
ข้อมูลเมตา LiteRT มีมาตรฐานสำหรับคำอธิบายโมเดล ข้อมูลเมตาเป็นแหล่งความรู้ที่สำคัญเกี่ยวกับสิ่งที่โมเดลทำ รวมถึงข้อมูลอินพุต / เอาต์พุต ข้อมูลเมตาประกอบด้วย
- ส่วนที่มนุษย์อ่านได้ซึ่งสื่อถึงแนวทางปฏิบัติแนะนำเมื่อใช้โมเดล และ
- ส่วนที่เครื่องอ่านได้ซึ่งเครื่องมือสร้างโค้ดใช้ประโยชน์ได้ เช่น เครื่องมือสร้างโค้ด Android ของ LiteRT และฟีเจอร์การเชื่อมโยง ML ของ Android Studio
โมเดลรูปภาพทั้งหมดที่เผยแพร่ใน Kaggle Models มีข้อมูลเมตา
โมเดลที่มีรูปแบบข้อมูลเมตา
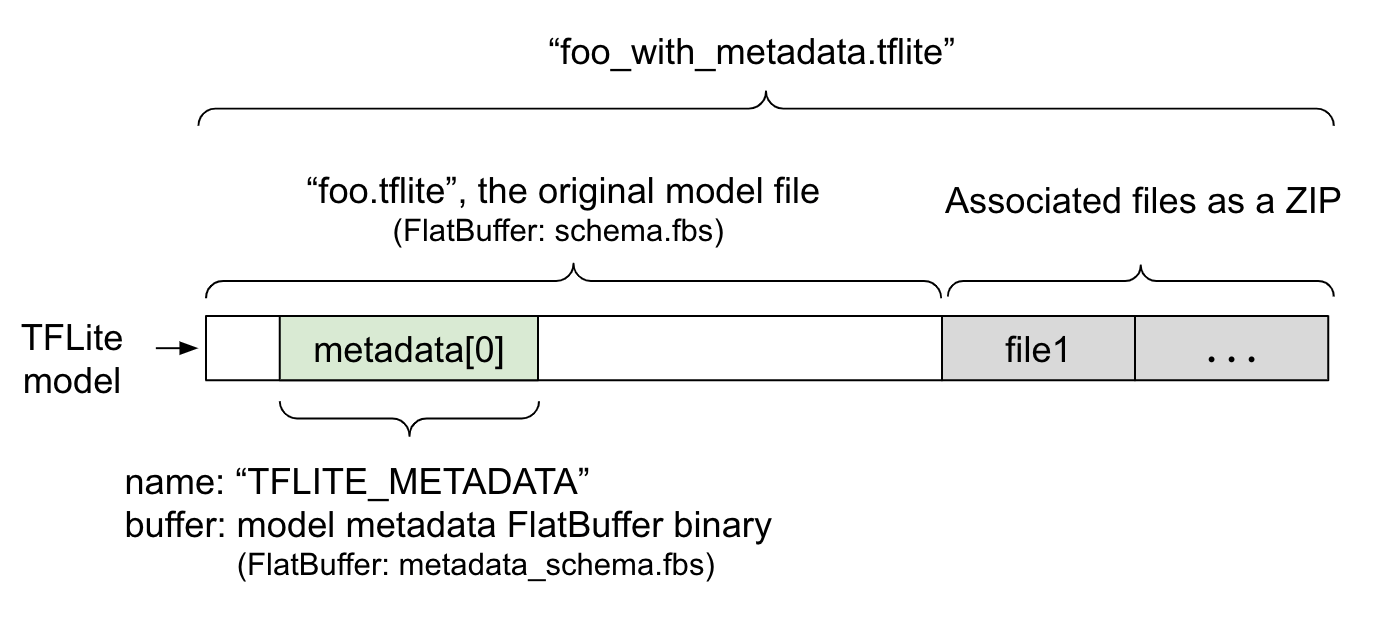
ข้อมูลเมตาของโมเดลจะกำหนดไว้ในไฟล์
metadata_schema.fbs
ซึ่งเป็นไฟล์
FlatBuffer ดังที่แสดงในรูปที่ 1 ข้อมูลจะจัดเก็บไว้ในฟิลด์
metadata
ของสคีมาโมเดล TFLite
ภายใต้ชื่อ "TFLITE_METADATA" โมเดลบางรุ่นอาจมาพร้อมกับไฟล์ที่เกี่ยวข้อง
เช่น ไฟล์ป้ายกำกับการแยกประเภท
ระบบจะต่อท้ายไฟล์เหล่านี้ไว้ที่ท้ายไฟล์โมเดลต้นฉบับเป็นไฟล์ ZIP
โดยใช้โหมด "append"
ของ ZipFile (โหมด 'a') TFLite
Interpreter สามารถใช้รูปแบบไฟล์ใหม่ได้ในลักษณะเดียวกับก่อนหน้า ดูข้อมูลเพิ่มเติมได้ที่แพ็ก
ไฟล์ที่เกี่ยวข้อง
ดูวิธีการป้อนข้อมูล แสดงภาพ และอ่านข้อมูลเมตาได้ที่คำสั่งด้านล่าง
ตั้งค่าเครื่องมือข้อมูลเมตา
ก่อนที่จะเพิ่มข้อมูลเมตาลงในโมเดล คุณจะต้องตั้งค่าสภาพแวดล้อมการเขียนโปรแกรม Python เพื่อเรียกใช้ TensorFlow ดูคำแนะนำโดยละเอียดเกี่ยวกับวิธี ตั้งค่านี้ได้ที่นี่
หลังจากตั้งค่าสภาพแวดล้อมการเขียนโปรแกรม Python แล้ว คุณจะต้องติดตั้ง เครื่องมือเพิ่มเติม
pip install tflite-support
เครื่องมือข้อมูลเมตา LiteRT รองรับ Python 3
การเพิ่มข้อมูลเมตาโดยใช้ Flatbuffers Python API
ข้อมูลเมตาของโมเดลในสคีมามี 3 ส่วน ดังนี้
- ข้อมูลโมเดล - รายละเอียดโดยรวมของโมเดลและรายการต่างๆ เช่น ข้อกำหนดของใบอนุญาต ดู ModelMetadata 2. ข้อมูลอินพุต - คำอธิบายของอินพุตและการประมวลผลล่วงหน้า ที่จำเป็น เช่น การปรับให้เป็นมาตรฐาน ดู SubGraphMetadata.input_tensor_metadata 3. ข้อมูลเอาต์พุต - คำอธิบายของเอาต์พุตและ การประมวลผลภายหลังที่จำเป็น เช่น การแมปกับป้ายกำกับ ดู SubGraphMetadata.output_tensor_metadata
