
کوانتیزاسیون پس از آموزش، یک تکنیک تبدیل است که میتواند اندازه مدل را کاهش دهد و در عین حال تأخیر پردازنده و شتابدهنده سختافزاری را نیز بهبود بخشد، بدون اینکه دقت مدل کمی کاهش یابد. میتوانید یک مدل TensorFlow از نوع float که از قبل آموزش دیده است را هنگام تبدیل آن به فرمت LiteRT با استفاده از LiteRT Converter ، کوانتیزاسیون کنید.
روشهای بهینهسازی
چندین گزینه کوانتیزاسیون پس از آموزش برای انتخاب وجود دارد. در اینجا جدول خلاصهای از گزینهها و مزایای آنها آورده شده است:
| تکنیک | مزایا | سختافزار |
|---|---|---|
| کوانتیزاسیون محدوده دینامیکی | ۴ برابر کوچکتر، ۲ تا ۳ برابر سریعتر | پردازنده |
| کوانتیزاسیون کامل عدد صحیح | ۴ برابر کوچکتر، ۳ برابر سریعتر | پردازنده مرکزی، Edge TPU، میکروکنترلرها |
| کوانتیزاسیون Float16 | دو برابر کوچکتر، شتاب GPU | پردازنده مرکزی، پردازنده گرافیکی |
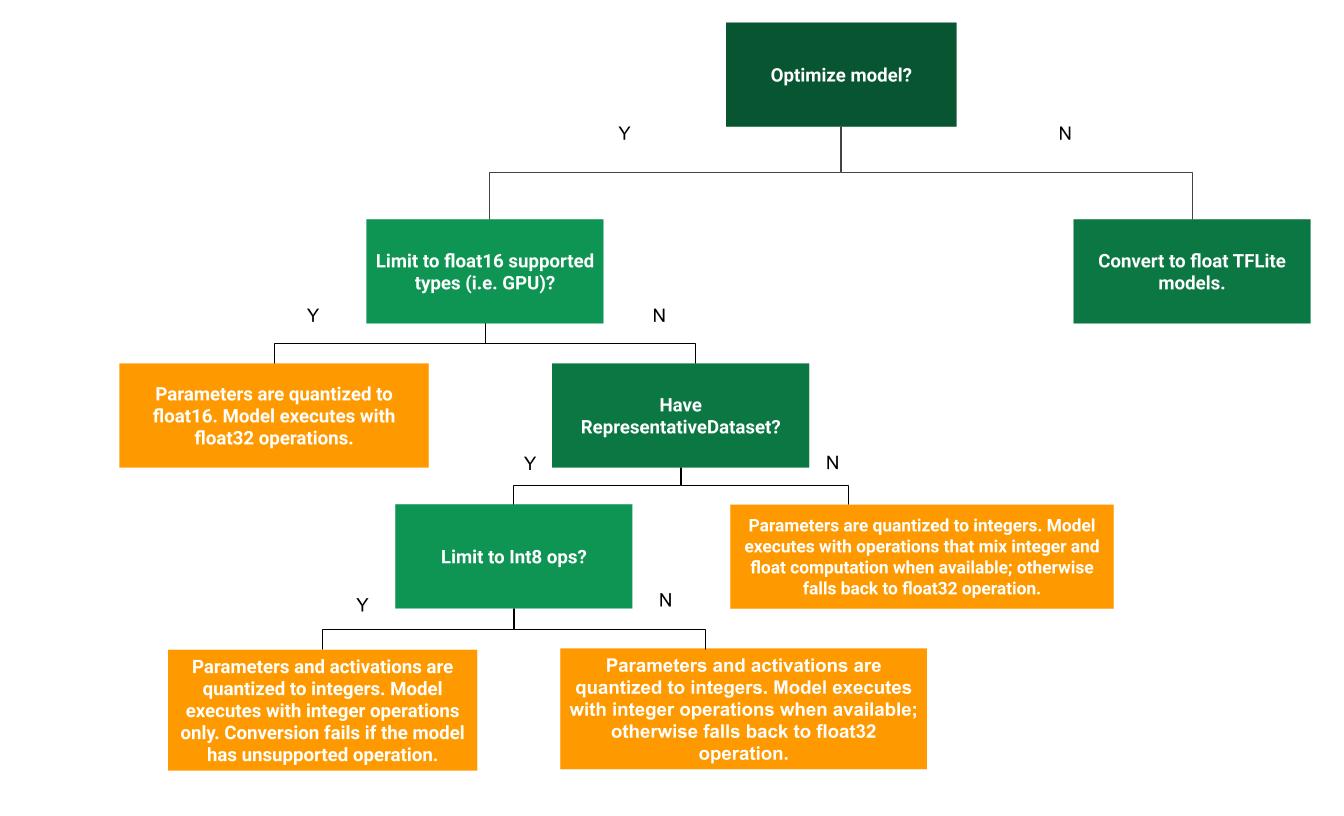
درخت تصمیم زیر میتواند به تعیین اینکه کدام روش کوانتیزاسیون پس از آموزش برای مورد استفاده شما بهترین است، کمک کند:
بدون کوانتیزاسیون
تبدیل به یک مدل TFLite بدون کوانتیزاسیون، نقطه شروع توصیه شدهای است. این کار یک مدل TFLite از نوع اعشاری (float) تولید میکند.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) tflite_quant_model = converter.convert()
