
غالبًا ما تكون أجهزة الحافة محدودة الذاكرة أو القدرة الحسابية. يمكن تطبيق تحسينات مختلفة على النماذج لكي يمكن تشغيلها ضمن هذه القيود. بالإضافة إلى ذلك، تسمح بعض التحسينات باستخدام أجهزة متخصصة للاستدلال السريع.
توفّر LiteRT وأداة تحسين نماذج TensorFlow أدوات لتقليل تعقيد عملية تحسين الاستدلال.
ننصحك بمراعاة تحسين النموذج أثناء عملية تطوير التطبيق. يوضّح هذا المستند بعض أفضل الممارسات لتحسين نماذج TensorFlow من أجل نشرها على أجهزة الحافة.
أهمية تحسين النماذج
هناك عدة طرق رئيسية يمكن أن يساعد بها تحسين النماذج في تطوير التطبيقات.
تقليل الحجم
يمكن استخدام بعض أشكال التحسين لتقليل حجم النموذج. تقدّم النماذج الأصغر حجمًا المزايا التالية:
- حجم تخزين أصغر: تشغل النماذج الأصغر حجمًا مساحة تخزين أقل على أجهزة المستخدمين. على سبيل المثال، سيشغل تطبيق Android الذي يستخدم نموذجًا أصغر حجمًا مساحة تخزين أقل على جهاز المستخدم الجوّال.
- حجم تنزيل أصغر: تتطلّب النماذج الأصغر وقتًا ونطاقًا تردديًا أقل للتنزيل على أجهزة المستخدمين.
- استخدام أقل للذاكرة: تستخدم النماذج الأصغر حجمًا ذاكرة وصول عشوائي (RAM) أقل عند تشغيلها، ما يوفّر مساحة ذاكرة يمكن أن تستخدمها أجزاء أخرى من تطبيقك، ويمكن أن يؤدي ذلك إلى تحسين الأداء والاستقرار.
يمكن أن يؤدي التكميم إلى تقليل حجم النموذج في كل هذه الحالات، ولكن قد يؤثر ذلك في دقة النموذج. يمكن أن يؤدي التقليم والتجميع إلى تقليل حجم نموذج يمكن تنزيله من خلال تسهيل ضغطه.
تقليل وقت الاستجابة
وقت الاستجابة هو مقدار الوقت الذي يستغرقه تنفيذ استنتاج واحد باستخدام نموذج معيّن. يمكن أن تؤدي بعض أشكال التحسين إلى تقليل مقدار العمليات الحسابية المطلوبة لتشغيل الاستدلال باستخدام نموذج، ما يؤدي إلى تقليل وقت الاستجابة. يمكن أن يؤثّر وقت الاستجابة أيضًا في استهلاك الطاقة.
يمكن حاليًا استخدام التكميم لتقليل وقت الاستجابة من خلال تبسيط العمليات الحسابية التي تحدث أثناء الاستدلال، وقد يؤدي ذلك إلى خفض مستوى الدقة.
توافق أداة التسريع
يمكن لبعض أدوات تسريع الأجهزة، مثل Edge TPU، تنفيذ الاستدلال بسرعة فائقة باستخدام نماذج تم تحسينها بشكل صحيح.
وبشكل عام، تتطلّب هذه الأنواع من الأجهزة أن يتم تحديد كمية النماذج بطريقة معيّنة. راجِع مستندات كل أداة تسريع للأجهزة لمعرفة المزيد من المعلومات حول متطلباتها.
المفاضلات
يمكن أن تؤدي عمليات التحسين إلى تغييرات في دقة النموذج، ويجب أخذ ذلك في الاعتبار أثناء عملية تطوير التطبيق.
تعتمد التغييرات في الدقة على النموذج الفردي الذي يتم تحسينه، ومن الصعب توقّعها مسبقًا. بشكل عام، ستنخفض دقة النماذج التي تم تحسينها من حيث الحجم أو وقت الاستجابة بشكل طفيف. قد يؤثر ذلك في تجربة المستخدمين أو لا يؤثر فيها، وذلك حسب تطبيقك. في حالات نادرة، قد تزداد دقة بعض النماذج نتيجة لعملية التحسين.
أنواع التحسين
تتيح LiteRT حاليًا تحسين الأداء من خلال التكميم والتشذيب والتجميع.
وهي جزء من أداة تحسين نماذج TensorFlow التي توفّر موارد لأساليب تحسين النماذج المتوافقة مع TensorFlow Lite.
التكميم
تعمل الكمّية من خلال تقليل دقة الأرقام المستخدَمة لتمثيل مَعلمات النموذج، والتي تكون تلقائيًا أرقام نقطة عائمة ذات 32 بت. ويؤدي ذلك إلى تقليل حجم النموذج وتسريع عملية الحساب.
