
Alat benchmark LiteRT mengukur dan menghitung statistik untuk metrik performa penting berikut:
- Waktu inisialisasi
- Waktu inferensi status pemanasan
- Waktu inferensi kondisi stabil
- Penggunaan memori selama waktu inisialisasi
- Penggunaan memori keseluruhan
Alat tolok ukur tersedia sebagai aplikasi tolok ukur untuk Android dan iOS serta sebagai biner command line yang telah dibuat sebelumnya, dan semuanya menggunakan logika pengukuran performa inti yang sama. Perhatikan bahwa opsi dan format output yang tersedia sedikit berbeda karena perbedaan lingkungan runtime.
Aplikasi tolok ukur Android
Aplikasi tolok ukur Android berdasarkan Interpreter API v1 juga disediakan. Hal ini merupakan pengukuran yang lebih baik tentang performa model dalam aplikasi Android. Angka dari alat tolok ukur akan tetap sedikit berbeda dari saat menjalankan inferensi dengan model dalam aplikasi sebenarnya.
Aplikasi benchmark Android ini tidak memiliki UI. Instal dan jalankan menggunakan perintah adb
dan ambil hasilnya menggunakan perintah adb logcat.
Mendownload atau membangun aplikasi
Download aplikasi tolok ukur Android yang telah dibuat sebelumnya setiap malam menggunakan link berikut:
Untuk aplikasi tolok ukur Android yang mendukung operasi TF melalui delegasi Flex, gunakan link di bawah:
Anda juga dapat membangun aplikasi dari sumber dengan mengikuti petunjuk ini.
Siapkan tolok ukur
Sebelum menjalankan aplikasi benchmark, instal aplikasi dan kirim file model ke perangkat sebagai berikut:
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
Menjalankan benchmark
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph adalah parameter wajib.
graph:string
Jalur ke file model TFLite.
Anda dapat menentukan lebih banyak parameter opsional untuk menjalankan benchmark.
num_threads:int(default=1)
Jumlah thread yang akan digunakan untuk menjalankan interpreter TFLite.use_gpu:bool(default=false)
Gunakan GPU delegate.use_xnnpack:bool(default=false)
Gunakan XNNPACK delegate.
Bergantung pada perangkat yang Anda gunakan, beberapa opsi ini mungkin tidak tersedia atau tidak berpengaruh. Lihat parameter untuk mengetahui parameter performa lainnya yang dapat Anda jalankan dengan aplikasi tolok ukur.
Lihat hasilnya menggunakan perintah logcat:
adb logcat | grep "Inference timings"
Hasil tolok ukur dilaporkan sebagai:
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
Aplikasi benchmark iOS
Untuk menjalankan tolok ukur di perangkat iOS, Anda perlu mem-build aplikasi dari
sumber.
Letakkan file model LiteRT di direktori benchmark_data pohon sumber dan ubah file benchmark_params.json. File tersebut dikemas ke dalam aplikasi dan aplikasi membaca data dari direktori. Buka
aplikasi tolok ukur iOS
untuk mendapatkan petunjuk mendetail.
Tolok ukur performa untuk model terkenal
Bagian ini mencantumkan tolok ukur performa LiteRT saat menjalankan model terkenal di beberapa perangkat Android dan iOS.
Tolok ukur performa Android
Angka tolok ukur performa ini dihasilkan dengan biner tolok ukur native.
Untuk tolok ukur Android, afinitas CPU disetel untuk menggunakan core besar di perangkat guna mengurangi varians (lihat detail).
Contoh ini mengasumsikan bahwa model telah didownload dan diekstrak ke direktori /data/local/tmp/tflite_models. Biner tolok ukur dibuat menggunakan
petunjuk ini
dan diasumsikan berada di direktori /data/local/tmp.
Untuk menjalankan benchmark:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
Untuk menjalankan dengan delegasi GPU, tetapkan --use_gpu=true.
