
LiteRT unterstützt Intel OpenVino über die CompiledModel API für die AOT- und die On-Device-Kompilierung.
Python API
Entwicklungsumgebung einrichten
Linux (x86_64):
- Ubuntu 22.04 oder 24.04 LTS
- Python 3.10 oder höher – Installation über python.org oder Ihre Distribution (
sudo apt install python3 python3-venv) - Intel-NPU-Treiber v1.32.1 – siehe Linux-NPU-Einrichtung
Windows (x86_64):
- Windows 10 oder 11
- Python 3.10 oder höher – Installation über python.org
- Intel-NPU-Treiber 32.0.100.4724+ – siehe Windows-NPU-Einrichtung
Für das Erstellen aus der Quelle ist auch Bazel 7.4.1+ mit Bazelisk oder dem hermetischen Docker-Build erforderlich.
Unterstützte SoCs
| Plattform | NPU | Codename | Betriebssystem |
|---|---|---|---|
| Intel Core Ultra Series 2 | NPU4000 | Lunar Lake (LNL) | Linux, Windows |
| Intel Core Ultra Series 3 | NPU5010 | Panther Lake (PTL) | Linux, Windows |
Schnellstart
1. NPU-Treiber installieren
Weitere Informationen finden Sie unter NPU unter Linux einrichten oder NPU unter Windows einrichten. Überspringen Sie diesen Schritt, wenn Sie nur AOT benötigen.
Der NPU-Treiber ist nur auf Systemen erforderlich, auf denen das Modell auf NPU-Hardware ausgeführt wird. Bei reinen AOT-Build-Systemen kann dieser Schritt übersprungen werden.
Hinweis:
ai-edge-litert-sdk-intel-nightlyfixiert das passende OpenVINO-Nightly-Wheel nach PEP 440-Version (z. B.openvino==2026.2.0.dev20260506). Daher benötigt pip--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly, um es zu finden. Wenn unter Linux durch die automatische Erkennung der Distribution das falsche Archiv ausgewählt wird, legen SieLITERT_OV_OS_ID=ubuntu22oderubuntu24vorpip installfest.
2. Virtuelle Python-Umgebung erstellen
Es wird empfohlen, das openvino-Wheel für die nächtliche Ausführung von einer systemweiten OpenVINO-Installation zu isolieren.
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
3. pip-Paket installieren
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
Mit --extra-index-url kann pip das angepinnte openvino-Nightly-Wheel aus dem OpenVINO-Index zusammen mit Paketen auf PyPI auflösen.
4. Installation prüfen
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
Worauf Sie in der Ausgabe achten sollten:
SDK libslistetlibopenvino_intel_npu_compiler.so(Linux) oderopenvino_intel_npu_compiler.dll(Windows) auf – erforderlich für AOT.Available devicesenthältNPU– dies bestätigt, dass der NPU-Treiber installiert ist und OpenVINO mit dem Gerät kommunizieren kann.NPUist auf Systemen, die nur AOT unterstützen (auf denen der Treiber nicht installiert ist), und auf Systemen ohne Intel NPU-Hardware nicht vorhanden.
5. AOT-Kompilierung (optional)
- Kompiliert ein
.tflitefür ein bestimmtes Intel NPU-Ziel (PTL oder LNL) vor, damit die Laufzeit den Compiler-Plug-in-Schritt überspringt. - Keine physische NPU oder der NPU-Treiber erforderlich – nur
ai-edge-litert-nightlyundai-edge-litert-sdk-intel-nightly. - Cross-Compilation wird unterstützt: Sie können auf einem beliebigen Linux- oder Windows-Host kompilieren, die resultierende
.tflitean ein Ziel des jeweiligen Betriebssystems senden und dort ausführen.
Ausgabedateien haben den Namen <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite.
