
การแปลงเป็นควอนไทซ์หลังการฝึกเป็นเทคนิคการแปลงที่ช่วยลดขนาดโมเดล พร้อมทั้งปรับปรุงเวลาในการตอบสนองของ CPU และตัวเร่งฮาร์ดแวร์ โดยมีความแม่นยำของโมเดลลดลงเพียงเล็กน้อย คุณสามารถควอนไทซ์โมเดล TensorFlow แบบ Float ที่ฝึกแล้วได้เมื่อแปลงเป็นรูปแบบ LiteRT โดยใช้ LiteRT Converter
วิธีการเพิ่มประสิทธิภาพ
คุณเลือกตัวเลือกการหาปริมาณหลังการฝึกได้หลายแบบ ตารางสรุปตัวเลือกและประโยชน์ที่ได้รับมีดังนี้
| เทคนิค | ข้อดี | ฮาร์ดแวร์ |
|---|---|---|
| การหาปริมาณช่วงไดนามิก | เล็กลง 4 เท่า เร็วขึ้น 2-3 เท่า | CPU |
| การหาปริมาณจำนวนเต็มแบบเต็ม | เล็กลง 4 เท่า เร็วขึ้น 3 เท่าขึ้นไป | CPU, Edge TPU, ไมโครคอนโทรลเลอร์ |
| การกำหนดปริมาณ Float16 | เล็กลง 2 เท่า, การเร่งความเร็วด้วย GPU | CPU, GPU |
แผนผังการตัดสินใจต่อไปนี้จะช่วยพิจารณาว่าวิธีการหาปริมาณหลังการฝึก วิธีใดดีที่สุดสำหรับกรณีการใช้งานของคุณ
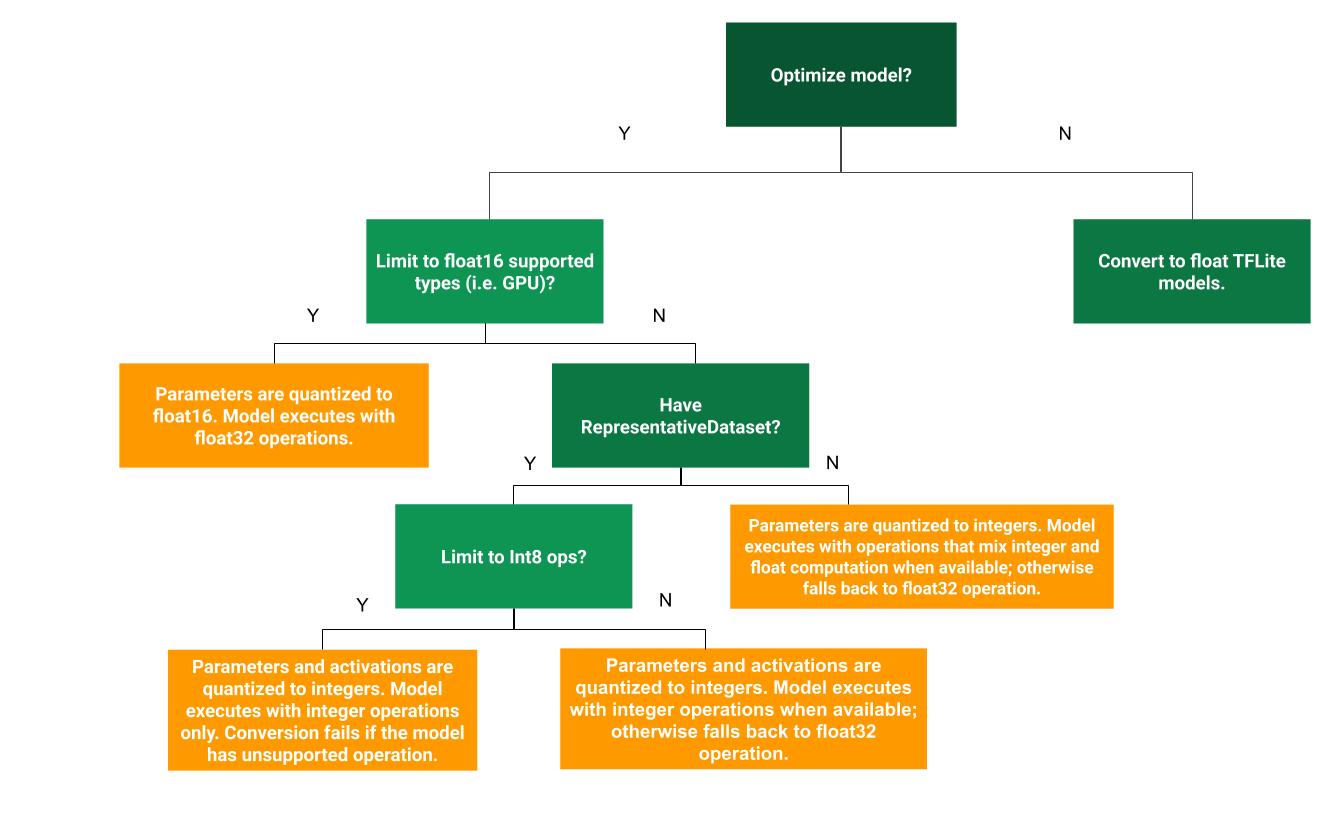
ไม่มีการควอนไทซ์
เราขอแนะนำให้เริ่มต้นด้วยการแปลงเป็นโมเดล TFLite โดยไม่ใช้การลดขนาด การดำเนินการนี้จะสร้างโมเดล TFLite แบบทศนิยม
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
เราขอแนะนำให้คุณทำขั้นตอนนี้เป็นขั้นตอนแรกเพื่อยืนยันว่าโอเปอเรเตอร์ของโมเดล TF ต้นฉบับเข้ากันได้กับ TFLite และยังใช้เป็นพื้นฐานในการแก้ไขข้อผิดพลาดในการกำหนดปริมาณที่เกิดจากวิธีการกำหนดปริมาณหลังการฝึกได้อีกด้วย เช่น หากโมเดล TFLite ที่ทำให้เล็กลงให้ผลลัพธ์ที่ไม่คาดคิด ในขณะที่โมเดล TFLite แบบลอยให้ผลลัพธ์ที่ถูกต้อง เราจะจำกัดปัญหาให้แคบลงได้เป็นข้อผิดพลาดที่เกิดจากโอเปอเรเตอร์ TFLite เวอร์ชันที่ทำให้เล็กลง
การหาปริมาณช่วงไดนามิก
การหาปริมาณช่วงแบบไดนามิกช่วยลดการใช้หน่วยความจำและเพิ่มความเร็วในการคำนวณ โดยที่คุณไม่ต้องระบุชุดข้อมูลตัวแทนสำหรับการปรับเทียบ การหาปริมาณประเภทนี้จะหาปริมาณแบบคงที่เฉพาะน้ำหนักจากจุดลอยตัวเป็นจำนวนเต็มในเวลาที่แปลง ซึ่งให้ความแม่นยำ 8 บิต
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
