
Gli strumenti di benchmarking LiteRT misurano e calcolano le statistiche per le seguenti importanti metriche sul rendimento:
- Tempo di inizializzazione
- Tempo di inferenza dello stato di warmup
- Tempo di inferenza dello stato stazionario
- Utilizzo della memoria durante il tempo di inizializzazione
- Utilizzo complessivo della memoria
Gli strumenti di benchmarking sono disponibili come app di benchmarking per Android e iOS e come binari della riga di comando precompilati e condividono tutti la stessa logica di misurazione delle prestazioni di base. Tieni presente che le opzioni disponibili e i formati di output sono leggermente diversi a causa delle differenze nell'ambiente di runtime.
App benchmark per Android
Viene fornita anche un'app di benchmark per Android basata sull'API Interpreter v1. Si tratta di una misura migliore di come si comporterebbe il modello in un'app per Android. I numeri dello strumento di benchmark differiranno comunque leggermente da quelli ottenuti durante l'inferenza con il modello nell'app effettiva.
Questa app di benchmark per Android non ha un'interfaccia utente. Installalo ed eseguilo utilizzando il comando adb e recupera i risultati utilizzando il comando adb logcat.
Scaricare o creare l'app
Scarica le app di benchmark Android precompilate notturne utilizzando i seguenti link:
Per quanto riguarda le app di benchmark per Android che supportano le operazioni TF tramite il delegato flessibile, utilizza i seguenti link:
Puoi anche creare l'app dal codice sorgente seguendo queste istruzioni.
Prepara benchmark
Prima di eseguire l'app di benchmark, installala e trasferisci il file del modello sul dispositivo nel seguente modo:
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
Esegui benchmark
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph è un parametro obbligatorio.
graph:string
Il percorso del file del modello TFLite.
Puoi specificare altri parametri facoltativi per l'esecuzione del benchmark.
num_threads:int(valore predefinito=1)
Il numero di thread da utilizzare per l'esecuzione dell'interprete TFLite.use_gpu:bool(default=false)
Utilizza il delegato GPU.use_xnnpack:bool(valore predefinito=false)
Utilizza XNNPACK delegate.
A seconda del dispositivo che utilizzi, alcune di queste opzioni potrebbero non essere disponibili o non avere effetto. Consulta la sezione parametri per altri parametri di rendimento che puoi eseguire con l'app di benchmarking.
Visualizza i risultati utilizzando il comando logcat:
adb logcat | grep "Inference timings"
I risultati del benchmark vengono riportati come:
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
App benchmark per iOS
Per eseguire benchmark su un dispositivo iOS, devi creare l'app dal
codice sorgente.
Inserisci il file del modello LiteRT nella directory
benchmark_data
dell'albero delle origini e modifica il file benchmark_params.json. Questi
file vengono inseriti nel pacchetto dell'app e l'app legge i dati dalla directory. Visita
l'app di benchmark per iOS
per istruzioni dettagliate.
Benchmark del rendimento per modelli noti
Questa sezione elenca i benchmark delle prestazioni di LiteRT durante l'esecuzione di modelli noti su alcuni dispositivi Android e iOS.
Benchmark delle prestazioni di Android
Questi numeri di benchmark prestazionali sono stati generati con il file binario di benchmark nativo.
Per i benchmark Android, l'affinità della CPU è impostata per utilizzare i core di grandi dimensioni sul dispositivo per ridurre la varianza (vedi dettagli).
Suppone che i modelli siano stati scaricati e decompressi nella directory
/data/local/tmp/tflite_models. Il binario di benchmark viene creato utilizzando
queste istruzioni
e si presume che si trovi nella directory /data/local/tmp.
Per eseguire il benchmark:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
Per l'esecuzione con il delegato GPU, imposta --use_gpu=true.