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
6. NPU-Inferenz ausführen
LiteRT unterstützt zwei Inferenzpfade auf der Intel NPU:
- JIT: Lädt ein Roh-
.tflite. Das Compiler-Plug-in partitioniert und kompiliert unterstützte Vorgänge für die NPU zur Laufzeit (CompiledModel.from_file()). Fügt eine gewisse Latenz beim ersten Ausführen hinzu (variiert je nach Modell). - AOT-kompiliert: Laden Sie eine
<model>_IntelOpenVINO_<SoC>_apply_plugin.tflite, die in Schritt 4 erstellt wurde. Überspringt beim Laden den Partitionierungs- und Kompilierungsschritt.
Dieses Snippet funktioniert für beide:
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
Prüfen, ob JIT tatsächlich ausgeführt wurde
Wenn JIT erfolgreich ist, enthält das Log Folgendes (die Dateiendung ist .so unter Linux und .dll unter Windows):
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
Wenn diese Zeilen fehlen, aber Fully accelerated: True weiterhin gemeldet wird, wurde das Modell mit dem XNNPACK-CPU-Fallback und nicht auf der NPU ausgeführt. Weitere Informationen finden Sie in der Zeile zur JIT-Fehlerbehebung.
7. Benchmark
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
Häufige Flags:
| Flag | Standardeinstellung | Beschreibung |
|---|---|---|
--model PATH
|
– | Pfad zum .tflite-Modell (erforderlich). |
--signature KEY |
1. | Signaturschlüssel, der ausgeführt werden soll. |
--use_cpu/--no_cpu
|
am | Aktivieren oder deaktivieren Sie den CPU-Beschleuniger / CPU-Fallback. |
--use_gpu |
deaktiviert | Aktivieren Sie den GPU-Beschleuniger. |
--use_npu |
deaktiviert | Aktivieren Sie den Intel NPU-Beschleuniger. |
--require_full_delegation
|
deaktiviert | Fehler, wenn das Modell nicht vollständig auf den ausgewählten Beschleuniger ausgelagert wird. |
--num_runs N
|
50 | Anzahl der zeitgesteuerten Inferenziterationen. |
--warmup_runs N
|
5 | Nicht zeitgesteuerte Warm-up-Iterationen vor der Messung. |
--num_threads N |
1 | Anzahl der CPU-Threads. |
--result_json PATH
|
– | Schreibe eine JSON-Zusammenfassung (Latenzstatistiken, Durchsatz, Beschleunigerliste). |
--verbose |
deaktiviert | Zusätzliches Laufzeit-Logging. |
Erweiterte / Überschreibungs-Flags – nur erforderlich, um auf benutzerdefinierte Builds zu verweisen: --dispatch_library_path, --compiler_plugin_path, --runtime_path.
Räder mit verschiedenen Anbietern: JIT an Intel OV anpinnen
Hinweis:Wenn
Environment.create()ohne explizite Pfade aufgerufen wird, werden Anbieter unterai_edge_litert/vendors/in alphabetischer Reihenfolge automatisch erkannt und der erste gefundene Anbieter wird registriert. Bei einer Installation mit verschiedenen Anbietern ist das möglicherweise nicht Intel OV. Übergeben Sie die Intel OV-Verzeichnisse explizit, um die richtige Auswahl zu erzwingen.
- Das Pip-Rad enthält Compiler-Plug-ins für jeden registrierten Anbieter (
intel_openvino/,google_tensor/,mediatek/,qualcomm/,samsung/). - Wenn Sie den Intel OV-Pfad erzwingen möchten (empfohlen, wenn mehrere Anbieter-SDKs installiert sind), übergeben Sie die Intel OV-Verzeichnisse manuell:
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
Die Laufzeit lädt jede freigegebene Bibliothek, die sie im angegebenen Verzeichnis findet. Wenn Sie also auf vendors/intel_openvino/compiler/ verweisen, wird nur das Intel-Plug-in geladen. Die Google Tensor-/MediaTek-/Qualcomm-/Samsung-Plug-ins in gleichgeordneten Verzeichnissen werden nie verwendet.
