
Периферийные устройства часто имеют ограниченный объём памяти или вычислительной мощности. Для запуска моделей в рамках этих ограничений можно применять различные оптимизации. Кроме того, некоторые оптимизации позволяют использовать специализированное оборудование для ускоренного вывода.
LiteRT и набор инструментов для оптимизации моделей TensorFlow предоставляют инструменты, позволяющие минимизировать сложность оптимизации вывода.
Рекомендуется учитывать оптимизацию моделей в процессе разработки приложений. В этом документе описаны некоторые рекомендации по оптимизации моделей TensorFlow для развертывания на периферийном оборудовании.
Почему модели следует оптимизировать
Существует несколько основных способов, которыми оптимизация моделей может помочь в разработке приложений.
Уменьшение размера
Некоторые формы оптимизации могут быть использованы для уменьшения размера модели. Меньшие модели имеют следующие преимущества:
- Меньший объём хранилища: модели меньшего размера занимают меньше места на устройствах пользователей. Например, приложение Android, использующее модель меньшего размера, займёт меньше места на мобильном устройстве пользователя.
- Меньший размер загружаемого файла: для загрузки небольших моделей на устройства пользователей требуется меньше времени и пропускной способности.
- Меньшее использование памяти: Меньшие модели используют меньше оперативной памяти при запуске, что освобождает память для использования другими частями вашего приложения и может привести к повышению производительности и стабильности.
Квантование может уменьшить размер модели во всех этих случаях, возможно, за счёт некоторой потери точности. Отсечение и кластеризация могут уменьшить размер модели для загрузки, упрощая её сжатие.
Уменьшение задержки
Задержка — это время, необходимое для выполнения одного вывода с использованием заданной модели. Некоторые методы оптимизации могут сократить объём вычислений, необходимых для выполнения вывода с использованием модели, что приводит к снижению задержки. Задержка также может влиять на энергопотребление.
В настоящее время квантование может использоваться для сокращения задержки путем упрощения вычислений, выполняемых во время вывода, возможно, за счет некоторой потери точности.
Совместимость с ускорителем
Некоторые аппаратные ускорители, такие как Edge TPU , могут выполнять вывод чрезвычайно быстро с моделями, которые были правильно оптимизированы.
Как правило, для таких устройств требуется определённый способ квантования моделей. Подробнее о требованиях см. в документации к каждому аппаратному ускорителю.
Компромиссы
Оптимизации потенциально могут привести к изменению точности модели, что необходимо учитывать в процессе разработки приложения.
Изменения точности зависят от конкретной оптимизируемой модели и их сложно предсказать заранее. Как правило, модели, оптимизированные по размеру или задержке, немного теряют в точности. В зависимости от вашего приложения, это может повлиять на пользовательский опыт, а может и нет. В редких случаях точность некоторых моделей может повыситься в результате оптимизации.
Типы оптимизации
В настоящее время LiteRT поддерживает оптимизацию посредством квантования, обрезки и кластеризации.
Они являются частью набора инструментов оптимизации моделей TensorFlow , который предоставляет ресурсы для методов оптимизации моделей, совместимых с TensorFlow Lite.
Квантование
Квантование работает за счёт снижения точности чисел, используемых для представления параметров модели, которые по умолчанию представляют собой 32-битные числа с плавающей запятой. Это приводит к уменьшению размера модели и ускорению вычислений.
В LiteRT доступны следующие типы квантования:
| Техника | Требования к данным | Уменьшение размера | Точность | Поддерживаемое оборудование |
|---|---|---|---|---|
| Квантование float16 после обучения | Нет данных | До 50% | Незначительная потеря точности | Центральный процессор, графический процессор |
| Квантование динамического диапазона после обучения | Нет данных | До 75% | Наименьшая потеря точности | Центральный процессор, графический процессор (Android) |
| Целочисленное квантование после обучения | Немаркированный репрезентативный образец | До 75% | Небольшая потеря точности | Центральный процессор, графический процессор (Android), EdgeTPU |
| Обучение с учетом квантизации | Маркированные данные обучения | До 75% | Наименьшая потеря точности | Центральный процессор, графический процессор (Android), EdgeTPU |
Следующее дерево решений поможет вам выбрать схемы квантования, которые вы, возможно, захотите использовать для своей модели, основываясь исключительно на ожидаемом размере модели и точности.