تتوفّر أنواع التكميم التالية في LiteRT:
| الأسلوب | متطلبات البيانات | تقليل الحجم | الدقة | الأجهزة المتوافقة |
|---|---|---|---|---|
| التكميم float16 بعد التدريب | ليست هناك أي بيانات | ما يصل إلى %50 | فقدان طفيف للدقة | وحدة المعالجة المركزية، وحدة معالجة الرسومات |
| تحديد الكمية الديناميكية بعد التدريب | ليست هناك أي بيانات | خصم يصل إلى 75% | أقل قدر من فقدان الدقة | وحدة المعالجة المركزية (CPU) ووحدة معالجة الرسومات (GPU) (نظام التشغيل Android) |
| تحديد الكمية الصحيحة بعد التدريب | عيّنة تمثيلية غير مصنّفة | ما يصل إلى 75% | فقدان طفيف للدقة | وحدة المعالجة المركزية (CPU) ووحدة معالجة الرسومات (GPU) (على Android) وEdgeTPU |
| التدريب مع مراعاة التكميم | بيانات التدريب المصنَّفة | خصم يصل إلى 75% | أقل قدر من فقدان الدقة | وحدة المعالجة المركزية (CPU) ووحدة معالجة الرسومات (GPU) (على Android) وEdgeTPU |
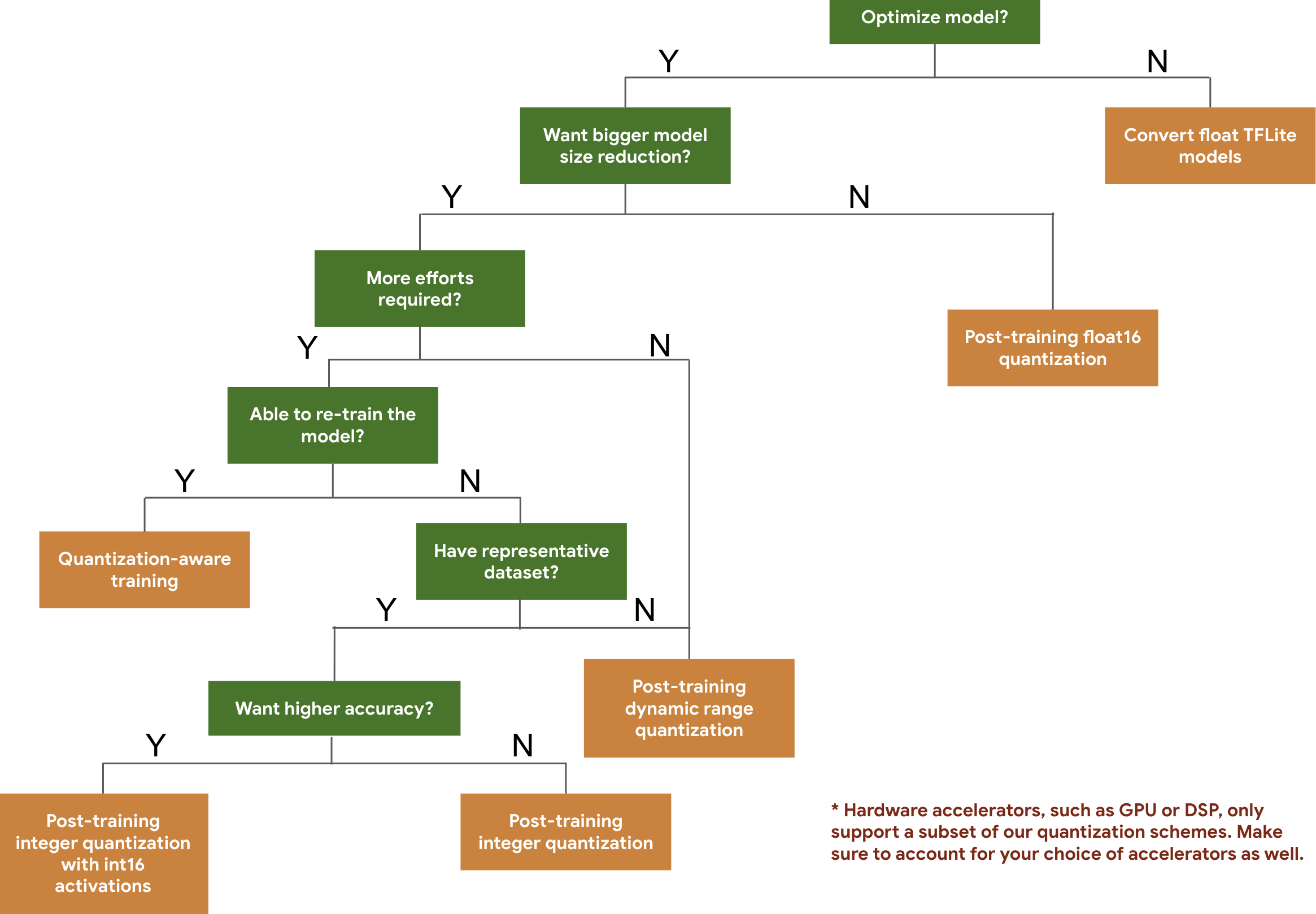
تساعدك شجرة القرارات التالية في اختيار مخططات التكميم التي قد تحتاج إلى استخدامها في نموذجك، وذلك استنادًا إلى حجم النموذج ودقته المتوقّعَين.