Für die CLI sind die entsprechenden Flags:
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
NPU-Ausführung prüfen
Um zu bestätigen, dass das Modell tatsächlich auf der NPU ausgeführt wurde, müssen beide Signale vorhanden sein:
- Das Log enthält
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}– die Intel-Dispatch-Bibliothek wurde geladen (.sounter Linux,.dllunter Windows). model.is_fully_accelerated()gibtTruezurück – jeder Vorgang wurde an den ausgewählten Beschleuniger ausgelagert.
is_fully_accelerated() allein reicht nicht aus: Wenn die Dispatch-Bibliothek nie geladen wurde, wurden Vorgänge vollständig auf XNNPACK/CPU ausgelagert, nicht auf die NPU.
Linux-NPU-Einrichtung
Hinweis:Überspringen Sie diesen Abschnitt, wenn Sie nur AOT benötigen. Eine physische NPU ist nicht erforderlich.
Info:Verwenden Sie den NPU-Treiber v1.32.1 (in Kombination mit OpenVINO 2026.1). Ältere Treiber schlagen mit
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATUREfehl.
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
Führen Sie dann den Installations- und Bestätigungsschnipsel aus dem Schnelleinstieg aus.
Einrichtung der Windows-NPU
Hinweis:Überspringen Sie diesen Abschnitt, wenn Sie nur AOT benötigen. Eine physische NPU ist nicht erforderlich.
- Installieren Sie den Intel NPU-Treiber (32.0.100.4724+) aus dem Intel Download Center.
- Prüfen Sie, ob das NPU-Gerät im Geräte-Manager unter Neural processors (Neuronale Prozessoren) aufgeführt ist (je nach Treiber als
Intel(R) AI BoostoderIntel(R) NPUangezeigt). - Führen Sie den Installations- und Überprüfungsschnipsel aus dem Schnelleinstieg aus und ersetzen Sie
pipdurchpython -m pip.
Hinweis:
import ai_edge_litertregistriert DLL-Verzeichnisse automatisch mitos.add_dll_directory(). Daher ist für Python-Scripts keinePATH-Einrichtung erforderlich. Für Nicht-Python-Nutzer führen Siesetupvars.bataus oder stellen<openvino>/libsvorPATH.
Aus Quelle erstellen
Hinter einem Proxy? Exportieren Sie
http_proxy/https_proxy/no_proxy, bevor Sie die Build-Scripts ausführen. Sie leiten diese an Docker und den Container weiter.
Linux (Docker, hermetisch):
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
Windows (PowerShell, Bazel in PATH):
.\ci\build_pip_package_with_bazel_windows.ps1
Ausgaben werden in dist/ gespeichert:
ai_edge_litert-*.whl– das Laufzeitrad.ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz– Anbieter-SDISTs.- Die Intel-sdist ist etwa 5 KB groß. Der NPU-Compiler
.so/.dllwird zurpip install-Zeit abgerufen. Daher funktioniert dieselbe sdist unter Linux und Windows.
