
Eğitim sonrası nicemleme, model doğruluğunda çok az düşüşle model boyutunu küçültebilen, aynı zamanda CPU ve donanım hızlandırıcı gecikmesini iyileştirebilen bir dönüştürme tekniğidir. LiteRT dönüştürücüyü kullanarak önceden eğitilmiş bir float TensorFlow modelini LiteRT biçimine dönüştürürken nicemleyebilirsiniz.
Optimizasyon Yöntemleri
Eğitim sonrası nicemleme için çeşitli seçenekler vardır. Aşağıda, seçeneklerin ve sağladıkları avantajların özet tablosunu bulabilirsiniz:
| Teknik | Avantajları | Donanım |
|---|---|---|
| Dinamik aralık nicelendirme | 4 kat daha küçük, 2-3 kat daha hızlı | CPU |
| Tam sayı nicelendirme | 4 kat daha küçük, 3 kat daha hızlı | CPU, Edge TPU, Mikro denetleyiciler |
| Float16 nicemleme | 2 kat daha küçük, GPU hızlandırma | CPU, GPU |
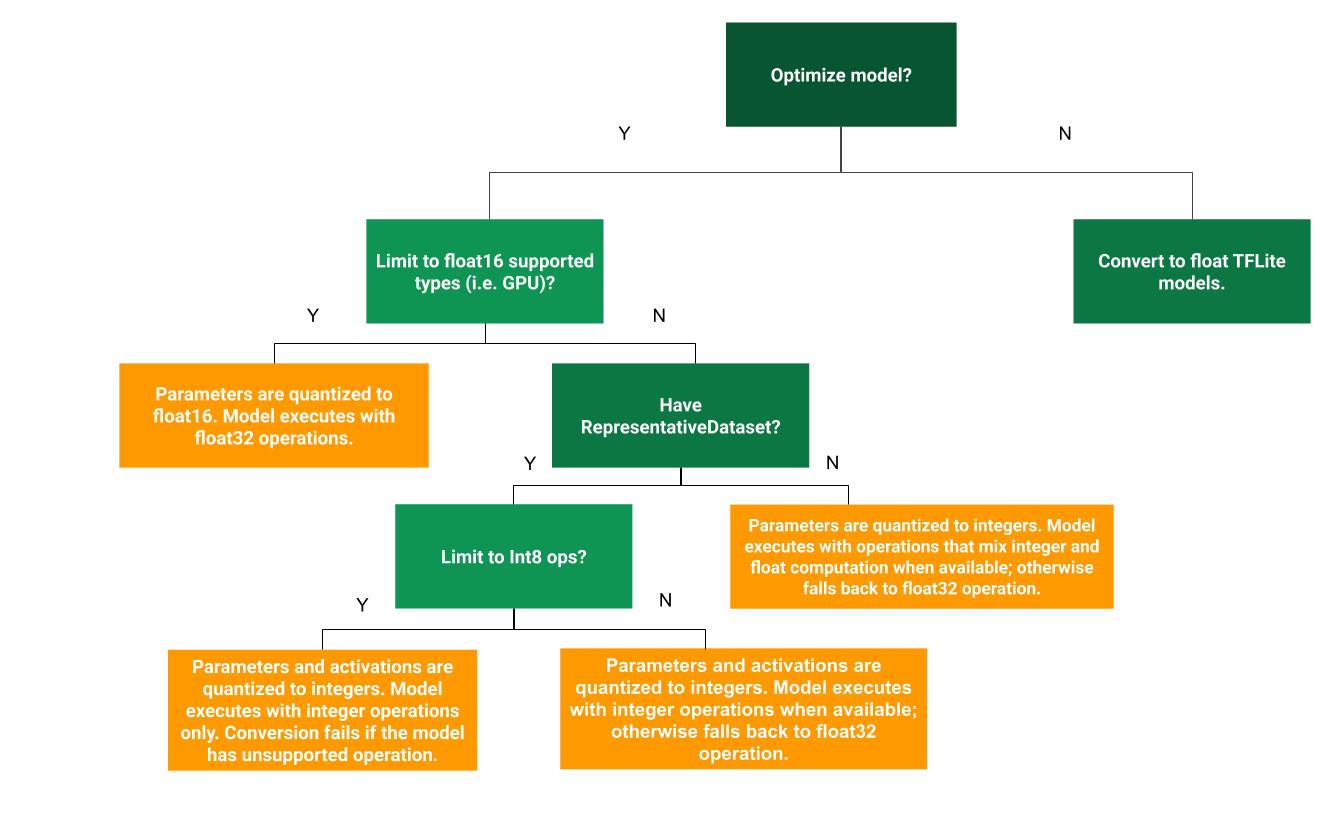
Aşağıdaki karar ağacı, eğitim sonrası nicemleme yöntemlerinden hangisinin kullanım alanınız için en uygun olduğunu belirlemenize yardımcı olabilir:
Kuantizasyon Yok
Kuantizasyon olmadan TFLite modeline dönüştürme, önerilen bir başlangıç noktasıdır. Bu işlem, kayan nokta TFLite modeli oluşturur.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
Bunu, orijinal TF modelinin operatörlerinin TFLite ile uyumlu olduğunu doğrulamak için ilk adım olarak yapmanızı öneririz. Bu adım, eğitim sonrası nicemleme yöntemleriyle ortaya çıkan nicemleme hatalarını ayıklamak için temel olarak da kullanılabilir. Örneğin, ölçülen TFLite modeli beklenmedik sonuçlar üretirken kayan nokta TFLite modeli doğru sonuçlar veriyorsa sorunu, TFLite operatörlerinin ölçülen sürümünün neden olduğu hatalarla daraltabiliriz.