เนื่องจากขณะนี้ LiteRT รองรับเฉพาะกราฟย่อยเดียว ตัวสร้างโค้ด LiteRT
และฟีเจอร์การเชื่อมโยง ML ของ Android Studio
จะใช้ ModelMetadata.name และ ModelMetadata.description แทน SubGraphMetadata.name และ SubGraphMetadata.description เมื่อแสดงข้อมูลเมตาและสร้างโค้ด
ประเภทอินพุต / เอาต์พุตที่รองรับ
ข้อมูลเมตา LiteRT สำหรับอินพุตและเอาต์พุตไม่ได้ออกแบบมาโดยคำนึงถึงประเภทโมเดลที่เฉพาะเจาะจง แต่คำนึงถึงประเภทอินพุตและเอาต์พุต ไม่ว่าโมเดลจะทำหน้าที่อะไรก็ตาม ตราบใดที่ประเภทอินพุตและเอาต์พุตประกอบด้วยรายการต่อไปนี้หรือการรวมกันของรายการต่อไปนี้ โมเดลนั้นจะได้รับการรองรับโดยข้อมูลเมตาของ TensorFlow Lite
- ฟีเจอร์ - ตัวเลขที่เป็นจำนวนเต็มที่ไม่มีเครื่องหมายหรือ float32
- รูปภาพ - ปัจจุบันข้อมูลเมตารองรับรูปภาพ RGB และรูปภาพระดับสีเทา
- กรอบล้อมรอบ - กรอบล้อมรอบรูปสี่เหลี่ยมผืนผ้า สคีมารองรับรูปแบบการ กำหนดหมายเลข ที่หลากหลาย
แพ็กไฟล์ที่เกี่ยวข้อง
โมเดล LiteRT อาจมาพร้อมกับไฟล์ที่เกี่ยวข้องที่แตกต่างกัน เช่น โมเดลภาษาธรรมชาติมักจะมีไฟล์คำศัพท์ที่เชื่อมโยงชิ้นส่วนคำกับรหัสคำ โมเดลการจัดประเภทอาจมีไฟล์ป้ายกำกับที่ระบุหมวดหมู่วัตถุ หากไม่มีไฟล์ที่เชื่อมโยง (หากมี) โมเดลจะทำงานได้ไม่ดี
ตอนนี้คุณสามารถรวมไฟล์ที่เกี่ยวข้องกับโมเดลผ่านไลบรารีข้อมูลเมตา
Python ได้แล้ว โมเดล LiteRT ใหม่จะกลายเป็นไฟล์ ZIP ที่มีทั้งโมเดลและไฟล์ที่เกี่ยวข้อง โดยสามารถคลายแพ็กได้ด้วยเครื่องมือ ZIP ทั่วไป รูปแบบโมเดลใหม่นี้ยังคงใช้นามสกุลไฟล์เดิมคือ .tflite ซึ่ง
ใช้งานร่วมกับเฟรมเวิร์ก TFLite และ Interpreter ที่มีอยู่ได้ ดูรายละเอียดเพิ่มเติมได้ที่แพ็กข้อมูลเมตา
และไฟล์ที่เกี่ยวข้องลงใน
โมเดล
คุณบันทึกข้อมูลไฟล์ที่เชื่อมโยงไว้ในข้อมูลเมตาได้ เครื่องมือสร้างโค้ด Android ของ LiteRT อาจใช้การประมวลผลล่วงหน้า/หลังที่เกี่ยวข้องกับออบเจ็กต์โดยอัตโนมัติ ทั้งนี้ขึ้นอยู่กับ
ประเภทไฟล์และตำแหน่งที่แนบไฟล์ (เช่น ModelMetadata
SubGraphMetadata และ TensorMetadata) ดูรายละเอียดเพิ่มเติมได้ที่ส่วน <Codegen usage> ของ
แต่ละไฟล์ที่เกี่ยวข้อง
ประเภท
ในสคีมา
