
Использование графических процессоров (GPU) для запуска моделей машинного обучения (ML) может значительно повысить производительность вашей модели и удобство работы с приложениями с поддержкой ML. На устройствах iOS вы можете включить использование графического ускорения ваших моделей с помощью делегата . Делегаты выступают в роли аппаратных драйверов для LiteRT, позволяя запускать код вашей модели на процессорах графического процессора.
На этой странице описано, как включить ускорение графического процессора для моделей LiteRT в приложениях iOS. Дополнительные сведения об использовании делегата графического процессора для LiteRT, включая рекомендации и передовые методы, см. на странице делегатов графического процессора .
Используйте графический процессор с API-интерпретатора
API-интерфейс LiteRT Interpreter предоставляет набор API-интерфейсов общего назначения для создания приложений машинного обучения. Следующие инструкции помогут вам добавить поддержку графического процессора в приложение iOS. В этом руководстве предполагается, что у вас уже есть приложение для iOS, которое может успешно выполнять модель машинного обучения с помощью LiteRT.
Измените подфайл, включив поддержку графического процессора.
Начиная с версии LiteRT 2.3.0, делегат GPU исключен из модуля, чтобы уменьшить размер двоичного файла. Вы можете включить их, указав подспецификацию для модуля TensorFlowLiteSwift :
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
ИЛИ
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
Вы также можете использовать TensorFlowLiteObjC или TensorFlowLiteC если хотите использовать Objective-C, доступный для версий 2.4.0 и выше, или C API.
Инициализация и использование делегата графического процессора
Вы можете использовать делегат GPU с API-интерфейсом LiteRT Interpreter с рядом языков программирования. Рекомендуется использовать Swift и Objective-C, но вы также можете использовать C++ и C. Использование C необходимо, если вы используете версию LiteRT ниже 2.4. В следующих примерах кода показано, как использовать делегат с каждым из этих языков.
Быстрый
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
Цель-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
С++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (до версии 2.4.0)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
Примечания по использованию языка API графического процессора
- Версии LiteRT до 2.4.0 могут использовать только C API для Objective-C.
- API C++ доступен только в том случае, если вы используете bazel или самостоятельно собираете TensorFlow Lite. API C++ нельзя использовать с CocoaPods.
- При использовании LiteRT с делегатом графического процессора с C++ получите делегат графического процессора с помощью функции
TFLGpuDelegateCreate(), а затем передайте его вInterpreter::ModifyGraphWithDelegate()вместо вызоваInterpreter::AllocateTensors().
Сборка и тестирование в режиме выпуска
Перейдите на сборку выпуска с соответствующими настройками ускорителя Metal API, чтобы повысить производительность и провести окончательное тестирование. В этом разделе объясняется, как включить выпускную сборку и настроить параметры ускорения Metal.
Чтобы перейти к выпускной сборке:
- Измените параметры сборки, выбрав «Продукт» > «Схема» > «Редактировать схему...» , а затем выбрав «Выполнить» .
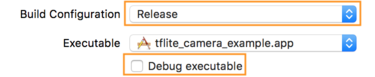
- На вкладке «Информация» измените «Конфигурация сборки» на «Выпуск» и снимите флажок «Отладка исполняемого файла» .
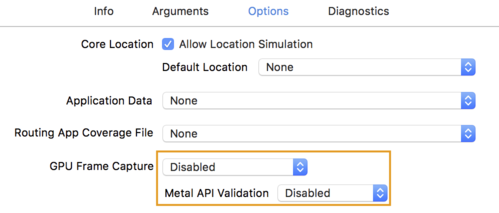
- Перейдите на вкладку «Параметры» и измените параметр «Захват кадров графического процессора» на «Отключено» , а «Проверка Metal API» — на «Отключено» .
- Обязательно выберите сборки только для выпуска на 64-разрядной архитектуре. В разделе «Навигатор проекта» > «tflite_camera_example» > «ПРОЕКТ» > «имя_вашего_проекта» > «Настройки сборки» установите для параметра «Построить только активную архитектуру» > «Выпустить» значение «Да» .

Расширенная поддержка графического процессора
В этом разделе описываются расширенные возможности использования делегата графического процессора для iOS, включая параметры делегата, буферы ввода и вывода, а также использование квантованных моделей.
Параметры делегирования для iOS
Конструктор делегата графического процессора принимает struct параметров Swift API , Objective-C API и C API . Передача nullptr (C API) или ничего (Objective-C и Swift API) в инициализатор устанавливает параметры по умолчанию (которые подробно описаны в примере базового использования выше).
Быстрый
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
Цель-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
С
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
Буферы ввода/вывода с использованием C++ API
Вычисления на графическом процессоре требуют, чтобы данные были доступны графическому процессору. Это требование часто означает, что вам необходимо выполнить копирование памяти. По возможности вам следует избегать пересечения границы памяти CPU/GPU, поскольку это может занять значительное количество времени. Обычно такое пересечение неизбежно, но в некоторых особых случаях то или другое можно опустить.
Если входные данные сети представляют собой изображение, уже загруженное в память графического процессора (например, текстуру графического процессора, содержащую изображение с камеры), оно может оставаться в памяти графического процессора, даже не попадая в память процессора. Аналогично, если выходные данные сети представлены в форме визуализируемого изображения, например, в результате операции передачи стиля изображения , вы можете напрямую отобразить результат на экране.
Для достижения максимальной производительности LiteRT позволяет пользователям напрямую читать и записывать в аппаратный буфер TensorFlow и обходить копии памяти, которых можно избежать.
Предполагая, что входное изображение находится в памяти графического процессора, необходимо сначала преобразовать его в объект MTLBuffer для Metal. Вы можете связать TfLiteTensor с подготовленным пользователем MTLBuffer с помощью функции TFLGpuDelegateBindMetalBufferToTensor() . Обратите внимание, что эту функцию необходимо вызывать после Interpreter::ModifyGraphWithDelegate() . Кроме того, выходные данные вывода по умолчанию копируются из памяти графического процессора в память процессора. Вы можете отключить это поведение, вызвав Interpreter::SetAllowBufferHandleOutput(true) во время инициализации.
С++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
Если поведение по умолчанию отключено, копирование вывода вывода из памяти графического процессора в память ЦП требует явного вызова Interpreter::EnsureTensorDataIsReadable() для каждого выходного тензора. Этот подход также работает для квантованных моделей, но вам все равно необходимо использовать буфер размера float32 с данными float32 , поскольку буфер привязан к внутреннему деквантованному буферу.
Квантованные модели
Библиотеки делегатов графического процессора iOS по умолчанию поддерживают квантованные модели . Вам не нужно вносить какие-либо изменения в код, чтобы использовать квантованные модели с делегатом графического процессора. В следующем разделе объясняется, как отключить поддержку квантования для целей тестирования или экспериментов.
Отключить поддержку квантованной модели
Следующий код показывает, как отключить поддержку квантованных моделей.
Быстрый
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
Цель-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
С
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
Дополнительные сведения о запуске квантованных моделей с ускорением графического процессора см. в разделе Обзор делегатов графического процессора .