
LiterRT মেটাডেটা মডেল বর্ণনার জন্য একটি মান প্রদান করে। মেটাডেটা মডেলটি কী করে এবং এর ইনপুট/আউটপুট তথ্য সম্পর্কে জ্ঞানের একটি গুরুত্বপূর্ণ উৎস। মেটাডেটা উভয়ই নিয়ে গঠিত
- মানুষের পাঠযোগ্য অংশ যা মডেল ব্যবহার করার সময় সর্বোত্তম অনুশীলন প্রকাশ করে, এবং
- মেশিন রিডেবল যন্ত্রাংশ যা কোড জেনারেটর দ্বারা ব্যবহার করা যেতে পারে, যেমন LiterRT অ্যান্ড্রয়েড কোড জেনারেটর এবং অ্যান্ড্রয়েড স্টুডিও এমএল বাইন্ডিং বৈশিষ্ট্য ।
Kaggle Models- এ প্রকাশিত সমস্ত ছবির মডেল মেটাডেটা দিয়ে পূর্ণ করা হয়েছে।
মেটাডেটা ফর্ম্যাট সহ মডেল
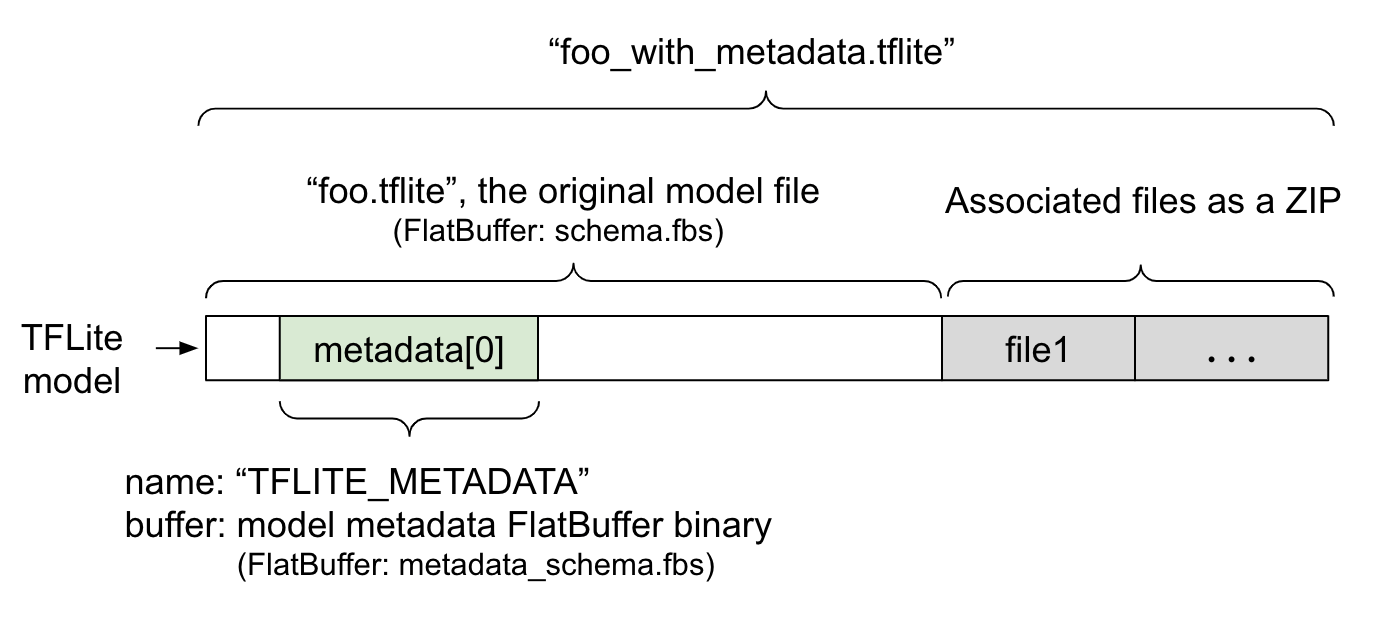
মডেল মেটাডেটা metadata_schema.fbs , একটি FlatBuffer ফাইলে সংজ্ঞায়িত করা হয়েছে। চিত্র 1-এ দেখানো হয়েছে, এটি TFLite মডেল স্কিমার মেটাডেটা ক্ষেত্রে "TFLITE_METADATA" নামে সংরক্ষণ করা হয়েছে। কিছু মডেলের সাথে সম্পর্কিত ফাইল থাকতে পারে, যেমন শ্রেণীবিভাগ লেবেল ফাইল । এই ফাইলগুলি ZipFile "append" মোড ( 'a' মোড) ব্যবহার করে একটি ZIP হিসাবে মূল মডেল ফাইলের শেষে সংযুক্ত করা হয়। TFLite ইন্টারপ্রেটার আগের মতোই নতুন ফাইল ফর্ম্যাটটি ব্যবহার করতে পারে। আরও তথ্যের জন্য সংশ্লিষ্ট ফাইলগুলি প্যাক করুন দেখুন।
মেটাডেটা কীভাবে পূরণ, কল্পনা এবং পড়া যায় সে সম্পর্কে নীচের নির্দেশাবলী দেখুন।
মেটাডেটা টুল সেটআপ করুন
আপনার মডেলে মেটাডেটা যোগ করার আগে, TensorFlow চালানোর জন্য আপনাকে একটি Python প্রোগ্রামিং পরিবেশ সেটআপ করতে হবে। এটি কীভাবে সেট আপ করবেন তার একটি বিস্তারিত নির্দেশিকা এখানে রয়েছে।
পাইথন প্রোগ্রামিং পরিবেশ সেটআপ করার পরে, আপনাকে অতিরিক্ত টুলিং ইনস্টল করতে হবে:
pip install tflite-support
LiterRT মেটাডেটা টুলিং পাইথন 3 সমর্থন করে।
Flatbuffers Python API ব্যবহার করে মেটাডেটা যোগ করা হচ্ছে
স্কিমায় মডেল মেটাডেটার তিনটি অংশ আছে:
- মডেল তথ্য - মডেলের সামগ্রিক বিবরণ এবং লাইসেন্স শর্তাবলীর মতো আইটেমগুলি দেখুন। মডেলমেটাডেটা দেখুন। 2. ইনপুট তথ্য - ইনপুট এবং প্রয়োজনীয় প্রয়োজনীয় প্রক্রিয়াকরণের বর্ণনা যেমন নরমালাইজেশন। দেখুন SubGraphMetadata.input_tensor_metadata । 3. আউটপুট তথ্য - লেবেলে ম্যাপিং করার মতো প্রয়োজনীয় আউটপুট এবং প্রক্রিয়াকরণের বিবরণ। দেখুন SubGraphMetadata.output_tensor_metadata ।