توصیه میکنیم این کار را به عنوان گام اولیه انجام دهید تا تأیید کنید که عملگرهای مدل اصلی TF با TFLite سازگار هستند و همچنین میتوانند به عنوان پایهای برای اشکالزدایی خطاهای کوانتیزاسیون ایجاد شده توسط روشهای کوانتیزاسیون پس از آموزش بعدی استفاده شوند. به عنوان مثال، اگر یک مدل TFLite کوانتیزه شده نتایج غیرمنتظرهای تولید کند، در حالی که مدل TFLite اعشاری دقیق است، میتوانیم مشکل را به خطاهای ایجاد شده توسط نسخه کوانتیزه شده عملگرهای TFLite محدود کنیم.
کوانتیزاسیون محدوده دینامیکی
کوانتیزاسیون دامنه پویا، بدون نیاز به ارائه یک مجموعه داده نماینده برای کالیبراسیون، باعث کاهش مصرف حافظه و محاسبه سریعتر میشود. این نوع کوانتیزاسیون، فقط وزنها را از نقطه شناور به عدد صحیح در زمان تبدیل، به صورت ایستا کوانتیزه میکند که دقت ۸ بیتی را فراهم میکند:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
برای کاهش بیشتر تأخیر در طول استنتاج، عملگرهای «دامنه پویا» به صورت پویا فعالسازیها را بر اساس دامنه آنها تا ۸ بیت کوانتیزه میکنند و محاسبات را با وزنها و فعالسازیهای ۸ بیتی انجام میدهند. این بهینهسازی تأخیرهایی نزدیک به استنتاجهای کاملاً نقطه ثابت ارائه میدهد. با این حال، خروجیها هنوز با استفاده از ممیز شناور ذخیره میشوند، بنابراین سرعت افزایشیافته عملیاتهای دامنه پویا کمتر از یک محاسبه کامل نقطه ثابت است.
کوانتیزاسیون کامل عدد صحیح
با اطمینان از اینکه تمام ریاضیات مدل به صورت کوانتیزه شده با اعداد صحیح است، میتوانید بهبودهای بیشتری در تأخیر، کاهش در اوج استفاده از حافظه و سازگاری با دستگاههای سختافزاری یا شتابدهندههای صرفاً عدد صحیح را به دست آورید.
