
Die Quantisierung nach dem Training ist eine Konvertierungsmethode, mit der Sie die Modellgröße verringern und gleichzeitig die Latenz für CPU- und Hardwarebeschleuniger verbessern können, wobei die Modellgenauigkeit wenig beeinträchtigt wird. Sie können ein bereits trainiertes TensorFlow-Modell mit Gleitkommazahlen quantisieren, wenn Sie es mit dem LiteRT Converter in das LiteRT-Format konvertieren.
Optimierungsmethoden
Es gibt mehrere Optionen für die Quantisierung nach dem Training. In der folgenden Tabelle sind die Optionen und ihre Vorteile zusammengefasst:
| Verfahren | Vorteile | Hardware |
|---|---|---|
| Quantisierung des dynamischen Bereichs | 4-mal kleiner, 2- bis 3-mal schneller | CPU |
| Vollständige Ganzzahlquantisierung | 4-mal kleiner, 3-mal schneller | CPU, Edge TPU, Mikrocontroller |
| Float16-Quantisierung | 2-mal kleiner, GPU-Beschleunigung | CPU, GPU |
Der folgende Entscheidungsbaum kann Ihnen bei der Entscheidung helfen, welche Methode zur Quantisierung nach dem Training für Ihren Anwendungsfall am besten geeignet ist:
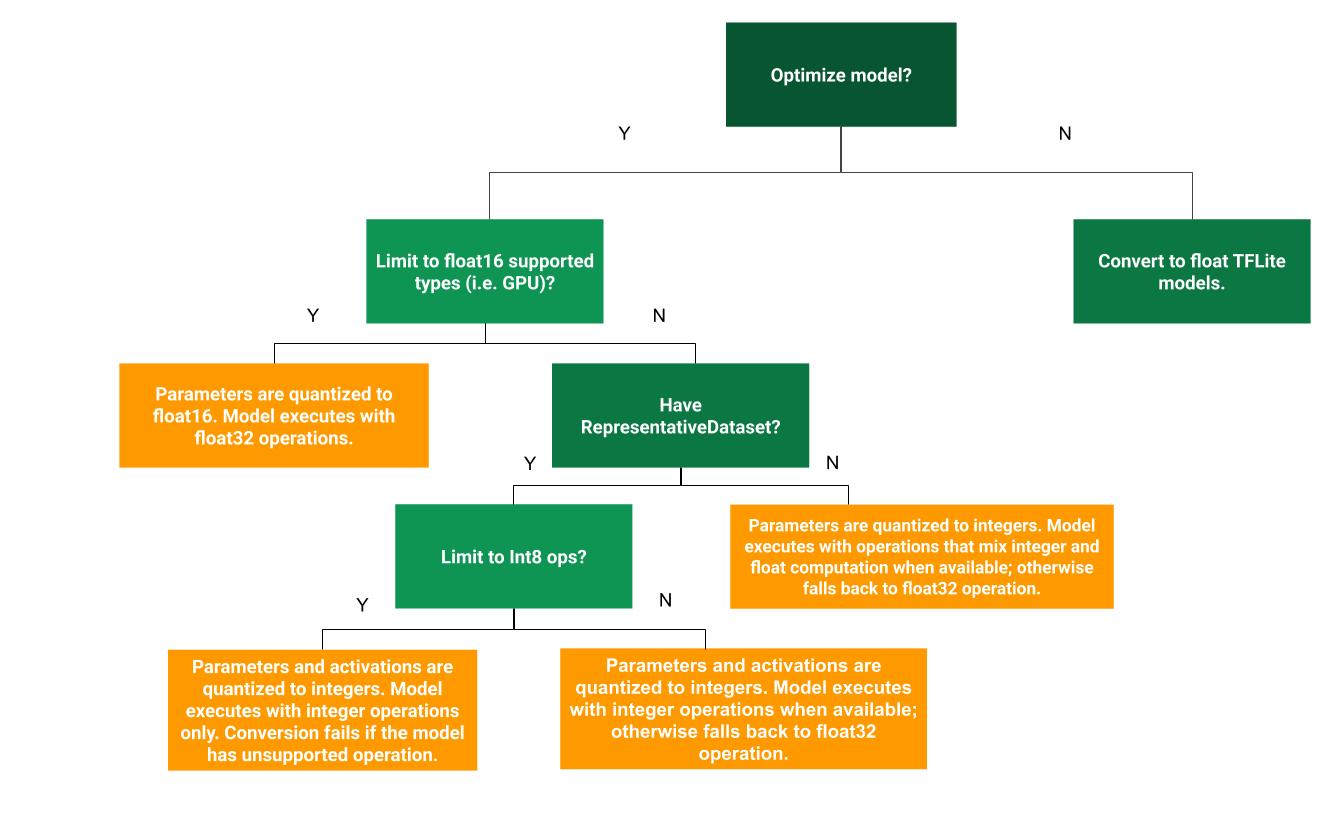
Keine Quantisierung
Die Konvertierung in ein TFLite-Modell ohne Quantisierung ist ein empfohlener Ausgangspunkt. Dadurch wird ein TFLite-Modell mit Gleitkommazahlen generiert.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
Wir empfehlen, dies als ersten Schritt zu tun, um zu prüfen, ob die Operatoren des ursprünglichen TensorFlow-Modells mit TFLite kompatibel sind. Außerdem können Sie so Quantisierungsfehler beheben, die durch nachfolgende Quantisierungsmethoden nach dem Training eingeführt wurden. Wenn beispielsweise ein quantisiertes TFLite-Modell unerwartete Ergebnisse liefert, während das TFLite-Modell mit Gleitkommazahlen genau ist, können wir das Problem auf Fehler eingrenzen, die durch die quantisierte Version der TFLite-Operatoren verursacht werden.