I valori di rendimento riportati di seguito sono misurati su Android 10.
| Nome modello | Dispositivo | CPU, 4 thread | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | Pixel 3 | 23,9 ms | 6,45 ms |
| Pixel 4 | 14,0 ms | 9,0 ms | |
| Mobilenet_1.0_224 (quant) | Pixel 3 | 13,4 ms | --- |
| Pixel 4 | 5,0 ms | --- | |
| NASNet mobile | Pixel 3 | 56 ms | --- |
| Pixel 4 | 34,5 ms | --- | |
| SqueezeNet | Pixel 3 | 35,8 ms | 9,5 ms |
| Pixel 4 | 23,9 ms | 11,1 ms | |
| Inception_ResNet_V2 | Pixel 3 | 422 ms | 99,8 ms |
| Pixel 4 | 272,6 ms | 87,2 ms | |
| Inception_V4 | Pixel 3 | 486 ms | 93 ms |
| Pixel 4 | 324,1 ms | 97,6 ms |
Benchmark del rendimento per iOS
Questi numeri di benchmark prestazionali sono stati generati con l'app di benchmark per iOS.
Per eseguire i benchmark iOS, l'app di benchmark è stata modificata in modo da includere il modello appropriato e benchmark_params.json è stato modificato in modo da impostare num_threads su 2. Per utilizzare
il delegato GPU, sono state aggiunte anche le opzioni "use_gpu" : "1" e "gpu_wait_type" : "aggressive" a benchmark_params.json.
| Nome modello | Dispositivo | CPU, 2 thread | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14,8 ms | 3,4 ms |
| Mobilenet_1.0_224 (quant) | iPhone XS | 11 ms | --- |
| NASNet mobile | iPhone XS | 30,4 ms | --- |
| SqueezeNet | iPhone XS | 21,1 ms | 15,5 ms |
| Inception_ResNet_V2 | iPhone XS | 261,1 ms | 45,7 ms |
| Inception_V4 | iPhone XS | 309 ms | 54,4 ms |
Elementi interni di Trace LiteRT
Tracciare i componenti interni di LiteRT in Android
Gli eventi interni dell'interprete LiteRT di un'app per Android possono essere acquisiti dagli strumenti di tracciamento Android. Si tratta degli stessi eventi dell'API Trace di Android, quindi gli eventi acquisiti dal codice Java/Kotlin vengono visualizzati insieme agli eventi interni di LiteRT.
Alcuni esempi di eventi sono:
- Chiamata all'operatore
- Modifica del grafico da parte del delegato
- Allocazione dei tensori
Tra le diverse opzioni per acquisire le tracce, questa guida tratta il Profiler CPU di Android Studio e l'app System Tracing. Per altre opzioni, consulta Strumento da riga di comando Perfetto o Strumento da riga di comando Systrace.
Aggiunta di eventi di traccia nel codice Java
Questo è uno snippet di codice dell'app di esempio
Classificazione delle immagini. L'interprete LiteRT viene eseguito nella sezione
recognizeImage/runInference. Questo passaggio è facoltativo, ma è utile per
aiutare a notare dove viene effettuata la chiamata di inferenza.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
Abilitare il tracciamento LiteRT
Per attivare la tracciabilità LiteRT, imposta la proprietà di sistema Android
debug.tflite.trace su 1 prima di avviare l'app Android.
adb shell setprop debug.tflite.trace 1
Se questa proprietà è stata impostata durante l'inizializzazione dell'interprete LiteRT, verranno tracciati gli eventi chiave (ad es. l'invocazione dell'operatore) dell'interprete.
Dopo aver acquisito tutte le tracce, disattiva la tracciatura impostando il valore della proprietà su 0.
adb shell setprop debug.tflite.trace 0
CPU Profiler di Android Studio
Acquisisci le tracce con Android Studio CPU Profiler seguendo questi passaggi:
Seleziona Esegui > Profilo "app" dai menu in alto.
Fai clic in un punto qualsiasi della sequenza temporale della CPU quando viene visualizzata la finestra Profiler.
Seleziona "Trace System Calls" (Traccia chiamate di sistema) tra le modalità di profilazione della CPU.
