
LiteRT は、AOT コンパイルとデバイス上コンパイルの両方で CompiledModel API を介して Intel OpenVino
をサポートしています。
Python API
開発環境をセットアップする
Linux(x86_64):
- Ubuntu 22.04 または 24.04 LTS
- Python 3.10 以降 - python.org
またはディストリビューション(
sudo apt install python3 python3-venv)からインストールします。 - Intel NPU ドライバ v1.32.1 - Linux NPU のセットアップをご覧ください。
Windows(x86_64):
- Windows 10 または 11
- Python 3.10 以降 - python.orgからインストールします。
- Intel NPU ドライバ 32.0.100.4724+ - Windows NPU のセットアップをご覧ください。
ソースからビルドするには、 Bazelisk を使用した Bazel 7.4.1 以降または hermetic Docker ビルド も必要です。
サポートされている SoC
| プラットフォーム | NPU | コードネーム | OS |
|---|---|---|---|
| Intel Core Ultra シリーズ 2 | NPU4000 | Lunar Lake(LNL) | Linux、Windows |
| Intel Core Ultra シリーズ 3 | NPU5010 | Panther Lake(PTL) | Linux、Windows |
クイック スタート
1. NPU ドライバをインストールする
Linux NPU のセットアップまたは Windows NPU のセットアップをご覧ください。AOT のみが必要な場合はスキップしてください。
NPU ドライバは、NPU ハードウェアでモデルを実行 するシステムでのみ必要です。純粋な AOT ビルド システムではスキップできます。
注:
ai-edge-litert-sdk-intel-nightlyは、PEP 440 バージョン(openvino==2026.2.0.dev20260506など)で一致する OpenVINO nightly wheel を固定するため、 pip で--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightlyを指定して検索する必要があります。Linux で、ディストリビューションの自動検出で誤ったアーカイブが選択された場合は、pip installの前にLITERT_OV_OS_ID=ubuntu22またはubuntu24を設定します。
2. Python 仮想環境を作成する
nightly openvino wheel をシステム全体の OpenVINO インストールから分離しておくことをおすすめします。
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
3. pip パッケージをインストールする
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
--extra-index-url を使用すると、pip は PyPI のパッケージとともに OpenVINO のインデックスから固定された openvino nightly wheel を解決できます。
4. インストールを検証する
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
出力で確認する内容:
SDK libsにlibopenvino_intel_npu_compiler.so(Linux)またはopenvino_intel_npu_compiler.dll(Windows)が表示される - AOT に必要です。Available devicesにNPUが含まれている - NPU ドライバがインストールされており、OpenVINO がデバイスと通信できることを確認します。NPUは、AOT 専用システム(ドライバがインストールされていない場合)と Intel NPU ハードウェアのないシステムには存在しません。
5. AOT コンパイル(省略可)
- 特定の Intel NPU ターゲット(PTL または LNL)の
.tfliteを事前コンパイルして、ランタイムがコンパイラ プラグイン ステップをスキップできるようにします。 - 物理 NPU または NPU ドライバは必要ありません 。
ai-edge-litert-nightlyとai-edge-litert-sdk-intel-nightlyのみが必要です。 - クロスコンパイルがサポートされています。Linux または Windows ホストでコンパイルし、結果の
.tfliteをいずれかの OS のターゲットに出荷して、そこで実行します。
出力ファイルの名前は <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite です。
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
6. NPU 推論を実行する
LiteRT は、Intel NPU で次の 2 つの推論パスをサポートしています。
- JIT - 未加工の
.tfliteを読み込みます。コンパイラ プラグインは、CompiledModel.from_file()時に NPU のサポート対象のオペレーションをパーティショニングしてコンパイルします。初回実行時のレイテンシが追加されます(モデルによって異なります)。 - AOT コンパイル済み - ステップ 4 で生成された
<model>_IntelOpenVINO_<SoC>_apply_plugin.tfliteを読み込みます。読み込み時にパーティショニングとコンパイルのステップがスキップされます。
このスニペットは両方で機能します。
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
JIT が実際に実行されたことを確認する
JIT が成功すると、ログに次の内容が含まれます(ファイル拡張子は Linux では .so、Windows では .dll です)。