Unit Tests
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
Fehlerbehebung
| Problem | Problembehebung |
|---|---|
AOT-Fehler: Device with "NPU" name is not registered |
NPU-Compiler nicht abgerufen. Sehen Sie in den ai_edge_litert_sdk_intel.path_to_sdk_libs()-Listen libopenvino_intel_npu_compiler.so / .dll nach. Wenn leer, installieren Sie die App mit Netzwerkzugriff neu oder legen Sie LITERT_OV_OS_ID=ubuntu22/ubuntu24 fest. |
JIT wird auf der CPU anstelle der NPU ausgeführt (kein Partitioned subgraph-Log, kein Loaded plugin-Log, Fully accelerated: True wird weiterhin ausgegeben) |
Das Compiler-Plug-in wurde nicht erkannt. Prüfen Sie, ob ov.get_compiler_plugin_dir() einen Pfad unter ai_edge_litert/vendors/intel_openvino/compiler/ zurückgibt. Wenn mehrere Anbieter-SDKs installiert sind, übergeben Sie compiler_plugin_path=ov.get_compiler_plugin_dir() explizit an Environment.create() (oder --compiler_plugin_path=... an litert-benchmark). |
JIT-Fehler: Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so (Linux) / openvino_intel_npu_compiler.dll (Windows) |
Beim ersten import ai_edge_litert_sdk_intel kopiert das SDK-sdist den NPU-Compiler nach openvino/libs/. Wenn das Kopieren übersprungen wurde (schreibgeschütztes Dateisystem, openvino fehlt), installieren Sie ai-edge-litert-sdk-intel neu, nachdem openvino installiert wurde, und dann import ai_edge_litert in einem neuen Prozess. |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE |
Aktualisieren Sie den NPU-Treiber auf Version 1.32.1 (Linux). |
/dev/accel/accel0 nicht gefunden |
sudo dmesg | grep -i vpu, um den Treiber zu debuggen. Starten Sie das Gerät nach der Installation neu. |
| Berechtigung für NPU verweigert | sudo gpasswd -a ${USER} render && newgrp render. |
| Windows: NPU nicht im Geräte-Manager | Installieren Sie den NPU-Treiber 32.0.100.4724+ aus dem Intel Download Center. |
Windows: Failed to initialize Dispatch API / fehlende DLLs |
Achten Sie darauf, dass import ai_edge_litert zuerst ausgeführt wird (automatische Registrierung von DLL-Verzeichnissen). Bei Nicht-Python-Aufrufern führen Sie setupvars.bat aus oder stellen Sie <openvino>/libs vor PATH. |
Windows-Build: LNK2001 fixed_address_empty_string, C2491 dllimport, Python 3.12+ fails |
Protobuf-ABI / Einschränkung der Python-Version – siehe ci/build_pip_package_with_bazel_windows.ps1; für Windows-Builds ist Python 3.11 erforderlich. |
Beschränkungen
Über den OpenVINO-Dispatch-Pfad wird nur das NPU-Gerät unterstützt. Verwenden Sie für die CPU-Inferenz nur HardwareAccelerator.CPU (XNNPACK).
C++ API
Voraussetzungen und Einrichtung des Builds
Voraussetzungen für die Entwicklung:
- Visual Studio 2022 oder höher (C++-Entwicklungstools müssen installiert sein).
- git: Installieren Sie Git unter https://git-scm.com/install/. Achten Sie darauf, dass
C:\Program Files\Git\bin and C:\Program Files\Git\cmdin der PATH-Umgebungsvariable Ihres Systems enthalten sind, damit bash.exe und git.exe von den Build-Prozessen von LiteRT/LiteRT-LM gefunden werden können. - bazelisk: Installieren Sie bazelisk und fügen Sie den Speicherort in die Umgebungsvariable
PATHIhres Systems ein: https://bazel.build/install/bazelisk. - CMake: Installieren Sie CMake Version 4.3.0 oder höher von https://cmake.org/download/ und prüfen Sie, ob CMake im PATH Ihres Systems enthalten ist.
- Python: Prüfen Sie, ob Python 3.11 oder höher installiert ist und ob sich „python.exe“ in Ihrem PATH befindet.
- Windows-Einstellungen: Aktivieren Sie den Entwicklermodus in den Windows-Einstellungen.
LiteRT-Tools und ‑Plug-ins für Intel NPU erstellen
Damit Modelle mit LiteRT auf der Intel NPU ausgeführt werden können, müssen sie mit dem LiteRT Intel OpenVINO-Compiler-Plug-in kompiliert werden. Außerdem muss jedes kompilierte Modell, das auf der Intel NPU ausgeführt werden soll, an das LiteRT Intel OpenVINO-Dispatch-Plug-in delegiert werden.