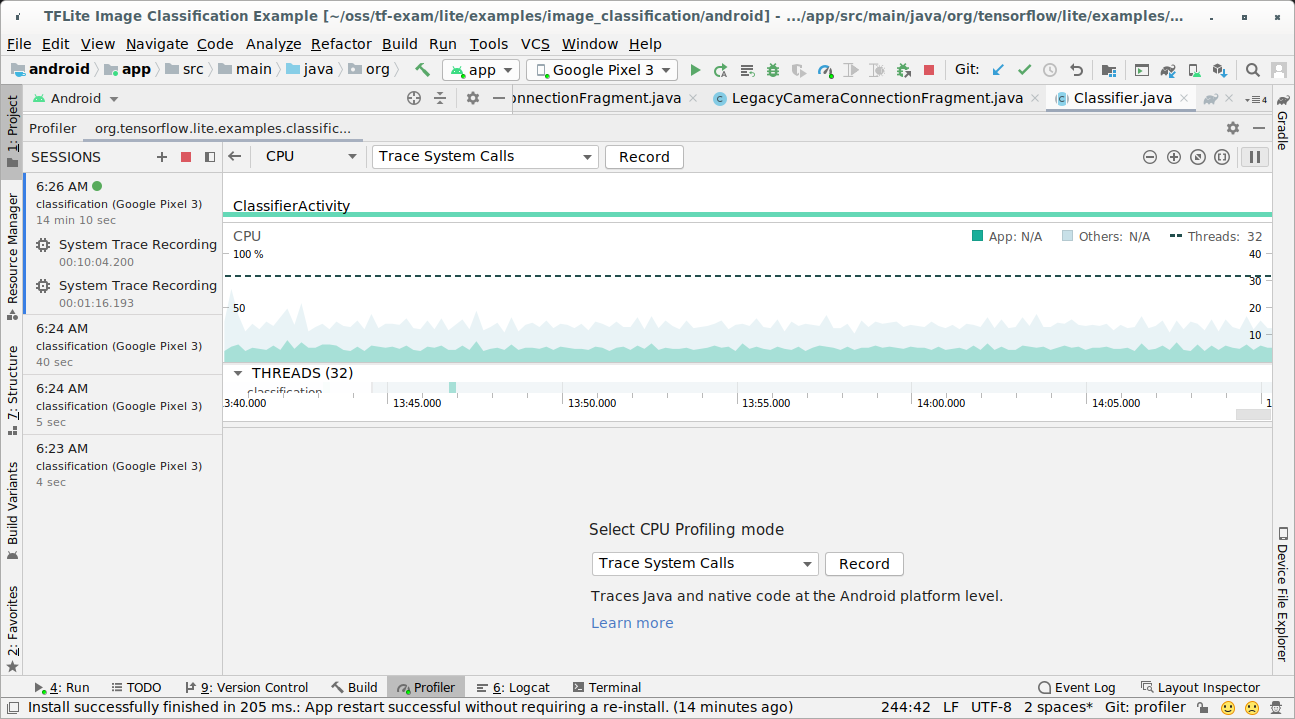
Premi il pulsante "Registra".
Premi il pulsante "Interrompi".
Esamina il risultato della traccia.
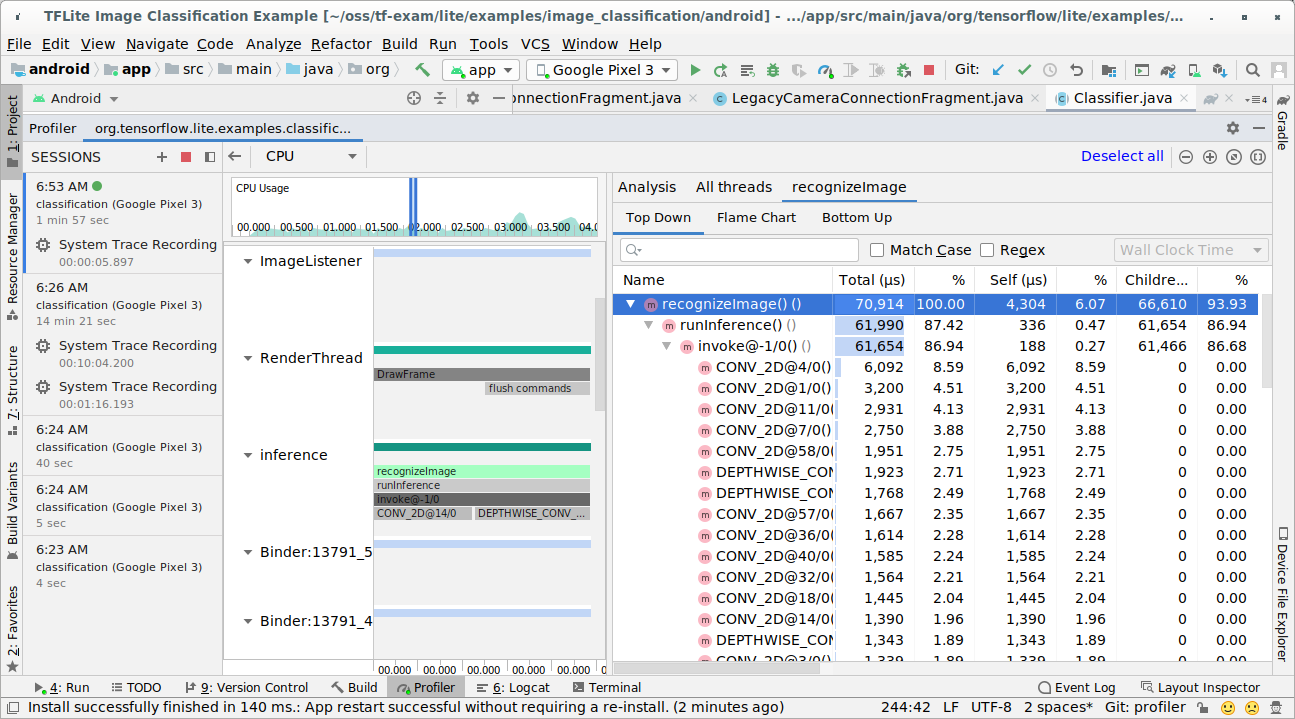
In questo esempio, puoi vedere la gerarchia degli eventi in un thread e le statistiche per ogni tempo dell'operatore, nonché il flusso di dati dell'intera app tra i thread.
App Tracciamento del sistema
Acquisisci tracce senza Android Studio seguendo i passaggi descritti nell'app System Tracing.
