
Инструменты тестирования производительности LiteRT измеряют и вычисляют статистические данные по следующим важным показателям производительности:
- Время инициализации
- Время определения состояния прогрева
- Время вывода стационарного состояния
- Использование памяти во время инициализации
- Общее использование памяти
Инструменты для тестирования производительности доступны в виде приложений для Android и iOS, а также в виде предварительно собранных исполняемых файлов командной строки, и все они используют одну и ту же основную логику измерения производительности. Обратите внимание, что доступные параметры и форматы вывода немного различаются из-за различий в среде выполнения.
приложение для тестирования производительности Android
Также предоставляется приложение для тестирования производительности Android, основанное на API интерпретатора версии 1. Это позволяет лучше оценить, как модель будет работать в приложении Android. Однако результаты, полученные с помощью инструмента тестирования, будут немного отличаться от результатов, полученных при выполнении инференса с использованием модели в реальном приложении.
Это приложение для тестирования производительности Android не имеет пользовательского интерфейса. Установите и запустите его с помощью команды adb , а результаты получите с помощью команды adb logcat .
Скачайте или соберите приложение.
Загрузите предварительно собранные в течение ночи приложения для тестирования производительности Android, используя следующие ссылки:
Что касается приложений для тестирования производительности Android, поддерживающих операции TF через делегат Flex , воспользуйтесь ссылками ниже:
Вы также можете собрать приложение из исходного кода, следуя этим инструкциям .
Подготовьте эталонные показатели
Перед запуском приложения для тестирования производительности установите приложение и загрузите файл модели на устройство следующим образом:
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
Запустить бенчмарк
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph является обязательным параметром.
-
graph:string
Путь к файлу модели TFLite.
Для запуска теста производительности можно указать дополнительные необязательные параметры.
-
num_threads:int(по умолчанию=1)
Количество потоков, используемых для запуска интерпретатора TFLite. -
use_gpu:bool(по умолчанию=false)
Используйте делегат GPU . -
use_xnnpack:bool(по умолчанию =false)
Используйте делегат XNNPACK .
В зависимости от используемого устройства некоторые из этих параметров могут быть недоступны или не оказывать никакого эффекта. Для получения дополнительной информации о параметрах производительности, которые можно использовать с приложением для тестирования, обратитесь к разделу «Параметры ».
Просмотрите результаты с помощью команды logcat :
adb logcat | grep "Inference timings"
Результаты сравнительного анализа представлены в следующем виде:
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
приложение для тестирования производительности iOS
Для запуска тестов на устройствах iOS необходимо собрать приложение из исходного кода . Поместите файл модели LiteRT в каталог benchmark_data в дереве исходного кода и измените файл benchmark_params.json . Эти файлы будут упакованы в приложение, и приложение будет считывать данные из этого каталога. Подробные инструкции см. в приложении для тестирования производительности iOS .
Тесты производительности для известных моделей
В этом разделе приведены результаты тестов производительности LiteRT при запуске популярных моделей на некоторых устройствах Android и iOS.
Тесты производительности Android
Эти показатели производительности были получены с помощью собственного исполняемого файла бенчмарка .
Для тестов производительности Android приоритет процессора устанавливается таким образом, чтобы использовать более мощные ядра устройства для уменьшения погрешности ( подробнее см. здесь).
Предполагается, что модели были загружены и распакованы в каталог /data/local/tmp/tflite_models . Бинарный файл бенчмарка собирается с использованием этих инструкций и предполагается, что он находится в каталоге /data/local/tmp .
Для запуска теста производительности:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
Для запуска с использованием делегата GPU установите --use_gpu=true .
Приведенные ниже показатели производительности измерены на Android 10.
| Название модели | Устройство | Процессор, 4 потока | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | Пиксель 3 | 23,9 мс | 6,45 мс |
| Пиксель 4 | 14,0 мс | 9,0 мс | |
| Mobilenet_1.0_224 (quant) | Пиксель 3 | 13,4 мс | --- |
| Пиксель 4 | 5,0 мс | --- | |
| NASNet мобильный | Пиксель 3 | 56 мс | --- |
| Пиксель 4 | 34,5 мс | --- | |
| SqueezeNet | Пиксель 3 | 35,8 мс | 9,5 мс |
| Пиксель 4 | 23,9 мс | 11,1 мс | |
| Inception_ResNet_V2 | Пиксель 3 | 422 мс | 99,8 мс |
| Пиксель 4 | 272,6 мс | 87,2 мс | |
| Inception_V4 | Пиксель 3 | 486 мс | 93 мс |
| Пиксель 4 | 324,1 мс | 97,6 мс |
Тесты производительности iOS
Эти показатели производительности были получены с помощью приложения для тестирования производительности iOS .
