
エッジデバイスは、メモリや計算能力が制限されていることがよくあります。モデルにさまざまな最適化を適用して、これらの制約内で実行できるようにすることができます。また、一部の最適化では、推論の高速化に専用のハードウェアを使用できます。
LiteRT と TensorFlow Model Optimization Toolkit は、推論の最適化の複雑さを最小限に抑えるツールを提供します。
アプリケーションの開発プロセスでモデルの最適化を検討することをおすすめします。このドキュメントでは、エッジ ハードウェアへのデプロイ用に TensorFlow モデルを最適化するためのベスト プラクティスについて説明します。
モデルを最適化する理由
モデルの最適化は、アプリケーション開発に役立ついくつかの主な方法があります。
サイズ縮小
一部の最適化手法は、モデルのサイズを縮小するために使用できます。小規模なモデルには次のようなメリットがあります。
- ストレージ サイズの縮小: モデルが小さくなると、ユーザーのデバイスで占有するストレージ容量が少なくなります。たとえば、小さいモデルを使用する Android アプリは、ユーザーのモバイル デバイスのストレージ容量をあまり使用しません。
- ダウンロード サイズの縮小: モデルが小さいほど、ユーザーのデバイスにダウンロードするのに必要な時間と帯域幅が少なくなります。
- メモリ使用量の削減: 小さいモデルは実行時に使用する RAM が少ないため、アプリケーションの他の部分で使用できるメモリが解放され、パフォーマンスと安定性の向上につながります。
量子化により、これらのすべてのケースでモデルのサイズを縮小できます。ただし、精度が低下する可能性があります。枝刈りとクラスタリングにより、モデルの圧縮が容易になり、ダウンロードするモデルのサイズを削減できます。
遅延の軽減
レイテンシは、特定のモデルで単一の推論を実行するのにかかる時間です。最適化の中には、モデルを使用して推論を実行するために必要な計算量を減らし、レイテンシを短縮できるものがあります。レイテンシは消費電力にも影響する可能性があります。
現在、量子化は、推論中に発生する計算を簡素化することでレイテンシを短縮するために使用できます。ただし、精度が低下する可能性があります。
アクセラレータの互換性
Edge TPU などのハードウェア アクセラレータは、正しく最適化されたモデルで推論を非常に高速に実行できます。
一般的に、この種のデバイスでは、モデルを特定の方法で量子化する必要があります。要件について詳しくは、各ハードウェア アクセラレータのドキュメントをご覧ください。
トレードオフ
最適化によりモデルの精度が変化する可能性があるため、アプリ開発プロセスで考慮する必要があります。
精度の変化は、最適化される個々のモデルによって異なり、事前に予測することは困難です。一般に、サイズやレイテンシを最適化したモデルでは、精度がわずかに低下します。アプリケーションによっては、ユーザー エクスペリエンスに影響する可能性があります。まれに、最適化プロセスによって特定のモデルの精度が向上することがあります。