Der Mechanismus, mit dem LiteRT diese Plug-ins aufruft, wird im Folgenden veranschaulicht:
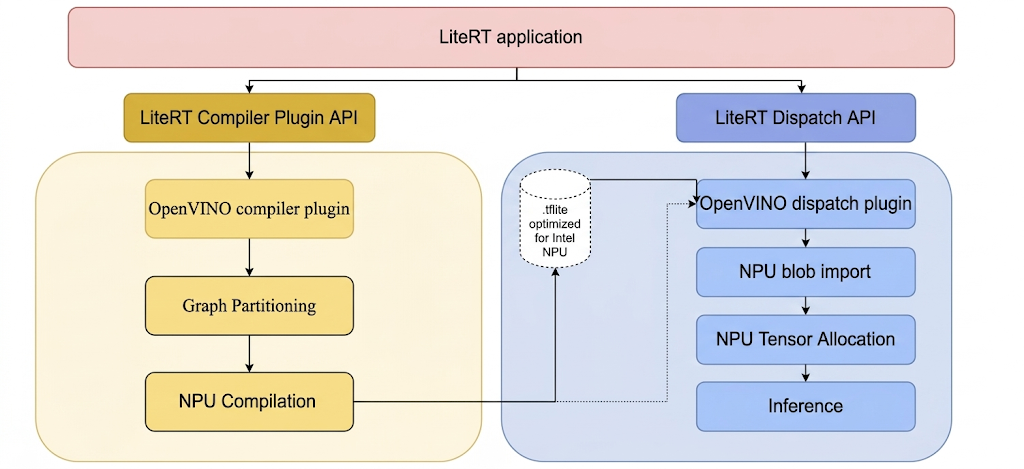
Schritte zum Erstellen von LiteRT-Tools und Intel-Plug-ins.
Bevor Sie ausführbare Dateien oder Bibliotheken aus LiteRT erstellen, erstellen Sie ein lokales Verzeichnis, z. B. C:\bzl. Die Binärdatei für die Build-Ausgabe wird aus diesem Verzeichnis abgerufen. Intel OpenVINO-Dispatch-Plug-in erstellen
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Alternativ können Sie das Dispatch-Plug-in auch aus dem LiteRT-LM-Repository erstellen, indem Sie dem Ziel ein @litert-Präfix hinzufügen. Das gilt auch für alle folgenden Ziele aus dem LiteRT-Repository.
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Intel OpenVINO-Compiler-Plug-in erstellen
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
Build LiteRT Ahead-of-Time (AOT) Compiler Utility Für einige LiteRT-Tools ist eine explizite AOT-Kompilierung von Modellen erforderlich, bevor sie auf der Intel NPU ausgeführt werden können. Build-Anleitung für das LiteRT-AOT-Compiler-Dienstprogramm:
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
LiteRT-Modell-Runner erstellen Mit dem LiteRT-Modell-Runner kann ein Modell auf der Intel NPU ausgeführt werden, entweder ein nicht vorkompiliertes Modell oder ein AOT-kompiliertes Modell. Die Anleitung zum Erstellen des Modell-Runners:
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
LiteRT-Benchmark-Modell-Utility erstellen Mit dem LiteRT-Modell-Benchmark-Tool kann die Leistung der Inferenz eines Modells auf der Intel NPU gemessen werden. Wenn eine Anleitung zum Erstellen des Benchmark-Tools vorhanden ist:
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
LiteRT-Tool zum Prüfen von numerischen Werten erstellen
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
Erweiterte Nutzung: Mit dem angepassten Intel OpenVINO SDK entwickeln
Das LiteRT-Build-System ruft das vorgefertigte Intel OpenVINO SDK automatisch ab, wenn die Compiler- und Dispatch-Plug-ins kompiliert werden.