Nilai performa di bawah diukur di Android 10.
| Nama Model | Perangkat | CPU, 4 thread | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | Pixel 3 | 23,9 md | 6,45 md |
| Pixel 4 | 14,0 md | 9,0 md | |
| Mobilenet_1.0_224 (quant) | Pixel 3 | 13,4 md | --- |
| Pixel 4 | 5,0 md | --- | |
| NASNet seluler | Pixel 3 | 56 md | --- |
| Pixel 4 | 34,5 md | --- | |
| SqueezeNet | Pixel 3 | 35,8 md | 9,5 md |
| Pixel 4 | 23,9 md | 11,1 md | |
| Inception_ResNet_V2 | Pixel 3 | 422 md | 99,8 md |
| Pixel 4 | 272,6 md | 87,2 md | |
| Inception_V4 | Pixel 3 | 486 md | 93 md |
| Pixel 4 | 324,1 md | 97,6 md |
Tolok ukur performa iOS
Angka tolok ukur performa ini dibuat dengan aplikasi tolok ukur iOS.
Untuk menjalankan tolok ukur iOS, aplikasi tolok ukur diubah untuk menyertakan model yang sesuai dan benchmark_params.json diubah untuk menyetel num_threads ke 2. Untuk menggunakan
GPU delegate, opsi "use_gpu" : "1" dan "gpu_wait_type" : "aggressive"
juga ditambahkan ke benchmark_params.json.
| Nama Model | Perangkat | CPU, 2 thread | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(float) | iPhone XS | 14,8 md | 3,4 md |
| Mobilenet_1.0_224 (quant) | iPhone XS | 11 md | --- |
| NASNet seluler | iPhone XS | 30,4 md | --- |
| SqueezeNet | iPhone XS | 21,1 md | 15,5 md |
| Inception_ResNet_V2 | iPhone XS | 261,1 md | 45,7 md |
| Inception_V4 | iPhone XS | 309 md | 54,4 md |
Melakukan trace internal LiteRT
Melacak internal LiteRT di Android
Peristiwa internal dari interpreter LiteRT aplikasi Android dapat direkam oleh alat perekaman aktivitas Android. Peristiwa ini sama dengan Android Trace API, sehingga peristiwa yang direkam dari kode Java/Kotlin terlihat bersama dengan peristiwa internal LiteRT.
Beberapa contoh peristiwa adalah:
- Pemanggilan operator
- Modifikasi grafik oleh penerima tugas
- Alokasi tensor
Di antara berbagai opsi untuk merekam aktivitas, panduan ini membahas Profiler CPU Android Studio dan aplikasi Pelacakan Sistem. Lihat alat command line Perfetto atau alat command line Systrace untuk opsi lainnya.
Menambahkan peristiwa rekaman aktivitas dalam kode Java
Ini adalah cuplikan kode dari contoh aplikasi
Image Classification. Interpreter LiteRT berjalan di bagian
recognizeImage/runInference. Langkah ini bersifat opsional, tetapi berguna untuk
membantu melihat tempat panggilan inferensi dilakukan.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
Mengaktifkan pelacakan LiteRT
Untuk mengaktifkan perekaman aktivitas LiteRT, setel properti sistem Android
debug.tflite.trace ke 1 sebelum memulai aplikasi Android.
adb shell setprop debug.tflite.trace 1
Jika properti ini telah ditetapkan saat interpreter LiteRT diinisialisasi, peristiwa utama (misalnya, pemanggilan operator) dari interpreter akan dilacak.
Setelah Anda merekam semua rekaman aktivitas, nonaktifkan perekaman aktivitas dengan menyetel nilai properti ke 0.
adb shell setprop debug.tflite.trace 0
CPU Profiler Android Studio
Rekam aktivitas dengan Profiler CPU Android Studio dengan mengikuti langkah-langkah di bawah:
Pilih Run > Profile 'app' dari menu atas.
Klik di mana saja dalam linimasa CPU saat jendela Profiler muncul.
Pilih 'Trace System Calls' di antara mode CPU Profiling.