最適化の種類
LiteRT は現在、量子化、プルーニング、クラスタリングによる最適化をサポートしています。
これらは TensorFlow Model Optimization Toolkit の一部であり、TensorFlow Lite と互換性のあるモデル最適化手法のリソースを提供します。
量子化
量子化は、モデルのパラメータを表すために使用される数値の精度を下げることで機能します。デフォルトでは、32 ビット浮動小数点数です。この結果、モデルサイズが小さくなり、計算速度が向上します。
LiteRT では、次の種類の量子化を使用できます。
| 手法 | データ要件 | サイズ縮小 | 精度 | サポートされているハードウェア |
|---|---|---|---|---|
| トレーニング後の float16 の量子化 | データなし | 最大 50% | 精度の損失がわずか | CPU、GPU |
| トレーニング後のダイナミック レンジの量子化 | データなし | 最大 75% | 精度損失が最小 | CPU、GPU(Android) |
| トレーニング後の整数量子化 | ラベルなしの代表サンプル | 最大 75% | 精度の低下が小さい | CPU、GPU(Android)、EdgeTPU |
| 量子化認識トレーニング | ラベル付きトレーニング データ | 最大 75% | 精度損失が最小 | CPU、GPU(Android)、EdgeTPU |
次のディシジョン ツリーは、モデルの予想サイズと精度に基づいて、モデルで使用する量子化スキームを選択するのに役立ちます。
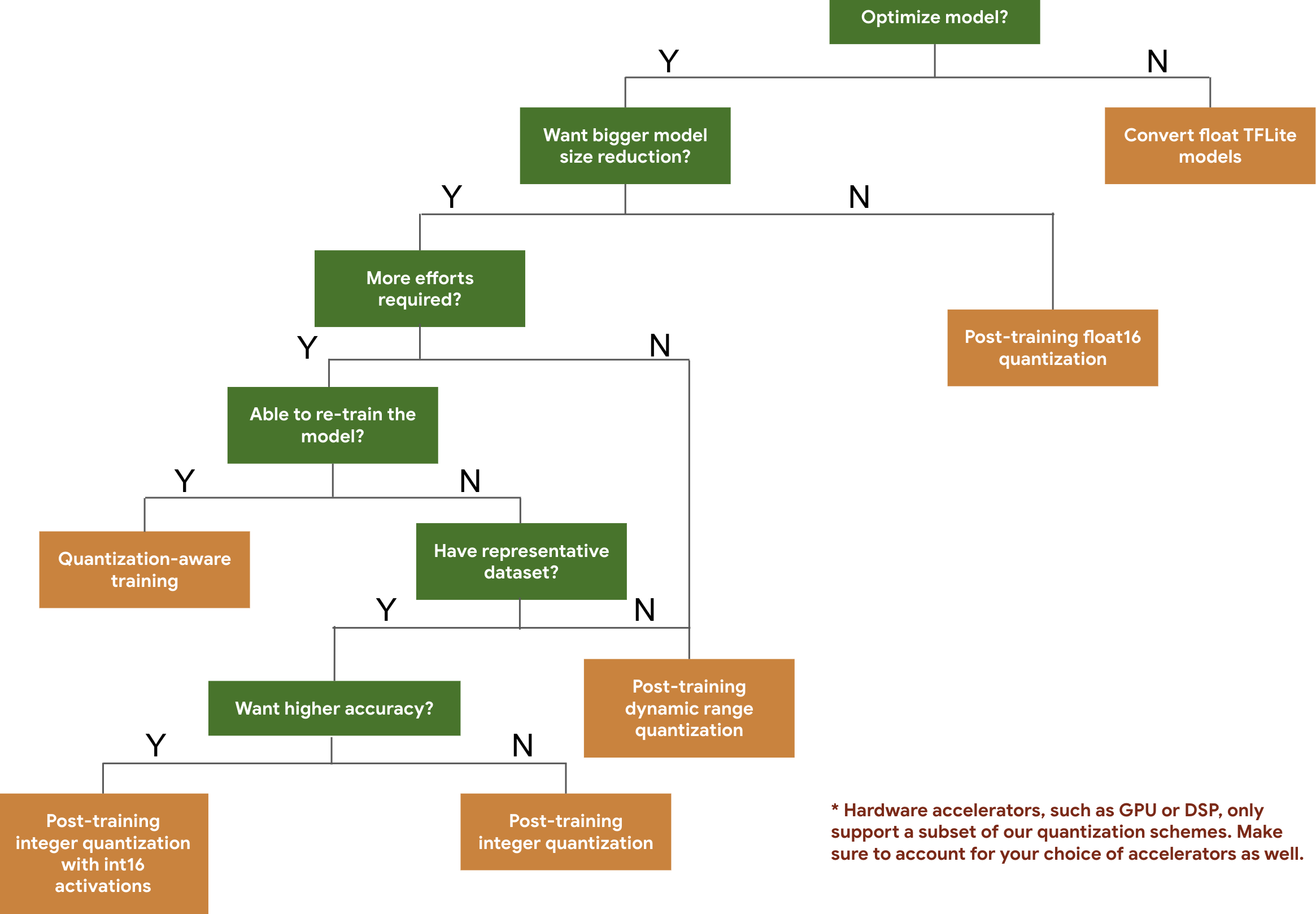
以下に、いくつかのモデルでのトレーニング後の量子化と量子化認識トレーニングのレイテンシと精度の結果を示します。レイテンシの数値はすべて、1 つのビッグコア CPU を使用する Google Pixel 2 デバイスで測定されています。ツールキットが改善されるにつれて、次の数値も改善されます。
| モデル | Top-1 精度(オリジナル) | 上位 1 の精度(トレーニング後の量子化) | 最上位の精度(量子化認識トレーニング) | レイテンシ(オリジナル)(ミリ秒) | レイテンシ(トレーニング後の量子化)(ミリ秒) | レイテンシ(量子化認識トレーニング)(ミリ秒) | サイズ(オリジナル)(MB) | サイズ(最適化済み)(MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | なし | 3973 | 2868 | なし | 178.3 | 44.9 |
完全な整数量子化(int16 アクティベーションと int8 重みを使用)