Wenn für Ihr Projekt eine bestimmte oder benutzerdefinierte Version des Intel OpenVINO SDK erforderlich ist, führen Sie diese zusätzlichen Konfigurationsschritte aus, bevor Sie mit dem Erstellen des Plug-ins beginnen:
- Laden Sie die aktuelle OpenVINO-Release-Binärdatei für Windows von https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html herunter und entpacken Sie sie auf der lokalen Festplatte, z. B.
C:\Intel\intel_openvino. - Achten Sie darauf, dass das einzige untergeordnete Verzeichnis unter diesem Pfad „openvino“ heißt und Unterverzeichnisse wie „runtime“ und „include“ enthält.
- Wechseln Sie in der Konsole (Eingabeaufforderung oder PowerShell) zum Stammverzeichnis des geklonten LiteRT-Repositorys und legen Sie die Variable OPENVINO_NATIVE_DIR fest. Achten Sie darauf, dass kein nachgestelltes
\`), for example:vorhanden ist:\`), for example:set OPENVINO_NATIVE_DIR=C:\Intel\intel_openvino`
AOT-Kompilierung benutzerdefinierter Modelle
In diesem Abschnitt wird die Umgebung vorbereitet und die AOT-Kompilierung von benutzerdefinierten TFLite-, PyTorch- oder JAX-Modellen für LiteRT durchgeführt.
Während der Modellkompilierung für die Intel NPU validiert LiteRT den Modellgraphen anhand der Operatoren, die vom LiteRT Intel OpenVINO-Compiler-Plug-in unterstützt werden. Für Operatoren oder Teilgraphen, die mit dem Compiler-Plug-in kompatibel sind, kompiliert LiteRT jeden solchen Teilgraphen in einen DISPATCH_OP, der anschließend den ursprünglichen Teilgraphen im Diagramm ersetzt. Operatoren, die nicht im unterstützten Opset des Intel OpenVINO-Compilers enthalten sind, bleiben im Diagramm unverändert. Daher kann die AOT-Kompilierung entweder ein vollständig oder teilweise delegiertes Modell ergeben. Hier sehen Sie ein Beispiel für ein vollständig delegiertes AOT-kompiliertes Modell:
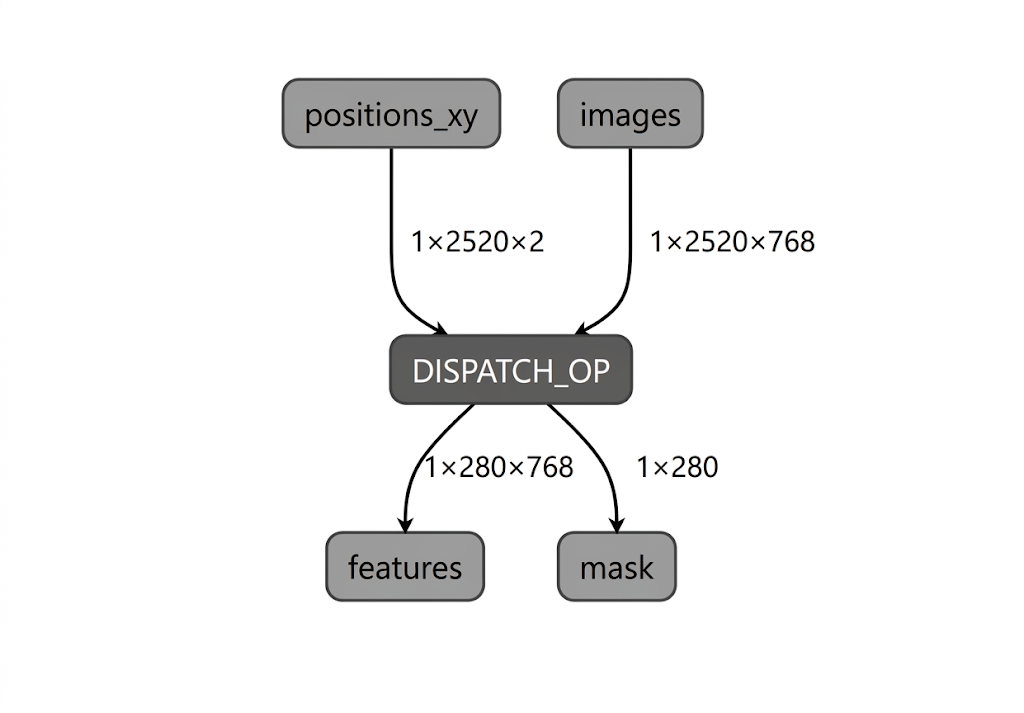
Das LiteRT-Dienstprogramm „apply_plugin_main“ (apply_plugin_main.exe) ist das AOT-Kompilierungsdienstprogramm, das Sie für diesen Zweck verwenden können. Beispiel für die Verwendung des Dienstprogramms auf der Intel-Plattform:
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
Der standardmäßige zugrunde liegende NPU-Compiler, der in der binären Verteilung des Intel OpenVINO SDK enthalten ist, wird für Intel Core Ultra Series 2 und nachfolgende SoCs verwendet. Wenn ein Modell für eine NPU kompiliert wird, die nicht auf der Liste der unterstützten Geräte steht, muss der Compilertyp explizit angegeben werden. Für Intel Core Ultra 2 und höher ist dies jedoch weiterhin optional.