In questo esempio, gli stessi eventi TFLite sono stati acquisiti e salvati nel formato Perfetto o Systrace a seconda della versione del dispositivo Android. I file di traccia acquisiti possono essere aperti in Perfetto UI.
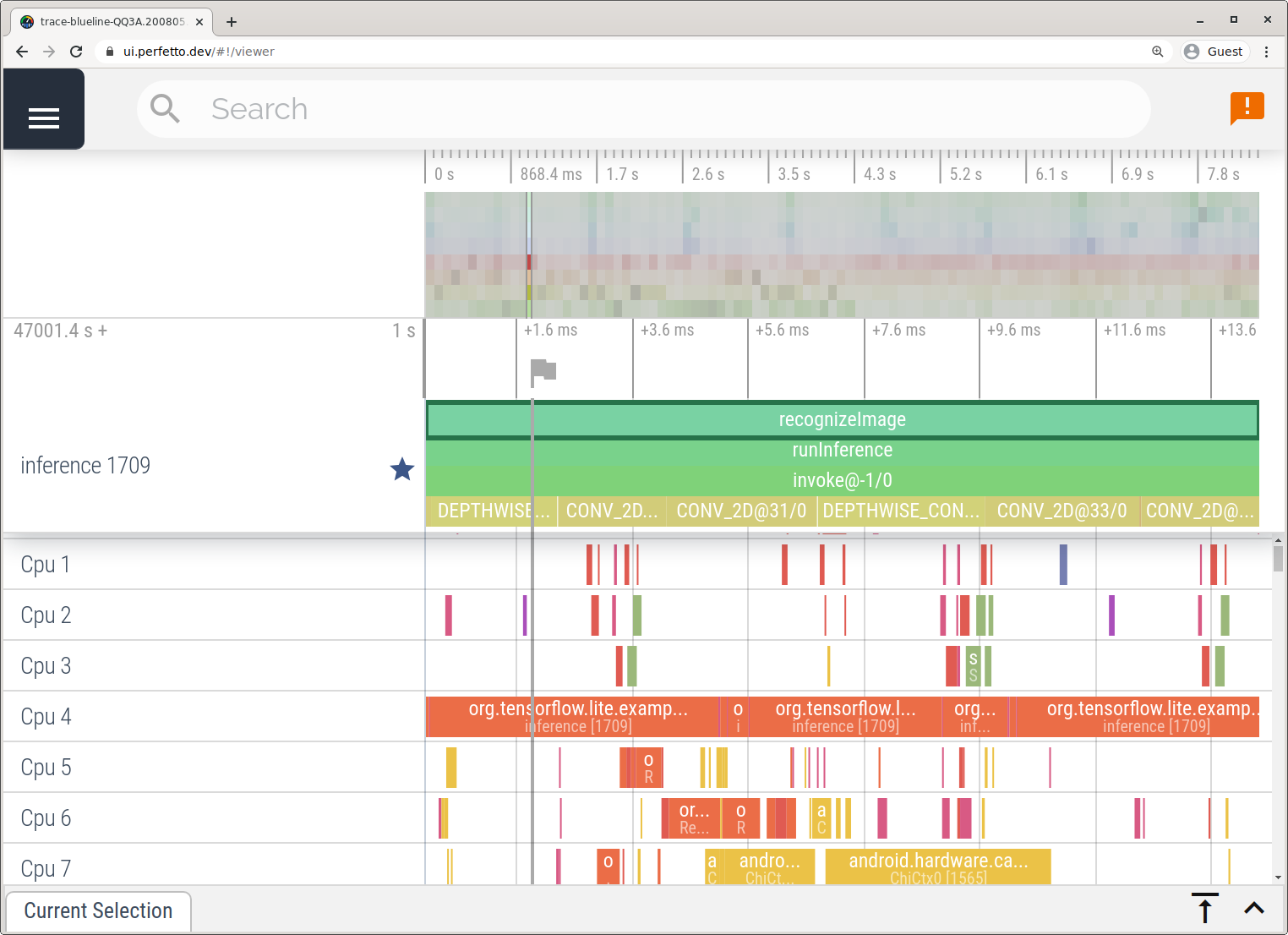
Tracciare i componenti interni di LiteRT in iOS
Gli eventi interni dell'interprete LiteRT di un'app per iOS possono essere acquisiti dallo strumento Instruments incluso in Xcode. Si tratta degli eventi signpost iOS, quindi gli eventi acquisiti dal codice Swift/Objective-C vengono visualizzati insieme agli eventi interni di LiteRT.
Alcuni esempi di eventi sono:
- Chiamata all'operatore
- Modifica del grafico da parte del delegato
- Allocazione dei tensori
Abilitare il tracciamento LiteRT
Imposta la variabile di ambiente debug.tflite.trace seguendo i passaggi riportati di seguito:
Seleziona Product > Scheme > Edit Scheme… (Prodotto > Schema > Modifica schema…) dai menu in alto di Xcode.
Fai clic su "Profilo" nel riquadro a sinistra.
Deseleziona la casella di controllo "Utilizza gli argomenti e le variabili di ambiente dell'azione Esegui".