যেহেতু LiteRT এই মুহূর্তে শুধুমাত্র একক সাবগ্রাফ সমর্থন করে, তাই LiteRT কোড জেনারেটর এবং Android Studio ML বাইন্ডিং বৈশিষ্ট্যটি মেটাডেটা প্রদর্শন এবং কোড তৈরি করার সময় SubGraphMetadata.name এবং SubGraphMetadata.description এর পরিবর্তে ModelMetadata.name এবং ModelMetadata.description ব্যবহার করবে।
সমর্থিত ইনপুট / আউটপুট প্রকার
ইনপুট এবং আউটপুটের জন্য LiterRT মেটাডেটা নির্দিষ্ট মডেল ধরণের কথা মাথায় রেখে ডিজাইন করা হয়নি বরং ইনপুট এবং আউটপুট ধরণের কথা মাথায় রেখে তৈরি করা হয়েছে। মডেলটি কার্যকরীভাবে কী করে তা বিবেচ্য নয়, যতক্ষণ না ইনপুট এবং আউটপুট ধরণের মধ্যে নিম্নলিখিতগুলি থাকে বা নিম্নলিখিতগুলির সংমিশ্রণ থাকে, এটি TensorFlow Lite মেটাডেটা দ্বারা সমর্থিত:
- বৈশিষ্ট্য - স্বাক্ষরবিহীন পূর্ণসংখ্যা বা float32 সংখ্যা।
- ছবি - মেটাডেটা বর্তমানে RGB এবং গ্রেস্কেল ছবি সমর্থন করে।
- বাউন্ডিং বক্স - আয়তক্ষেত্রাকার আকৃতির বাউন্ডিং বক্স। স্কিমা বিভিন্ন সংখ্যায়ন স্কিম সমর্থন করে।
সংশ্লিষ্ট ফাইলগুলি প্যাক করুন
LiterRT মডেলগুলিতে বিভিন্ন সংযুক্ত ফাইল থাকতে পারে। উদাহরণস্বরূপ, প্রাকৃতিক ভাষা মডেলগুলিতে সাধারণত ভোকাব ফাইল থাকে যা শব্দের টুকরোগুলিকে শব্দ আইডিতে ম্যাপ করে; শ্রেণিবিন্যাস মডেলগুলিতে লেবেল ফাইল থাকতে পারে যা বস্তুর বিভাগগুলি নির্দেশ করে। সংযুক্ত ফাইলগুলি (যদি থাকে) ছাড়া, একটি মডেল ভালভাবে কাজ করবে না।
সংশ্লিষ্ট ফাইলগুলি এখন মেটাডেটা পাইথন লাইব্রেরির মাধ্যমে মডেলের সাথে একত্রিত করা যেতে পারে। নতুন LiterRT মডেলটি একটি জিপ ফাইলে পরিণত হয় যাতে মডেল এবং সংশ্লিষ্ট ফাইল উভয়ই থাকে। এটি সাধারণ জিপ টুল দিয়ে আনপ্যাক করা যেতে পারে। এই নতুন মডেল ফর্ম্যাটটি একই ফাইল এক্সটেনশন, .tflite ব্যবহার করে। এটি বিদ্যমান TFLite ফ্রেমওয়ার্ক এবং ইন্টারপ্রেটারের সাথে সামঞ্জস্যপূর্ণ। আরও বিস্তারিত জানার জন্য মডেলে মেটাডেটা এবং সংশ্লিষ্ট ফাইলগুলি প্যাক করুন দেখুন।
সংশ্লিষ্ট ফাইলের তথ্য মেটাডেটাতে রেকর্ড করা যেতে পারে। ফাইলের ধরণ এবং ফাইলটি কোথায় সংযুক্ত করা হয়েছে (যেমন ModelMetadata , SubGraphMetadata , এবং TensorMetadata ) তার উপর নির্ভর করে, LiteRT অ্যান্ড্রয়েড কোড জেনারেটর বস্তুর সাথে স্বয়ংক্রিয়ভাবে সংশ্লিষ্ট প্রাক/পোস্ট প্রক্রিয়াকরণ প্রয়োগ করতে পারে। আরও বিস্তারিত জানার জন্য স্কিমার প্রতিটি সহযোগী ফাইল ধরণের <Codegen usage> বিভাগটি দেখুন।