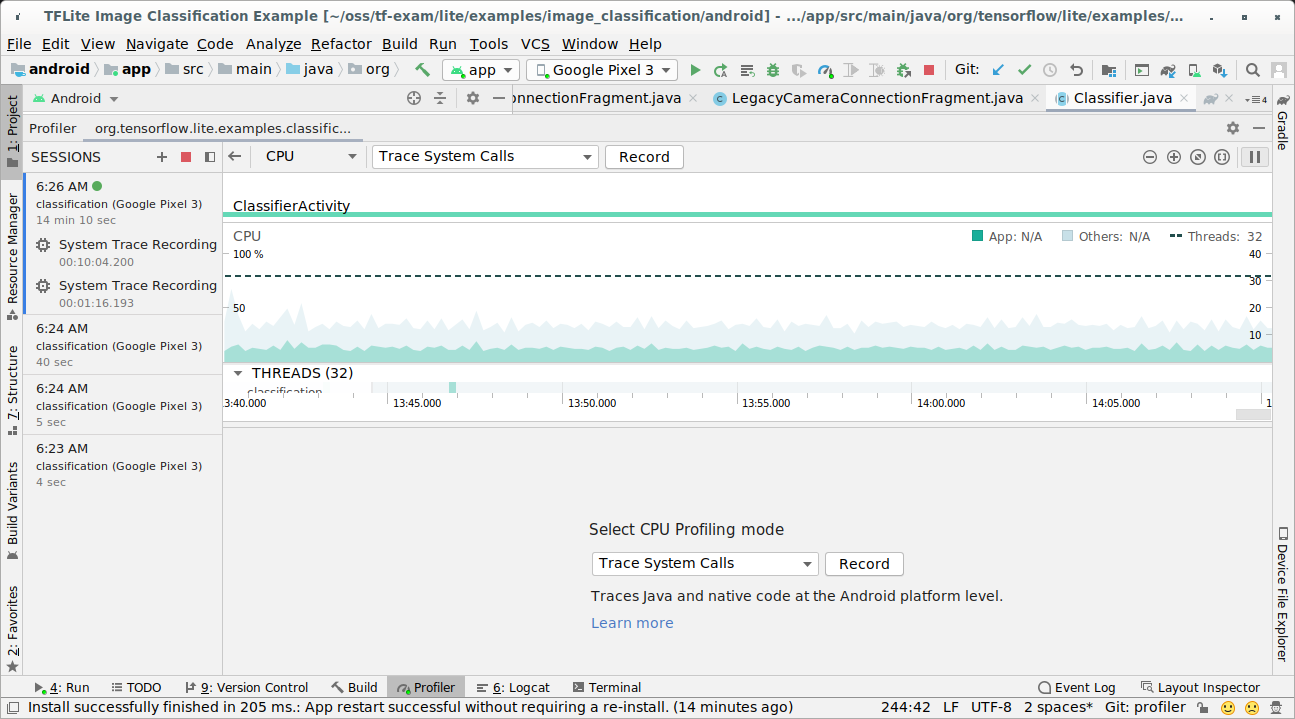
Tekan tombol 'Rekam'.
Tekan tombol 'Berhenti'.
Periksa hasil rekaman aktivitas.
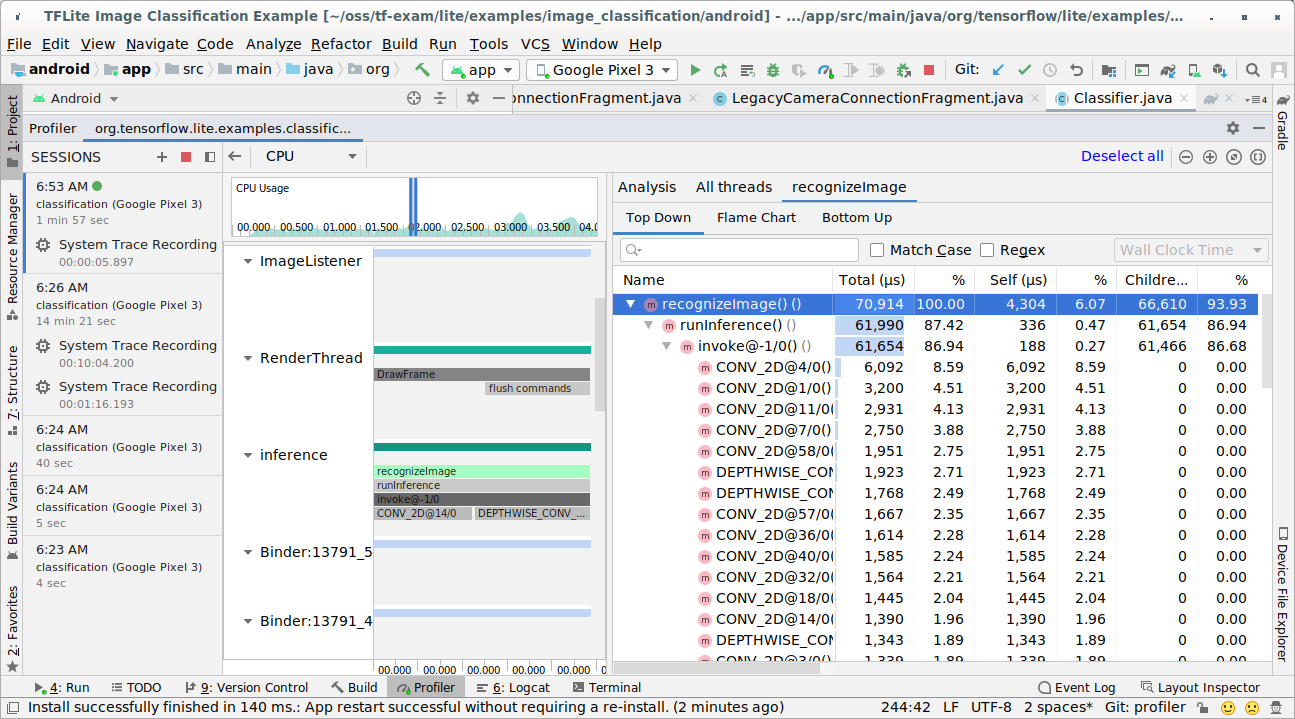
Dalam contoh ini, Anda dapat melihat hierarki peristiwa dalam thread dan statistik untuk setiap waktu operator serta melihat alur data seluruh aplikasi di antara thread.
Aplikasi Pelacakan Sistem
Merekam aktivitas tanpa Android Studio dengan mengikuti langkah-langkah yang dijelaskan dalam aplikasi Perekaman Aktivitas Sistem.
