
เครื่องมือเปรียบเทียบ LiteRT จะวัดและคำนวณสถิติสำหรับเมตริกประสิทธิภาพที่สำคัญต่อไปนี้
- เวลาเริ่มต้น
- เวลาในการอนุมานของสถานะวอร์มอัป
- เวลาอนุมานของสถานะคงที่
- การใช้งานหน่วยความจำในระหว่างเวลาเริ่มต้น
- การใช้หน่วยความจำโดยรวม
เครื่องมือเปรียบเทียบมีให้บริการเป็นแอปเปรียบเทียบสำหรับ Android และ iOS รวมถึงเป็น ไบนารีบรรทัดคำสั่งที่สร้างไว้ล่วงหน้า และทั้งหมดใช้ตรรกะการวัดประสิทธิภาพหลักเดียวกัน โปรดทราบว่าตัวเลือกที่ใช้ได้และรูปแบบเอาต์พุตจะ แตกต่างกันเล็กน้อยเนื่องจากสภาพแวดล้อมรันไทม์ที่แตกต่างกัน
แอปการเปรียบเทียบ Android
นอกจากนี้ เรายังมีแอปการเปรียบเทียบ Android ที่อิงตาม Interpreter API เวอร์ชัน 1 ด้วย ซึ่งเป็นตัวชี้วัดที่ดีกว่าว่าโมเดลจะทำงานในแอป Android ได้อย่างไร ตัวเลขจากเครื่องมือเปรียบเทียบจะยังคงแตกต่างเล็กน้อยเมื่อเรียกใช้การอนุมานด้วยโมเดลในแอปจริง
แอปการเปรียบเทียบ Android นี้ไม่มี UI ติดตั้งและเรียกใช้โดยใช้คำสั่ง adb
และดึงผลลัพธ์โดยใช้คำสั่ง adb logcat
ดาวน์โหลดหรือสร้างแอป
ดาวน์โหลดแอปทดสอบประสิทธิภาพ Android ที่สร้างไว้ล่วงหน้าในเวอร์ชันกลางคืนโดยใช้ลิงก์ต่อไปนี้
สำหรับแอปการทดสอบประสิทธิภาพของ Android ที่รองรับการดำเนินการ TF ผ่านตัวแทน Flex ให้ใช้ลิงก์ด้านล่าง
