒนา
เริ่มต้นด้วยการตรวจสอบว่าโมเดลในโมเดลที่โฮสต์ใช้กับแอปพลิเคชันของคุณได้หรือไม่ หากไม่เป็นเช่นนั้น เราขอแนะนำให้ผู้ใช้เริ่มต้นด้วยเครื่องมือการวัดปริมาณหลังการฝึก เนื่องจากเครื่องมือนี้ใช้ได้ในวงกว้างและไม่จำเป็นต้องใช้ข้อมูลการฝึก
ในกรณีที่ไม่ได้ตามเป้าหมายความแม่นยำและความหน่วง หรือการรองรับตัวเร่งฮาร์ดแวร์เป็นสิ่งสำคัญ การฝึกแบบตระหนักถึงการหาปริมาณ จึงเป็นตัวเลือกที่ดีกว่า ดูเทคนิคการเพิ่มประสิทธิภาพเพิ่มเติมได้ใน ชุดเครื่องมือเพิ่มประสิทธิภาพโมเดล TensorFlow
หากต้องการลดขนาดโมเดลเพิ่มเติม คุณสามารถลองใช้การพรุน และ/หรือการจัดกลุ่มก่อนที่จะควอนไทซ์โมเดล