Quantisierung des Dynamikbereichs
Die dynamische Bereichsquantisierung führt zu einer geringeren Speichernutzung und schnelleren Berechnungen, ohne dass Sie einen repräsentativen Datensatz für die Kalibrierung bereitstellen müssen. Bei dieser Art der Quantisierung werden nur die Gewichte statisch von Gleitkomma- zu Ganzzahlen konvertiert. Das bietet eine Genauigkeit von 8 Bit:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
Um die Latenz während der Inferenz weiter zu reduzieren, quantisieren „dynamic-range“-Operatoren Aktivierungen dynamisch basierend auf ihrem Bereich auf 8 Bit und führen Berechnungen mit 8‑Bit-Gewichten und ‑Aktivierungen durch. Diese Optimierung bietet Latenzen, die denen von Inferenzvorgängen mit vollständig festen Gleitkommazahlen nahekommen. Die Ausgaben werden jedoch weiterhin als Gleitkommazahlen gespeichert. Die höhere Geschwindigkeit von Operationen mit dynamischem Bereich ist daher geringer als bei einer vollständigen Festkomma-Berechnung.
Ganzzahlige Quantisierung
Sie können die Latenz weiter verbessern, die maximale Speichernutzung reduzieren und die Kompatibilität mit Hardwaregeräten oder Beschleunigern, die nur Ganzzahlen unterstützen, sicherstellen, indem Sie dafür sorgen, dass alle Berechnungen im Modell ganzzahlig quantisiert werden.
Für die Ganzzahlquantisierung müssen Sie den Bereich kalibrieren oder schätzen. (min, max) aller Gleitkommatensoren im Modell. Im Gegensatz zu konstanten Tensoren wie Gewichten und Bias können variable Tensoren wie Modelleingabe, Aktivierungen (Ausgaben von Zwischenschichten) und Modellausgabe nur kalibriert werden, wenn wir einige Inferenzzyklen durchlaufen. Daher ist ein repräsentatives Dataset erforderlich, um den Konverter zu kalibrieren. Dieses Dataset kann eine kleine Teilmenge (etwa 100–500 Beispiele) der Trainings- oder Validierungsdaten sein. Weitere Informationen finden Sie unten bei der Funktion representative_dataset().
Ab TensorFlow 2.7 können Sie das repräsentative Dataset über eine Signatur angeben, wie im folgenden Beispiel:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
Wenn das angegebene TensorFlow-Modell mehrere Signaturen enthält, können Sie das Dataset angeben, indem Sie die Signaturschlüssel angeben:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
Sie können das repräsentative Dataset generieren, indem Sie eine Liste mit Eingabetensoren angeben:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
Seit TensorFlow 2.7 empfehlen wir, den signaturbasierten Ansatz anstelle des auf der Eingabe-Tensorliste basierenden Ansatzes zu verwenden, da die Reihenfolge der Eingabe-Tensoren leicht geändert werden kann.
Für Testzwecke können Sie ein Dummy-Dataset wie folgt verwenden:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Ganzzahl mit Float-Fallback (mit Standard-Float-Ein-/Ausgabe)
Wenn Sie ein Modell vollständig in Ganzzahlen quantisieren, aber Gleitkomma-Operatoren verwenden möchten, wenn es keine Ganzzahlimplementierung gibt (um eine reibungslose Konvertierung zu gewährleisten), gehen Sie so vor:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Nur Ganzzahl
Die Erstellung von Modellen, die nur Ganzzahlen verwenden, ist ein häufiger Anwendungsfall für LiteRT for Microcontrollers und Coral Edge TPUs.
Um die Kompatibilität mit Geräten, die nur Ganzzahlen unterstützen (z. B. 8-Bit-Mikrocontroller) und Beschleunigern (z. B. Coral Edge TPU) zu gewährleisten, können Sie die vollständige Ganzzahlquantisierung für alle Vorgänge, einschließlich der Ein- und Ausgabe, mit den folgenden Schritten erzwingen:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Float16-Quantisierung
Sie können die Größe eines Gleitkommamodells reduzieren, indem Sie die Gewichte auf float16 quantisieren, den IEEE-Standard für 16-Bit-Gleitkommazahlen. So aktivieren Sie die float16-Quantisierung von Gewichten:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
Die Vorteile der float16-Quantisierung sind:
- Dadurch wird die Modellgröße um bis zu die Hälfte reduziert, da alle Gewichte nur noch halb so groß sind wie ursprünglich.