Для запуска тестов производительности iOS приложение для тестирования было изменено, чтобы включить соответствующую модель, а benchmark_params.json был изменен, чтобы установить num_threads равным 2. Для использования делегата GPU в файл benchmark_params.json также были добавлены параметры "use_gpu" : "1" и "gpu_wait_type" : "aggressive" .
| Название модели | Устройство | Процессор, 2 потока | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14,8 мс | 3,4 мс |
| Mobilenet_1.0_224 (quant) | iPhone XS | 11 мс | --- |
| NASNet мобильный | iPhone XS | 30,4 мс | --- |
| SqueezeNet | iPhone XS | 21,1 мс | 15,5 мс |
| Inception_ResNet_V2 | iPhone XS | 261,1 мс | 45,7 мс |
| Inception_V4 | iPhone XS | 309 мс | 54,4 мс |
Проследите внутреннее устройство LiteRT
Отслеживание внутренних компонентов LiteRT в Android
Внутренние события интерпретатора LiteRT приложения Android могут быть перехвачены инструментами трассировки Android . Это те же самые события, что и в Android Trace API, поэтому перехваченные события из кода Java/Kotlin отображаются вместе с внутренними событиями LiteRT.
Примерами таких событий могут служить следующие:
- Вызов оператора
- Изменение графика делегатом
- распределение тензоров
В данном руководстве рассматриваются различные варианты захвата трассировки, включая Android Studio CPU Profiler и приложение System Tracing. Для получения информации о других вариантах обратитесь к инструментам командной строки Perfetto или Systrace .
Добавление событий трассировки в код Java
Это фрагмент кода из примера приложения для классификации изображений . Интерпретатор LiteRT запускается в разделе recognizeImage/runInference . Этот шаг необязателен, но полезен для того, чтобы понять, где происходит вызов функции вывода.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
Включить трассировку LiteRT
Чтобы включить трассировку LiteRT, перед запуском приложения Android установите системное свойство Android debug.tflite.trace в значение 1.
adb shell setprop debug.tflite.trace 1
Если это свойство было установлено при инициализации интерпретатора LiteRT, то события нажатия клавиш (например, вызов оператора) из интерпретатора будут отслеживаться.
После того, как вы получили все трассировки, отключите трассировку, установив значение свойства равным 0.
adb shell setprop debug.tflite.trace 0
Профайлер ЦП в Android Studio
Чтобы получить трассировку с помощью профилировщика ЦП в Android Studio , выполните следующие действия:
В верхнем меню выберите «Запуск» > «Профиль приложения» .
Когда появится окно профилировщика, щелкните в любом месте временной шкалы ЦП.
В разделе режимов профилирования ЦП выберите «Трассировка системных вызовов».
Нажмите кнопку «Запись».
Нажмите кнопку «Стоп».
Изучите результаты трассировки.
