
আপনার মেশিন লার্নিং (ML) মডেলগুলি চালানোর জন্য গ্রাফিক্স প্রসেসিং ইউনিট (GPUs) ব্যবহার করা আপনার মডেলের কর্মক্ষমতা এবং আপনার ML-সক্ষম অ্যাপ্লিকেশনগুলির ব্যবহারকারীর অভিজ্ঞতাকে নাটকীয়ভাবে উন্নত করতে পারে। iOS ডিভাইসে, আপনি একটি প্রতিনিধি ব্যবহার করে আপনার মডেলগুলির GPU-এক্সিলারেটেড এক্সিকিউশন ব্যবহার সক্ষম করতে পারেন। প্রতিনিধিরা LiteRT-এর জন্য হার্ডওয়্যার ড্রাইভার হিসাবে কাজ করে, যা আপনাকে GPU প্রসেসরে আপনার মডেলের কোড চালানোর অনুমতি দেয়।
এই পৃষ্ঠাটি বর্ণনা করে কিভাবে iOS অ্যাপে LiteRT মডেলের জন্য GPU ত্বরণ সক্ষম করা যায়। সেরা অনুশীলন এবং উন্নত কৌশল সহ LiteRT-এর জন্য GPU প্রতিনিধি ব্যবহার সম্পর্কে আরও তথ্যের জন্য, GPU প্রতিনিধি পৃষ্ঠাটি দেখুন।
ইন্টারপ্রেটার API সহ GPU ব্যবহার করুন
LiteRT ইন্টারপ্রেটার API একটি মেশিন লার্নিং অ্যাপ্লিকেশন তৈরির জন্য সাধারণ উদ্দেশ্য API-এর একটি সেট প্রদান করে। নিম্নলিখিত নির্দেশাবলী একটি iOS অ্যাপে GPU সমর্থন যোগ করার মাধ্যমে আপনাকে গাইড করে। এই নির্দেশিকা অনুমান করে যে আপনার কাছে ইতিমধ্যেই একটি iOS অ্যাপ রয়েছে যা সফলভাবে LiteRT এর সাথে একটি ML মডেল কার্যকর করতে পারে।
GPU সমর্থন অন্তর্ভুক্ত করতে Podfile পরিবর্তন করুন
LiteRT 2.3.0 রিলিজ দিয়ে শুরু করে, বাইনারি আকার কমাতে GPU প্রতিনিধিকে পড থেকে বাদ দেওয়া হয়েছে। আপনি TensorFlowLiteSwift পডের জন্য একটি সাবস্পেক নির্দিষ্ট করে তাদের অন্তর্ভুক্ত করতে পারেন:
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
বা
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
আপনি যদি অবজেক্টিভ-সি, যা 2.4.0 এবং উচ্চতর সংস্করণের জন্য উপলব্ধ, বা C API ব্যবহার করতে চান তবে আপনি TensorFlowLiteObjC বা TensorFlowLiteC ব্যবহার করতে পারেন।
শুরু করুন এবং GPU প্রতিনিধি ব্যবহার করুন
আপনি অনেকগুলি প্রোগ্রামিং ভাষার সাথে LiteRT ইন্টারপ্রেটার API সহ GPU প্রতিনিধি ব্যবহার করতে পারেন। সুইফট এবং অবজেক্টিভ-সি সুপারিশ করা হয়, তবে আপনি C++ এবং C ব্যবহার করতে পারেন। আপনি যদি 2.4-এর আগে LiteRT-এর সংস্করণ ব্যবহার করেন তবে C ব্যবহার করা প্রয়োজন। নিম্নলিখিত কোড উদাহরণগুলি এই প্রতিটি ভাষার সাথে প্রতিনিধিকে কীভাবে ব্যবহার করতে হয় তার রূপরেখা দেয়।
সুইফট
import TensorFlowLite // Load model ... // Initialize LiteRT interpreter with the GPU delegate. let delegate = MetalDelegate() if let interpreter = try Interpreter(modelPath: modelPath, delegates: [delegate]) { // Run inference ... }
উদ্দেশ্য-C
// Import module when using CocoaPods with module support @import TFLTensorFlowLite; // Or import following headers manually #import "tensorflow/lite/objc/apis/TFLMetalDelegate.h" #import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h" // Initialize GPU delegate TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init]; // Initialize interpreter with model path and GPU delegate TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init]; NSError* error = nil; TFLInterpreter* interpreter = [[TFLInterpreter alloc] initWithModelPath:modelPath options:options delegates:@[ metalDelegate ] error:&error]; if (error != nil) { /* Error handling... */ } if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ } if (error != nil) { /* Error handling... */ } // Run inference ...