Dinamik aralık nicemleme
Dinamik aralık nicemleme, kalibrasyon için temsili bir veri kümesi sağlamanız gerekmeden bellek kullanımını azaltır ve daha hızlı hesaplama sağlar. Bu tür bir nicemleme, yalnızca dönüşüm sırasında kayan noktalı sayılardan tam sayılara ağırlıkları statik olarak nicemler ve 8 bitlik hassasiyet sağlar:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
Çıkarım sırasında gecikmeyi daha da azaltmak için "dynamic-range" operatörleri, etkinleştirmeleri aralıklarına göre dinamik olarak 8 bit'e nicelleştirir ve 8 bit ağırlıklar ve etkinleştirmelerle hesaplamalar yapar. Bu optimizasyon, tamamen sabit noktalı çıkarımlara yakın gecikmeler sağlar. Ancak çıkışlar yine de kayan nokta kullanılarak depolanır. Bu nedenle, dinamik aralık işlemlerinin hızındaki artış, tam sabit nokta hesaplamasına göre daha azdır.
Tam sayı kuantizasyonu
Tüm model matematik işlemlerinin tamsayı olarak nicelendirildiğinden emin olarak daha fazla gecikme iyileştirmesi, en yüksek bellek kullanımında azalma ve yalnızca tamsayı destekli donanım cihazlar veya hızlandırıcılarla uyumluluk elde edebilirsiniz.
Tam sayı kuantizasyonu için aralığı kalibre etmeniz veya tahmin etmeniz gerekir. Örneğin: Modeldeki tüm kayan noktalı tensörlerin (min, maks) değerleri. Ağırlıklar ve sapmalar gibi sabit tensörlerin aksine, model girişi, etkinleştirmeler (ara katmanların çıkışları) ve model çıkışı gibi değişken tensörler, birkaç çıkarım döngüsü çalıştırmadığımız sürece kalibre edilemez. Bu nedenle dönüştürücülerin kalibre edilmesi için temsili bir veri kümesi gerekir. Bu veri kümesi, eğitim veya doğrulama verilerinin küçük bir alt kümesi (yaklaşık 100-500 örnek) olabilir. Aşağıdaki representative_dataset() işlevine bakın.
TensorFlow 2.7 sürümünden itibaren, temsili veri kümesini aşağıdaki örnekte gösterildiği gibi bir imza aracılığıyla belirtebilirsiniz:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
Belirli TensorFlow modelinde birden fazla imza varsa imza anahtarlarını belirterek birden fazla veri kümesi belirtebilirsiniz:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
Giriş tensör listesi sağlayarak temsili veri kümesi oluşturabilirsiniz:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
TensorFlow 2.7 sürümünden itibaren, giriş tensörlerinin sırası kolayca değiştirilebildiğinden giriş tensör listesine dayalı yaklaşım yerine imzaya dayalı yaklaşımı kullanmanızı öneririz.
Test amacıyla aşağıdaki gibi bir sahte veri kümesi kullanabilirsiniz:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Ondalıklı sayı geri dönüşü olan tam sayı (varsayılan ondalıklı sayı girişi/çıkışı kullanılarak)
Bir modeli tamamen tamsayı olarak nicelendirmek ancak tamsayı uygulaması olmayan durumlarda kayan nokta operatörlerini kullanmak (dönüşümün sorunsuz bir şekilde gerçekleşmesini sağlamak için) istiyorsanız aşağıdaki adımları uygulayın:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Yalnızca tam sayı
Yalnızca tam sayı içeren modeller oluşturmak, LiteRT for Microcontrollers ve Coral Edge TPU'lar için yaygın bir kullanım alanıdır.
Ayrıca, yalnızca tam sayı cihazlarla (ör. 8 bit mikrodenetleyiciler) ve hızlandırıcılarla (ör. Coral Edge TPU) uyumluluğu sağlamak için aşağıdaki adımları uygulayarak giriş ve çıkış dahil tüm işlemler için tam sayı nicemlemeyi zorunlu kılabilirsiniz:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Float16 nicemleme
Kayan nokta modelinin boyutunu, ağırlıkları 16 bitlik kayan nokta sayıları için IEEE standardı olan float16'ya nicelendirerek azaltabilirsiniz. Ağırlıkların float16 nicelendirmesini etkinleştirmek için aşağıdaki adımları uygulayın:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
float16 nicemlemenin avantajları şunlardır:
- Model boyutunu yarı yarıya azaltır (tüm ağırlıklar orijinal boyutlarının yarısı kadar olur).
