
LiteRT-Metadaten bieten einen Standard für Modellbeschreibungen. Die Metadaten sind eine wichtige Wissensquelle darüber, was das Modell tut, und enthalten Informationen zu seinen Ein- und Ausgaben. Die Metadaten bestehen aus
- für Menschen lesbare Teile, die die Best Practice für die Verwendung des Modells vermitteln, und
- maschinenlesbare Teile, die von Codegeneratoren wie dem LiteRT Android-Codegenerator und der Android Studio ML-Bindungsfunktion genutzt werden können.
Alle Bildmodelle, die in Kaggle Models veröffentlicht wurden, enthalten Metadaten.
Modell mit Metadatenformat
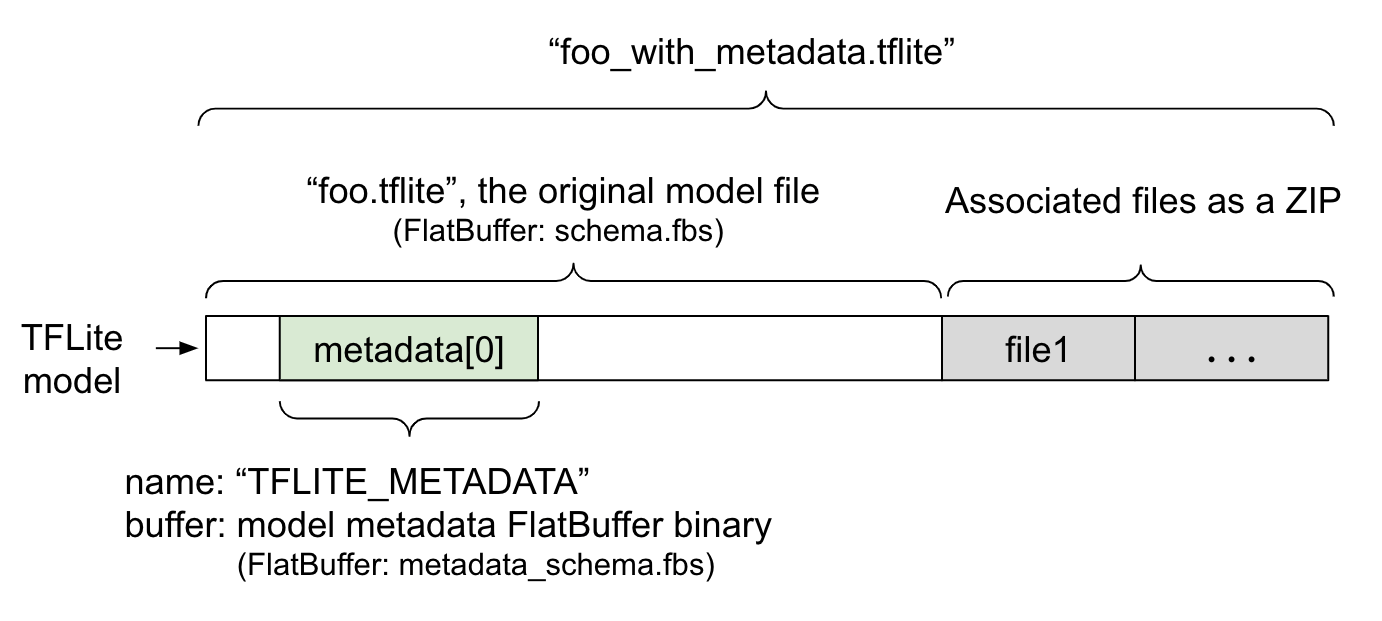
Modellmetadaten werden in metadata_schema.fbs definiert, einer FlatBuffer-Datei. Wie in Abbildung 1 dargestellt, wird sie im Feld metadata des TFLite-Modellschemas unter dem Namen "TFLITE_METADATA" gespeichert. Einige Modelle haben möglicherweise zugehörige Dateien, z. B. Dateien mit Klassifizierungslabeln.
Diese Dateien werden als ZIP-Datei mit dem ZipFile-Modus „append“ ('a'-Modus) an das Ende der ursprünglichen Modelldatei angehängt. Der TFLite-Interpreter kann das neue Dateiformat wie bisher verwenden. Weitere Informationen finden Sie unter Zugehörige Dateien packen.