พารามิเตอร์การทําให้เป็นมาตรฐานและการหาปริมาณ
การปรับให้เป็นมาตรฐานเป็นเทคนิคการประมวลผลข้อมูลเบื้องต้นที่ใช้กันทั่วไปในแมชชีนเลิร์นนิง เป้าหมายของการปรับให้เป็นมาตรฐานคือการเปลี่ยนค่าให้อยู่ในมาตราส่วนทั่วไปโดยไม่ บิดเบือนความแตกต่างในค่าช่วงต่างๆ
การกำหนดปริมาณโมเดลเป็นเทคนิค ที่ช่วยให้แสดงค่าความแม่นยำที่ลดลงของน้ำหนัก และเลือกได้ การเปิดใช้งานทั้งสำหรับการจัดเก็บและการคำนวณ
ในส่วนของการประมวลผลล่วงหน้าและการประมวลผลภายหลัง การปรับให้เป็นมาตรฐานและการหาปริมาณ เป็น 2 ขั้นตอนที่เป็นอิสระ ตามรายละเอียดดังนี้
| การแปลงเป็นรูปแบบมาตรฐาน | การควอนไทซ์ | |
|---|---|---|
ตัวอย่างค่าพารามิเตอร์ของ รูปภาพอินพุตใน MobileNet สำหรับโมเดล แบบลอยและแบบ ควอนไทซ์ตามลำดับ |
โมเดล Float: - mean: 127.5 - std: 127.5 โมเดล Quant: - mean: 127.5 - std: 127.5 |
โมเดล Float: - zeroPoint: 0 - scale: 1.0 โมเดล Quant: - zeroPoint: 128.0 - scale:0.0078125f |
กรณีที่ควรเรียกใช้ |
อินพุต: หากข้อมูลอินพุต ได้รับการแปลงเป็นรูปแบบมาตรฐานใน การฝึก ข้อมูลอินพุต ของการอนุมานจะต้อง ได้รับการแปลงเป็นรูปแบบมาตรฐาน ตามนั้น เอาต์พุต: โดยทั่วไปแล้ว ระบบจะไม่ ทําให้ข้อมูล เอาต์พุตเป็นมาตรฐาน |
โมเดลแบบลอยตัวไม่จำเป็นต้องมีการหาปริมาณ โมเดลที่แปลงให้เล็กลงอาจ หรือไม่จำเป็นต้อง แปลงให้เล็กลงใน การประมวลผลก่อน/หลัง ขึ้นอยู่กับประเภทข้อมูลของ อินพุต/เอาต์พุตเทนเซอร์ - เทนเซอร์แบบลอย: ไม่จำเป็นต้อง มีการวัดปริมาณใน การประมวลผลล่วงหน้า/หลัง Quant op และ dequant op จะ รวมอยู่ในโมเดล กราฟ - เทนเซอร์ int8/uint8: ต้องมีการวัดปริมาณใน การประมวลผลก่อน/หลัง |
สูตร |
normalized_input = (input - mean) / std |
การหาปริมาณสำหรับอินพุต
q = f / scale + zeroPoint การยกเลิกการหาปริมาณสำหรับเอาต์พุต f = (q - zeroPoint) * scale |
พารามิเตอร์อยู่ที่ใด |
กรอกโดยผู้สร้างโมเดล
และจัดเก็บไว้ในข้อมูลเมตาของโมเดล
เป็น
NormalizationOptions |
กรอกโดยตัวแปลง TFLite โดยอัตโนมัติและจัดเก็บไว้ในไฟล์โมเดล tflite |
| วิธีรับ พารามิเตอร์ | ผ่านMetadataExtractor API
[2]
|
ผ่าน TFLite
Tensor API [1] หรือ
ผ่าน
