
Los dispositivos perimetrales suelen tener una memoria o una potencia de procesamiento limitadas. Se pueden aplicar varias optimizaciones a los modelos para que se puedan ejecutar dentro de estas restricciones. Además, algunas optimizaciones permiten el uso de hardware especializado para la inferencia acelerada.
LiteRT y el kit de herramientas de optimización de modelos de TensorFlow proporcionan herramientas para minimizar la complejidad de la optimización de la inferencia.
Te recomendamos que tengas en cuenta la optimización del modelo durante el proceso de desarrollo de la aplicación. En este documento, se describen algunas prácticas recomendadas para optimizar los modelos de TensorFlow para la implementación en hardware perimetral.
Por qué se deben optimizar los modelos
Existen varias formas principales en las que la optimización del modelo puede ayudar con el desarrollo de aplicaciones.
Reducción del tamaño
Algunas formas de optimización se pueden usar para reducir el tamaño de un modelo. Los modelos más pequeños tienen los siguientes beneficios:
- Tamaño de almacenamiento más pequeño: Los modelos más pequeños ocupan menos espacio de almacenamiento en los dispositivos de los usuarios. Por ejemplo, una app para Android que usa un modelo más pequeño ocupará menos espacio de almacenamiento en el dispositivo móvil del usuario.
- Tamaño de descarga más pequeño: Los modelos más pequeños requieren menos tiempo y ancho de banda para descargarse en los dispositivos de los usuarios.
- Menor uso de memoria: Los modelos más pequeños usan menos RAM cuando se ejecutan, lo que libera memoria para que la usen otras partes de tu aplicación y puede traducirse en un mejor rendimiento y estabilidad.
En todos estos casos, la cuantización puede reducir el tamaño de un modelo, posiblemente a expensas de cierta exactitud. La reducción y el agrupamiento en clústeres pueden reducir el tamaño de un modelo para su descarga, ya que lo hacen más fácil de comprimir.
Reducción de latencia
La latencia es la cantidad de tiempo que se tarda en ejecutar una sola inferencia con un modelo determinado. Algunas formas de optimización pueden reducir la cantidad de procesamiento que se requiere para ejecutar la inferencia con un modelo, lo que genera una menor latencia. La latencia también puede afectar el consumo de energía.
Actualmente, la cuantización se puede usar para reducir la latencia, ya que simplifica los cálculos que se realizan durante la inferencia, posiblemente a expensas de cierta precisión.
Compatibilidad del acelerador
Algunos aceleradores de hardware, como la TPU de Edge, pueden ejecutar la inferencia con extrema rapidez con modelos que se optimizaron correctamente.
Por lo general, estos tipos de dispositivos requieren que los modelos se cuantifiquen de una manera específica. Consulta la documentación de cada acelerador de hardware para obtener más información sobre sus requisitos.
Compensaciones
Las optimizaciones pueden generar cambios en la precisión del modelo, lo que se debe tener en cuenta durante el proceso de desarrollo de la aplicación.
Los cambios en la precisión dependen del modelo individual que se optimiza y son difíciles de predecir con anticipación. En general, los modelos optimizados para el tamaño o la latencia perderán una pequeña cantidad de exactitud. Según tu aplicación, esto puede afectar o no la experiencia de los usuarios. En casos excepcionales, ciertos modelos pueden ganar algo de precisión como resultado del proceso de optimización.
Tipos de optimización
Actualmente, LiteRT admite la optimización a través de la cuantificación, la poda y el agrupamiento en clústeres.
Estos forman parte del kit de herramientas de optimización de modelos de TensorFlow, que proporciona recursos para técnicas de optimización de modelos compatibles con TensorFlow Lite.
Cuantización
La cuantización funciona reduciendo la precisión de los números que se usan para representar los parámetros de un modelo, que, de forma predeterminada, son números de punto flotante de 32 bits. Esto genera un tamaño de modelo más pequeño y un procesamiento más rápido.