Unten finden Sie eine Anleitung dazu, wie Sie Metadaten einfügen, visualisieren und lesen.
Metadatentools einrichten
Bevor Sie Ihrem Modell Metadaten hinzufügen, müssen Sie eine Python-Programmierumgebung für die Ausführung von TensorFlow einrichten. Hier findest du eine detaillierte Anleitung.
Nachdem Sie die Python-Programmierumgebung eingerichtet haben, müssen Sie zusätzliche Tools installieren:
pip install tflite-support
Die LiteRT-Metadatentools unterstützen Python 3.
Metadaten mit der Flatbuffers Python API hinzufügen
Die Modellmetadaten im Schema bestehen aus drei Teilen:
- Modellinformationen: Allgemeine Beschreibung des Modells sowie Elemente wie Lizenzbedingungen. Weitere Informationen finden Sie unter ModelMetadata. 2. Eingabeinformationen: Beschreibung der erforderlichen Eingaben und Vorverarbeitung, z. B. Normalisierung. Weitere Informationen finden Sie unter SubGraphMetadata.input_tensor_metadata. 3. Ausgabeinformationen: Beschreibung der Ausgabe und der erforderlichen Nachbearbeitung, z. B. Zuordnung zu Labels. Weitere Informationen finden Sie unter SubGraphMetadata.output_tensor_metadata.
Da LiteRT derzeit nur einzelne Untergraphen unterstützt, verwenden der LiteRT-Codegenerator und die Android Studio ML Binding-Funktion beim Anzeigen von Metadaten und Generieren von Code ModelMetadata.name und ModelMetadata.description anstelle von SubGraphMetadata.name und SubGraphMetadata.description.
Unterstützte Ein- und Ausgabetypen
LiteRT-Metadaten für Ein- und Ausgabe sind nicht für bestimmte Modelltypen, sondern für Ein- und Ausgabetypen konzipiert. Es spielt keine Rolle, was das Modell funktional tut, solange die Ein- und Ausgabetypen aus den folgenden oder einer Kombination der folgenden bestehen. Sie werden von TensorFlow Lite-Metadaten unterstützt:
- Feature: Zahlen, die vorzeichenlose Ganzzahlen oder float32 sind.
- Bild: Metadaten unterstützen derzeit RGB- und Graustufenbilder.
- Begrenzungsrahmen – Rechteckige Begrenzungsrahmen. Das Schema unterstützt verschiedene Nummerierungsschemata.
Zugehörige Dateien packen
LiteRT-Modelle können mit verschiedenen zugehörigen Dateien geliefert werden. Natürliche Sprachmodelle haben beispielsweise in der Regel Vokabeldateien, in denen Wortteile Wort-IDs zugeordnet werden. Klassifizierungsmodelle können Labeldateien haben, die Objektkategorien angeben. Ohne die zugehörigen Dateien (falls vorhanden) funktioniert ein Modell nicht gut.
Die zugehörigen Dateien können jetzt über die Python-Bibliothek für Metadaten mit dem Modell gebündelt werden. Das neue LiteRT-Modell wird zu einer ZIP-Datei, die sowohl das Modell als auch die zugehörigen Dateien enthält. Sie kann mit gängigen ZIP-Tools entpackt werden. Für dieses neue Modellformat wird weiterhin die Dateiendung .tflite verwendet. Es ist mit dem vorhandenen TFLite-Framework und -Interpreter kompatibel. Weitere Informationen finden Sie unter Metadaten und zugehörige Dateien in das Modell einfügen.
Die zugehörigen Dateiinformationen können in den Metadaten aufgezeichnet werden. Je nach Dateityp und Ort, an dem die Datei angehängt ist (d.h. ModelMetadata, SubGraphMetadata und TensorMetadata), wendet der LiteRT-Android-Codegenerator möglicherweise automatisch eine entsprechende Vor-/Nachbearbeitung auf das Objekt an. Weitere Informationen finden Sie im Schema im Abschnitt Codegenerierung für jeden zugehörigen Dateityp.