সি++
// Set up interpreter. auto model = FlatBufferModel::BuildFromFile(model_path); if (!model) return false; tflite::ops::builtin::BuiltinOpResolver op_resolver; std::unique_ptr<Interpreter> interpreter; InterpreterBuilder(*model, op_resolver)(&interpreter); // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; // Run inference. WriteToInputTensor(interpreter->typed_input_tensor<float>(0)); if (interpreter->Invoke() != kTfLiteOk) return false; ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0)); // Clean up. TFLGpuDelegateDelete(delegate);
C (২.৪.০ এর আগে)
#include "tensorflow/lite/c/c_api.h" #include "tensorflow/lite/delegates/gpu/metal_delegate.h" // Initialize model TfLiteModel* model = TfLiteModelCreateFromFile(model_path); // Initialize interpreter with GPU delegate TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate(); TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config TfLiteInterpreterOptionsAddDelegate(options, metal_delegate); TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options); TfLiteInterpreterOptionsDelete(options); TfLiteInterpreterAllocateTensors(interpreter); NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)]; NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)]; TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0); const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0); // Run inference TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length); TfLiteInterpreterInvoke(interpreter); TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length); // Clean up TfLiteInterpreterDelete(interpreter); TFLGpuDelegateDelete(metal_delegate); TfLiteModelDelete(model);
GPU API ভাষা নোট ব্যবহার করে
- 2.4.0-এর আগের LiteRT সংস্করণগুলি উদ্দেশ্য-C-এর জন্য শুধুমাত্র C API ব্যবহার করতে পারে।
- C++ এপিআই শুধুমাত্র তখনই পাওয়া যায় যখন আপনি বেজেল ব্যবহার করেন বা নিজে থেকে টেনসরফ্লো লাইট তৈরি করেন। C++ API CocoaPods এর সাথে ব্যবহার করা যাবে না।
- C++ এর সাথে GPU প্রতিনিধির সাথে LiteRT ব্যবহার করার সময়,
TFLGpuDelegateCreate()ফাংশনের মাধ্যমে GPU প্রতিনিধি পান এবং তারপর Interpreter::Interpreter::AllocateTensors()Interpreter::ModifyGraphWithDelegate()এ পাঠান।
রিলিজ মোড দিয়ে তৈরি করুন এবং পরীক্ষা করুন
ভাল পারফরম্যান্স পেতে এবং চূড়ান্ত পরীক্ষার জন্য উপযুক্ত মেটাল API অ্যাক্সিলারেটর সেটিংস সহ একটি রিলিজ বিল্ডে পরিবর্তন করুন। এই বিভাগটি ব্যাখ্যা করে কিভাবে মেটাল ত্বরণের জন্য একটি রিলিজ বিল্ড এবং কনফিগার সেটিং সক্ষম করতে হয়।
একটি রিলিজ বিল্ডে পরিবর্তন করতে:
- পণ্য > স্কিম > স্কিম সম্পাদনা করুন... এবং তারপর রান নির্বাচন করে বিল্ড সেটিংস সম্পাদনা করুন।