برای کوانتیزاسیون کامل عدد صحیح، باید محدوده، یعنی (حداقل، حداکثر) تمام تانسورهای ممیز شناور در مدل را کالیبره یا تخمین بزنید. برخلاف تانسورهای ثابت مانند وزنها و بایاسها، تانسورهای متغیر مانند ورودی مدل، فعالسازیها (خروجیهای لایههای میانی) و خروجی مدل را نمیتوان کالیبره کرد، مگر اینکه چند چرخه استنتاج را اجرا کنیم. در نتیجه، مبدل برای کالیبره کردن آنها به یک مجموعه داده نماینده نیاز دارد. این مجموعه داده میتواند زیرمجموعه کوچکی (حدود ۱۰۰ تا ۵۰۰ نمونه) از دادههای آموزش یا اعتبارسنجی باشد. به تابع representative_dataset() در زیر مراجعه کنید.
از نسخه TensorFlow 2.7، میتوانید مجموعه دادههای نماینده را از طریق یک امضا به عنوان مثال زیر مشخص کنید:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
اگر بیش از یک امضا در مدل TensorFlow داده شده وجود داشته باشد، میتوانید با مشخص کردن کلیدهای امضا، مجموعه دادههای چندگانه را مشخص کنید:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
شما میتوانید با ارائه یک لیست تانسور ورودی، مجموعه دادههای نماینده را تولید کنید:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
از نسخه ۲.۷ تنسورفلو، ما استفاده از رویکرد مبتنی بر امضا را به رویکرد مبتنی بر لیست تانسور ورودی توصیه میکنیم، زیرا ترتیب تانسور ورودی را میتوان به راحتی تغییر داد.
برای اهداف آزمایشی، میتوانید از یک مجموعه داده ساختگی به شرح زیر استفاده کنید:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
عدد صحیح با قابلیت جایگزینی اعشاری (با استفاده از ورودی/خروجی اعشاری پیشفرض)
برای اینکه یک مدل را کاملاً به صورت عدد صحیح کوانتیزه کنید، اما وقتی پیادهسازی عدد صحیح ندارند از عملگرهای اعشاری استفاده کنید (برای اطمینان از اینکه تبدیل به طور روان انجام میشود)، مراحل زیر را دنبال کنید:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
فقط عدد صحیح
ایجاد مدلهای فقط عدد صحیح، یک مورد استفاده رایج برای LiteRT برای میکروکنترلرها و Coral Edge TPUها است.
علاوه بر این، برای اطمینان از سازگاری با دستگاههای فقط اعداد صحیح (مانند میکروکنترلرهای ۸ بیتی) و شتابدهندهها (مانند Coral Edge TPU)، میتوانید با استفاده از مراحل زیر، کوانتیزاسیون کامل اعداد صحیح را برای همه عملیاتها، از جمله ورودی و خروجی، اعمال کنید:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
کوانتیزاسیون Float16
شما میتوانید با کوانتیزه کردن وزنها به float16، استاندارد IEEE برای اعداد ممیز شناور ۱۶ بیتی، اندازه یک مدل ممیز شناور را کاهش دهید. برای فعال کردن کوانتیزه کردن وزنها به float16، از مراحل زیر استفاده کنید:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
مزایای کوانتیزاسیون float16 به شرح زیر است:
- اندازه مدل را تا نصف کاهش میدهد (زیرا تمام وزنها نصف اندازه اصلی خود میشوند).
- باعث کمترین افت دقت میشود.
- این برنامه از برخی نمایندگان (مثلاً نماینده GPU) پشتیبانی میکند که میتوانند مستقیماً روی دادههای float16 عمل کنند و در نتیجه اجرای سریعتری نسبت به محاسبات float32 داشته باشند.
معایب کوانتیزاسیون float16 به شرح زیر است:
- این روش به اندازه کوانتیزاسیون با روش ریاضی نقطه ثابت، تأخیر را کاهش نمیدهد.
- به طور پیشفرض، یک مدل کوانتیزه شده با float16، هنگام اجرا روی CPU، مقادیر وزنها را به float32 "dequantize" میکند. (توجه داشته باشید که نماینده GPU این dequantization را انجام نمیدهد، زیرا میتواند روی دادههای float16 عمل کند.)
