
Метаданные LiteRT предоставляют стандарт для описания моделей. Метаданные являются важным источником информации о том, что делает модель, а также о её входных и выходных данных. Метаданные включают в себя:
- человекочитаемые части, которые передают наилучшую практику использования модели, и
- машиночитаемые части, которые могут быть использованы генераторами кода, такими как генератор кода Android LiteRT и функция привязки ML Android Studio .
Все модели изображений, опубликованные на Kaggle Models, заполнены метаданными.
Модель с форматом метаданных
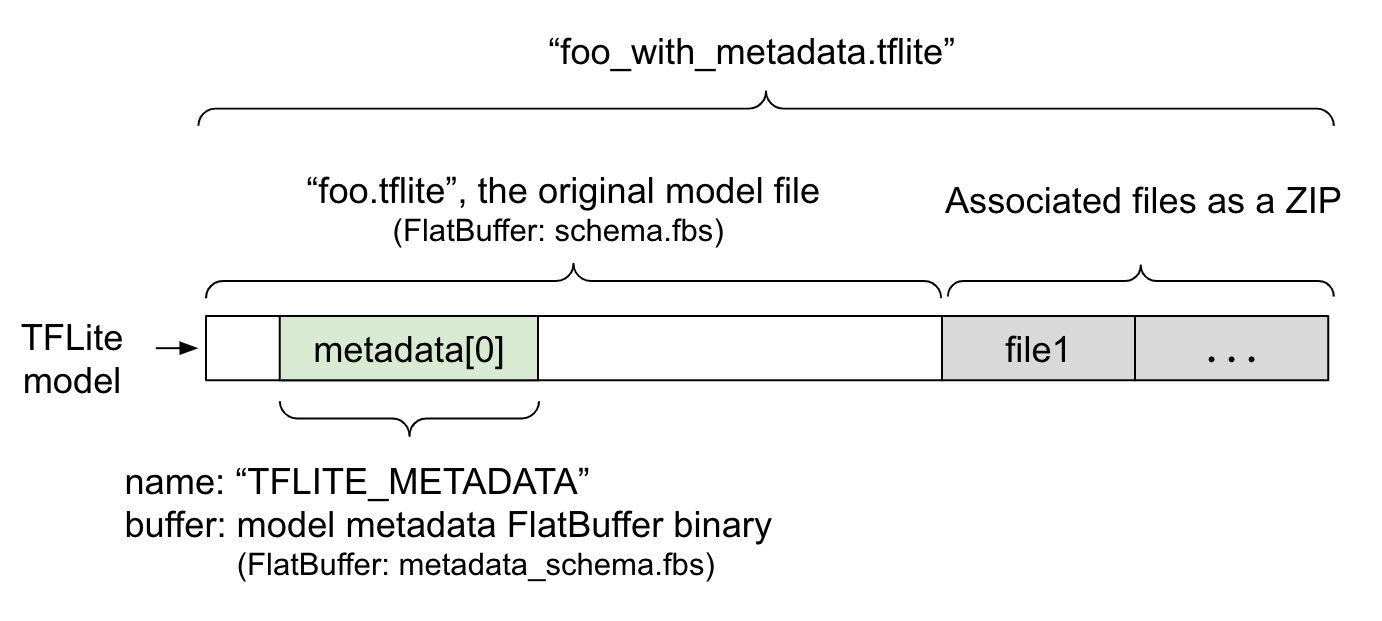
Метаданные модели определяются в metadata_schema.fbs — файле FlatBuffer . Как показано на рисунке 1, они хранятся в поле метаданных схемы модели TFLite под именем "TFLITE_METADATA" . Некоторые модели могут поставляться с соответствующими файлами, например, файлами классификационных меток . Эти файлы добавляются в конец исходного файла модели в виде ZIP-архива с использованием режима добавления ( 'a' ) утилиты ZipFile. Интерпретатор TFLite может использовать новый формат файла так же, как и раньше. Подробнее см. в разделе «Упаковка связанных файлов» .
Инструкцию о том, как заполнять, визуализировать и читать метаданные, см. ниже.