- তথ্য ট্যাবে, বিল্ড কনফিগারেশনকে রিলিজে পরিবর্তন করুন এবং ডিবাগ এক্সিকিউটেবল টিক চিহ্নমুক্ত করুন।
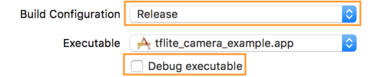
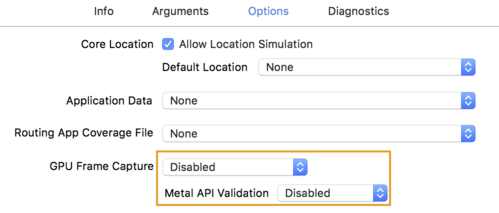
- বিকল্প ট্যাবে ক্লিক করুন এবং GPU ফ্রেম ক্যাপচারকে নিষ্ক্রিয় এবং মেটাল API যাচাইকরণ নিষ্ক্রিয় তে পরিবর্তন করুন।
- 64-বিট আর্কিটেকচারে রিলিজ-অনলি বিল্ড নির্বাচন করা নিশ্চিত করুন। প্রজেক্ট নেভিগেটরের অধীনে > tflite_camera_example > PROJECT > your_project_name > বিল্ড সেটিংস সেট বিল্ড অ্যাক্টিভ আর্কিটেকচার শুধুমাত্র > রিলিজ তে হ্যাঁ ।

উন্নত GPU সমর্থন
এই বিভাগে প্রতিনিধি বিকল্প, ইনপুট এবং আউটপুট বাফার এবং কোয়ান্টাইজড মডেলের ব্যবহার সহ iOS এর জন্য GPU প্রতিনিধির উন্নত ব্যবহারগুলি কভার করে৷
আইওএসের জন্য বিকল্পগুলি অর্পণ করুন৷
GPU প্রতিনিধির জন্য কনস্ট্রাক্টর সুইফ্ট এপিআই , অবজেক্টিভ-সি এপিআই , এবং সি এপিআই- এ বিকল্পগুলির একটি struct গ্রহণ করে। ইনিশিয়ালাইজারে nullptr (C API) বা কিছুই (অবজেক্টিভ-সি এবং সুইফ্ট API) পাস করা ডিফল্ট বিকল্পগুলি সেট করে (যা উপরে বেসিক ব্যবহারের উদাহরণে ব্যাখ্যা করা হয়েছে)।
সুইফট
// THIS: var options = MetalDelegate.Options() options.isPrecisionLossAllowed = false options.waitType = .passive options.isQuantizationEnabled = true let delegate = MetalDelegate(options: options) // IS THE SAME AS THIS: let delegate = MetalDelegate()
উদ্দেশ্য-C
// THIS: TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.precisionLossAllowed = false; options.waitType = TFLMetalDelegateThreadWaitTypePassive; options.quantizationEnabled = true; TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options]; // IS THE SAME AS THIS: TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
গ
// THIS: const TFLGpuDelegateOptions options = { .allow_precision_loss = false, .wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive, .enable_quantization = true, }; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options); // IS THE SAME AS THIS: TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
C++ API ব্যবহার করে ইনপুট/আউটপুট বাফার
GPU-তে কম্পিউটেশনের জন্য ডেটা GPU-তে উপলব্ধ থাকা প্রয়োজন। এই প্রয়োজনীয়তা প্রায়ই মানে আপনি একটি মেমরি কপি সম্পাদন করতে হবে. সম্ভব হলে আপনার ডেটা CPU/GPU মেমরির সীমানা অতিক্রম করা এড়াতে হবে, কারণ এটি একটি উল্লেখযোগ্য পরিমাণ সময় নিতে পারে। সাধারণত, এই ধরনের ক্রসিং অনিবার্য, কিন্তু কিছু বিশেষ ক্ষেত্রে, এক বা অন্য বাদ দেওয়া যেতে পারে।
যদি নেটওয়ার্কের ইনপুটটি GPU মেমরিতে ইতিমধ্যেই লোড করা একটি চিত্র হয় (উদাহরণস্বরূপ, ক্যামেরা ফিড ধারণকারী একটি GPU টেক্সচার) এটি CPU মেমরিতে প্রবেশ না করেই GPU মেমরিতে থাকতে পারে। একইভাবে, যদি নেটওয়ার্কের আউটপুট একটি রেন্ডারযোগ্য চিত্রের আকারে হয়, যেমন একটি চিত্র শৈলী স্থানান্তর অপারেশন, আপনি সরাসরি ফলাফলটি স্ক্রিনে প্রদর্শন করতে পারেন।