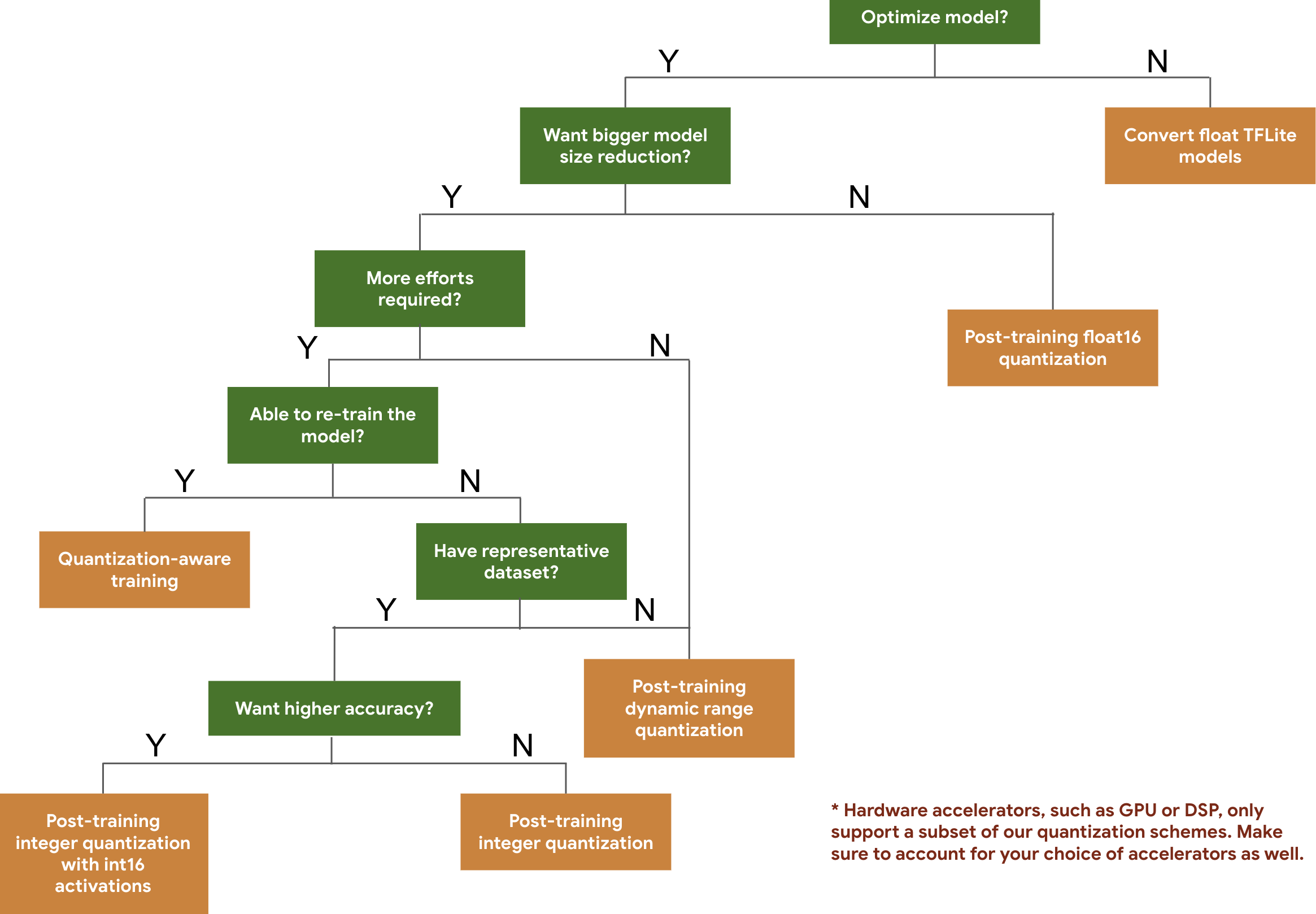
Ниже приведены результаты по задержке и точности для квантования после обучения и обучения с учётом квантования на нескольких моделях. Все значения задержки измерены на устройствах Pixel 2 с использованием одного ядра процессора. По мере совершенствования инструментария будут совершенствоваться и приведенные здесь показатели:
| Модель | Точность 1 (оригинал) | Точность 1 (квантованная после обучения) | Точность 1 уровня (обучение с учетом квантования) | Задержка (исходная) (мс) | Задержка (квантованная после обучения) (мс) | Задержка (обучение с учетом квантования) (мс) | Размер (исходный) (МБ) | Размер (оптимизированный) (МБ) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0,709 | 0,657 | 0,70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0,719 | 0,637 | 0,709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0,78 | 0,772 | 0,775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0,770 | 0,768 | Н/Д | 3973 | 2868 | Н/Д | 178.3 | 44.9 |
Полное целочисленное квантование с активациями int16 и весами int8
Квантование с активациями int16 — это схема полного целочисленного квантования с активациями в int16 и весами в int8. Этот режим может повысить точность квантованной модели по сравнению со схемой полного целочисленного квантования, где как активации, так и веса находятся в int8, сохраняя при этом аналогичный размер модели. Рекомендуется использовать этот режим, когда активации чувствительны к квантованию.
ПРИМЕЧАНИЕ: В настоящее время в TFLite доступны только неоптимизированные реализации эталонного ядра для этой схемы квантования, поэтому по умолчанию производительность будет ниже, чем у ядер int8. Все преимущества этого режима в настоящее время доступны с помощью специализированного оборудования или пользовательского программного обеспечения.