- Doğrulukta minimum kayba neden olur.
- Bazı temsilcileri (ör.GPU temsilcisi) destekler. Bu temsilciler, doğrudan float16 verileri üzerinde çalışabilir ve float32 hesaplamalarına kıyasla daha hızlı yürütme sağlar.
float16 nicemlemenin dezavantajları şunlardır:
- Gecikmeyi, sabit nokta matematiğine nicemleme kadar azaltmaz.
- Varsayılan olarak, float16 nicelendirilmiş bir model, CPU'da çalıştırıldığında ağırlık değerlerini float32'ye "nicelendirilmemiş" hale getirir. (GPU yetkilisi, float16 verileri üzerinde çalışabildiğinden bu nicelikten arındırma işlemini gerçekleştirmeyecektir.)
Yalnızca tam sayı: 8 bit ağırlıklarla 16 bit etkinleştirme (deneysel)
Bu, deneysel bir nicemleme şemasıdır. Bu, "yalnızca tam sayı" şemasına benzer ancak etkinleştirmeler 16 bit aralığına göre nicelleştirilir, ağırlıklar 8 bit tam sayı olarak nicelleştirilir ve önyargı 64 bit tam sayı olarak nicelleştirilir. Bu, 16x8 nicemleme olarak adlandırılır.
Bu nicelendirmenin temel avantajı, doğruluğu önemli ölçüde artırabilmesi ancak model boyutunu yalnızca biraz artırmasıdır.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
Modeldeki bazı operatörler için 16x8 nicemleme desteklenmiyorsa model yine de nicemlenebilir ancak desteklenmeyen operatörler kayan nokta olarak tutulur. Buna izin vermek için hedef_spec'e aşağıdaki seçenek eklenmelidir.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Bu nicelendirme şemasıyla sağlanan doğruluk iyileştirmelerinin kullanıldığı alanlara örnek olarak şunlar verilebilir:
- süper çözünürlük,
- Gürültü giderme ve ışın oluşturma gibi ses sinyali işleme,
- görüntüdeki gürültüyü azaltma,
- Tek bir görüntüden HDR yeniden oluşturma
Bu nicelendirmenin dezavantajı şudur:
- Şu anda çıkarım, optimize edilmiş çekirdek uygulaması olmaması nedeniyle 8 bit tam sayıdan belirgin şekilde daha yavaştır.
- Şu anda mevcut donanım hızlandırmalı TFLite temsilcileriyle uyumlu değildir.
Bu nicelendirme moduyla ilgili eğitime buradan ulaşabilirsiniz.
Model doğruluğu
Ağırlıklar eğitim sonrasında nicel hale getirildiğinden, özellikle daha küçük ağlarda doğruluk kaybı olabilir. Tamamen nicelenmiş önceden eğitilmiş modeller, Kaggle Models'da belirli ağlar için sağlanır . Doğruluktaki herhangi bir düşüşün kabul edilebilir sınırlar içinde olduğunu doğrulamak için nicelenmiş modelin doğruluğunu kontrol etmek önemlidir. LiteRT modelinin doğruluğunu değerlendirmeye yönelik araçlar vardır.
Alternatif olarak, doğruluktaki düşüş çok yüksekse nicemlemeye duyarlı eğitim kullanmayı düşünebilirsiniz . Ancak bunu yapmak için model eğitimi sırasında sahte nicemleme düğümleri eklemek üzere değişiklikler yapılması gerekir. Bu sayfadaki eğitim sonrası nicemleme teknikleri ise mevcut önceden eğitilmiş bir modeli kullanır.
Kuantize edilmiş tensörlerin temsili
8 bit nicemleme, kayan nokta değerlerini aşağıdaki formülü kullanarak yaklaşık olarak hesaplar.
\[real\_value = (int8\_value - zero\_point) \times scale\]
Gösterimin iki ana bölümü vardır:
Sıfır noktası 0 olan, [-127, 127] aralığındaki int8 ikiye tamamlama değerleriyle temsil edilen eksen başına (diğer adıyla kanal başına) veya tensör başına ağırlıklar.
[-128, 127] aralığında sıfır noktasıyla birlikte, [-128, 127] aralığındaki int8 ikili tümleyen değerleriyle temsil edilen tensör başına etkinleştirmeler/girişler.
Kuantizasyon şemamızın ayrıntılı görünümü için lütfen kuantizasyon spec belgemize bakın. TensorFlow Lite'ın temsilci arayüzüne bağlanmak isteyen donanım satıcılarının, orada açıklanan kuantizasyon şemasını uygulamaları önerilir.