เพื่อลดเวลาในการตอบสนองระหว่างการอนุมานให้ดียิ่งขึ้น โอเปอเรเตอร์ "ช่วงไดนามิก" จะทำการหาปริมาณการเปิดใช้งานแบบไดนามิกตามช่วงเป็น 8 บิต และทำการ คำนวณด้วยน้ำหนักและการเปิดใช้งานแบบ 8 บิต การเพิ่มประสิทธิภาพนี้จะให้เวลาในการตอบสนองที่ใกล้เคียงกับการอนุมานแบบจุดคงที่อย่างสมบูรณ์ อย่างไรก็ตาม เอาต์พุตจะยังคง จัดเก็บโดยใช้จุดลอยตัว ดังนั้นความเร็วที่เพิ่มขึ้นของการดำเนินการช่วงไดนามิกจึงน้อยกว่าการคำนวณแบบจุดคงที่เต็มรูปแบบ
การหาปริมาณจำนวนเต็มแบบเต็ม
คุณสามารถปรับปรุงเวลาในการตอบสนองเพิ่มเติม ลดการใช้หน่วยความจำสูงสุด และ ความเข้ากันได้กับอุปกรณ์ฮาร์ดแวร์หรือตัวเร่งที่มีจำนวนเต็มเท่านั้นได้โดยตรวจสอบว่า การคำนวณโมเดลทั้งหมดเป็นจำนวนเต็มที่กำหนด
สำหรับการวัดปริมาณจำนวนเต็มแบบเต็ม คุณต้องปรับเทียบหรือประมาณช่วง
กล่าวคือ (ต่ำสุด สูงสุด) ของเทนเซอร์ทศนิยมทั้งหมดในโมเดล Tensor ตัวแปร เช่น อินพุตของโมเดล
การเปิดใช้งาน (เอาต์พุตของเลเยอร์กลาง) และเอาต์พุตของโมเดลจะปรับเทียบไม่ได้
เว้นแต่เราจะเรียกใช้รอบการอนุมาน 2-3 รอบ ซึ่งต่างจาก Tensor ค่าคงที่ เช่น น้ำหนักและอคติ ด้วยเหตุนี้ ตัวแปลงจึงต้องมีชุดข้อมูลที่เป็นตัวแทนเพื่อปรับเทียบ ชุดข้อมูลนี้อาจเป็นชุดข้อมูลย่อยขนาดเล็ก (ประมาณ 100-500 ตัวอย่าง) ของข้อมูลการฝึกหรือการตรวจสอบ โปรดดูฟังก์ชัน representative_dataset() ด้านล่าง
ตั้งแต่ TensorFlow เวอร์ชัน 2.7 คุณสามารถระบุชุดข้อมูลตัวแทนผ่านลายเซ็นได้ดังตัวอย่างต่อไปนี้
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
หากมีลายเซ็นมากกว่า 1 รายการในโมเดล TensorFlow ที่ระบุ คุณสามารถ ระบุชุดข้อมูลหลายรายการได้โดยการระบุคีย์ลายเซ็น
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
คุณสร้างชุดข้อมูลตัวแทนได้โดยระบุรายการเทนเซอร์อินพุต
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
ตั้งแต่ TensorFlow เวอร์ชัน 2.7 เป็นต้นไป เราขอแนะนำให้ใช้แนวทางตามลายเซ็น มากกว่าแนวทางตามรายการเทนเซอร์อินพุต เนื่องจากลำดับเทนเซอร์อินพุตสามารถ พลิกกลับได้ง่าย
คุณสามารถใช้ชุดข้อมูลจำลองเพื่อวัตถุประสงค์ในการทดสอบได้ดังนี้
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
จำนวนเต็มที่มีการสำรองข้อมูลแบบลอยตัว (ใช้การป้อน/ส่งออกแบบลอยตัวเริ่มต้น)
หากต้องการทําให้โมเดลเป็นจํานวนเต็มทั้งหมด แต่ใช้ตัวดำเนินการแบบลอยเมื่อไม่มีการใช้งานจำนวนเต็ม (เพื่อให้มั่นใจว่าการแปลงจะเกิดขึ้นอย่างราบรื่น) ให้ทําตามขั้นตอนต่อไปนี้