MetadataExtractor API
[2] |
| โมเดล Float และ Quant มีค่าเดียวกันไหม | ใช่ โมเดล float และ quant มีพารามิเตอร์ การทำให้เป็นมาตรฐาน เหมือนกัน | ไม่ โมเดลทศนิยมไม่จำเป็นต้องมีการวัดปริมาณ |
| TFLite Code generator หรือ Android Studio ML binding สร้างโดยอัตโนมัติ ในการประมวลผลข้อมูลไหม | ใช่ |
ใช่ |
[1] LiteRT Java
API
และ LiteRT C++
API
[2] ไลบรารีโปรแกรมแยกข้อมูลเมตา
เมื่อประมวลผลข้อมูลรูปภาพสำหรับโมเดล uint8 บางครั้งระบบจะข้ามการทําให้เป็นมาตรฐานและการหาปริมาณ คุณทำเช่นนั้นได้เมื่อค่าพิกเซลอยู่ในช่วง [0, 255] แต่โดยทั่วไป คุณควรประมวลผลข้อมูลตามพารามิเตอร์การปรับให้เป็นมาตรฐานและการหาปริมาณเสมอเมื่อมี
ตัวอย่าง
ดูตัวอย่างวิธีป้อนข้อมูลเมตาสำหรับโมเดลประเภทต่างๆ ได้ที่นี่
การจัดประเภทรูปภาพ
ดาวน์โหลดสคริปต์ที่นี่ ซึ่งจะสร้างข้อมูลเมตาใน mobilenet_v1_0.75_160_quantized.tflite เรียกใช้สคริปต์ดังนี้
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
หากต้องการป้อนข้อมูลเมตาสำหรับโมเดลการแยกประเภทรูปภาพอื่นๆ ให้เพิ่มข้อมูลจำเพาะของโมเดล เช่น นี้ ลงในสคริปต์ ส่วนที่เหลือของคู่มือนี้จะไฮไลต์ส่วนสำคัญบางส่วน ในตัวอย่างการจัดหมวดหมู่รูปภาพเพื่อแสดงองค์ประกอบสำคัญ
เจาะลึกตัวอย่างการแยกประเภทรูปภาพ
ข้อมูลรุ่น
ข้อมูลเมตาเริ่มต้นด้วยการสร้างข้อมูลโมเดลใหม่ ดังนี้
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
ข้อมูลอินพุต / เอาต์พุต
ส่วนนี้จะแสดงวิธีอธิบายลายเซ็นอินพุตและเอาต์พุตของโมเดล เครื่องมือสร้างโค้ดอัตโนมัติอาจใช้ข้อมูลเมตานี้เพื่อสร้างโค้ดก่อนและหลัง การประมวลผล วิธีสร้างข้อมูลอินพุตหรือเอาต์พุตเกี่ยวกับเทนเซอร์
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
การป้อนรูปภาพ
รูปภาพเป็นประเภทอินพุตทั่วไปสำหรับแมชชีนเลิร์นนิง ข้อมูลเมตา LiteRT รองรับข้อมูล เช่น ข้อมูลพื้นที่สีและการประมวลผลล่วงหน้า เช่น การปรับให้เป็นมาตรฐาน คุณไม่จำเป็นต้องระบุขนาดของรูปภาพด้วยตนเอง เนื่องจากรูปร่างของเทนเซอร์อินพุตจะระบุขนาดไว้แล้วและระบบจะ อนุมานขนาดโดยอัตโนมัติ
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
เอาต์พุตป้ายกำกับ