Parameter für Normalisierung und Quantisierung
Die Normalisierung ist eine gängige Methode zur Vorverarbeitung von Daten beim maschinellen Lernen. Ziel der Normalisierung ist es, die Werte auf eine gemeinsame Skala zu bringen, ohne die Unterschiede in den Wertebereichen zu verzerren.
Die Modellquantisierung ist eine Technik, die eine Darstellung von Gewichten mit reduzierter Genauigkeit und optional auch von Aktivierungen für Speicher und Berechnung ermöglicht.
Bei der Vor- und Nachbearbeitung sind Normalisierung und Quantisierung zwei unabhängige Schritte. Ausführliche Informationen zum Problem:
| Normalisierung | Quantisierung | |
|---|---|---|
Beispiel für die Parameterwerte des Eingabebilds in MobileNet für Float- und Quant-Modelle. |
Gleitkommamodell: - Mittelwert: 127,5 - Standardabweichung: 127,5 Quantisiertes Modell: - Mittelwert: 127,5 - Standardabweichung: 127,5 |
Gleitkommamodell: - zeroPoint: 0 - scale: 1.0 Quantisiertes Modell: - zeroPoint: 128.0 - scale:0.0078125f |
Wann sollte die Funktion aufgerufen werden? |
Eingaben: Wenn Eingabedaten beim Training normalisiert werden, müssen die Eingabedaten für die Inferenz entsprechend normalisiert werden. Ausgaben: Ausgabedaten werden im Allgemeinen nicht normalisiert. |
Gleitkommamodelle müssen nicht quantisiert werden. Quantisiertes Modell erfordert möglicherweise eine Quantisierung bei der Vor-/Nachbearbeitung. Das hängt vom Datentyp der Ein-/Ausgabetensoren ab. - Gleitkommatensoren: Für die Vor- und Nachbearbeitung ist keine Quantisierung erforderlich. Quant- und Dequant-Vorgänge sind im Modellgraphen enthalten. - int8-/uint8-Tensoren: Erfordern eine Quantisierung in der Vor-/Nachbearbeitung. |
Formel |
normalized_input = (input - mean) / std |
Quantisierung für Eingaben:
q = f / scale + zeroPoint Dequantisierung für Ausgaben: f = (q – zeroPoint) * scale |
Wo finde ich die Parameter? |
Wird vom Modellentwickler ausgefüllt und in den Modellmetadaten als NormalizationOptions gespeichert. |
Wird automatisch vom TFLite-Converter ausgefüllt und in der TFLite-Modelldatei gespeichert. |
| So rufen Sie die Parameter ab | Über die MetadataExtractor API[2]
|
Über die TFLite-Tensor-API [1] oder die MetadataExtractor-API [2] |
| Haben Float- und Quant-Modelle denselben Wert? | Ja, Float- und Quant-Modelle haben dieselben Normalisierungsparameter. | Nein, das Float-Modell muss nicht quantisiert werden. |
| Wird es automatisch bei der Datenverarbeitung durch den TFLite-Codegenerator oder die Android Studio ML-Bindung generiert? | Ja |
Ja |
[1] Die LiteRT Java API und die LiteRT C++ API.
[2] Die Bibliothek zum Extrahieren von Metadaten
Bei der Verarbeitung von Bilddaten für uint8-Modelle werden Normalisierung und Quantisierung manchmal übersprungen. Das ist in Ordnung, wenn die Pixelwerte im Bereich [0, 255] liegen. Im Allgemeinen sollten Sie die Daten jedoch immer gemäß den Normalisierungs- und Quantisierungsparametern verarbeiten, sofern zutreffend.
Beispiele
Hier finden Sie Beispiele dafür, wie die Metadaten für verschiedene Arten von Modellen ausgefüllt werden sollten:
Bildklassifizierung
Laden Sie das Script hier herunter, mit dem Metadaten für mobilenet_v1_0.75_160_quantized.tflite eingefügt werden. Führen Sie das Skript so aus:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
Wenn Sie Metadaten für andere Bildklassifizierungsmodelle einfügen möchten, fügen Sie die Modellspezifikationen wie diese in das Skript ein. Im Rest dieser Anleitung werden einige der wichtigsten Abschnitte im Beispiel für die Bildklassifizierung hervorgehoben, um die wichtigsten Elemente zu veranschaulichen.