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
จำนวนเต็มเท่านั้น
การสร้างโมเดลจำนวนเต็มเท่านั้นเป็นกรณีการใช้งานทั่วไปสำหรับ LiteRT สำหรับ ไมโครคอนโทรลเลอร์และ Coral Edge TPU
นอกจากนี้ เพื่อให้มั่นใจว่าอุปกรณ์ที่รองรับเฉพาะจำนวนเต็ม (เช่น ไมโครคอนโทรลเลอร์ 8 บิต) และตัวเร่งความเร็ว (เช่น Coral Edge TPU) จะใช้งานร่วมกันได้ คุณสามารถบังคับใช้การแปลงให้เล็กลงเป็นจำนวนเต็มทั้งหมดสำหรับทุกการดำเนินการ รวมถึงอินพุตและเอาต์พุตได้โดยทำตามขั้นตอนต่อไปนี้
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
การกำหนดปริมาณ Float16
คุณลดขนาดโมเดลจุดลอยได้โดยการควอนไทซ์น้ำหนักเป็น float16 ซึ่งเป็นมาตรฐาน IEEE สำหรับตัวเลขจุดลอยแบบ 16 บิต หากต้องการเปิดใช้การหาปริมาณน้ำหนัก float16 ให้ทำตามขั้นตอนต่อไปนี้
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
ข้อดีของการกำหนดปริมาณ float16 มีดังนี้
- ซึ่งจะลดขนาดโมเดลได้สูงสุดครึ่งหนึ่ง (เนื่องจากน้ำหนักทั้งหมดจะลดลงครึ่งหนึ่งของขนาดเดิม)
- ซึ่งจะทำให้ความแม่นยำลดลงเพียงเล็กน้อย
- โดยรองรับตัวแทนบางราย (เช่น ตัวแทน GPU) ซึ่งสามารถทำงาน กับข้อมูล float16 ได้โดยตรง จึงทำให้การดำเนินการเร็วกว่าการคำนวณ float32
ข้อเสียของการกำหนดปริมาณ float16 มีดังนี้
- ซึ่งไม่ได้ลดเวลาในการตอบสนองมากเท่ากับการหาปริมาณไปยังคณิตศาสตร์แบบจุดคงที่
- โดยค่าเริ่มต้น โมเดลที่แปลงเป็นควอนไทซ์ float16 จะ "ยกเลิกการแปลงเป็นควอนไทซ์" ค่าถ่วงน้ำหนัก เป็น float32 เมื่อเรียกใช้ใน CPU (โปรดทราบว่าตัวแทน GPU จะไม่ทำการยกเลิกการหาปริมาณนี้ เนื่องจากสามารถทำงานกับข้อมูล float16 ได้)
จำนวนเต็มเท่านั้น: การเปิดใช้งานแบบ 16 บิตที่มีน้ำหนักแบบ 8 บิต (ทดลอง)
นี่คือรูปแบบการหาปริมาณเวอร์ชันทดลอง ซึ่งคล้ายกับสคีมา "จำนวนเต็มเท่านั้น" แต่การเปิดใช้งานจะได้รับการหาปริมาณตามช่วงเป็น 16 บิต ส่วนน้ำหนัก จะได้รับการหาปริมาณเป็นจำนวนเต็ม 8 บิต และอคติจะได้รับการหาปริมาณเป็นจำนวนเต็ม 64 บิต ซึ่ง เรียกว่าการหาปริมาณ 16x8
ข้อดีหลักของการหาปริมาณนี้คือช่วยปรับปรุงความแม่นยำได้อย่างมาก แต่จะเพิ่มขนาดโมเดลเพียงเล็กน้อยเท่านั้น
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