คุณสามารถแมปป้ายกำกับกับเอาต์พุตเทนเซอร์ผ่านไฟล์ที่เชื่อมโยงโดยใช้
TENSOR_AXIS_LABELS
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
สร้าง Flatbuffers ของข้อมูลเมตา
โค้ดต่อไปนี้จะรวมข้อมูลโมเดลกับข้อมูลอินพุตและเอาต์พุต
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
แพ็กข้อมูลเมตาและไฟล์ที่เกี่ยวข้องลงในโมเดล
เมื่อสร้าง Flatbuffers ของข้อมูลเมตาแล้ว ระบบจะเขียนข้อมูลเมตาและไฟล์ป้ายกำกับลงในไฟล์ TFLite ผ่านเมธอด populate
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
คุณสามารถแพ็กไฟล์ที่เกี่ยวข้องได้มากเท่าที่ต้องการลงในโมเดลผ่าน
load_associated_files อย่างไรก็ตาม คุณต้องแพ็กไฟล์เหล่านั้นอย่างน้อย
ตามที่ระบุไว้ในข้อมูลเมตา ในตัวอย่างนี้ การแพ็กไฟล์ป้ายกำกับเป็น
ข้อบังคับ
แสดงภาพข้อมูลเมตา
คุณใช้ Netron เพื่อแสดงภาพข้อมูลเมตา หรือจะอ่านข้อมูลเมตาจากโมเดล LiteRT เป็นรูปแบบ JSON โดยใช้ MetadataDisplayer ก็ได้
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio ยังรองรับการแสดงข้อมูลเมตาผ่านฟีเจอร์การเชื่อมโยง ML ของ Android Studio ด้วย
การกำหนดเวอร์ชันของข้อมูลเมตา
สคีมา ข้อมูลเมตา ได้รับการกำหนดเวอร์ชันทั้งตามหมายเลขการกำหนดเวอร์ชันเชิงความหมาย ซึ่งติดตามการเปลี่ยนแปลงของ ไฟล์สคีมา และตามการระบุไฟล์ Flatbuffers ซึ่งบ่งบอกถึง ความเข้ากันได้ของเวอร์ชันที่แท้จริง
หมายเลขการกำหนดเวอร์ชันทางอรรถศาสตร์
สคีมาข้อมูลเมตาจะได้รับการกำหนดเวอร์ชันโดยหมายเลขการกำหนดเวอร์ชันทางอรรถศาสตร์
เช่น MAJOR.MINOR.PATCH โดยจะติดตามการเปลี่ยนแปลงสคีมาตามกฎ
ที่นี่
ดูประวัติของ
ฟิลด์
ที่เพิ่มหลังจากเวอร์ชัน 1.0.0
การระบุไฟล์ Flatbuffers
การกำหนดเวอร์ชันเชิงความหมายรับประกันความเข้ากันได้หากปฏิบัติตามกฎ แต่ไม่ได้หมายความว่าไม่มีความเข้ากันได้จริง การเพิ่มหมายเลข MAJOR ไม่ได้หมายความว่าความเข้ากันได้แบบย้อนหลังจะเสียเสมอไป ดังนั้น เราจึงใช้การระบุไฟล์ Flatbuffers file_identifier เพื่อระบุความเข้ากันได้ที่แท้จริงของสคีมาข้อมูลเมตา ตัวระบุไฟล์ต้องมีความยาว 4 อักขระ โดยจะยึดตามสคีมาข้อมูลเมตาที่แน่นอนและผู้ใช้ไม่สามารถเปลี่ยนแปลงได้ หากต้องหยุดความเข้ากันได้แบบย้อนหลังของสคีมาข้อมูลเมตา ด้วยเหตุผลบางประการ ตัวระบุไฟล์จะเพิ่มขึ้น เช่น จาก "M001" เป็น "M002" คาดว่าตัวระบุไฟล์จะมีการเปลี่ยนแปลงน้อยกว่า metadata_version มาก