Aggiungi
debug.tflite.tracenella sezione "Variabili di ambiente".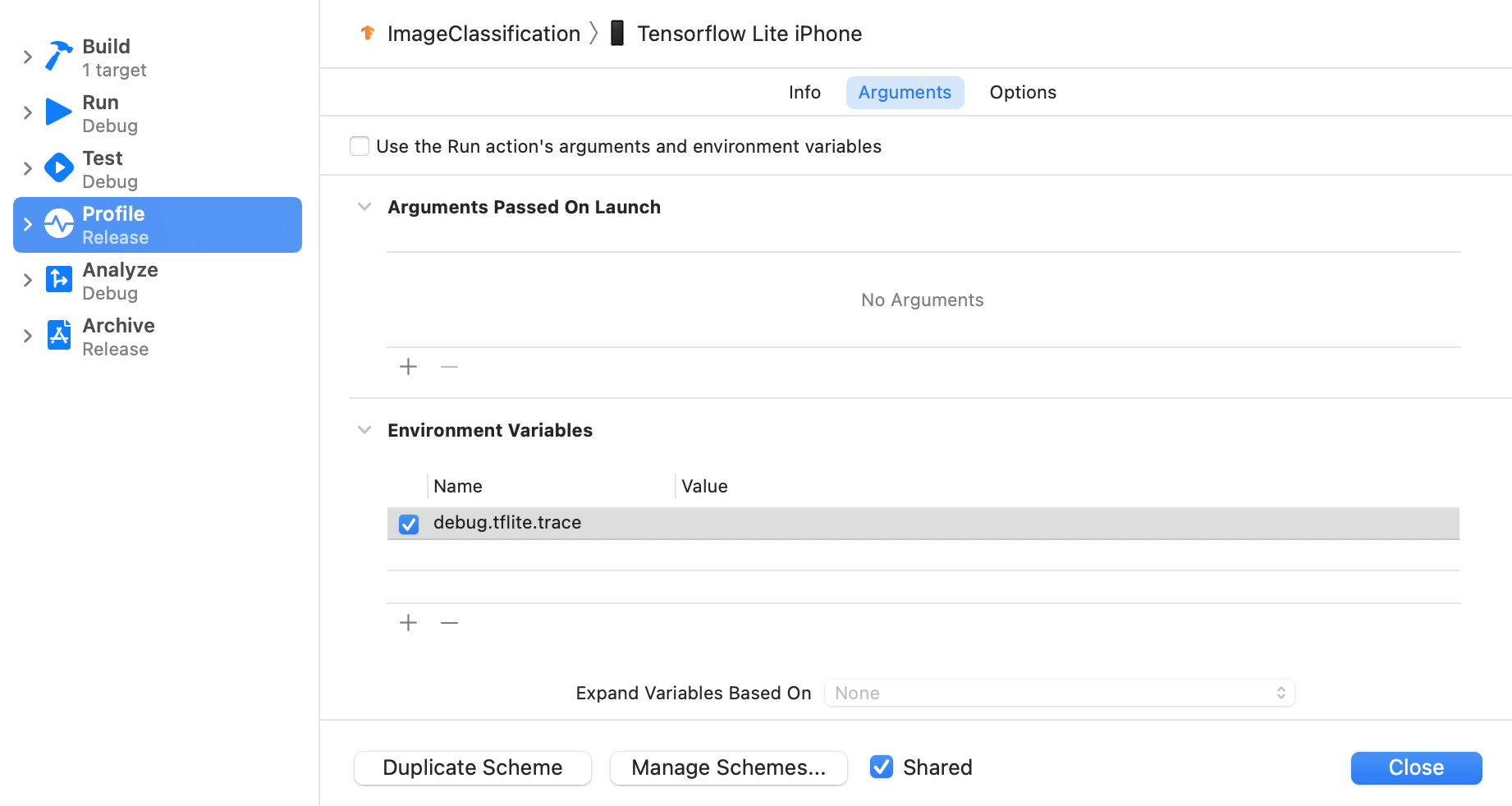
Se vuoi escludere gli eventi LiteRT durante la profilazione dell'app per iOS, disattiva la traccia rimuovendo la variabile di ambiente.
XCode Instruments
Acquisisci le tracce seguendo i passaggi riportati di seguito:
Seleziona Product > Profile (Prodotto > Profilo) dai menu in alto di Xcode.
Fai clic su Registrazione tra i modelli di profilazione all'avvio dello strumento Instruments.
Premi il pulsante "Avvia".
Premi il pulsante "Interrompi".
Fai clic su "os_signpost" per espandere gli elementi del sottosistema di logging del sistema operativo.
Fai clic sul sottosistema di logging del sistema operativo "org.tensorflow.lite".
Esamina il risultato della traccia.