หากโมเดลไม่รองรับการหาปริมาณ 16x8 สำหรับตัวดำเนินการบางตัว โมเดลจะยังคงหาปริมาณได้ แต่ตัวดำเนินการที่ไม่รองรับจะยังคงเป็นแบบลอย ควรเพิ่มตัวเลือกต่อไปนี้ลงใน target_spec เพื่ออนุญาตการดำเนินการนี้
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
ตัวอย่างกรณีการใช้งานที่ความแม่นยำที่ได้รับการปรับปรุงจากรูปแบบการหาปริมาณนี้มีประโยชน์ ได้แก่
- ความละเอียดสูง
- การประมวลผลสัญญาณเสียง เช่น การตัดเสียงรบกวนและการสร้างบีม
- การลดสัญญาณรบกวนในรูปภาพ
- การสร้าง HDR ใหม่จากรูปภาพเดียว
ข้อเสียของการหาปริมาณนี้คือ
- ปัจจุบันการอนุมานช้ากว่าจำนวนเต็ม 8 บิตอย่างเห็นได้ชัดเนื่องจาก ไม่มีการติดตั้งใช้งานเคอร์เนลที่เพิ่มประสิทธิภาพ
- ปัจจุบันยังใช้ร่วมกับตัวแทน TFLite ที่เร่งด้วยฮาร์ดแวร์ที่มีอยู่ไม่ได้
ดูบทแนะนำสำหรับโหมดการหาปริมาณนี้ได้ที่นี่
ความแม่นยำของโมเดล
เนื่องจากน้ำหนักจะได้รับการควอนไทซ์หลังการฝึก จึงอาจมีความแม่นยำลดลง โดยเฉพาะอย่างยิ่งสำหรับเครือข่ายขนาดเล็ก โมเดลที่ได้รับการควอนไทซ์อย่างสมบูรณ์และฝึกล่วงหน้ามีให้บริการสำหรับเครือข่ายที่เฉพาะเจาะจงใน Kaggle Models คุณควรตรวจสอบความแม่นยำของโมเดลที่ผ่านการควอนไทซ์เพื่อยืนยันว่า ความแม่นยำที่ลดลงอยู่ในขีดจำกัดที่ยอมรับได้ มีเครื่องมือสำหรับ ประเมินความแม่นยำของโมเดล LiteRT
หรือหากความแม่นยำลดลงมากเกินไป ให้ลองใช้การฝึกที่คำนึงถึง การหาปริมาณ อย่างไรก็ตาม การทำเช่นนี้ต้องมีการแก้ไขระหว่างการฝึกโมเดลเพื่อเพิ่มโหนดการหาปริมาณปลอม ในขณะที่เทคนิคการหาปริมาณหลังการฝึกในหน้านี้ ใช้โมเดลที่ฝึกไว้ล่วงหน้าที่มีอยู่
การแสดงผลสำหรับเทนเซอร์ที่ผ่านการควอนไทซ์
การหาปริมาณ 8 บิตจะประมาณค่าทศนิยมโดยใช้สูตรต่อไปนี้
\[real\_value = (int8\_value - zero\_point) \times scale\]
การแสดงประกอบด้วย 2 ส่วนหลักๆ ดังนี้
น้ำหนักต่อแกน (หรือต่อแชแนล) หรือต่อเทนเซอร์ที่แสดงด้วยค่าเติมเต็มแบบ 2 ของ int8 ในช่วง [-127, 127] โดยมีจุดศูนย์เท่ากับ 0
การเปิดใช้งาน/อินพุตต่อเทนเซอร์ที่แสดงด้วยค่าส่วนเติมเต็ม 2 ของ int8 ใน ช่วง [-128, 127] โดยมีจุดศูนย์ในช่วง [-128, 127]
หากต้องการดูรายละเอียดของรูปแบบการหาปริมาณ โปรดดูข้อกำหนดการหาปริมาณ ผู้ให้บริการฮาร์ดแวร์ที่ต้องการเชื่อมต่อกับอินเทอร์เฟซตัวแทนของ TensorFlow Lite ควรใช้รูปแบบการหาปริมาณ ที่อธิบายไว้