นอกจากนี้ คุณยังสร้างแอปจากแหล่งที่มาได้โดยทำตามวิธีการเหล่านี้
เตรียมการเปรียบเทียบ
ก่อนเรียกใช้แอปการเปรียบเทียบ ให้ติดตั้งแอปและพุชไฟล์โมเดลไปยังอุปกรณ์โดยทำดังนี้
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
เรียกใช้การเปรียบเทียบ
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph คือพารามิเตอร์ที่ต้องระบุ
graph:string
เส้นทางไปยังไฟล์โมเดล TFLite
คุณระบุพารามิเตอร์ที่ไม่บังคับเพิ่มเติมเพื่อเรียกใช้การเปรียบเทียบได้
num_threads:int(ค่าเริ่มต้น=1)
จำนวนเธรดที่จะใช้ในการเรียกใช้ตัวแปล TFLiteuse_gpu:bool(ค่าเริ่มต้น=false)
ใช้ตัวแทน GPUuse_xnnpack:bool(ค่าเริ่มต้น=false)
ใช้ ผู้แทน XNNPACK
ตัวเลือกบางอย่างอาจไม่พร้อมใช้งานหรือไม่มีผล ทั้งนี้ขึ้นอยู่กับอุปกรณ์ที่คุณใช้ ดูพารามิเตอร์ เพื่อดูพารามิเตอร์ประสิทธิภาพเพิ่มเติมที่คุณเรียกใช้กับแอปการเปรียบเทียบได้
ดูผลลัพธ์โดยใช้คำสั่ง logcat
adb logcat | grep "Inference timings"
ผลการเปรียบเทียบจะรายงานเป็น
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
แอปการเปรียบเทียบ iOS
หากต้องการเรียกใช้การทดสอบประสิทธิภาพในอุปกรณ์ iOS คุณต้องสร้างแอปจากแหล่งที่มา
วางไฟล์โมเดล LiteRT ในไดเรกทอรี
benchmark_data