স্বাভাবিকীকরণ এবং পরিমাণ নির্ধারণের পরামিতি
মেশিন লার্নিংয়ে নরমালাইজেশন হল একটি সাধারণ ডেটা প্রিপ্রসেসিং কৌশল। নরমালাইজেশনের লক্ষ্য হল মানগুলির পরিসরের পার্থক্য বিকৃত না করে মানগুলিকে একটি সাধারণ স্কেলে পরিবর্তন করা।
মডেল কোয়ান্টাইজেশন হল এমন একটি কৌশল যা ওজনের হ্রাসকৃত নির্ভুল উপস্থাপনা এবং ঐচ্ছিকভাবে, স্টোরেজ এবং গণনা উভয়ের জন্য সক্রিয়করণের অনুমতি দেয়।
প্রি-প্রসেসিং এবং পোস্ট-প্রসেসিংয়ের ক্ষেত্রে, নরমালাইজেশন এবং কোয়ান্টাইজেশন দুটি স্বাধীন ধাপ। এখানে বিস্তারিত দেওয়া হল।
| স্বাভাবিকীকরণ | পরিমাণ নির্ধারণ | |
|---|---|---|
মোবাইলনেটে যথাক্রমে ফ্লোট এবং কোয়ান্ট মডেলের জন্য ইনপুট চিত্রের প্যারামিটার মানের একটি উদাহরণ। | ভাসমান মডেল : - গড়: ১২৭.৫ - মান: ১২৭.৫ কোয়ান্ট মডেল : - গড়: ১২৭.৫ - মান: ১২৭.৫ | ভাসমান মডেল : - শূন্যপয়েন্ট: ০ - স্কেল: 1.0 কোয়ান্ট মডেল : - জিরোপয়েন্ট: ১২৮.০ - স্কেল: ০.০০৭৮১২৫f |
কখন আহ্বান করতে হবে? | ইনপুট : প্রশিক্ষণে যদি ইনপুট ডেটা স্বাভাবিক করা হয়, তাহলে অনুমানের ইনপুট ডেটা সেই অনুযায়ী স্বাভাবিক করতে হবে। আউটপুট : আউটপুট ডেটা সাধারণভাবে স্বাভাবিক করা হবে না। | ফ্লোট মডেলের কোয়ান্টাইজেশনের প্রয়োজন হয় না। কোয়ান্টাইজড মডেলের প্রি/পোস্ট প্রসেসিংয়ে কোয়ান্টাইজেশনের প্রয়োজন হতে পারে আবার নাও হতে পারে। এটি ইনপুট/আউটপুট টেনসরের ডেটাটাইপের উপর নির্ভর করে। - ফ্লোট টেনসর: প্রি/পোস্ট প্রসেসিংয়ে কোন কোয়ান্টাইজেশনের প্রয়োজন নেই। কোয়ান্ট অপ এবং ডিকোয়ান্ট অপ মডেল গ্রাফে বেক করা হয়েছে। - int8/uint8 টেনসর: প্রি/পোস্ট প্রসেসিংয়ে কোয়ান্টাইজেশন প্রয়োজন। |
সূত্র | normalized_input = (ইনপুট - গড়) / std | ইনপুটগুলির পরিমাণ নির্ধারণ করুন : q = f / স্কেল + শূন্যপয়েন্ট আউটপুটগুলির জন্য পরিমাণ নির্ধারণ করুন : f = (q - শূন্যপয়েন্ট) * স্কেল |
প্যারামিটারগুলো কোথায়? | মডেল নির্মাতা দ্বারা পূরণ করা হয়েছে এবং মডেল মেটাডেটাতে NormalizationOptions হিসাবে সংরক্ষণ করা হয়েছে। | TFLite কনভার্টার দ্বারা স্বয়ংক্রিয়ভাবে পূরণ করা হয় এবং tflite মডেল ফাইলে সংরক্ষণ করা হয়। |
| প্যারামিটারগুলো কিভাবে পাবো? | MetadataExtractor API এর মাধ্যমে [2] | TFLite Tensor API [1] অথবা MetadataExtractor API [2] এর মাধ্যমে |