Detaillierte Informationen zum Beispiel für die Bildklassifizierung
Modellinformationen
Metadaten beginnen mit dem Erstellen von neuen Modellinformationen:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
Informationen zu Ein- und Ausgabe
In diesem Abschnitt wird beschrieben, wie Sie die Ein- und Ausgabesignatur Ihres Modells beschreiben. Diese Metadaten können von automatischen Codegeneratoren verwendet werden, um Code für die Vor- und Nachbearbeitung zu erstellen. So erstellen Sie Eingabe- oder Ausgabedaten zu einem Tensor:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
Bildeingabe
Bilder sind ein gängiger Eingabetyp für maschinelles Lernen. LiteRT-Metadaten unterstützen Informationen wie Farbraum und Vorverarbeitungsinformationen wie Normalisierung. Die Dimension des Bildes muss nicht manuell angegeben werden, da sie bereits durch die Form des Eingabetensors bereitgestellt und automatisch abgeleitet werden kann.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
Labelausgabe
Das Label kann über eine zugehörige Datei mit TENSOR_AXIS_LABELS einem Ausgabetensor zugeordnet werden.
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
Flatbuffers für Metadaten erstellen
Im folgenden Code werden die Modellinformationen mit den Ein- und Ausgabedaten kombiniert:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
Metadaten und zugehörige Dateien in das Modell einfügen
Sobald die Flatbuffers für die Metadaten erstellt wurden, werden die Metadaten und die Labeldatei über die Methode populate in die TFLite-Datei geschrieben:
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
Sie können beliebig viele zugehörige Dateien über load_associated_files in das Modell einfügen. Es ist jedoch erforderlich, mindestens die in den Metadaten dokumentierten Dateien zu packen. In diesem Beispiel ist das Packen der Labeldatei obligatorisch.
Metadaten visualisieren
Sie können Netron verwenden, um Ihre Metadaten zu visualisieren, oder die Metadaten aus einem LiteRT-Modell mit dem MetadataDisplayer in ein JSON-Format lesen:
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio unterstützt auch die Anzeige von Metadaten über die Android Studio ML Binding-Funktion.
Versionsverwaltung von Metadaten
Das Metadatenschema wird sowohl durch die semantische Versionsnummer, die die Änderungen der Schemadatei nachverfolgt, als auch durch die Flatbuffers-Datei-ID, die die tatsächliche Versionskompatibilität angibt, versioniert.
Die semantische Versionsnummer
Das Metadatenschema wird mit der semantischen Versionsnummer wie HAUPTVERSION.NEBENVERSION.PATCH versioniert. Es werden Schemaänderungen gemäß den Regeln hier erfasst.
Verlauf der Felder, die nach Version 1.0.0 hinzugefügt wurden
Die Flatbuffers-Datei-ID
Die semantische Versionierung garantiert die Kompatibilität, wenn die Regeln eingehalten werden, impliziert aber nicht die tatsächliche Inkompatibilität. Wenn die HAUPTversionsnummer erhöht wird, bedeutet das nicht unbedingt, dass die Abwärtskompatibilität nicht mehr gegeben ist. Daher verwenden wir die Flatbuffers-Dateiidentifikation, file_identifier, um die tatsächliche Kompatibilität des Metadatenschemas anzugeben. Die Datei-ID ist genau 4 Zeichen lang. Sie ist an ein bestimmtes Metadatenschema gebunden und kann von Nutzern nicht geändert werden. Wenn die Abwärtskompatibilität des Metadatenschemas aus irgendeinem Grund unterbrochen werden muss, wird der file_identifier erhöht, z. B. von „M001“ auf „M002“. Der file_identifier wird voraussichtlich viel seltener geändert als die metadata_version.
Die mindestens erforderliche Version des Metadaten-Parsers
Die mindestens erforderliche Version des Metadaten-Parsers ist die Mindestversion des Metadaten-Parsers (der von Flatbuffers generierte Code), mit der die Metadaten-Flatbuffers vollständig gelesen werden können. Die Version ist im Grunde die größte Versionsnummer unter den Versionen aller ausgefüllten Felder und die kleinste kompatible Version, die durch die Dateikennung angegeben wird. Die erforderliche Mindestversion des Metadaten-Parsers wird automatisch von MetadataPopulator ausgefüllt, wenn die Metadaten in ein TFLite-Modell eingefügt werden. Weitere Informationen zur Verwendung der erforderlichen Mindestversion des Metadaten-Parsers finden Sie unter Metadaten-Extractor.