Настройка инструментов метаданных
Перед добавлением метаданных в модель вам потребуется настроить среду программирования Python для запуска TensorFlow. Подробное руководство по настройке доступно здесь .
После настройки среды программирования Python вам потребуется установить дополнительные инструменты:
pip install tflite-support
Инструментарий метаданных LiteRT поддерживает Python 3.
Добавление метаданных с помощью Flatbuffers Python API
Метаданные модели в схеме состоят из трех частей:
- Информация о модели — общее описание модели, а также такие элементы, как условия лицензии. См. ModelMetadata . 2. Входная информация — описание входных данных и необходимой предварительной обработки, например, нормализации. См. SubGraphMetadata.input_tensor_metadata . 3. Выходная информация — описание выходных данных и необходимой постобработки, например, сопоставления с метками. См. SubGraphMetadata.output_tensor_metadata .
Поскольку на данный момент LiteRT поддерживает только один подграф, генератор кода LiteRT и функция привязки ML Android Studio будут использовать ModelMetadata.name и ModelMetadata.description вместо SubGraphMetadata.name и SubGraphMetadata.description при отображении метаданных и генерации кода.
Поддерживаемые типы ввода/вывода
Метаданные LiteRT для входных и выходных данных разработаны не для конкретных типов моделей, а для типов входных и выходных данных. Неважно, какую функцию выполняет модель, если типы входных и выходных данных включают в себя следующие элементы или их комбинацию, метаданные TensorFlow Lite поддерживают их:
- Особенность - Числа, которые являются беззнаковыми целыми числами или числами с плавающей точкой.
- Изображение - Метаданные в настоящее время поддерживают изображения в форматах RGB и оттенков серого.
- Ограничивающий блок — прямоугольные ограничивающие блоки. Схема поддерживает различные варианты нумерации .
Упакуйте сопутствующие файлы
Модели LiteRT могут поставляться с различными связанными файлами. Например, модели естественного языка обычно содержат файлы лексики, сопоставляющие части слов с идентификаторами слов; модели классификации могут содержать файлы меток, указывающие категории объектов. Без связанных файлов (если они есть) модель не будет работать должным образом.
Связанные файлы теперь можно объединить с моделью через библиотеку метаданных Python. Новая модель LiteRT представляет собой ZIP-архив, содержащий как модель, так и связанные с ней файлы. Его можно распаковать с помощью стандартных ZIP-архиваторов. Этот новый формат модели сохраняет то же расширение файла — .tflite . Он совместим с существующим фреймворком TFLite и интерпретатором. Подробнее см. в разделе «Упаковка метаданных и связанных файлов в модель» .
Информация о связанном файле может быть записана в метаданные. В зависимости от типа файла и места его присоединения (например, ModelMetadata , SubGraphMetadata и TensorMetadata ), генератор кода LiteRT для Android может автоматически применять к объекту соответствующую предварительную и постобработку. Подробнее см. в разделе <Использование Codegen> для каждого связанного типа файла в схеме.
Параметры нормализации и квантования
Нормализация — распространённый метод предварительной обработки данных в машинном обучении. Цель нормализации — привести значения к единой шкале, не искажая различия в диапазонах значений.
Квантование модели — это метод, который позволяет уменьшить точность представления весов и, при необходимости, активировать как для хранения, так и для вычислений.
С точки зрения предварительной и постобработки нормализация и квантование — это два независимых этапа. Вот подробности.