Los siguientes tipos de cuantificación están disponibles en LiteRT:
| Técnica | Requisitos de los datos | Reducción del tamaño | Exactitud | Hardware compatible |
|---|---|---|---|---|
| Cuantización de float16 posterior al entrenamiento | No hay datos | Hasta el 50% | Pérdida de precisión insignificante | CPU, GPU |
| Cuantización de rango dinámico posterior al entrenamiento | No hay datos | Hasta un 75% | La menor pérdida de precisión | CPU y GPU (Android) |
| Cuantización de números enteros posterior al entrenamiento | Muestra representativa sin etiquetas | Hasta un 75% | Poca pérdida de precisión | CPU, GPU (Android) y Edge TPU |
| Entrenamiento con reconocimiento de la cuantización | Datos de entrenamiento etiquetados | Hasta un 75% | La menor pérdida de precisión | CPU, GPU (Android) y Edge TPU |
El siguiente árbol de decisión te ayuda a seleccionar los esquemas de cuantización que podrías usar para tu modelo, simplemente en función del tamaño y la precisión esperados del modelo.
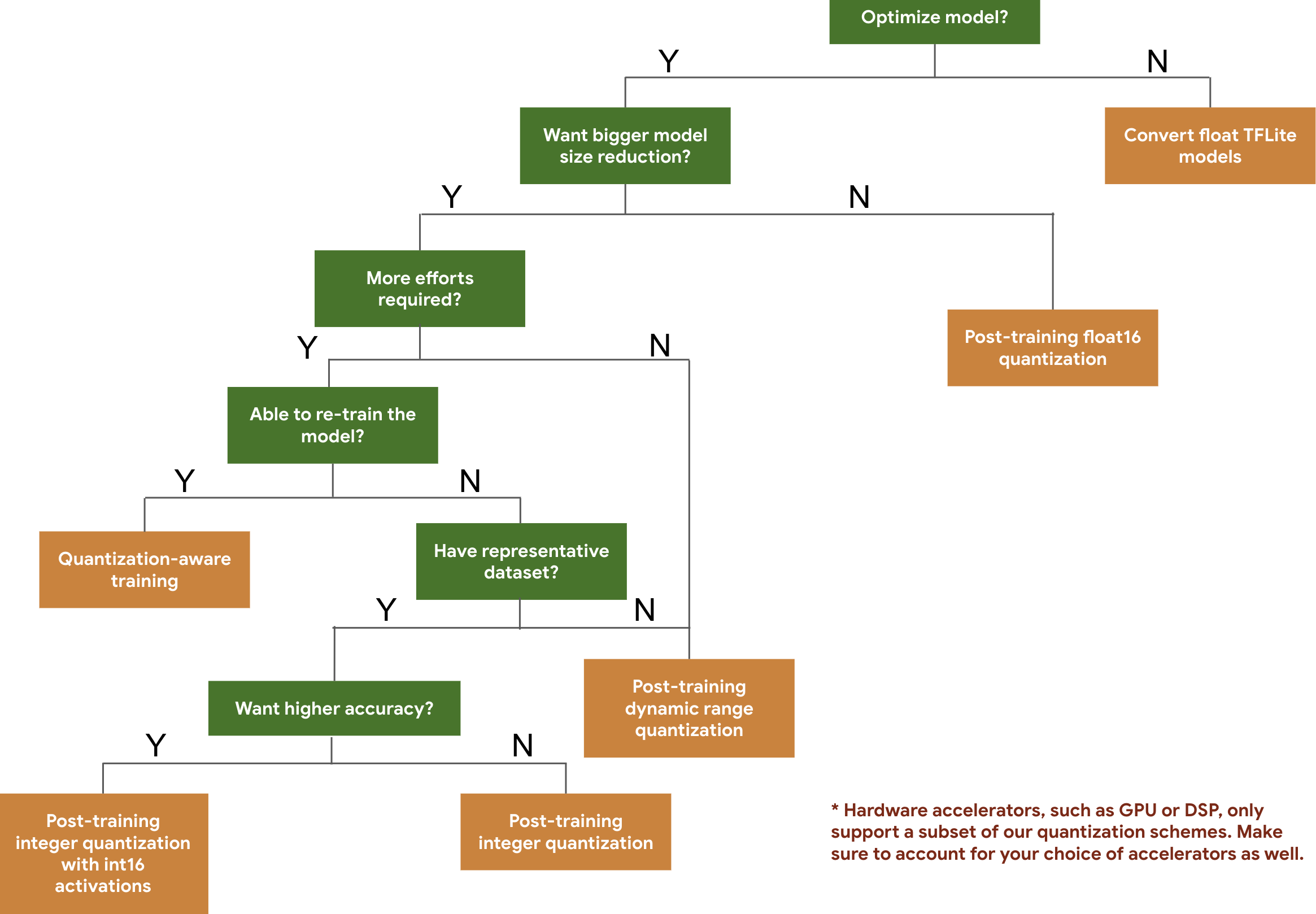
A continuación, se muestran los resultados de latencia y exactitud para la cuantización posterior al entrenamiento y el entrenamiento con cuantización en algunos modelos. Todos los números de latencia se miden en dispositivos Pixel 2 con una sola CPU de núcleo grande. A medida que mejore el kit de herramientas, también lo harán las cifras que se muestran aquí:
| Modelo | Precisión más alta (original) | Precisión del Top-1 (cuantizada después del entrenamiento) | Precisión del Top-1 (entrenamiento con cuantización) | Latencia (original) (ms) | Latencia (cuantificada después del entrenamiento) (ms) | Latencia (entrenamiento con cuantización) (ms) | Tamaño (original) (MB) | Tamaño (optimizado) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | N/A | 3973 | 2868 | N/A | 178.3 | 44.9 |
Cuantización de números enteros completa con activaciones de int16 y pesos de int8
La cuantización con activaciones de int16 es un esquema de cuantización de números enteros completo con activaciones en int16 y pesos en int8. Este modo puede mejorar la precisión del modelo cuantificado en comparación con el esquema de cuantificación de números enteros completo con activaciones y pesos en int8, lo que mantiene un tamaño de modelo similar. Se recomienda cuando las activaciones son sensibles a la cuantificación.
NOTA: Actualmente, solo hay disponibles implementaciones de kernel de referencia no optimizadas en TFLite para este esquema de cuantización, por lo que, de forma predeterminada, el rendimiento será lento en comparación con los kernels de int8. Actualmente, se puede acceder a todas las ventajas de este modo a través de hardware especializado o software personalizado.