ของโครงสร้างซอร์สโค้ด แล้วแก้ไขไฟล์ benchmark_params.json ระบบจะแพ็กไฟล์เหล่านั้นลงในแอป และแอปจะอ่านข้อมูลจากไดเรกทอรี ดูวิธีการโดยละเอียดได้ที่แอปการเปรียบเทียบ iOS
การเปรียบเทียบประสิทธิภาพสำหรับโมเดลที่รู้จักกันดี
ส่วนนี้แสดงเกณฑ์เปรียบเทียบประสิทธิภาพของ LiteRT เมื่อเรียกใช้โมเดลที่รู้จักกันดีในอุปกรณ์ Android และ iOS บางรุ่น
การเปรียบเทียบประสิทธิภาพของ Android
ตัวเลขการเปรียบเทียบประสิทธิภาพเหล่านี้สร้างขึ้นด้วยไบนารีการเปรียบเทียบดั้งเดิม
สำหรับการทดสอบประสิทธิภาพของ Android ระบบจะตั้งค่าความสัมพันธ์ของ CPU ให้ใช้คอร์ขนาดใหญ่ในอุปกรณ์ เพื่อลดความแปรปรวน (ดูรายละเอียด)
โดยจะถือว่ามีการดาวน์โหลดและคลายซิปโมเดลไปยังไดเรกทอรี
/data/local/tmp/tflite_models แล้ว ไบนารีการเปรียบเทียบสร้างขึ้นโดยใช้วิธีการเหล่านี้
และถือว่าอยู่ในไดเรกทอรี /data/local/tmp
วิธีเรียกใช้การเปรียบเทียบ
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
หากต้องการเรียกใช้ด้วยตัวแทน GPU ให้ตั้งค่า --use_gpu=true
ค่าประสิทธิภาพด้านล่างวัดบน Android 10
| ชื่อแบบจำลอง | อุปกรณ์ | CPU, 4 เธรด | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | Pixel 3 | 23.9 มิลลิวินาที | 6.45 มิลลิวินาที |
| Pixel 4 | 14.0 มิลลิวินาที | 9.0 มิลลิวินาที | |