في ما يلي نتائج وقت الاستجابة والدقة لعملية التكميم بعد التدريب وعملية التدريب مع مراعاة التكميم في بعض النماذج. يتم قياس جميع أرقام الكمون على أجهزة Pixel 2 باستخدام وحدة معالجة مركزية واحدة كبيرة النواة. ومع تحسّن مجموعة الأدوات، ستتحسّن الأرقام التالية:
| الطراز | دقة أعلى 1 (الأصلية) | دقة أعلى 1 (بعد التدريب الكمي) | دقة أعلى 1 (التدريب على التكميم) | وقت الاستجابة (الأصلي) (مللي ثانية) | وقت الاستجابة (بعد التدريب الكمي) (مللي ثانية) | وقت الاستجابة (التدريب مع مراعاة التكميم) (مللي ثانية) | الحجم (الأصلي) (ميغابايت) | الحجم (محسّن) (ميغابايت) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | لا ينطبق | 3973 | 2868 | لا ينطبق | 178.3 | 44.9 |
تحديد الكمية الكاملة للأعداد الصحيحة مع تنشيط int16 وأوزان int8
التكميم باستخدام عمليات التنشيط int16 هو نظام تكميم كامل للأعداد الصحيحة مع عمليات تنشيط في int16 وأوزان في int8. يمكن أن يحسّن هذا الوضع دقة النموذج الكمّي مقارنةً بنظام التكميم الكامل للأعداد الصحيحة مع كل من عمليات التنشيط والأوزان في int8 مع الحفاظ على حجم نموذج مماثل. يُنصح باستخدامها عندما تكون عمليات التفعيل حساسة للتكميم.
ملاحظة: لا تتوفّر حاليًا في TFLite سوى عمليات تنفيذ غير محسّنة لنواة مرجعية خاصة بنظام التكميم هذا، لذا سيكون الأداء بطيئًا تلقائيًا مقارنةً بنواة int8. يمكن حاليًا الاستفادة من المزايا الكاملة لهذا الوضع من خلال أجهزة متخصصة أو برامج مخصصة.
في ما يلي نتائج الدقة لبعض النماذج التي تستفيد من هذا الوضع.
| الطراز | نوع مقياس الدقة | الدقة (عمليات التفعيل float32) | الدقة (عمليات التنشيط int8) | الدقة (تنشيطات int16) |
|---|---|---|---|---|
| Wav2letter | WER | 6.7% | 7.7% | 7.2% |
| DeepSpeech 0.5.1 (غير مضغوط) | CER | 6.13% | 43.67% | 6.52% |
| YoloV3 | متوسط الدقة(IOU=0.5) | 0.577 | 0.563 | 0.574 |
| MobileNetV1 | دقة أعلى 1 | 0.7062 | 0.694 | 0.6936 |
| MobileNetV2 | دقة أعلى 1 | 0.718 | 0.7126 | 0.7137 |
| MobileBert | F1(Exact match) | 88.81(81.23) | 2.08(0) | 88.73(81.15) |
التقليم
تعمل عملية التقليم من خلال إزالة المَعلمات التي لا تؤثّر إلا بشكل طفيف في التوقّعات التي يقدّمها النموذج. تكون أحجام النماذج التي تم تقليمها هي نفسها على القرص، ويكون وقت الاستجابة أثناء التشغيل هو نفسه، ولكن يمكن ضغطها بشكل أكثر فعالية. وهذا يجعل عملية التقليم أسلوبًا مفيدًا لتقليل حجم تنزيل النموذج.
في المستقبل، ستوفّر LiteRT إمكانية تقليل وقت الاستجابة للنماذج التي تم تقليل حجمها.
مجمّع
تعمل عملية التجميع من خلال تجميع أوزان كل طبقة في نموذج في عدد محدّد مسبقًا من المجموعات، ثم مشاركة قيم النقطة المركزية للأوزان التي تنتمي إلى كل مجموعة فردية. يؤدي ذلك إلى تقليل عدد قيم الأوزان الفريدة في النموذج، وبالتالي تقليل تعقيده.
نتيجةً لذلك، يمكن ضغط النماذج المجمّعة بشكل أكثر فعالية، ما يوفّر مزايا نشر مشابهة لمزايا التقليم.
سير عمل التطوير
للبدء، تحقَّق مما إذا كانت النماذج في النماذج المستضافة مناسبة لتطبيقك. إذا لم يكن الأمر كذلك، ننصح المستخدمين بالبدء باستخدام أداة التكميم بعد التدريب لأنّها قابلة للتطبيق على نطاق واسع ولا تتطلّب بيانات تدريب.
في الحالات التي لا يتم فيها استيفاء أهداف الدقة ووقت الاستجابة، أو عندما يكون توفّر مسرّع للأجهزة مهمًا، يكون التدريب المدرك للتكميم هو الخيار الأفضل. يمكنك الاطّلاع على تقنيات تحسين إضافية ضمن مجموعة أدوات تحسين نماذج TensorFlow.
إذا أردت تقليل حجم النموذج بشكل أكبر، يمكنك تجربة التقليم و/أو التجميع قبل تكميم النماذج.