Metadaten aus Modellen lesen
Die Metadata Extractor-Bibliothek ist ein praktisches Tool zum Lesen der Metadaten und zugehörigen Dateien von Modellen auf verschiedenen Plattformen (siehe die Java-Version und die C++-Version). Sie können Ihr eigenes Tool zum Extrahieren von Metadaten in anderen Sprachen mit der Flatbuffers-Bibliothek erstellen.
Metadaten in Java lesen
Wenn Sie die Metadata Extractor-Bibliothek in Ihrer Android-App verwenden möchten, empfehlen wir die Verwendung des LiteRT-Metadaten-AAR, das bei MavenCentral gehostet wird.
Sie enthält die Klasse MetadataExtractor sowie die FlatBuffers-Java-Bindungen für das Metadatenschema und das Modellschema.
Sie können dies in Ihren build.gradle-Abhängigkeiten so angeben:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
Wenn Sie Nightly Snapshots verwenden möchten, müssen Sie das Sonatype-Snapshot-Repository hinzufügen.
Sie können ein MetadataExtractor-Objekt mit einem ByteBuffer initialisieren, der auf das Modell verweist:
public MetadataExtractor(ByteBuffer buffer);
Der ByteBuffer muss während der gesamten Lebensdauer des MetadataExtractor-Objekts unverändert bleiben. Die Initialisierung kann fehlschlagen, wenn die Flatbuffers-Datei-ID der Modellmetadaten nicht mit der des Metadaten-Parsers übereinstimmt. Weitere Informationen finden Sie unter Versionsverwaltung von Metadaten.
Mit übereinstimmenden Dateikennungen kann der Metadaten-Extractor Metadaten, die aus allen vergangenen und zukünftigen Schemas generiert wurden, aufgrund des Vorwärts- und Rückwärtskompatibilitätsmechanismus von Flatbuffers lesen. Felder aus zukünftigen Schemas können jedoch nicht von älteren Metadaten-Extraktoren extrahiert werden. Die mindestens erforderliche Parserversion der Metadaten gibt die Mindestversion des Metadaten-Parsers an, mit der die Flatbuffers-Metadaten vollständig gelesen werden können. Mit der folgenden Methode können Sie prüfen, ob die Bedingung für die Mindestversion des erforderlichen Parsers erfüllt ist:
public final boolean isMinimumParserVersionSatisfied();
Es ist zulässig, ein Modell ohne Metadaten zu übergeben. Das Aufrufen von Methoden, die Metadaten lesen, führt jedoch zu Laufzeitfehlern. Mit der Methode hasMetadata können Sie prüfen, ob ein Modell Metadaten hat:
public boolean hasMetadata();
MetadataExtractor bietet praktische Funktionen zum Abrufen der Metadaten der Ein-/Ausgabetensoren. Beispiel:
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
Obwohl das LiteRT-Modellschema mehrere Untergraphen unterstützt, unterstützt der TFLite-Interpreter derzeit nur einen einzelnen Untergraphen. Daher wird der Subgraph-Index in den Methoden von MetadataExtractor nicht als Eingabeargument verwendet.
Zugehörige Dateien aus Modellen lesen
Das LiteRT-Modell mit Metadaten und zugehörigen Dateien ist im Grunde eine ZIP-Datei, die mit gängigen ZIP-Tools entpackt werden kann, um die zugehörigen Dateien zu erhalten. Sie können beispielsweise mobilenet_v1_0.75_160_quantized entzippen und die Labeldatei im Modell so extrahieren:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
Sie können auch zugehörige Dateien über die Metadata Extractor-Bibliothek lesen.
Übergeben Sie in Java den Dateinamen an die Methode MetadataExtractor.getAssociatedFile:
public InputStream getAssociatedFile(String fileName);
In C++ kann dies mit der Methode ModelMetadataExtractor::GetAssociatedFile erfolgen:
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;