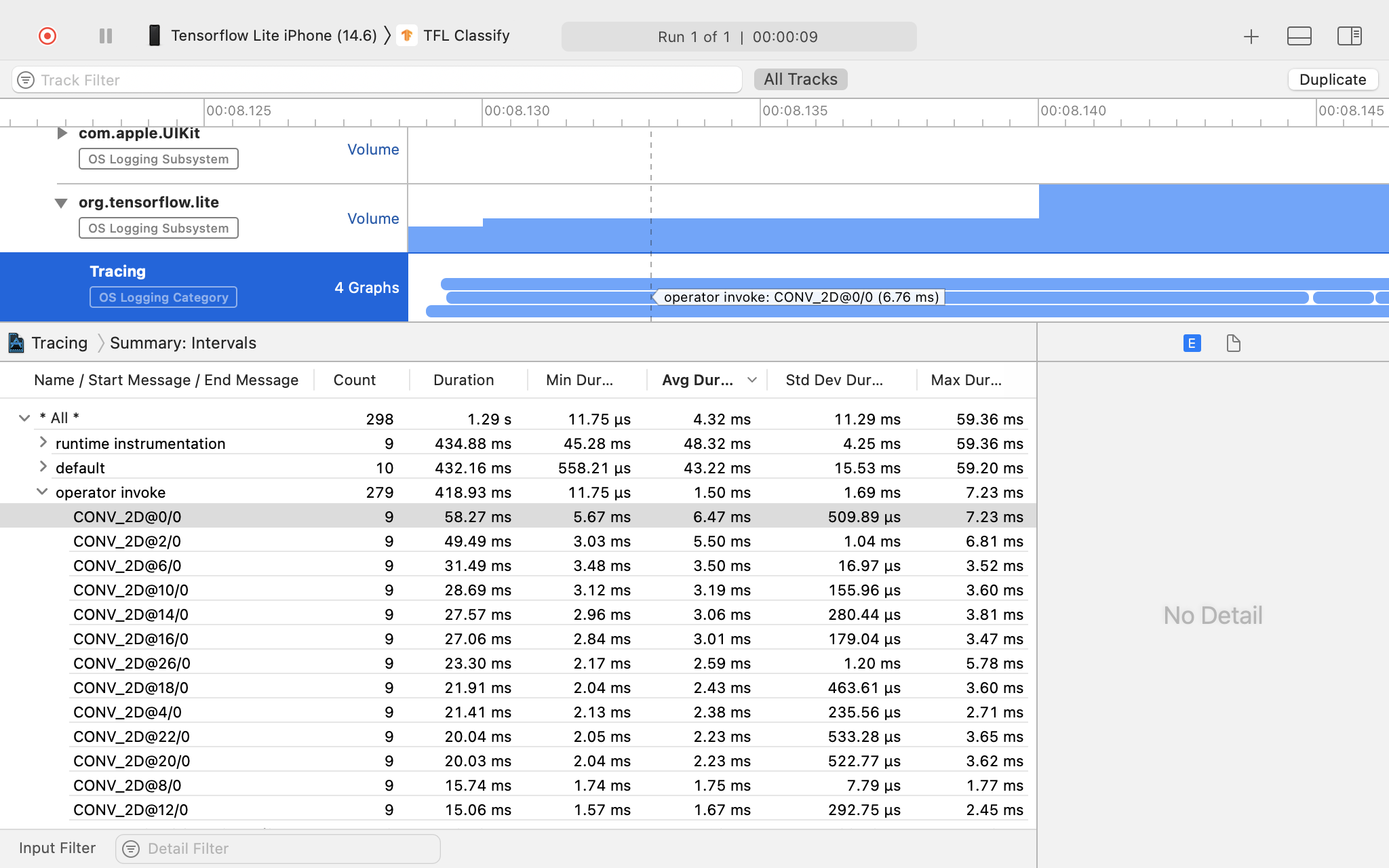
In questo esempio, puoi vedere la gerarchia degli eventi e le statistiche per ogni operatore.
Utilizzo dei dati di tracciamento
I dati di tracciamento ti consentono di identificare i colli di bottiglia delle prestazioni.
Ecco alcuni esempi di approfondimenti che puoi ottenere dal profiler e potenziali soluzioni per migliorare le prestazioni:
- Se il numero di core CPU disponibili è inferiore al numero di thread di inferenza, il sovraccarico di pianificazione della CPU può comportare prestazioni scadenti. Puoi riprogrammare altre attività che utilizzano molta CPU nella tua applicazione per evitare sovrapposizioni con l'inferenza del modello o modificare il numero di thread dell'interprete.
- Se gli operatori non sono completamente delegati, alcune parti del grafico del modello vengono eseguite sulla CPU anziché sull'acceleratore hardware previsto. Puoi sostituire gli operatori non supportati con operatori supportati simili.