| ফ্লোট এবং কোয়ান্ট মডেল কি একই মান ভাগ করে? | হ্যাঁ, ফ্লোট এবং কোয়ান্ট মডেলের নরমালাইজেশন প্যারামিটার একই রকম। | না, ফ্লোট মডেলের কোয়ান্টাইজেশনের প্রয়োজন নেই। |
| TFLite কোড জেনারেটর বা অ্যান্ড্রয়েড স্টুডিও এমএল বাইন্ডিং কি ডেটা প্রক্রিয়াকরণে স্বয়ংক্রিয়ভাবে এটি তৈরি করে? | হাঁ | হাঁ |
[1] LiteRT Java API এবং LiteRT C++ API ।
[2] মেটাডেটা এক্সট্র্যাক্টর লাইব্রেরি
uint8 মডেলের জন্য ছবির ডেটা প্রক্রিয়াকরণের সময়, কখনও কখনও স্বাভাবিকীকরণ এবং কোয়ান্টাইজেশন বাদ দেওয়া হয়। পিক্সেল মান [0, 255] এর মধ্যে থাকলে এটি করা ঠিক আছে। তবে সাধারণভাবে, প্রযোজ্য ক্ষেত্রে আপনার সর্বদা স্বাভাবিকীকরণ এবং কোয়ান্টাইজেশন পরামিতি অনুসারে ডেটা প্রক্রিয়া করা উচিত।
উদাহরণ
বিভিন্ন ধরণের মডেলের জন্য মেটাডেটা কীভাবে পূরণ করা উচিত তার উদাহরণ আপনি এখানে পেতে পারেন:
ছবির শ্রেণীবিভাগ
স্ক্রিপ্টটি এখান থেকে ডাউনলোড করুন, যা mobilenet_v1_0.75_160_quantized.tflite তে মেটাডেটা পূরণ করে। স্ক্রিপ্টটি এভাবে চালান:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
অন্যান্য চিত্র শ্রেণীবিভাগ মডেলের জন্য মেটাডেটা পূরণ করতে, স্ক্রিপ্টে এই ধরণের মডেল স্পেসিফিকেশন যোগ করুন। এই নির্দেশিকার বাকি অংশে মূল উপাদানগুলি চিত্র শ্রেণীবিভাগ উদাহরণের কিছু গুরুত্বপূর্ণ অংশ তুলে ধরা হবে।
ছবির শ্রেণীবিভাগের উদাহরণটি গভীরভাবে জেনে নিন
মডেল তথ্য
মেটাডেটা একটি নতুন মডেল তথ্য তৈরি করে শুরু হয়:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
ইনপুট / আউটপুট তথ্য
এই বিভাগটি আপনাকে দেখায় কিভাবে আপনার মডেলের ইনপুট এবং আউটপুট স্বাক্ষর বর্ণনা করবেন। এই মেটাডেটা স্বয়ংক্রিয় কোড জেনারেটর দ্বারা প্রাক- এবং পোস্ট-প্রসেসিং কোড তৈরি করতে ব্যবহার করা যেতে পারে। একটি টেনসর সম্পর্কে ইনপুট বা আউটপুট তথ্য তৈরি করতে:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
ছবি ইনপুট
মেশিন লার্নিংয়ের জন্য ইমেজ একটি সাধারণ ইনপুট টাইপ। LiterRT মেটাডেটা কালারস্পেসের মতো তথ্য এবং নরমালাইজেশনের মতো প্রাক-প্রক্রিয়াকরণ তথ্য সমর্থন করে। ইমেজের মাত্রা ম্যানুয়াল স্পেসিফিকেশনের প্রয়োজন হয় না কারণ এটি ইতিমধ্যেই ইনপুট টেনসরের আকৃতি দ্বারা সরবরাহ করা হয়েছে এবং স্বয়ংক্রিয়ভাবে অনুমান করা যেতে পারে।
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
লেবেল আউটপুট