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
これらの行が存在しないが、Fully accelerated: True が報告されている場合、モデルは NPU ではなく XNNPACK CPU フォールバックで実行されました。JIT のトラブルシューティングの行をご覧ください。
7. ベンチマーク
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
共通フラグ:
| フラグ | デフォルト | 説明 |
|---|---|---|
--model PATH
|
— | .tflite モデルのパス(必須)。 |
--signature KEY |
第 1 | 実行する署名鍵。 |
--use_cpu / --no_cpu
|
オン | CPU アクセラレータ / CPU フォールバックを切り替えます。 |
--use_gpu |
オフ | GPU アクセラレータを有効にします。 |
--use_npu |
オフ | Intel NPU アクセラレータを有効にします。 |
--require_full_delegation
|
オフ | モデルが選択したアクセラレータに完全にオフロードされていない場合は失敗します。 |
--num_runs N
|
50 | 時間計測された推論の反復回数。 |
--warmup_runs N
|
5 | 測定前の時間計測なしのウォームアップ反復。 |
--num_threads N |
1 | CPU スレッド数。 |
--result_json PATH
|
— | JSON 形式の概要(レイテンシ統計、スループット、アクセラレータ リスト)を書き込みます。 |
--verbose |
オフ | 追加のランタイム ロギング。 |
詳細 / オーバーライド フラグ - カスタムビルドを指定する場合にのみ必要です: --dispatch_library_path、--compiler_plugin_path、--runtime_path。
混合ベンダーの wheel: JIT を Intel OV に固定する
注: 明示的なパスを指定せずに
Environment.create()が呼び出されると、ai_edge_litert/vendors/のベンダーがアルファベット順に自動検出され、最初に見つかったベンダーが登録されます。混合ベンダーのインストールでは、Intel OV ではない可能性があります。正しい選択を強制するには、Intel OV ディレクトリを明示的に渡します。
- pip wheel には、登録されているすべてのベンダー(
intel_openvino/、google_tensor/、mediatek/、qualcomm/、samsung/)のコンパイラ プラグインが付属しています。 - Intel OV パスを強制するには(複数のベンダー SDK がインストールされている場合におすすめ)、Intel OV ディレクトリを手動で渡します。
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
ランタイムは、指定されたディレクトリにあるすべての共有ライブラリを読み込むため、vendors/intel_openvino/compiler/ を指定すると、Intel プラグインのみが読み込まれます。兄弟ディレクトリにある Google Tensor / MediaTek / Qualcomm / Samsung プラグインは使用されません。
CLI の場合、同等のフラグは次のとおりです。
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
NPU の実行を確認する
モデルが実際に NPU で実行されたことを確認するには、両方 のシグナルを確認します。
- ログに
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}が含まれている - Intel ディスパッチ ライブラリが 読み込まれました(.soon Linux、.dllon Windows)。 model.is_fully_accelerated()がTrueを返す - すべてのオペレーションが選択したアクセラレータにオフロードされました。
is_fully_accelerated() だけでは十分ではありません 。ディスパッチ ライブラリが読み込まれなかった場合、オペレーションは NPU ではなく XNNPACK/CPU に完全にオフロードされました。
Linux NPU のセットアップ
注: AOT のみが必要な場合は、このセクションをスキップしてください。物理 NPU は必要ありません。
情報: NPU ドライバ v1.32.1 (OpenVINO 2026.1 とペア)を使用します。古いドライバは
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATUREで失敗します。
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
次に、クイック スタートからインストールと検証のスニペットを実行します。
Windows NPU のセットアップ
注: AOT のみが必要な場合は、このセクションをスキップしてください。物理 NPU は必要ありません。
- Intel ダウンロード センターから Intel NPU ドライバ(32.0.100.4724+)をインストールします。
- デバイス マネージャーに [Neural processors] の下に NPU デバイスが表示されることを確認します(ドライバに応じて
Intel(R) AI BoostまたはIntel(R) NPUとして表示されます)。 - クイック スタートからインストールと検証のスニペットを実行します。
pipをpython -m pipに置き換えます。
情報:
import ai_edge_litertはos.add_dll_directory()を使用して DLL ディレクトリを自動登録するため、Python スクリプトでPATHを設定する必要はありません。Python 以外のコンシューマーの場合は、setupvars.batを実行するか、<openvino>/libsをPATHの先頭に追加します。