เวอร์ชันของเครื่องมือแยกวิเคราะห์ข้อมูลเมตาที่จำเป็นขั้นต่ำ
เวอร์ชันตัวแยกวิเคราะห์ข้อมูลเมตาขั้นต่ำที่จำเป็น
คือเวอร์ชันขั้นต่ำของตัวแยกวิเคราะห์ข้อมูลเมตา (โค้ดที่สร้างโดย Flatbuffers) ที่
อ่าน Flatbuffers ของข้อมูลเมตาได้ทั้งหมด เวอร์ชันนี้คือหมายเลขเวอร์ชันที่ใหญ่ที่สุดในบรรดาเวอร์ชันของฟิลด์ทั้งหมดที่ป้อนข้อมูล และเป็นเวอร์ชันที่เข้ากันได้น้อยที่สุดซึ่งระบุโดยตัวระบุไฟล์ MetadataPopulator จะสร้างเวอร์ชันโปรแกรมแยกวิเคราะห์ข้อมูลเมตาที่จำเป็นขั้นต่ำโดยอัตโนมัติ
เมื่อมีการสร้างข้อมูลเมตาลงในโมเดล TFLite ดูข้อมูลเพิ่มเติมเกี่ยวกับวิธีใช้
เวอร์ชันโปรแกรมแยกวิเคราะห์ข้อมูลเมตาที่จำเป็นขั้นต่ำได้ที่
โปรแกรมแยกวิเคราะห์ข้อมูลเมตา
อ่านข้อมูลเมตาจากโมเดล
ไลบรารีโปรแกรมแยกข้อมูลเมตาเป็นเครื่องมือที่สะดวกในการอ่านข้อมูลเมตาและ ไฟล์ที่เชื่อมโยงจากโมเดลในแพลตฟอร์มต่างๆ (ดูเวอร์ชัน Java และเวอร์ชัน C++) คุณสร้างเครื่องมือแยกข้อมูลเมตาของคุณเองในภาษาอื่นๆ ได้โดยใช้ ไลบรารี Flatbuffers
อ่านข้อมูลเมตาใน Java
หากต้องการใช้ไลบรารีโปรแกรมแยกข้อมูลเมตาในแอป Android เราขอแนะนำให้ใช้ AAR ข้อมูลเมตา LiteRT ที่โฮสต์ใน
MavenCentral
ซึ่งมีคลาส MetadataExtractor รวมถึงการเชื่อมโยง FlatBuffers Java
สำหรับสคีมาข้อมูลเมตา
และสคีมาโมเดล
คุณระบุได้ในทรัพยากร Dependency ของ build.gradle ดังนี้
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
หากต้องการใช้สแนปชอตรายคืน โปรดตรวจสอบว่าคุณได้เพิ่มที่เก็บสแนปชอตของ Sonatype แล้ว
คุณสามารถเริ่มต้นMetadataExtractorออบเจ็กต์ด้วยByteBufferที่ชี้
ไปยังโมเดลได้โดยทำดังนี้
public MetadataExtractor(ByteBuffer buffer);
ByteBuffer ต้องไม่เปลี่ยนแปลงตลอดอายุการใช้งานของออบเจ็กต์ MetadataExtractor การเริ่มต้นอาจล้มเหลวหากตัวระบุไฟล์ Flatbuffers
ของข้อมูลเมตาของโมเดลไม่ตรงกับตัวระบุของเครื่องมือแยกวิเคราะห์ข้อมูลเมตา ดูข้อมูลเพิ่มเติมได้ที่การควบคุมเวอร์ชันของข้อมูลเมตา