Dalam contoh ini, peristiwa TFLite yang sama direkam dan disimpan ke format Perfetto atau Systrace, bergantung pada versi perangkat Android. File rekaman aktivitas yang diambil dapat dibuka di UI Perfetto.
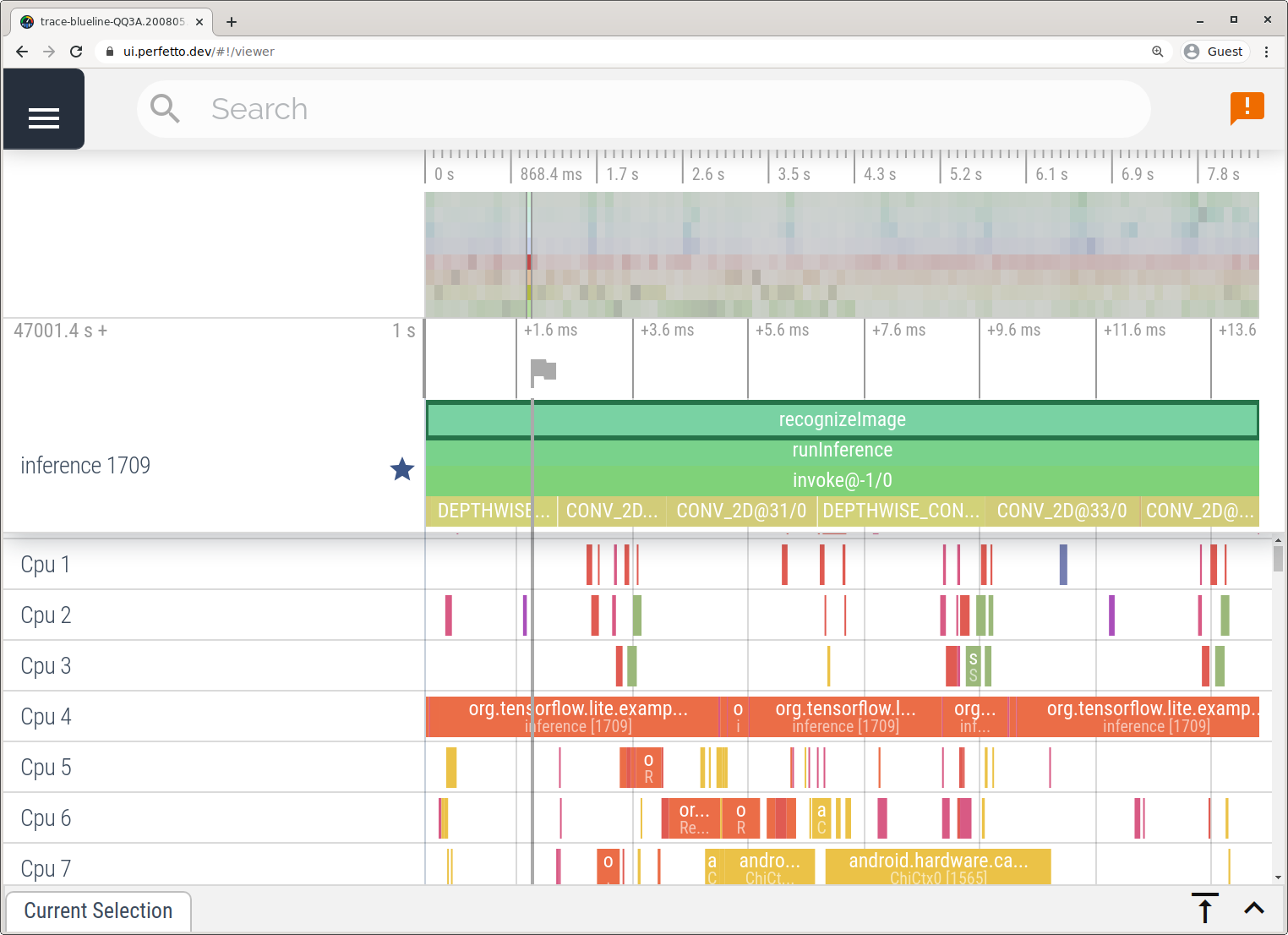
Melacak internal LiteRT di iOS
Peristiwa internal dari interpreter LiteRT aplikasi iOS dapat direkam oleh alat Instruments yang disertakan dengan Xcode. Peristiwa ini adalah peristiwa signpost iOS, sehingga peristiwa yang direkam dari kode Swift/Objective-C akan terlihat bersama dengan peristiwa internal LiteRT.
Beberapa contoh peristiwa adalah:
- Pemanggilan operator
- Modifikasi grafik oleh penerima tugas
- Alokasi tensor
Mengaktifkan pelacakan LiteRT
Tetapkan variabel lingkungan debug.tflite.trace dengan mengikuti langkah-langkah di bawah:
Pilih Product > Scheme > Edit Scheme... dari menu atas Xcode.
Klik 'Profil' di panel kiri.
Batalkan pilihan kotak centang 'Gunakan argumen dan variabel lingkungan tindakan Run'.