| Mobilenet_1.0_224 (quant) | Pixel 3 | 13.4 มิลลิวินาที | --- |
| Pixel 4 | 5.0 มิลลิวินาที | --- | |
| NASNet mobile | Pixel 3 | 56 มิลลิวินาที | --- |
| Pixel 4 | 34.5 มิลลิวินาที | --- | |
| SqueezeNet | Pixel 3 | 35.8 มิลลิวินาที | 9.5 มิลลิวินาที |
| Pixel 4 | 23.9 มิลลิวินาที | 11.1 มิลลิวินาที | |
| Inception_ResNet_V2 | Pixel 3 | 422 มิลลิวินาที | 99.8 มิลลิวินาที |
| Pixel 4 | 272.6 มิลลิวินาที | 87.2 มิลลิวินาที | |
| Inception_V4 | Pixel 3 | 486 มิลลิวินาที | 93 มิลลิวินาที |
| Pixel 4 | 324.1 มิลลิวินาที | 97.6 มิลลิวินาที |
การเปรียบเทียบประสิทธิภาพ iOS
ตัวเลขการเปรียบเทียบประสิทธิภาพเหล่านี้สร้างขึ้นด้วยแอปการเปรียบเทียบ iOS
หากต้องการเรียกใช้การเปรียบเทียบ iOS เราได้แก้ไขแอปเปรียบเทียบให้รวมโมเดลที่เหมาะสม
และแก้ไข benchmark_params.json เพื่อตั้งค่า num_threads เป็น 2 เรายังได้เพิ่มตัวเลือก "use_gpu" : "1" และ "gpu_wait_type" : "aggressive" ลงใน benchmark_params.json ด้วย
เพื่อใช้ตัวแทน GPU
| ชื่อแบบจำลอง | อุปกรณ์ | CPU, 2 เธรด | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14.8 มิลลิวินาที | 3.4 มิลลิวินาที |
| Mobilenet_1.0_224 (quant) | iPhone XS | 11 มิลลิวินาที | --- |