| Нормализация | Квантование | |
|---|---|---|
Пример значений параметров входного изображения в MobileNet для моделей float и quant соответственно. | Поплавковая модель : - среднее: 127,5 - стандарт: 127,5 Количественная модель : - среднее: 127,5 - стандарт: 127,5 | Поплавковая модель : - zeroPoint: 0 - масштаб: 1.0 Количественная модель : - zeroPoint: 128.0 - масштаб: 0,0078125f |
Когда вызывать? | Входные данные : если входные данные нормализованы при обучении, входные данные вывода должны быть нормализованы соответствующим образом. Выходные данные : выходные данные в целом не будут нормализованы. | Модели с плавающей точкой не требуют квантования. Квантованная модель может потребовать или не потребовать квантования на этапе предварительной/постобработки. Это зависит от типа данных входных/выходных тензоров. - тензоры с плавающей точкой: квантование при предварительной и последующей обработке не требуется. Квантовые и деквантовые операции встроены в граф модели. - тензоры int8/uint8: требуется квантование при пред/постобработке. |
Формула | нормализованный_вход = (вход - среднее) / стандарт | Квантование для входов : q = f / масштаб + нольPoint Деквантование для выходов : f = (q - zeroPoint) * масштаб |
Где параметры? | Заполняется создателем модели и сохраняется в метаданных модели как NormalizationOptions | Заполняется автоматически конвертером TFLite и сохраняется в файле модели tflite. |
| Как получить параметры? | Через API MetadataExtractor [2] | Через API TFLite Tensor [1] или через API MetadataExtractor [2] |
| Одинаково ли ценны модели с плавающей ставкой и количественные модели? | Да, модели с плавающей точкой и квантовые модели имеют одинаковые параметры нормализации. | Нет, модель float не нуждается в квантовании. |
| Генерирует ли генератор кода TFLite или привязка Android Studio ML автоматически при обработке данных? | Да | Да |
[1] API LiteRT Java и API LiteRT C++ .
[2] Библиотека извлечения метаданных
При обработке данных изображений для моделей uint8 нормализация и квантование иногда пропускаются. Это допустимо, если значения пикселей находятся в диапазоне [0, 255]. Но в целом следует всегда обрабатывать данные в соответствии с параметрами нормализации и квантования, если они применимы.
Примеры
Примеры заполнения метаданных для различных типов моделей можно найти здесь:
Классификация изображений
Загрузите скрипт здесь , он заполняет метаданные в mobilenet_v1_0.75_160_quantized.tflite . Запустите скрипт следующим образом:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
Чтобы заполнить метаданные для других моделей классификации изображений, добавьте в скрипт спецификации модели, подобные этим . Далее в этом руководстве будут рассмотрены некоторые ключевые разделы примера классификации изображений для иллюстрации ключевых элементов.
Подробный анализ примера классификации изображений
Информация о модели
Метаданные начинаются с создания новой информации о модели:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
Входная/выходная информация
В этом разделе показано, как описать входные и выходные данные модели. Эти метаданные могут использоваться автоматическими генераторами кода для создания кода предварительной и постобработки. Чтобы создать входную или выходную информацию о тензоре:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
Ввод изображения
Изображение — распространённый тип входных данных для машинного обучения. Метаданные LiteRT поддерживают такую информацию, как цветовое пространство и предобработка, например, нормализация. Размер изображения не требует ручного указания, поскольку он уже задан формой входного тензора и может быть определён автоматически.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
Вывод этикетки
Метку можно сопоставить с выходным тензором через связанный файл с помощью TENSOR_AXIS_LABELS .
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
Создайте метаданные Flatbuffers
Следующий код объединяет информацию о модели с входной и выходной информацией:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
Упакуйте метаданные и связанные файлы в модель
После создания Flatbuffers метаданных метаданные и файл метки записываются в файл TFLite с помощью метода populate :
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
Вы можете упаковать в модель любое количество связанных файлов с помощью load_associated_files . Однако необходимо упаковать как минимум те файлы, которые указаны в метаданных. В этом примере упаковка файла метки обязательна.
Визуализируйте метаданные
Вы можете использовать Netron для визуализации метаданных или прочитать метаданные из модели LiteRT в формате JSON с помощью MetadataDisplayer :
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio также поддерживает отображение метаданных с помощью функции Android Studio ML Binding .
Версионирование метаданных
Схема метаданных версионируется как по номеру версии Semantic, который отслеживает изменения файла схемы, так и по идентификатору файла Flatbuffers, который указывает на истинную совместимость версий.
Номер семантической версии
Схема метаданных версионируется по семантическому номеру версии , например, MAJOR.MINOR.PATCH. Изменения схемы отслеживаются в соответствии с правилами, описанными здесь . Смотрите историю полей, добавленных после версии 1.0.0 .