সর্বোত্তম কর্মক্ষমতা অর্জনের জন্য, LiteRT ব্যবহারকারীদের জন্য TensorFlow হার্ডওয়্যার বাফার থেকে সরাসরি পড়া এবং লিখতে এবং এড়ানো যায় এমন মেমরি কপিগুলিকে বাইপাস করা সম্ভব করে তোলে।
ইমেজ ইনপুটটি GPU মেমরিতে রয়েছে বলে ধরে নিলে, আপনাকে প্রথমে এটিকে মেটালের জন্য একটি MTLBuffer অবজেক্টে রূপান্তর করতে হবে। আপনি TFLGpuDelegateBindMetalBufferToTensor() ফাংশনের সাথে একটি ব্যবহারকারী-প্রস্তুত MTLBuffer এর সাথে একটি TfLiteTensor যুক্ত করতে পারেন। মনে রাখবেন যে এই ফাংশনটি অবশ্যই Interpreter::ModifyGraphWithDelegate() এর পরে কল করতে হবে। উপরন্তু, অনুমান আউটপুট, ডিফল্টরূপে, GPU মেমরি থেকে CPU মেমরিতে অনুলিপি করা হয়। শুরু করার সময় আপনি Interpreter::SetAllowBufferHandleOutput(true) কল করে এই আচরণটি বন্ধ করতে পারেন।
সি++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h" #include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h" // ... // Prepare GPU delegate. auto* delegate = TFLGpuDelegateCreate(nullptr); if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false; interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->inputs()[0], user_provided_input_buffer)) { return false; } if (!TFLGpuDelegateBindMetalBufferToTensor( delegate, interpreter->outputs()[0], user_provided_output_buffer)) { return false; } // Run inference. if (interpreter->Invoke() != kTfLiteOk) return false;
ডিফল্ট আচরণ বন্ধ হয়ে গেলে, GPU মেমরি থেকে CPU মেমরিতে অনুমান আউটপুট অনুলিপি করার জন্য প্রতিটি আউটপুট টেনসরের জন্য Interpreter::EnsureTensorDataIsReadable() এ একটি স্পষ্ট কল প্রয়োজন। এই পদ্ধতিটি কোয়ান্টাইজড মডেলগুলির জন্যও কাজ করে, তবে আপনাকে এখনও float32 ডেটা সহ একটি float32 আকারের বাফার ব্যবহার করতে হবে, কারণ বাফারটি অভ্যন্তরীণ ডি-কোয়ান্টাইজড বাফারের সাথে আবদ্ধ।
কোয়ান্টাইজড মডেল
iOS GPU প্রতিনিধি লাইব্রেরিগুলি ডিফল্টরূপে কোয়ান্টাইজড মডেলগুলিকে সমর্থন করে ৷ জিপিইউ প্রতিনিধির সাথে কোয়ান্টাইজড মডেল ব্যবহার করার জন্য আপনাকে কোনো কোড পরিবর্তন করতে হবে না। নিম্নলিখিত বিভাগটি ব্যাখ্যা করে কিভাবে পরীক্ষা বা পরীক্ষামূলক উদ্দেশ্যে কোয়ান্টাইজড সমর্থন অক্ষম করা যায়।
কোয়ান্টাইজড মডেল সমর্থন অক্ষম করুন
নিম্নোক্ত কোডটি দেখায় কিভাবে কোয়ান্টাইজড মডেলের জন্য সমর্থন অক্ষম করা যায়।
সুইফট
var options = MetalDelegate.Options() options.isQuantizationEnabled = false let delegate = MetalDelegate(options: options)
উদ্দেশ্য-C
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init]; options.quantizationEnabled = false;
গ
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault(); options.enable_quantization = false; TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
GPU ত্বরণ সহ কোয়ান্টাইজড মডেল চালানোর বিষয়ে আরও তথ্যের জন্য, GPU প্রতিনিধি ওভারভিউ দেখুন।