
التقييم الكمي بعد التدريب هو أسلوب تحويل يمكنه تقليل حجم النموذج مع تحسين وقت استجابة وحدة المعالجة المركزية ومسرّع الأجهزة، مع انخفاض بسيط في دقة النموذج. يمكنك تكميم نموذج TensorFlow تم تدريبه مسبقًا بنقطة عائمة عند تحويله إلى تنسيق LiteRT باستخدام أداة تحويل LiteRT.
طُرق التحسين
تتوفّر عدّة خيارات للتكميم بعد التدريب. في ما يلي جدول ملخّص للخيارات والمزايا التي توفّرها:
| الأسلوب | المزايا | أجهزة |
|---|---|---|
| تحديد الكمية للنطاق الديناميكي | حجم أصغر 4 مرّات، وسرعة أكبر من مرّتين إلى 3 مرّات | وحدة معالجة مركزية (CPU) |
| تحديد الكمية الكاملة للأعداد الصحيحة | حجم أصغر 4 مرات، وسرعة أكبر 3 مرات أو أكثر | وحدة المعالجة المركزية وEdge TPU والمتحكّمات الدقيقة |
| تحديد الكمية Float16 | حجم أصغر بمرّتين، تسريع باستخدام وحدة معالجة الرسومات | وحدة المعالجة المركزية، وحدة معالجة الرسومات |
يمكن أن تساعد شجرة القرارات التالية في تحديد طريقة التكميم بعد التدريب الأنسب لحالة الاستخدام:
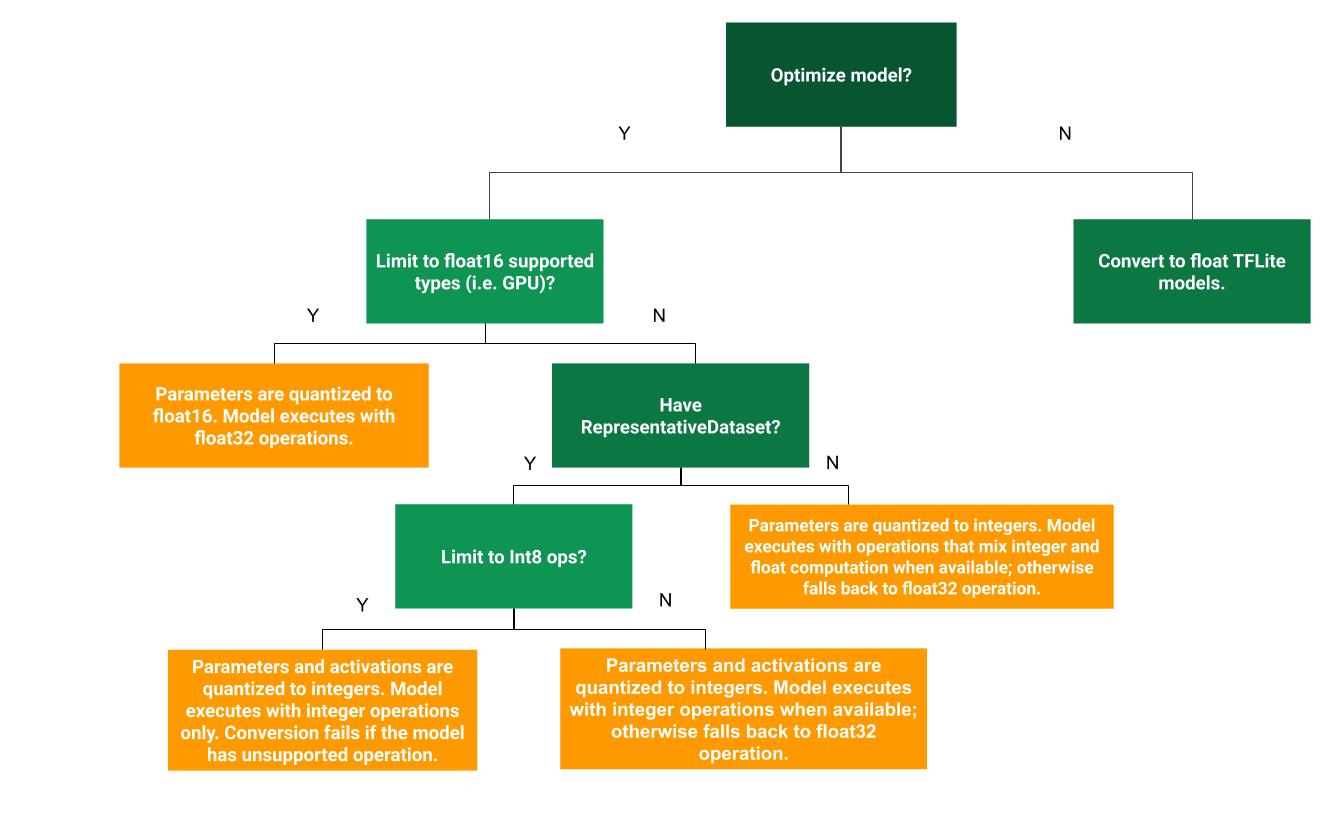
بدون تحديد الكمية
يُنصح بالبدء بتحويل النموذج إلى TFLite بدون تحديد الكمية. سيؤدي ذلك إلى إنشاء نموذج TFLite من النوع float.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
ننصحك بإجراء ذلك كخطوة أولية للتحقّق من أنّ عوامل تشغيل نموذج TensorFlow الأصلي متوافقة مع TFLite ويمكن استخدامها أيضًا كأساس لتصحيح أخطاء التكميم التي تسبّبت فيها طرق التكميم اللاحقة بعد التدريب. على