set IE_NPU_COMPILER_TYPE=PLUGIN
JIT- und AOT-Kompilierung in Ihrer Anwendung
Es gibt zwei Möglichkeiten, Modelle in Ihrer eigenen LiteRT-Anwendung zu kompilieren: die bereits vorgestellte AOT-Kompilierung und die Just-in-time-Kompilierung (JIT).
Bei der AOT-Kompilierung wird das Modell offline vor der Bereitstellung kompiliert und kann für die spätere Verwendung gespeichert werden. Dies wird häufig verwendet, wenn die Kompilierung zu ressourcenintensiv ist, um auf dem Gerät ausgeführt zu werden. Dies muss nicht auf demselben Gerät erfolgen, auf dem Sie das Modell bereitstellen. Beispiel für die AOT-Kompilierung in Ihrem Code:
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
So führen Sie die Inferenz mit einem AOT-kompilierten Modell aus:
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
Die Alternative besteht darin, das Modell zur Laufzeit auf dem Gerät zu kompilieren. Es ist flexibler, da nur eine einzige Backend-unabhängige Modelldatei erforderlich ist.
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
Benchmark mit benchmark_model
Das LiteRT-Tool „benchmark_model“ (benchmark_model.exe) wurde speziell für das Benchmarking eines AOT-kompilierten Modells auf der NPU entwickelt und kann verwendet werden, um die Leistung mit dem CPU-Backend (XNNPack) in LiteRT zu vergleichen. Beispielbefehl zum Benchmarking eines AOT-kompilierten Modells auf der Intel NPU:
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
Richtigkeitsprüfung mit npu_numerics_check
Mit dem Tool „npu_numerics_check“ wird die numerische Genauigkeit eines NPU-kompilierten Modells mit einer Baseline (in der Regel das CPU-Backend, XNNPack) verglichen. Dieser Schritt ist entscheidend, um sicherzustellen, dass die Delegation an die NPU keine inakzeptablen numerischen Abweichungen verursacht, die sich auf die Modellqualität auswirken könnten.
Numerische Prüfung ausführen Für das Tool ist das AOT-kompilierte Modell erforderlich. Es vergleicht die Ausgaben mit dem ursprünglichen, nicht delegierten Modell, das auf der CPU ausgeführt wird.
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
Nächste Schritte
- Beginnen Sie mit dem einheitlichen NPU-Leitfaden: NPU-Beschleunigung mit LiteRT
- Folgen Sie der Anleitung zur Konvertierung und Bereitstellung und wählen Sie bei Bedarf Qualcomm aus.
- Informationen zu LLMs finden Sie unter LLMs auf NPU mit LiteRT-LM ausführen.