ソースからビルドする
プロキシの背後にある場合ビルド スクリプトを実行する前に
http_proxy/https_proxy/no_proxyをエクスポートします。これらは Docker とコンテナに転送されます。
Linux(Docker、hermetic):
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
Windows(PowerShell、PATH の Bazel):
.\ci\build_pip_package_with_bazel_windows.ps1
出力は dist/ に保存されます。
ai_edge_litert-*.whl- ランタイム wheel。ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz- ベンダー sdist。- Intel sdist は約 5 KB です。NPU コンパイラの
.so/.dllはpip install時に取得されるため、同じ sdist が Linux と Windows で動作します。
単体テスト
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
トラブルシューティング
| 問題 | 修正 |
|---|---|
AOT が失敗する: Device with "NPU" name is not registered |
NPU コンパイラが取得されませんでした。ai_edge_litert_sdk_intel.path_to_sdk_libs() に libopenvino_intel_npu_compiler.so / .dll が表示されることを確認します。空の場合は、ネットワーク アクセスを使用して再インストールするか、LITERT_OV_OS_ID=ubuntu22/ubuntu24 を設定します。 |
JIT が NPU ではなく CPU で実行される(Partitioned subgraph ログがない、Loaded plugin ログがない、Fully accelerated: True が出力される) |
コンパイラ プラグインが検出されませんでした。ov.get_compiler_plugin_dir() が ai_edge_litert/vendors/intel_openvino/compiler/ のパスを返すことを確認します。複数のベンダー SDK がインストールされている場合は、compiler_plugin_path=ov.get_compiler_plugin_dir() を Environment.create() に明示的に渡します(または litert-benchmark に --compiler_plugin_path=... を渡します)。 |
JIT が失敗する: Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so(Linux)/ openvino_intel_npu_compiler.dll(Windows) |
SDK sdist は、最初の import ai_edge_litert_sdk_intel で NPU コンパイラを openvino/libs/ にコピーします。コピーがスキップされた場合(読み取り専用 FS、openvino がない)、openvino のインストール後に ai-edge-litert-sdk-intel を再インストールし、新しいプロセスで import ai_edge_litert を実行します。 |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE |
NPU ドライバを v1.32.1(Linux)にアップグレードします。 |
/dev/accel/accel0 が見つかりません |
sudo dmesg | grep -i vpu でドライバをデバッグします。インストール後に再起動します。 |
| NPU の権限が拒否されました | sudo gpasswd -a ${USER} render && newgrp render。 |
| Windows: デバイス マネージャーに NPU が表示されない | Intel ダウンロード センターから NPU ドライバ 32.0.100.4724+ をインストールします。 |
Windows: Failed to initialize Dispatch API / DLL がない |
import ai_edge_litert が最初に実行されることを確認します(DLL ディレクトリが自動登録されます)。Python 以外の呼び出し元の場合は、setupvars.bat を実行するか、<openvino>/libs を PATH の先頭に追加します。 |
Windows ビルド: LNK2001 fixed_address_empty_string、C2491 dllimport、Python 3.12+ fails |
Protobuf ABI / Python バージョンの制約 - ci/build_pip_package_with_bazel_windows.ps1 をご覧ください。Windows ビルドには Python 3.11 が必要です。 |
制限事項
OpenVINO ディスパッチ パスでは、NPU デバイスのみがサポートされています。CPU 推論には、HardwareAccelerator.CPU のみを使用します(XNNPACK)。
C++ API
前提条件とビルドの設定
ビルドの前提条件:
- Visual Studio 2022 以降(C++ 開発ツールがインストールされている必要があります)。
- git: https://git-scm.com/install/ から git をインストールします。LiteRT/LiteRT-LM ビルドプロセスで bash.exe と git.exe を検出できるように、
C:\Program Files\Git\bin and C:\Program Files\Git\cmdがシステムの PATH 環境変数に含まれていることを確認します。 - bazelisk: bazelisk をインストールし、その場所をシステムの