TENSOR_AXIS_LABELS ব্যবহার করে একটি সংশ্লিষ্ট ফাইলের মাধ্যমে লেবেলকে আউটপুট টেনসরের সাথে ম্যাপ করা যেতে পারে।
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
মেটাডেটা তৈরি করুন ফ্ল্যাটবাফার
নিম্নলিখিত কোডটি মডেলের তথ্য ইনপুট এবং আউটপুট তথ্যের সাথে একত্রিত করে:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
মডেলে মেটাডেটা এবং সংশ্লিষ্ট ফাইলগুলি প্যাক করুন
একবার মেটাডেটা ফ্ল্যাটবাফার তৈরি হয়ে গেলে, মেটাডেটা এবং লেবেল ফাইলটি populate পদ্ধতির মাধ্যমে TFLite ফাইলে লেখা হয়:
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
আপনি load_associated_files এর মাধ্যমে মডেলটিতে যত খুশি সংযুক্ত ফাইল প্যাক করতে পারেন। তবে, মেটাডেটাতে নথিভুক্ত কমপক্ষে সেই ফাইলগুলি প্যাক করা প্রয়োজন। এই উদাহরণে, লেবেল ফাইল প্যাক করা বাধ্যতামূলক।
মেটাডেটা ভিজ্যুয়ালাইজ করুন
আপনি আপনার মেটাডেটা কল্পনা করতে Netron ব্যবহার করতে পারেন, অথবা আপনি MetadataDisplayer ব্যবহার করে একটি LiterRT মডেল থেকে একটি json ফর্ম্যাটে মেটাডেটা পড়তে পারেন:
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
অ্যান্ড্রয়েড স্টুডিও অ্যান্ড্রয়েড স্টুডিও এমএল বাইন্ডিং বৈশিষ্ট্যের মাধ্যমে মেটাডেটা প্রদর্শন সমর্থন করে।
মেটাডেটা সংস্করণ
মেটাডেটা স্কিমাটি সিমান্টিক ভার্সনিং নম্বর দ্বারা ভার্সন করা হয়, যা স্কিমা ফাইলের পরিবর্তনগুলি ট্র্যাক করে এবং ফ্ল্যাটবাফার্স ফাইল সনাক্তকরণ দ্বারা, যা সত্য সংস্করণের সামঞ্জস্যতা নির্দেশ করে।
শব্দার্থিক সংস্করণ সংখ্যা
মেটাডেটা স্কিমাটি সিমান্টিক ভার্সনিং নম্বর , যেমন MAJOR.MINOR.PATCH দ্বারা ভার্সন করা হয়। এটি এখানে নিয়ম অনুসারে স্কিমার পরিবর্তনগুলি ট্র্যাক করে। ভার্সন 1.0.0 এর পরে যোগ করা ফিল্ডগুলির ইতিহাস দেখুন।
ফ্ল্যাটবাফার্স ফাইল সনাক্তকরণ
নিয়ম মেনে চললে সিমান্টিক ভার্সনিং সামঞ্জস্যের নিশ্চয়তা দেয়, কিন্তু এটি প্রকৃত অসঙ্গতি বোঝায় না। MAJOR নম্বরটি বাম্প করার সময়, এর অর্থ এই নয় যে ব্যাকওয়ার্ড সামঞ্জস্যতা ভেঙে গেছে। অতএব, আমরা মেটাডেটা স্কিমার প্রকৃত সামঞ্জস্য বোঝাতে Flatbuffers ফাইল আইডেন্টিফিকেশন , file_identifier ব্যবহার করি। ফাইল আইডেন্টিফায়ারটি ঠিক 4 অক্ষর দীর্ঘ। এটি একটি নির্দিষ্ট মেটাডেটা স্কিমার সাথে স্থির করা হয়েছে এবং ব্যবহারকারীদের দ্বারা পরিবর্তনের বিষয় নয়। যদি কোনও কারণে মেটাডেটা স্কিমার ব্যাকওয়ার্ড সামঞ্জস্যতা ভাঙতে হয়, তাহলে file_identifier "M001" থেকে "M002" পর্যন্ত উপরে উঠবে। metadata_version এর তুলনায় File_identifier অনেক কম ঘন ঘন পরিবর্তন হবে বলে আশা করা হচ্ছে।