سبيل المثال، إذا كان نموذج TFLite محدّد الكمية ينتج نتائج غير متوقّعة، بينما يكون نموذج TFLite ذو الفاصلة العائمة دقيقًا، يمكننا حصر المشكلة في الأخطاء التي تم إدخالها بواسطة الإصدار المحدّد الكمية من عوامل تشغيل TFLite.
تحديد كمية النطاق الديناميكي
توفّر عملية تحديد الكميات في النطاق الديناميكي تقليلًا في استخدام الذاكرة وتسريعًا في الحسابات بدون الحاجة إلى تقديم مجموعة بيانات تمثيلية لإجراء عملية المعايرة. يتم في هذا النوع من التكميم تكميم الأوزان بشكل ثابت من الفاصلة العائمة إلى العدد الصحيح فقط في وقت التحويل، ما يوفّر 8 بتات من الدقة:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
لتقليل وقت الاستجابة أثناء الاستدلال، تعمل عوامل تشغيل "النطاق الديناميكي" على تحديد كمية التنشيطات ديناميكيًا استنادًا إلى نطاقها إلى 8 بتات، وتجري العمليات الحسابية باستخدام أوزان وتنشيطات 8 بتات. يوفّر هذا التحسين زمن استجابة قريبًا من الاستنتاجات ذات النقطة الثابتة بالكامل. ومع ذلك، لا تزال المخرجات مخزّنة باستخدام الفاصلة العائمة، لذا فإنّ السرعة المتزايدة لعمليات النطاق الديناميكي أقل من عملية حسابية كاملة بنقطة ثابتة.
تحديد الكمية الكاملة للأعداد الصحيحة
يمكنك تحقيق المزيد من التحسينات في وقت الاستجابة وتقليل الحد الأقصى لاستخدام الذاكرة وضمان التوافق مع الأجهزة أو أدوات التسريع التي تستخدم الأعداد الصحيحة فقط من خلال التأكّد من أنّ جميع العمليات الحسابية في النموذج يتم تحديد كميتها باستخدام الأعداد الصحيحة.