Tambahkan
debug.tflite.tracedi bagian 'Environment Variables'.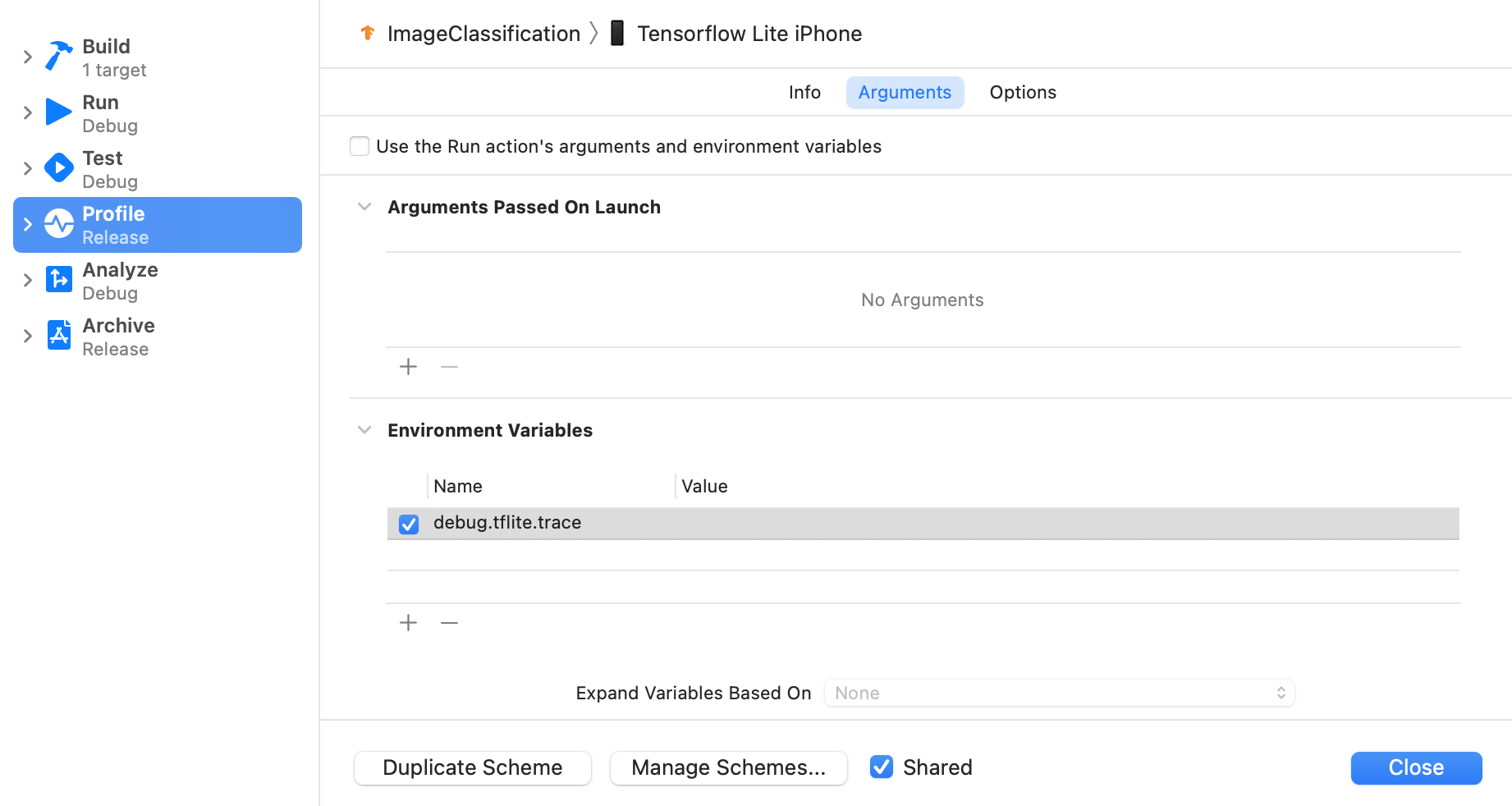
Jika Anda ingin mengecualikan peristiwa LiteRT saat membuat profil aplikasi iOS, nonaktifkan pelacakan dengan menghapus variabel lingkungan.
XCode Instruments
Ambil rekaman aktivitas dengan mengikuti langkah-langkah di bawah:
Pilih Product > Profile dari menu atas Xcode.
Klik Logging di antara template pembuatan profil saat alat Instruments diluncurkan.
Tekan tombol 'Start'.
Tekan tombol 'Berhenti'.
Klik 'os_signpost' untuk meluaskan item subsistem Logging OS.
Klik subsistem Logging OS 'org.tensorflow.lite'.
Periksa hasil rekaman aktivitas.