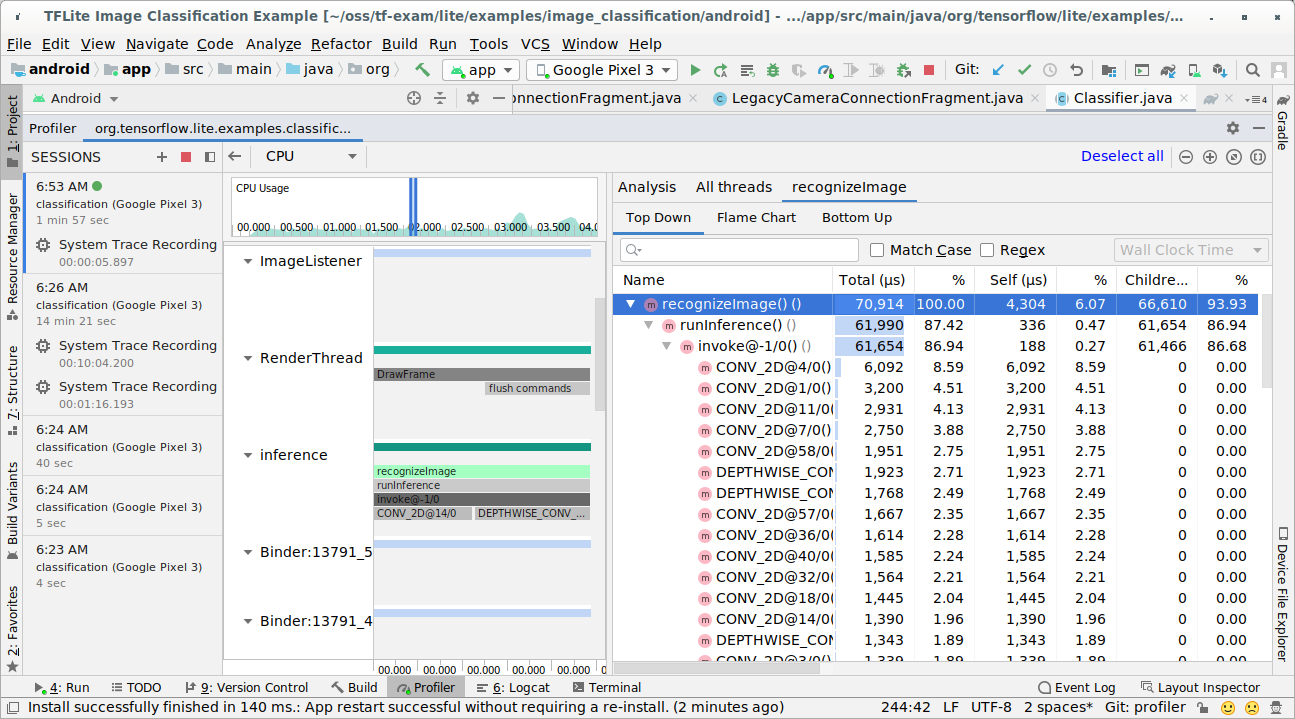
В этом примере вы можете увидеть иерархию событий в потоке, статистику по времени работы каждого оператора, а также поток данных всего приложения между потоками.
Приложение для трассировки системы
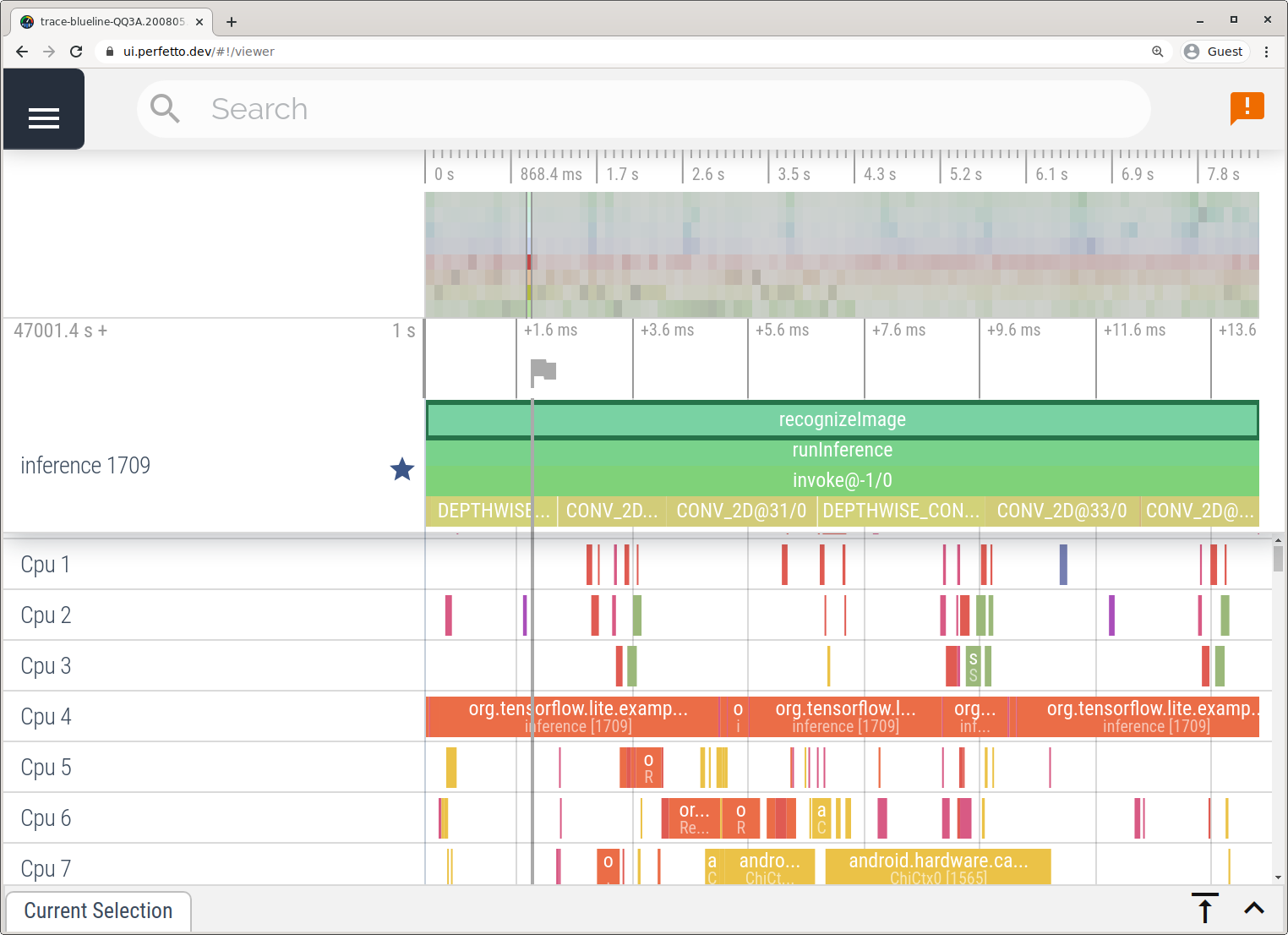
Для записи трассировки без использования Android Studio выполните действия, описанные в приложении «Трассировка системы» .
В этом примере одни и те же события TFLite были захвачены и сохранены в формате Perfetto или Systrace в зависимости от версии устройства Android. Захваченные файлы трассировки можно открыть в пользовательском интерфейсе Perfetto .
Отслеживание внутренних механизмов LiteRT в iOS
Внутренние события интерпретатора LiteRT iOS-приложения можно перехватить с помощью инструмента Instruments , входящего в состав Xcode. Это так называемые «сигнальные события» iOS, поэтому перехваченные события из кода Swift/Objective-C отображаются вместе с внутренними событиями LiteRT.
Примерами таких событий могут служить следующие:
- Вызов оператора
- Изменение графика делегатом
- распределение тензоров
Включить трассировку LiteRT
Установите переменную среды debug.tflite.trace , выполнив следующие действия:
В верхнем меню Xcode выберите Product > Scheme > Edit Scheme...
В левой панели нажмите кнопку «Профиль».
Снимите флажок «Использовать аргументы и переменные среды действия «Выполнить»».
Добавьте
debug.tflite.traceв раздел «Переменные среды».
Если вы хотите исключить события LiteRT при профилировании iOS-приложения, отключите трассировку, удалив соответствующую переменную среды.
Инструменты XCode
Для захвата трассировки выполните следующие действия:
В верхнем меню Xcode выберите Product > Profile .
При запуске инструмента «Инструменты» выберите «Ведение журнала» среди шаблонов профилирования.
Нажмите кнопку «Старт».
Нажмите кнопку «Стоп».
Нажмите на 'os_signpost', чтобы развернуть элементы подсистемы логирования ОС.
Нажмите на подсистему логирования ОС 'org.tensorflow.lite'.
Изучите результаты трассировки.