| NASNet Mobile | iPhone XS | 30.4 มิลลิวินาที | --- |
| SqueezeNet | iPhone XS | 21.1 มิลลิวินาที | 15.5 มิลลิวินาที |
| Inception_ResNet_V2 | iPhone XS | 261.1 มิลลิวินาที | 45.7 มิลลิวินาที |
| Inception_V4 | iPhone XS | 309 มิลลิวินาที | 54.4 มิลลิวินาที |
Trace LiteRT internals
ติดตามการทำงานภายในของ LiteRT ใน Android
เหตุการณ์ภายในจากตัวแปล LiteRT ของแอป Android สามารถ บันทึกได้โดย เครื่องมือการติดตามของ Android เหตุการณ์เหล่านี้เป็นเหตุการณ์เดียวกันกับ Android Trace API ดังนั้น เหตุการณ์ที่บันทึกจากโค้ด Java/Kotlin จะแสดงร่วมกับเหตุการณ์ภายในของ LiteRT
ตัวอย่างเหตุการณ์มีดังนี้
- การเรียกใช้โอเปอเรเตอร์
- การแก้ไขกราฟโดยผู้รับมอบสิทธิ์
- การจัดสรร Tensor
ในบรรดาตัวเลือกต่างๆ สำหรับการบันทึกร่องรอย คู่มือนี้จะครอบคลุมโปรไฟล์เลอร์ CPU ของ Android Studio และแอปการติดตามระบบ โปรดดูเครื่องมือบรรทัดคำสั่ง Perfetto หรือ เครื่องมือบรรทัดคำสั่ง Systrace สำหรับตัวเลือกอื่นๆ
การเพิ่มเหตุการณ์การติดตามในโค้ด Java
นี่คือข้อมูลโค้ดจากแอปตัวอย่าง
การจัดประเภทรูปภาพ
ตัวแปล LiteRT จะทํางานในส่วน
recognizeImage/runInference ขั้นตอนนี้เป็นขั้นตอนที่ไม่บังคับ แต่มีประโยชน์ในการ