A continuación, se muestran los resultados de precisión de algunos modelos que se benefician de este modo.
| Modelo | Tipo de métrica de precisión | Precisión (activaciones float32) | Precisión (activaciones int8) | Precisión (activaciones de int16) |
|---|---|---|---|---|
| Wav2letter | WER | 6.7% | 7.7% | 7.2% |
| DeepSpeech 0.5.1 (sin enrollar) | CER | 6.13% | 43.67% | 6.52% |
| YoloV3 | mAP(IOU=0.5) | 0.577 | 0.563 | 0.574 |
| MobileNetV1 | Precisión más alta | 0.7062 | 0.694 | 0.6936 |
| MobileNetV2 | Precisión más alta | 0.718 | 0.7126 | 0.7137 |
| MobileBert | F1(concordancia exacta) | 88.81(81.23) | 2.08(0) | 88.73(81.15) |
Poda
La poda funciona quitando los parámetros de un modelo que solo tienen un impacto menor en sus predicciones. Los modelos reducidos tienen el mismo tamaño en el disco y la misma latencia de tiempo de ejecución, pero se pueden comprimir de manera más eficaz. Esto hace que la reducción sea una técnica útil para reducir el tamaño de descarga del modelo.
En el futuro, LiteRT proporcionará una reducción de la latencia para los modelos podados.
Agrupamiento en clústeres
El agrupamiento en clústeres agrupa los pesos de cada capa de un modelo en una cantidad predefinida de clústeres y, luego, comparte los valores centroides de los pesos que pertenecen a cada clúster individual. Esto reduce la cantidad de valores de peso únicos en un modelo y, por lo tanto, su complejidad.
Como resultado, los modelos agrupados se pueden comprimir de manera más eficaz, lo que proporciona beneficios de implementación similares a la poda.
Flujo de trabajo de desarrollo
Como punto de partida, verifica si los modelos en modelos alojados pueden funcionar para tu aplicación. De lo contrario, recomendamos que los usuarios comiencen con la herramienta de cuantificación posterior al entrenamiento, ya que es ampliamente aplicable y no requiere datos de entrenamiento.
En los casos en que no se cumplen los objetivos de precisión y latencia, o en los que es importante la compatibilidad con el acelerador de hardware, el entrenamiento con reconocimiento de la cuantificación es la mejor opción. Consulta técnicas de optimización adicionales en el kit de herramientas de optimización de modelos de TensorFlow.
Si deseas reducir aún más el tamaño de tu modelo, puedes probar la poda o el agrupamiento antes de cuantificar tus modelos.