int16 アクティベーションによる量子化は、アクティベーションが int16 で重みが int8 の完全な整数量子化スキームです。このモードでは、活性化と重みの両方が int8 の完全な整数量子化スキームと比較して、量子化モデルの精度を向上させながら、モデルサイズをほぼ同じに保つことができます。量子化にアクティベーションが敏感な場合に推奨されます。
注: 現在、この量子化スキームでは、最適化されていない参照カーネル実装のみが TFLite で利用可能です。そのため、デフォルトでは、int8 カーネルと比較してパフォーマンスが遅くなります。このモードのメリットを最大限に活用するには、現在、専用のハードウェアまたはカスタム ソフトウェアを使用する必要があります。
以下に、このモードのメリットがある一部のモデルの精度結果を示します。
| モデル | 精度指標のタイプ | 精度(float32 アクティベーション) | 精度(int8 アクティベーション) | 精度(int16 アクティベーション) |
|---|---|---|---|---|
| Wav2letter | WER | 6.7% | 7.7% | 7.2% |
| DeepSpeech 0.5.1(アンロール) | CER | 6.13% | 43.67% | 6.52% |
| YoloV3 | mAP(IOU=0.5) | 0.577 | 0.563 | 0.574 |
| MobileNetV1 | 最上位の精度 | 0.7062 | 0.694 | 0.6936 |
| MobileNetV2 | 最上位の精度 | 0.718 | 0.7126 | 0.7137 |
| MobileBert | F1(完全一致) | 88.81(81.23) | 2.08(0) | 88.73(81.15) |
プルーニング
プルーニングは、モデルの予測にほとんど影響しないモデル内のパラメータを削除することで機能します。プルーニングされたモデルは、ディスク上のサイズとランタイム レイテンシは同じですが、より効果的に圧縮できます。そのため、枝刈りはモデルのダウンロード サイズを削減するのに役立つ手法です。
今後、LiteRT はプルーニングされたモデルのレイテンシ削減を提供します。
クラスタリング
クラスタリングは、モデル内の各レイヤの重みを事前定義された数のクラスタにグループ化し、各クラスタに属する重みの重心値を共有することで機能します。これにより、モデル内の固有の重み値の数が減り、複雑さが軽減されます。
その結果、クラスタリングされたモデルをより効果的に圧縮でき、プルーニングと同様のデプロイのメリットが得られます。
開発ワークフロー
まず、ホストされているモデルがアプリケーションで機能するかどうかを確認します。そうでない場合は、適用範囲が広く、トレーニング データも必要としない トレーニング後の量子化ツールから始めることをおすすめします。
精度とレイテンシの目標が達成されない場合や、ハードウェア アクセラレータのサポートが重要な場合は、量子化認識トレーニングが適しています。その他の最適化手法については、TensorFlow モデル最適化 Toolkit をご覧ください。