ช่วยสังเกตว่ามีการเรียกใช้การอนุมานที่ใด
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
เปิดใช้การติดตาม LiteRT
หากต้องการเปิดใช้การติดตาม LiteRT ให้ตั้งค่าพร็อพเพอร์ตี้ของระบบ Android
debug.tflite.trace เป็น 1 ก่อนเริ่มแอป Android
adb shell setprop debug.tflite.trace 1
หากตั้งค่าพร็อพเพอร์ตี้นี้เมื่อเริ่มต้นตัวแปล LiteRT ระบบจะติดตามเหตุการณ์สำคัญ (เช่น การเรียกใช้ตัวดำเนินการ) จากตัวแปล
หลังจากบันทึกการติดตามทั้งหมดแล้ว ให้ปิดใช้การติดตามโดยตั้งค่าพร็อพเพอร์ตี้ เป็น 0
adb shell setprop debug.tflite.trace 0
เครื่องมือสร้างโปรไฟล์ CPU ของ Android Studio
บันทึกร่องรอยด้วย โปรไฟล์เลอร์ CPU ของ Android Studio โดยทำตามขั้นตอนด้านล่าง
เลือกเรียกใช้ > โปรไฟล์ "แอป" จากเมนูด้านบน
คลิกที่ใดก็ได้ในไทม์ไลน์ CPU เมื่อหน้าต่าง Profiler ปรากฏขึ้น
เลือก "ติดตามการเรียกใช้ระบบ" ในโหมดการจัดโปรไฟล์ CPU
กดปุ่ม "บันทึก"
กดปุ่ม "หยุด"
ตรวจสอบผลการติดตาม
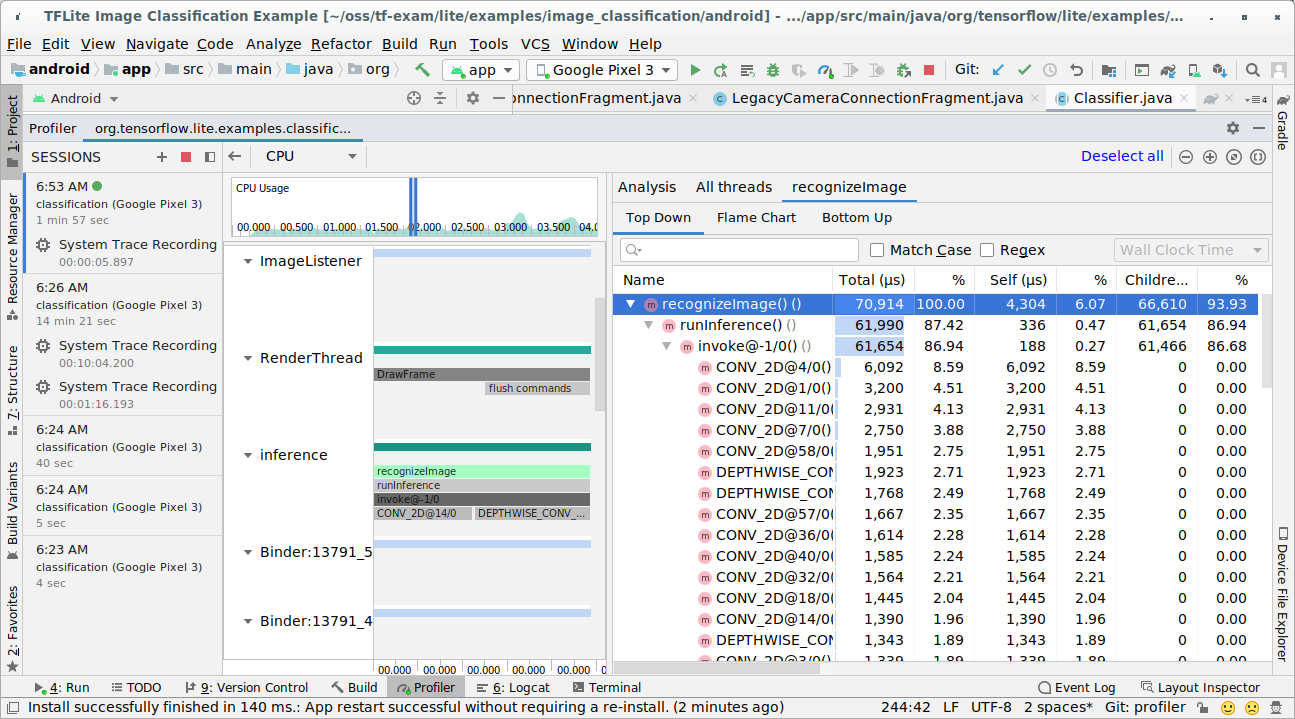
ในตัวอย่างนี้ คุณจะเห็นลําดับชั้นของเหตุการณ์ในเธรดและสถิติ สําหรับเวลาของผู้ปฏิบัติงานแต่ละคน รวมถึงเห็นโฟลว์ข้อมูลของทั้งแอปใน เธรดต่างๆ
แอป System Tracing
บันทึกร่องรอยโดยไม่ต้องใช้ Android Studio โดยทำตามขั้นตอนที่อธิบายไว้ในแอปการติดตามระบบ