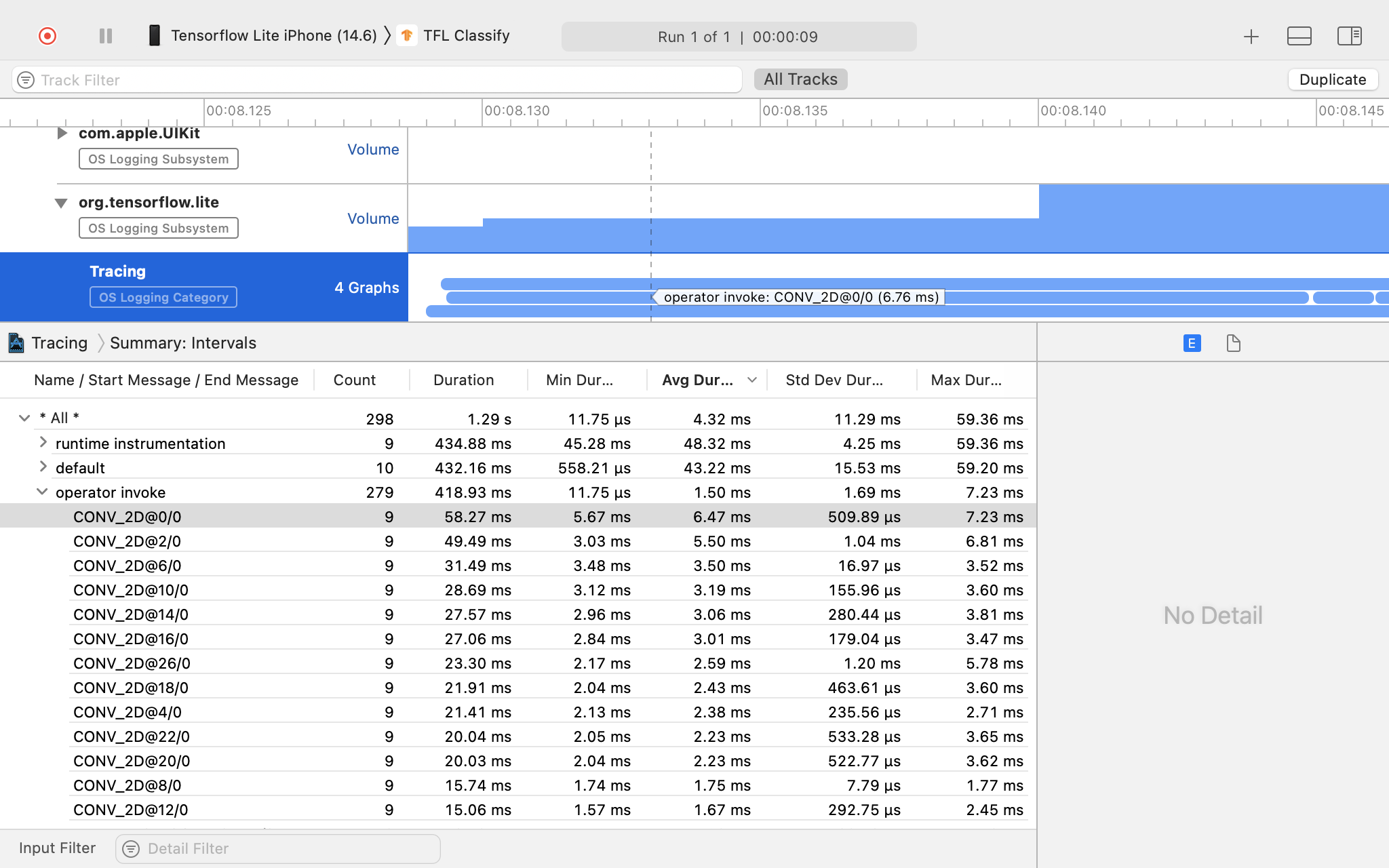
В этом примере вы можете увидеть иерархию событий и статистику для каждого рабочего времени оператора.
Используя данные трассировки
Данные трассировки позволяют выявлять узкие места в производительности.
Вот несколько примеров информации, которую можно получить с помощью профилировщика, и потенциальных решений для повышения производительности:
- Если количество доступных ядер ЦП меньше количества потоков вывода, то накладные расходы на планирование ЦП могут привести к снижению производительности. Вы можете перепланировать другие ресурсоемкие задачи в вашем приложении, чтобы избежать их наложения на вывод модели, или скорректировать количество потоков интерпретатора.
- Если операторы не делегированы полностью, то некоторые части графа модели выполняются на ЦП, а не на ожидаемом аппаратном ускорителе. Вы можете заменить неподдерживаемые операторы аналогичными поддерживаемыми операторами.