เมื่อใช้ตัวระบุไฟล์ที่ตรงกัน ตัวแยกข้อมูลเมตาจะอ่านข้อมูลเมตาที่สร้างจากสคีมาทั้งหมดในอดีตและอนาคตได้สำเร็จ เนื่องจากกลไกการทำงานของ Flatbuffers ที่รองรับการทำงานร่วมกันทั้งแบบย้อนกลับและไปข้างหน้า อย่างไรก็ตาม เครื่องมือแยกข้อมูลเมตาเวอร์ชันเก่าจะแยกฟิลด์จากสคีมาในอนาคตไม่ได้ เวอร์ชันของโปรแกรมแยกวิเคราะห์ข้อมูลเมตาขั้นต่ำที่จำเป็นจะระบุเวอร์ชันขั้นต่ำของโปรแกรมแยกวิเคราะห์ข้อมูลเมตาที่อ่าน Flatbuffers ของข้อมูลเมตา ได้ทั้งหมด คุณสามารถใช้วิธีต่อไปนี้เพื่อตรวจสอบว่าตรงตามเงื่อนไขของเวอร์ชันตัวแยกวิเคราะห์ขั้นต่ำที่จำเป็นหรือไม่
public final boolean isMinimumParserVersionSatisfied();
อนุญาตให้ส่งโมเดลโดยไม่มีข้อมูลเมตา อย่างไรก็ตาม การเรียกใช้เมธอดที่
อ่านจากข้อมูลเมตาจะทำให้เกิดข้อผิดพลาดรันไทม์ คุณตรวจสอบได้ว่าโมเดลมี
ข้อมูลเมตาหรือไม่โดยเรียกใช้เมธอด hasMetadata
public boolean hasMetadata();
MetadataExtractor มีฟังก์ชันที่สะดวกเพื่อให้คุณได้รับข้อมูลเมตาของเทนเซอร์อินพุต/เอาต์พุต
ตัวอย่างเช่น
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
แม้ว่าโมเดล LiteRT
schema
จะรองรับกราฟย่อยหลายรายการ แต่ปัจจุบัน TFLite Interpreter รองรับเฉพาะกราฟย่อยรายการเดียว ดังนั้น MetadataExtractorจึงละเว้นดัชนีกราฟย่อยเป็นอาร์กิวเมนต์อินพุต
ในเมธอด
อ่านไฟล์ที่เชื่อมโยงจากโมเดล
โมเดล LiteRT ที่มีข้อมูลเมตาและไฟล์ที่เชื่อมโยงนั้นเป็นไฟล์ ZIP ที่สามารถคลายซิปด้วยเครื่องมือ ZIP ทั่วไปเพื่อรับไฟล์ที่เชื่อมโยง ตัวอย่างเช่น คุณสามารถคลายซิป mobilenet_v1_0.75_160_quantized และแยกไฟล์ป้ายกำกับในโมเดลได้ดังนี้
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
นอกจากนี้ คุณยังอ่านไฟล์ที่เชื่อมโยงผ่านไลบรารี Metadata Extractor ได้ด้วย
ใน Java ให้ส่งชื่อไฟล์ไปยังเมธอด MetadataExtractor.getAssociatedFile
public InputStream getAssociatedFile(String fileName);
ในทำนองเดียวกัน ใน C++ คุณสามารถทำได้ด้วยเมธอด
ModelMetadataExtractor::GetAssociatedFile:
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;