ในตัวอย่างนี้ ระบบจะบันทึกและจัดเก็บเหตุการณ์ TFLite เดียวกันในรูปแบบ Perfetto หรือ Systrace ขึ้นอยู่กับเวอร์ชันของอุปกรณ์ Android คุณเปิดไฟล์การติดตามที่บันทึกไว้ได้ใน UI ของ Perfetto
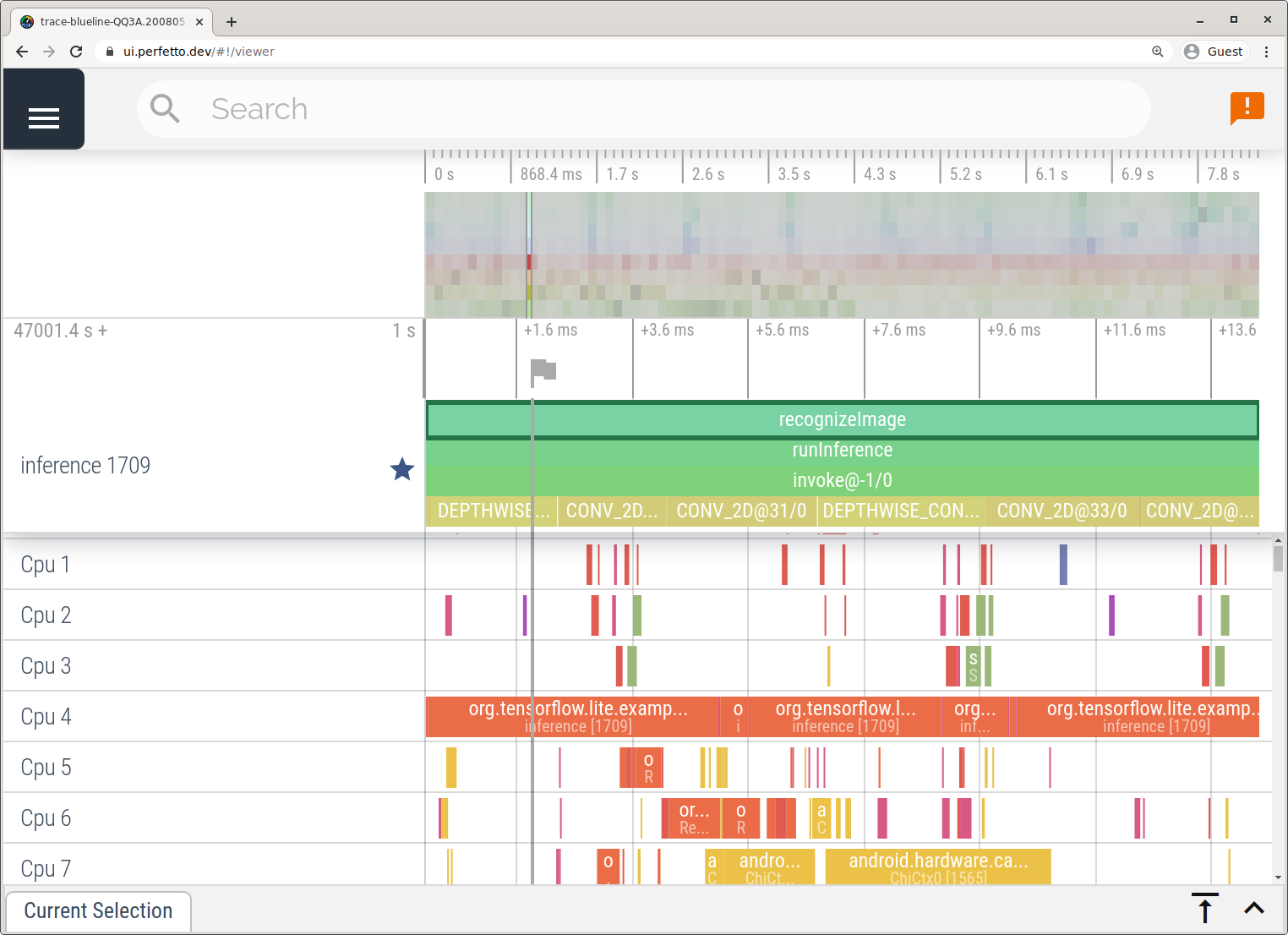
ติดตามรายละเอียดภายในของ LiteRT ใน iOS
เครื่องมือ Instruments ที่รวมอยู่ใน Xcode สามารถบันทึกเหตุการณ์ภายในจากตัวแปล LiteRT ของแอป iOS ได้ เหตุการณ์เหล่านี้คือเหตุการณ์ signpost ของ iOS ดังนั้นเหตุการณ์ที่บันทึกจากโค้ด Swift/Objective-C จะแสดงร่วมกับเหตุการณ์ภายในของ LiteRT
ตัวอย่างเหตุการณ์มีดังนี้
- การเรียกใช้โอเปอเรเตอร์
- การแก้ไขกราฟโดยผู้รับมอบสิทธิ์
- การจัดสรร Tensor
เปิดใช้การติดตาม LiteRT
ตั้งค่าตัวแปรสภาพแวดล้อม debug.tflite.trace โดยทำตามขั้นตอนด้านล่าง
เลือกผลิตภัณฑ์ > รูปแบบ > แก้ไขรูปแบบ... จากเมนูด้านบนของ Xcode
คลิก "โปรไฟล์" ในแผงด้านซ้าย
ยกเลิกการเลือกช่องทำเครื่องหมาย "ใช้อาร์กิวเมนต์และตัวแปรสภาพแวดล้อมของการดำเนินการ Run"
เพิ่ม
debug.tflite.traceในส่วน "ตัวแปรสภาพแวดล้อม"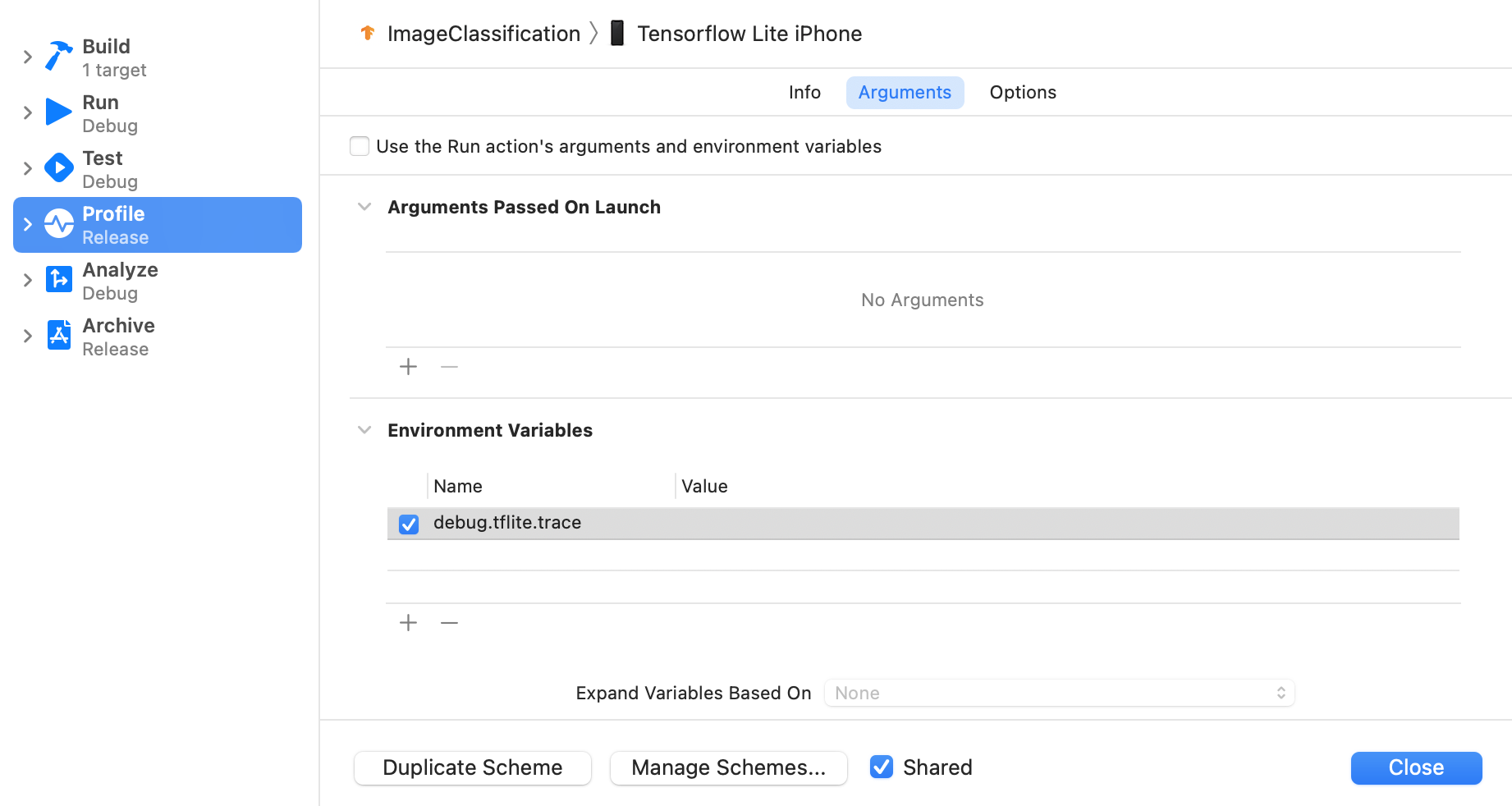
หากต้องการยกเว้นเหตุการณ์ LiteRT เมื่อทำโปรไฟล์แอป iOS ให้ปิดใช้การติดตามโดยนำตัวแปรสภาพแวดล้อมออก
XCode Instruments