ন্যূনতম প্রয়োজনীয় মেটাডেটা পার্সার সংস্করণ
ন্যূনতম প্রয়োজনীয় মেটাডেটা পার্সার সংস্করণ হল মেটাডেটা পার্সারের ন্যূনতম সংস্করণ (ফ্ল্যাটবাফার জেনারেটেড কোড) যা মেটাডেটা ফ্ল্যাটবাফারগুলিকে সম্পূর্ণরূপে পড়তে পারে। সংস্করণটি কার্যকরভাবে সমস্ত ক্ষেত্রের ভার্সনগুলির মধ্যে বৃহত্তম সংস্করণ নম্বর এবং ফাইল শনাক্তকারী দ্বারা নির্দেশিত সবচেয়ে ছোট সামঞ্জস্যপূর্ণ সংস্করণ। মেটাডেটা একটি TFLite মডেলে পপুলেট করা হলে ন্যূনতম প্রয়োজনীয় মেটাডেটা পার্সার সংস্করণটি স্বয়ংক্রিয়ভাবে MetadataPopulator দ্বারা পপুলেট করা হয়। ন্যূনতম প্রয়োজনীয় মেটাডেটা পার্সার সংস্করণ কীভাবে ব্যবহার করা হয় সে সম্পর্কে আরও তথ্যের জন্য মেটাডেটা এক্সট্র্যাক্টর দেখুন।
মডেলগুলি থেকে মেটাডেটা পড়ুন
মেটাডেটা এক্সট্র্যাক্টর লাইব্রেরি হল বিভিন্ন প্ল্যাটফর্ম জুড়ে মডেলের মেটাডেটা এবং সংশ্লিষ্ট ফাইলগুলি পড়ার জন্য সুবিধাজনক টুল ( জাভা সংস্করণ এবং C++ সংস্করণ দেখুন)। আপনি Flatbuffers লাইব্রেরি ব্যবহার করে অন্যান্য ভাষায় আপনার নিজস্ব মেটাডেটা এক্সট্র্যাক্টর টুল তৈরি করতে পারেন।
জাভাতে মেটাডেটা পড়ুন
আপনার অ্যান্ড্রয়েড অ্যাপে মেটাডেটা এক্সট্র্যাক্টর লাইব্রেরি ব্যবহার করার জন্য, আমরা MavenCentral এ হোস্ট করা LiterRT মেটাডেটা AAR ব্যবহার করার পরামর্শ দিচ্ছি। এতে MetadataExtractor ক্লাস রয়েছে, সেইসাথে মেটাডেটা স্কিমা এবং মডেল স্কিমার জন্য FlatBuffers জাভা বাইন্ডিং রয়েছে।
আপনি আপনার build.gradle নির্ভরতাগুলিতে এটি নিম্নরূপ উল্লেখ করতে পারেন:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
নাইটলি স্ন্যাপশট ব্যবহার করতে, নিশ্চিত করুন যে আপনি Sonatype স্ন্যাপশট রিপোজিটরি যোগ করেছেন।
আপনি একটি ByteBuffer দিয়ে একটি MetadataExtractor অবজেক্ট ইনিশিয়ালাইজ করতে পারেন যা মডেলটির দিকে নির্দেশ করে:
public MetadataExtractor(ByteBuffer buffer);
MetadataExtractor অবজেক্টের পুরো জীবনকাল ধরে ByteBuffer অপরিবর্তিত থাকতে হবে। মডেল মেটাডেটার ফ্ল্যাটবাফার ফাইল শনাক্তকারী যদি মেটাডেটা পার্সারের সাথে মেলে না, তাহলে ইনিশিয়ালাইজেশন ব্যর্থ হতে পারে। আরও তথ্যের জন্য মেটাডেটা ভার্সনিং দেখুন।