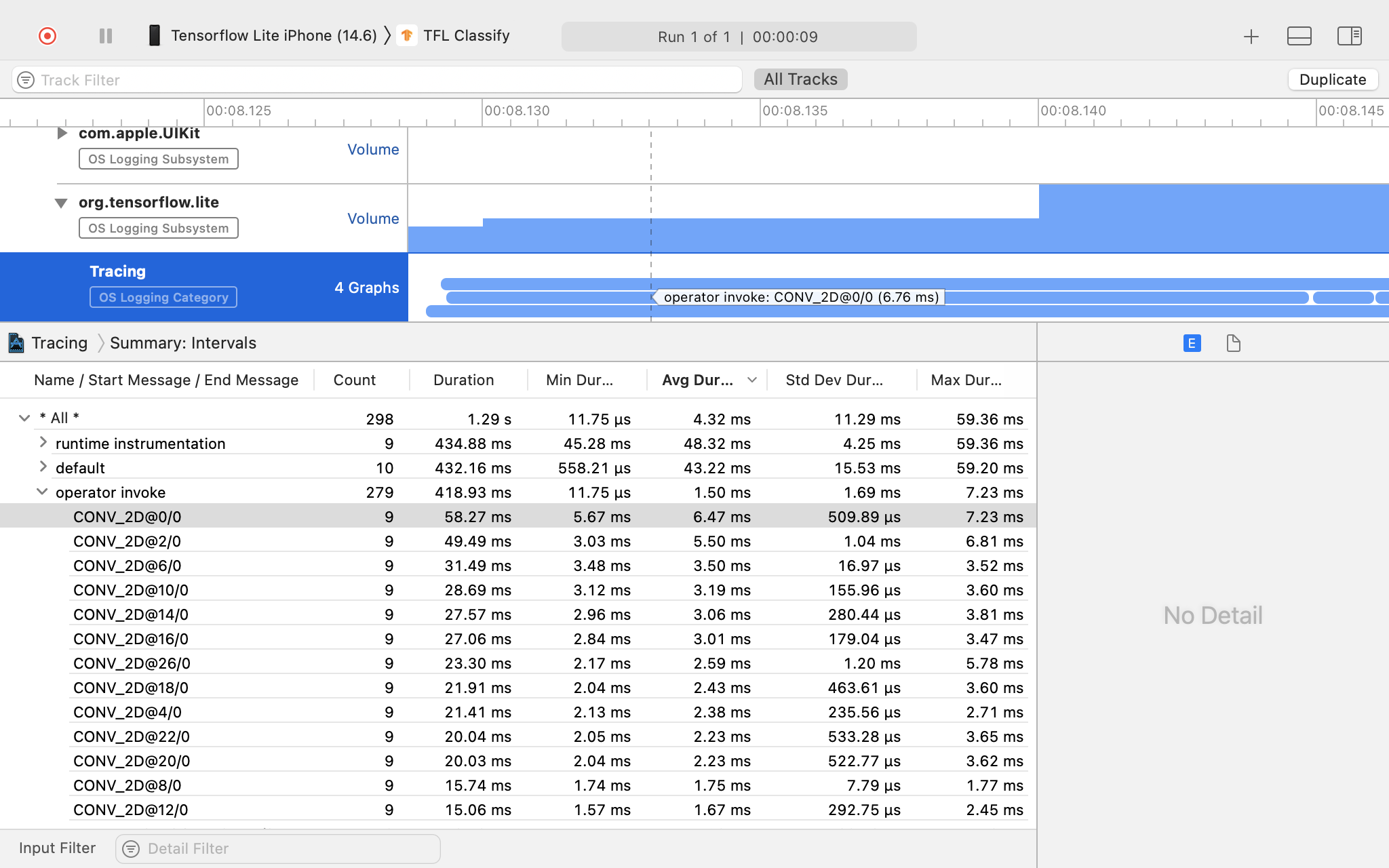
Dalam contoh ini, Anda dapat melihat hierarki peristiwa dan statistik untuk setiap waktu operator.
Menggunakan data pelacakan
Data pelacakan memungkinkan Anda mengidentifikasi bottleneck performa.
Berikut beberapa contoh insight yang bisa Anda dapatkan dari profiler dan potensi solusi untuk meningkatkan performa:
- Jika jumlah core CPU yang tersedia lebih kecil daripada jumlah thread inferensi, maka overhead penjadwalan CPU dapat menyebabkan performa yang kurang optimal. Anda dapat menjadwalkan ulang tugas intensif CPU lainnya di aplikasi untuk menghindari tumpang-tindih dengan inferensi model atau menyesuaikan jumlah thread interpreter.
- Jika operator tidak didelegasikan sepenuhnya, beberapa bagian grafik model akan dieksekusi di CPU, bukan akselerator hardware yang diharapkan. Anda dapat mengganti operator yang tidak didukung dengan operator serupa yang didukung.