บันทึกการติดตามโดยทำตามขั้นตอนด้านล่าง
เลือกผลิตภัณฑ์ > โปรไฟล์จากเมนูด้านบนของ Xcode
คลิกการบันทึกในเทมเพลตการสร้างโปรไฟล์เมื่อเปิดใช้เครื่องมือ Instruments
กดปุ่ม "เริ่ม"
กดปุ่ม "หยุด"
คลิก "os_signpost" เพื่อขยายรายการย่อยของระบบย่อยการบันทึก OS
คลิกระบบย่อยการบันทึกของระบบ "org.tensorflow.lite"
ตรวจสอบผลการติดตาม
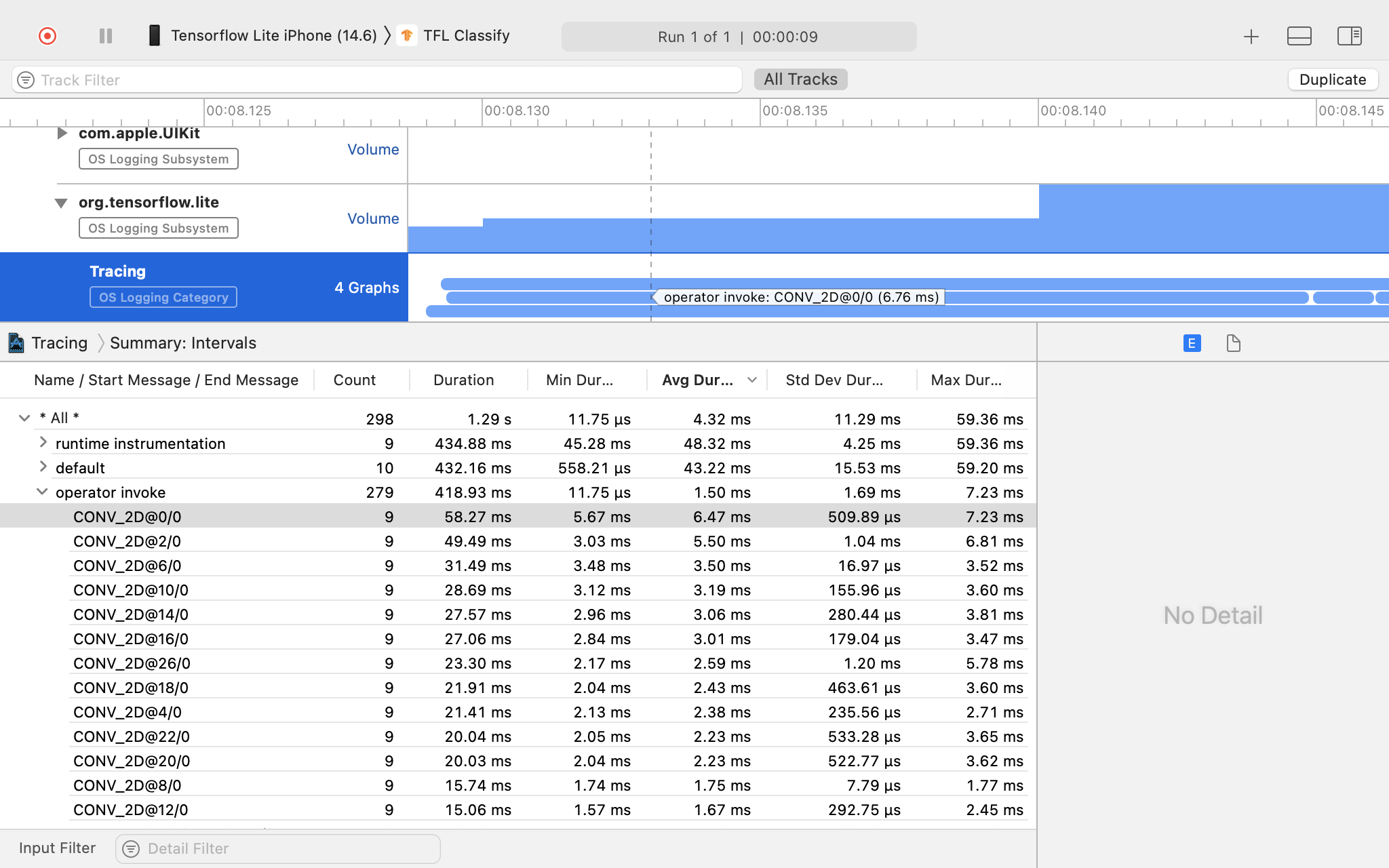
ในตัวอย่างนี้ คุณจะเห็นลําดับชั้นของเหตุการณ์และสถิติสําหรับเวลาของโอเปอเรเตอร์แต่ละราย
การใช้ข้อมูลการติดตาม
ข้อมูลการติดตามช่วยให้คุณระบุจุดคอขวดด้านประสิทธิภาพได้
ตัวอย่างข้อมูลเชิงลึกที่คุณได้รับจากโปรไฟล์เลอร์และ วิธีแก้ปัญหาที่อาจช่วยปรับปรุงประสิทธิภาพมีดังนี้
- หากจำนวนแกน CPU ที่พร้อมใช้งานน้อยกว่าจำนวนเธรดการอนุมาน ค่าใช้จ่ายในการกำหนดเวลา CPU อาจทำให้ประสิทธิภาพต่ำกว่ามาตรฐาน คุณสามารถจัดกำหนดการงานอื่นๆ ที่ใช้ CPU มากในแอปพลิเคชันใหม่เพื่อหลีกเลี่ยง การทับซ้อนกับการอนุมานโมเดล หรือปรับจำนวนเธรดของอินเทอร์พรีเตอร์
- หากไม่ได้มอบสิทธิ์ให้โอเปอเรเตอร์อย่างเต็มรูปแบบ ระบบจะเรียกใช้บางส่วนของกราฟโมเดล บน CPU แทนที่จะเป็นตัวเร่งฮาร์ดแวร์ตามที่คาดไว้ คุณ สามารถแทนที่โอเปอเรเตอร์ที่ไม่รองรับด้วยโอเปอเรเตอร์ที่รองรับที่คล้ายกัน