ফাইল আইডেন্টিফায়ারের সাথে মিলে গেলে, Flatbuffers-এর ফরোয়ার্ড এবং ব্যাকওয়ার্ড সামঞ্জস্য ব্যবস্থার কারণে মেটাডেটা এক্সট্র্যাক্টর অতীত এবং ভবিষ্যতের সমস্ত স্কিমা থেকে তৈরি মেটাডেটা সফলভাবে পড়বে। তবে, ভবিষ্যতের স্কিমা থেকে ক্ষেত্রগুলি পুরানো মেটাডেটা এক্সট্র্যাক্টর দ্বারা এক্সট্র্যাক্ট করা যাবে না। মেটাডেটার ন্যূনতম প্রয়োজনীয় পার্সার সংস্করণটি মেটাডেটা পার্সারের ন্যূনতম সংস্করণ নির্দেশ করে যা মেটাডেটা ফ্ল্যাটবাফারগুলিকে সম্পূর্ণরূপে পড়তে পারে। ন্যূনতম প্রয়োজনীয় পার্সার সংস্করণ শর্ত পূরণ হয়েছে কিনা তা যাচাই করতে আপনি নিম্নলিখিত পদ্ধতিটি ব্যবহার করতে পারেন:
public final boolean isMinimumParserVersionSatisfied();
মেটাডেটা ছাড়া মডেলে পাস করা অনুমোদিত। তবে, মেটাডেটা থেকে পড়া পদ্ধতিগুলি ব্যবহার করলে রানটাইম ত্রুটি দেখা দেবে। hasMetadata পদ্ধতি ব্যবহার করে আপনি একটি মডেলে মেটাডেটা আছে কিনা তা পরীক্ষা করতে পারেন:
public boolean hasMetadata();
MetadataExtractor আপনার ইনপুট/আউটপুট টেনসরের মেটাডেটা পাওয়ার জন্য সুবিধাজনক ফাংশন প্রদান করে। উদাহরণস্বরূপ,
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
যদিও LiterRT মডেল স্কিমা একাধিক সাবগ্রাফ সমর্থন করে, TFLite ইন্টারপ্রেটার বর্তমানে শুধুমাত্র একটি একক সাবগ্রাফ সমর্থন করে। অতএব, MetadataExtractor তার পদ্ধতিতে ইনপুট আর্গুমেন্ট হিসাবে সাবগ্রাফ সূচক বাদ দেয়।
মডেলগুলি থেকে সংশ্লিষ্ট ফাইলগুলি পড়ুন
মেটাডেটা এবং সংশ্লিষ্ট ফাইল সহ LiterRT মডেলটি মূলত একটি জিপ ফাইল যা সাধারণ জিপ টুল দিয়ে আনপ্যাক করে সংশ্লিষ্ট ফাইলগুলি পেতে পারে। উদাহরণস্বরূপ, আপনি mobilenet_v1_0.75_160_quantized আনজিপ করতে পারেন এবং মডেলটিতে লেবেল ফাইলটি নিম্নরূপে বের করতে পারেন:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
আপনি মেটাডেটা এক্সট্র্যাক্টর লাইব্রেরির মাধ্যমে সংশ্লিষ্ট ফাইলগুলিও পড়তে পারেন।
জাভাতে, ফাইলের নামটি MetadataExtractor.getAssociatedFile পদ্ধতিতে পাস করুন:
public InputStream getAssociatedFile(String fileName);
একইভাবে, C++ তে, এটি এই পদ্ধতি ব্যবহার করে করা যেতে পারে, ModelMetadataExtractor::GetAssociatedFile :
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;