فقط اعداد صحیح: فعالسازیهای ۱۶ بیتی با وزنهای ۸ بیتی (آزمایشی)
این یک طرح کوانتیزاسیون آزمایشی است. این طرح مشابه طرح "فقط عدد صحیح" است، اما فعالسازیها بر اساس محدودهشان تا ۱۶ بیت، وزنها بر اساس عدد صحیح ۸ بیتی و بایاس بر اساس عدد صحیح ۶۴ بیتی کوانتیزه میشوند. این روش، کوانتیزاسیون ۱۶x۸ نامیده میشود.
مزیت اصلی این کوانتیزاسیون این است که میتواند دقت را به میزان قابل توجهی بهبود بخشد، اما اندازه مدل را فقط کمی افزایش میدهد.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
اگر کوانتیزاسیون ۱۶x۸ برای برخی از عملگرها در مدل پشتیبانی نشود، مدل همچنان میتواند کوانتیزه شود، اما عملگرهای پشتیبانی نشده در مقدار اعشاری (float) نگه داشته میشوند. برای این کار، گزینه زیر باید به target_spec اضافه شود.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
نمونههایی از موارد استفاده که در آنها بهبود دقت توسط این طرح کوانتیزاسیون ارائه شده است عبارتند از:
- وضوح فوقالعاده،
- پردازش سیگنال صوتی مانند حذف نویز و شکلدهی پرتو
- نویززدایی تصویر،
- بازسازی HDR از یک تصویر واحد.
عیب این کوانتیزاسیون این است:
- در حال حاضر، به دلیل عدم پیادهسازی بهینه هسته، استنتاج به طور قابل توجهی کندتر از اعداد صحیح کامل ۸ بیتی است.
- در حال حاضر با نمایندگان TFLite شتابدهنده سختافزاری موجود سازگار نیست.
آموزش این حالت کوانتیزاسیون را میتوانید اینجا پیدا کنید.
دقت مدل
از آنجایی که وزنها پس از آموزش کوانتیزه میشوند، ممکن است کاهش دقت، به ویژه برای شبکههای کوچکتر، وجود داشته باشد. مدلهای کاملاً کوانتیزه شده از پیش آموزش دیده برای شبکههای خاص در مدلهای Kaggle ارائه شدهاند. بررسی دقت مدل کوانتیزه شده برای تأیید اینکه هرگونه کاهش دقت در محدوده قابل قبول است، مهم است. ابزارهایی برای ارزیابی دقت مدل LiteRT وجود دارد.
از طرف دیگر، اگر افت دقت خیلی زیاد باشد، استفاده از آموزش آگاهانه از کوانتیزاسیون را در نظر بگیرید. با این حال، انجام این کار نیاز به تغییراتی در طول آموزش مدل برای اضافه کردن گرههای کوانتیزاسیون جعلی دارد، در حالی که تکنیکهای کوانتیزاسیون پس از آموزش در این صفحه از یک مدل از پیش آموزش دیده موجود استفاده میکنند.
نمایش تانسورهای کوانتیزه
کوانتیزاسیون ۸ بیتی، مقادیر ممیز شناور را با استفاده از فرمول زیر تقریب میزند.
\[real\_value = (int8\_value - zero\_point) \times scale\]
نمایش دو بخش اصلی دارد:
وزنهای هر محور (معروف به هر کانال) یا هر تانسور که توسط مقادیر مکمل دو int8 در محدوده [-127، 127] با نقطه صفر برابر با 0 نشان داده میشوند.
فعالسازیها/ورودیهای هر تانسور که توسط int8 مقادیر مکمل دو در محدوده [-128، 127] نشان داده میشوند، با یک نقطه صفر در محدوده [-128، 127].
برای مشاهده جزئیات طرح کوانتیزاسیون ما، لطفاً به مشخصات کوانتیزاسیون ما مراجعه کنید. به فروشندگان سختافزار که میخواهند به رابط نماینده TensorFlow Lite متصل شوند، توصیه میشود طرح کوانتیزاسیون شرح داده شده در آنجا را پیادهسازی کنند.