- Die Genauigkeit wird nur minimal beeinträchtigt.
- Es unterstützt einige Delegates (z.B. den GPU-Delegate), die direkt mit float16-Daten arbeiten können, was zu einer schnelleren Ausführung als bei float32-Berechnungen führt.
Die Nachteile der float16-Quantisierung sind:
- Die Latenz wird dadurch nicht so stark reduziert wie bei einer Quantisierung auf Festkomma-Mathematik.
- Standardmäßig werden die Gewichtungswerte eines float16-quantisierten Modells beim Ausführen auf der CPU „dequantisiert“ (in float32 umgewandelt). Hinweis: Der GPU-Delegate führt diese Entquantisierung nicht durch, da er mit float16-Daten arbeiten kann.
Nur Ganzzahl: 16‑Bit-Aktivierungen mit 8‑Bit-Gewichtungen (experimentell)
Dies ist ein experimentelles Quantisierungsschema. Es ähnelt dem Schema „Nur Ganzzahlen“, aber Aktivierungen werden basierend auf ihrem Bereich auf 16 Bit quantisiert, Gewichte werden in 8-Bit-Ganzzahlen quantisiert und der Bias wird in 64-Bit-Ganzzahlen quantisiert. Dies wird im Folgenden als 16x8-Quantisierung bezeichnet.
Der Hauptvorteil dieser Quantisierung besteht darin, dass sie die Genauigkeit erheblich verbessern kann, die Modellgröße aber nur geringfügig erhöht.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
Wenn die 16‑Bit-Quantisierung mit 8 Bit-Ganzzahlen für einige Operatoren im Modell nicht unterstützt wird, kann das Modell trotzdem quantisiert werden. Nicht unterstützte Operatoren werden jedoch als Gleitkommazahlen beibehalten. Die folgende Option sollte dem target_spec hinzugefügt werden, um dies zu ermöglichen.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Beispiele für Anwendungsfälle, in denen die durch dieses Quantisierungsschema erzielten Verbesserungen der Genauigkeit von Vorteil sind:
- verbesserte Auflösung
- Audio-Signalverarbeitung wie Geräuschunterdrückung und Beamforming,
- Bildrauschen entfernen
- HDR-Rekonstruktion aus einem einzelnen Bild.
Der Nachteil dieser Quantisierung ist:
- Derzeit ist die Inferenz aufgrund der fehlenden optimierten Kernel-Implementierung deutlich langsamer als bei 8-Bit-Ganzzahlen.
- Derzeit ist sie nicht mit den vorhandenen hardwarebeschleunigten TFLite-Delegaten kompatibel.
Eine Anleitung für diesen Quantisierungsmodus finden Sie hier.
Modellgenauigkeit
Da Gewichte nach dem Training quantisiert werden, kann es zu einem Genauigkeitsverlust kommen, insbesondere bei kleineren Netzwerken. Vortrainierte, vollständig quantisierte Modelle sind für bestimmte Netzwerke in Kaggle Models verfügbar. Es ist wichtig, die Genauigkeit des quantisierten Modells zu prüfen, um sicherzustellen, dass eine etwaige Beeinträchtigung der Genauigkeit innerhalb akzeptabler Grenzen liegt. Es gibt Tools, mit denen Sie die Genauigkeit von LiteRT-Modellen bewerten können.
Wenn der Genauigkeitsverlust zu hoch ist, können Sie alternativ quantisierungsbewusstes Training verwenden. Dazu sind jedoch Änderungen während des Modelltrainings erforderlich, um gefälschte Quantisierungs-Nodes hinzuzufügen. Die auf dieser Seite beschriebenen Techniken zur Quantisierung nach dem Training verwenden dagegen ein vorhandenes vortrainiertes Modell.
Darstellung für quantisierte Tensoren
Bei der 8‑Bit-Quantisierung werden Gleitkommawerte mit der folgenden Formel angenähert.
\[real\_value = (int8\_value - zero\_point) \times scale\]
Die Darstellung besteht aus zwei Hauptteilen:
Gewichte pro Achse (auch pro Channel) oder pro Tensor, die durch int8-Zweierkomplementwerte im Bereich [–127, 127] mit dem Nullpunkt 0 dargestellt werden.
Aktivierungen/Eingaben pro Tensor, die durch int8-Zweierkomplementwerte im Bereich [-128, 127] mit einem Nullpunkt im Bereich [-128, 127] dargestellt werden.
Eine detaillierte Beschreibung unseres Quantisierungsschemas finden Sie in unserer Quantisierungsspezifikation. Hardwareanbieter, die die Delegate-Schnittstelle von TensorFlow Lite nutzen möchten, sollten das dort beschriebene Quantisierungsschema implementieren.