Ниже приведены результаты точности некоторых моделей, для которых этот режим оказался более эффективным. Модель Тип метрики точности Точность (активации float32) Точность (активации int8) Точность (активации int16) Wav2letter ВЕР 6,7% 7,7% 7,2% DeepSpeech 0.5.1 (развернутый) КЕР 6,13% 43,67% 6,52% YoloV3 mAP(IOU=0,5) 0,577 0,563 0,574 MobileNetV1 Точность 1 0,7062 0,694 0,6936 MobileNetV2 Точность 1 0,718 0,7126 0,7137 MobileBert F1(Точное совпадение) 88.81(81.23) 2.08(0) 88,73(81,15)
Обрезка
Отсечение модели заключается в удалении параметров, которые оказывают лишь незначительное влияние на её прогнозы. Отсечённые модели занимают тот же объём на диске и имеют ту же задержку выполнения, но могут быть сжаты более эффективно. Это делает отсечение полезной методикой для уменьшения размера загружаемой модели.
В будущем LiteRT обеспечит сокращение задержек для обрезанных моделей.
Кластеризация
Кластеризация работает путём группировки весов каждого слоя модели в предопределённое количество кластеров с последующим распределением значений центроида для весов, принадлежащих каждому отдельному кластеру. Это сокращает количество уникальных значений весов в модели, тем самым снижая её сложность.
В результате кластеризованные модели можно сжимать более эффективно, обеспечивая преимущества развертывания, аналогичные отсечению.
Рабочий процесс разработки
Для начала проверьте, подходят ли модели, размещенные в размещённых моделях, для вашего приложения. Если нет, мы рекомендуем начать с инструмента квантования после обучения, поскольку он широко применим и не требует обучающих данных.
В случаях, когда целевые показатели точности и задержки не достигаются или важна поддержка аппаратного ускорителя, обучение с учётом квантизации является лучшим вариантом. Дополнительные методы оптимизации см. в руководстве TensorFlow Model Optimization Toolkit .
Если вы хотите еще больше уменьшить размер модели, вы можете попробовать выполнить обрезку и/или кластеризацию перед квантованием моделей.