Идентификация файла Flatbuffers
Семантическое версионирование гарантирует совместимость при соблюдении правил, но не подразумевает истинную несовместимость. Увеличение номера MAJOR не обязательно означает нарушение обратной совместимости. Поэтому мы используем идентификатор файла Flatbuffers , file_identifier , для обозначения истинной совместимости схемы метаданных. Идентификатор файла состоит ровно из 4 символов. Он привязан к определенной схеме метаданных и не может быть изменен пользователями. Если по какой-либо причине обратная совместимость схемы метаданных должна быть нарушена, file_identifier увеличится, например, с «M001» до «M002». Ожидается, что File_identifier будет изменяться гораздо реже, чем metadata_version.
Минимально необходимая версия парсера метаданных
Минимальная необходимая версия парсера метаданных — это минимальная версия парсера метаданных (кода, сгенерированного Flatbuffers), которая может полностью считывать метаданные Flatbuffers. Эта версия фактически представляет собой наибольший номер версии среди всех заполненных полей и наименьшую совместимую версию, указанную идентификатором файла. Минимальная необходимая версия парсера метаданных автоматически заполняется MetadataPopulator при заполнении метаданных в модель TFLite. Подробнее об использовании минимально необходимой версии парсера метаданных см. в разделе « Извлечение метаданных» .
Чтение метаданных из моделей
Библиотека Metadata Extractor — это удобный инструмент для чтения метаданных и связанных файлов из моделей на разных платформах (см. версии для Java и C++ ). Вы можете создать собственный инструмент для извлечения метаданных на других языках, используя библиотеку Flatbuffers.
Прочитать метаданные на Java
Для использования библиотеки Metadata Extractor в вашем Android-приложении мы рекомендуем использовать LiteRT Metadata AAR, размещённый на MavenCentral . Он содержит класс MetadataExtractor , а также привязки FlatBuffers Java для схемы метаданных и схемы модели .
Вы можете указать это в зависимостях build.gradle следующим образом:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
Чтобы использовать ночные снимки, убедитесь, что вы добавили репозиторий снимков Sonatype .
Вы можете инициализировать объект MetadataExtractor с помощью ByteBuffer , который указывает на модель:
public MetadataExtractor(ByteBuffer buffer);
ByteBuffer должен оставаться неизменным в течение всего жизненного цикла объекта MetadataExtractor . Инициализация может завершиться неудачей, если идентификатор файла Flatbuffers метаданных модели не совпадает с идентификатором файла анализатора метаданных. Подробнее см. в разделе «Управление версиями метаданных» .
При совпадении идентификаторов файлов экстрактор метаданных успешно прочитает метаданные, сгенерированные из всех предыдущих и будущих схем благодаря механизму прямой и обратной совместимости Flatbuffers. Однако поля из будущих схем не могут быть извлечены старыми экстракторами метаданных. Минимальная необходимая версия парсера метаданных указывает минимальную версию парсера метаданных, которая может полностью прочитать метаданные Flatbuffers. Вы можете использовать следующий метод для проверки выполнения условия минимально необходимой версии парсера:
public final boolean isMinimumParserVersionSatisfied();
Передача модели без метаданных допускается. Однако вызов методов, считывающих метаданные, приведёт к ошибкам выполнения. Проверить наличие метаданных в модели можно, вызвав метод hasMetadata :
public boolean hasMetadata();
MetadataExtractor предоставляет удобные функции для получения метаданных входных/выходных тензоров. Например,
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
Хотя схема модели LiteRT поддерживает несколько подграфов, интерпретатор TFLite в настоящее время поддерживает только один подграф. Поэтому MetadataExtractor не использует индекс подграфа в качестве входного аргумента в своих методах.
Прочитать связанные файлы из моделей
Модель LiteRT с метаданными и связанными файлами представляет собой ZIP-архив, который можно распаковать с помощью стандартных ZIP-архиваторов для получения соответствующих файлов. Например, можно распаковать mobilenet_v1_0.75_160_quantized и извлечь файл метки из модели следующим образом:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
Вы также можете прочитать связанные файлы через библиотеку Metadata Extractor.
В Java передайте имя файла в метод MetadataExtractor.getAssociatedFile :
public InputStream getAssociatedFile(String fileName);
Аналогично в C++ это можно сделать с помощью метода ModelMetadataExtractor::GetAssociatedFile :
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;