بالنسبة إلى التكميم الكامل للأعداد الصحيحة، عليك معايرة النطاق أو تقديره، أي (الحدّ الأدنى، الحدّ الأقصى) لجميع موترات النقطة العائمة في النموذج على عكس الموترات الثابتة، مثل الأوزان والانحيازات، لا يمكن معايرة الموترات المتغيرة، مثل مدخلات النموذج والتنشيطات (مخرجات الطبقات الوسيطة) ومخرجات النموذج، إلا بعد تنفيذ بضع دورات استنتاج. نتيجةً لذلك، يحتاج المحوّل إلى مجموعة بيانات تمثيلية لمعايرتها. يمكن أن تكون مجموعة البيانات هذه مجموعة فرعية صغيرة (حوالي 100 إلى 500 عيّنة) من بيانات التدريب أو التحقّق من الصحة. راجِع الدالة representative_dataset() أدناه.
بدءًا من الإصدار 2.7 من TensorFlow، يمكنك تحديد مجموعة البيانات التمثيلية من خلال توقيع كما في المثال التالي:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
إذا كان هناك أكثر من توقيع واحد في نموذج TensorFlow المحدّد، يمكنك تحديد مجموعات البيانات المتعددة من خلال تحديد مفاتيح التوقيع:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
يمكنك إنشاء مجموعة البيانات التمثيلية من خلال تقديم قائمة موترات إدخال:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
منذ الإصدار 2.7 من TensorFlow، ننصح باستخدام طريقة تستند إلى التوقيع بدلاً من الطريقة التي تستند إلى قائمة موترات الإدخال، لأنّه يمكن تبديل ترتيب موترات الإدخال بسهولة.
لأغراض الاختبار، يمكنك استخدام مجموعة بيانات وهمية على النحو التالي:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
عدد صحيح مع خيار احتياطي للعدد العشري (باستخدام الإدخال/الإخراج التلقائي للعدد العشري)
لإجراء تكميم كامل للأعداد الصحيحة في نموذج، ولكن استخدام عوامل تشغيل الأعداد العشرية عندما لا يكون هناك تنفيذ للأعداد الصحيحة (لضمان حدوث التحويل بسلاسة)، اتّبِع الخطوات التالية:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
عدد صحيح فقط
يُعدّ إنشاء نماذج أعداد صحيحة فقط من حالات الاستخدام الشائعة في LiteRT for Microcontrollers وCoral Edge TPUs.
بالإضافة إلى ذلك، لضمان التوافق مع الأجهزة التي تستخدم الأعداد الصحيحة فقط (مثل وحدات التحكّم الدقيقة ذات 8 بت) والمسرّعات (مثل Coral Edge TPU)، يمكنك فرض التكميم الكامل للأعداد الصحيحة على جميع العمليات، بما في ذلك الإدخال والإخراج، باتّباع الخطوات التالية:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
تحديد الكمية Float16
يمكنك تقليل حجم نموذج النقطة العائمة من خلال تحديد كمية الأوزان إلى float16، وهو معيار IEEE لأرقام النقطة العائمة ذات 16 بت. لتفعيل تحديد الكمّ للأوزان باستخدام float16، اتّبِع الخطوات التالية:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
في ما يلي مزايا التكميم float16:
- يؤدي ذلك إلى تقليل حجم النموذج إلى النصف تقريبًا (لأنّ جميع القيم تصبح نصف حجمها الأصلي).
- يؤدي ذلك إلى حدّ أدنى من فقدان الدقة.
- وهي تتوافق مع بعض أدوات التفويض (مثل أداة تفويض وحدة معالجة الرسومات) التي يمكنها العمل مباشرةً على بيانات float16، ما يؤدي إلى تنفيذ أسرع من عمليات حساب float32.
في ما يلي عيوب التكميم float16:
- ولا يقلّل وقت الاستجابة بقدر ما يقلّله التكميم إلى رياضيات النقطة الثابتة.
- تلقائيًا، سيؤدي نموذج float16 الكمّي إلى "إزالة الكم" من قيم الأوزان إلى float32 عند تشغيله على وحدة المعالجة المركزية. (يُرجى العِلم أنّ المفوَّض الخاص بوحدة معالجة الرسومات لن ينفّذ عملية إلغاء التكميم هذه، لأنّه يمكنه العمل على بيانات float16).
عدد صحيح فقط: عمليات تفعيل 16 بت مع أوزان 8 بت (تجريبية)
هذا نظام تجريبي للتكميم. وهي تشبه مخطط "الأعداد الصحيحة فقط"، ولكن يتم تحديد كمية التنشيطات استنادًا إلى نطاقها إلى 16 بت، ويتم تحديد كمية الأوزان في عدد صحيح 8 بت، ويتم تحديد كمية الانحياز في عدد صحيح 64 بت. ويُشار إلى ذلك باسم التكميم 16x8.
تتمثّل الميزة الرئيسية لهذا التكميم في أنّه يمكنه تحسين الدقة بشكل كبير، ولكنّه يزيد حجم النموذج بشكل طفيف فقط.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
إذا لم يكن التكميم 16x8 متاحًا لبعض عوامل التشغيل في النموذج، سيظل بإمكانك تكميم النموذج، ولكن سيتم الاحتفاظ بعوامل التشغيل غير المتاحة في شكل أعداد عشرية. يجب إضافة الخيار التالي إلى target_spec للسماح بذلك.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
في ما يلي أمثلة على حالات الاستخدام التي توفّر فيها طريقة التكميم هذه تحسينات في الدقة:
- الدقة الفائقة
- معالجة الإشارات الصوتية، مثل إلغاء الضوضاء وتوجيه الصوت
- إزالة التشويش من الصور
- إعادة إنشاء صور HDR من صورة واحدة
تتمثّل عيوب هذا التكميم في ما يلي:
- في الوقت الحالي، تكون الاستدلالات أبطأ بشكل ملحوظ من الأعداد الصحيحة الكاملة ذات 8 بتات بسبب عدم توفّر تنفيذ محسّن للنواة.
- وهي غير متوافقة حاليًا مع برامج تفويض TFLite الحالية التي تستخدم تسريع الأجهزة.
يمكنك الاطّلاع على برنامج تعليمي حول وضع التكميم هذا هنا.
دقة النموذج
بما أنّ الأوزان يتم تحديد كميتها بعد التدريب، قد يحدث انخفاض في الدقة، خاصةً في الشبكات الأصغر حجمًا. تتوفّر نماذج مدرَّبة مسبقًا ومكمَّلة بالكامل لشبكات معيّنة على نماذج Kaggle. من المهم التحقّق من دقة النموذج الكمّي للتأكّد من أنّ أي انخفاض في الدقة يقع ضمن الحدود المقبولة. تتوفّر أدوات لتقييم دقة نموذج LiteRT.
بدلاً من ذلك، إذا كان الانخفاض في الدقة كبيرًا جدًا، يمكنك استخدام التدريب المراعي للتكميم . ومع ذلك، يتطلّب ذلك إجراء تعديلات أثناء تدريب النموذج لإضافة عُقد تكميم وهمية، بينما تستخدم تقنيات التكميم بعد التدريب الواردة في هذه الصفحة نموذجًا حاليًا مدرَّبًا مسبقًا.
تمثيل الموترات الكمية
يتم تقريب قيم النقطة العائمة باستخدام صيغة التكميم ذات 8 بتات التالية.
\[real\_value = (int8\_value - zero\_point) \times scale\]
يتضمّن التمثيل جزءَين رئيسيَّين:
الأوزان لكل محور (أو لكل قناة) أو لكل موتر، ويتم تمثيلها بقيم int8 بنظام المتمّم الثنائي في النطاق [-127, 127] مع نقطة صفر تساوي 0.
عمليات التنشيط/الإدخال لكل موتر ممثَّلة بقيم مكمّلة ثنائية من النوع int8 في النطاق [-128, 127]، مع نقطة صفرية في النطاق [-128, 127].
للاطّلاع على عرض تفصيلي لمخطط التكميم، يُرجى الرجوع إلى مواصفات التكميم. وننصح مورّدي الأجهزة الذين يريدون استخدام واجهة التفويض في TensorFlow Lite بتنفيذ مخطط التكميم الموضّح هناك.