PATH環境変数に含めます: https://bazel.build/install/bazelisk。 - Cmake: https://cmake.org/download/ から Cmake バージョン 4.3.0 以降をインストールし、Cmake がシステムの PATH に含まれていることを確認します。
- Python: Python 3.11 以降がインストールされており、python.exe が PATH に含まれていることを確認します。
- Windows の設定: Windows の設定でデベロッパー モードを有効にします。
Intel NPU 用の LiteRT ツールとプラグインをビルドする
LiteRT で Intel NPU 上でモデルを実行するには、LiteRT Intel OpenVINO コンパイラ プラグインを使用してコンパイルする必要があります。また、Intel NPU で実行するコンパイル済みモデルは、LiteRT Intel OpenVINO ディスパッチ プラグインに委任する必要があります。
LiteRT がこれらのプラグインを呼び出すメカニズムを次に示します。
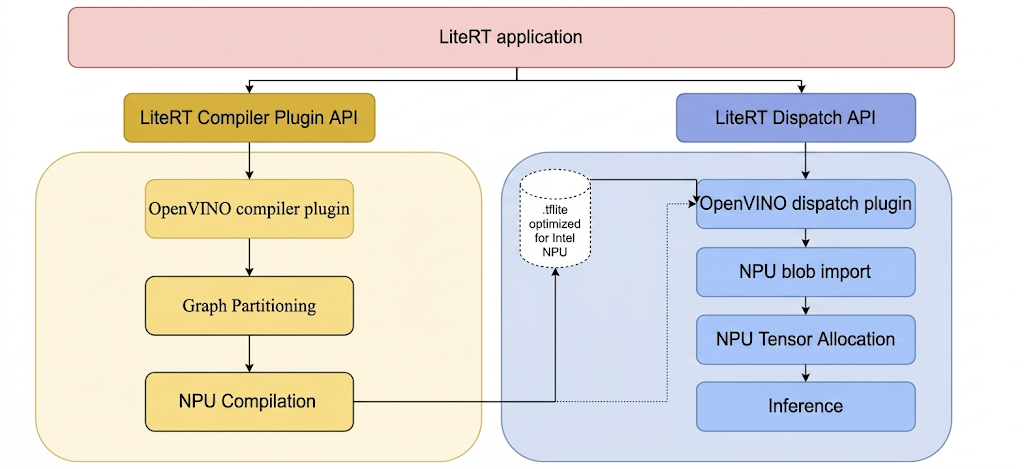
LiteRT ツールと Intel プラグインをビルドする手順。
LiteRT から実行可能ファイルまたはライブラリをビルドする前に、ローカル ディレクトリ(C:\bzl など)を作成します。ビルド出力バイナリはこのディレクトリから収集されます。Intel OpenVINO ディスパッチ プラグインをビルドする
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
または、ターゲットに @litert 接頭辞を追加して、LiteRT-LM リポジトリからディスパッチ プラグインをビルドすることもできます。これは、LiteRT リポジトリの以降のすべてのターゲットで同様です。
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Intel OpenVINO コンパイラ プラグインをビルドする
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
LiteRT 事前(AOT)コンパイラ ユーティリティをビルドする 一部の LiteRT ツールでは、Intel NPU で実行する前にモデルの明示的な AOT コンパイルが必要です。LiteRT AOT コンパイラ ユーティリティのビルド手順:
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
LiteRT モデル ランナーをビルドする LiteRT モデル ランナーを使用すると、Intel NPU でモデル(事前コンパイルされていないモデルまたは AOT コンパイル済みモデル)を実行できます。モデル ランナーをビルドする手順:
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
LiteRT ベンチマーク モデル ユーティリティをビルドする LiteRT モデル ベンチマーク ツールを使用すると、Intel NPU 上のモデルの推論のパフォーマンスをベンチマークできます。ベンチマーク ツールをビルドする手順:
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
LiteRT 数値チェック ユーティリティをビルドする
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
高度な使用方法: カスタマイズされた Intel OpenVINO SDK でビルドする
LiteRT ビルドシステムは、コンパイラとディスパッチ プラグインをコンパイルするときに、事前ビルド済みの Intel OpenVINO SDK を自動的に取得します。
プロジェクトで特定のバージョンまたはカスタマイズされたバージョンの Intel OpenVINO SDK が必要な場合は、プラグインのビルドを開始する前に、次の追加構成手順を完了します。
- https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html から Windows 用の最新の OpenVINO リリース バイナリをダウンロードし、ローカル ディスク(
C:\Intel\intel_openvinoなど)に抽出します。 - このパスの下にある子ディレクトリが「openvino」という名前で、その下に「runtime」や「include」などのサブディレクトリが含まれていることを確認します。
- コンソール
(コマンド プロンプトまたは PowerShell)で、クローン作成した LiteRT リポジトリのルート ディレクトリに移動し、OPENVINO_NATIVE_DIR 変数を設定します
(末尾に
\`), for example:set OPENVINO_NATIVE_DIR=C:\Intel\intel_openvino`
カスタムモデルの AOT コンパイル
このセクションでは、環境を準備し、LiteRT 用のカスタム TFLite、PyTorch、JAX モデルの AOT コンパイルを実行します。
Intel NPU のモデル コンパイル プロセス中に、LiteRT はモデルグラフを LiteRT Intel OpenVINO コンパイラ プラグインでサポートされているオペレーションと照らして検証します。コンパイラ プラグインと互換性のあるオペレーションまたはサブグラフの場合、LiteRT はそのようなサブグラフを DISPATCH_OP にコンパイルし、グラフ内の元のサブグラフを置き換えます。Intel OpenVINO コンパイラでサポートされているオペレーション セットに含まれていないオペレーションは、グラフ内で変更されません。そのため、AOT コンパイルでは、完全に委任されたモデルまたは部分的に委任されたモデルが生成される可能性があります。次に、完全に委任された AOT コンパイル済みモデルの例を示します。
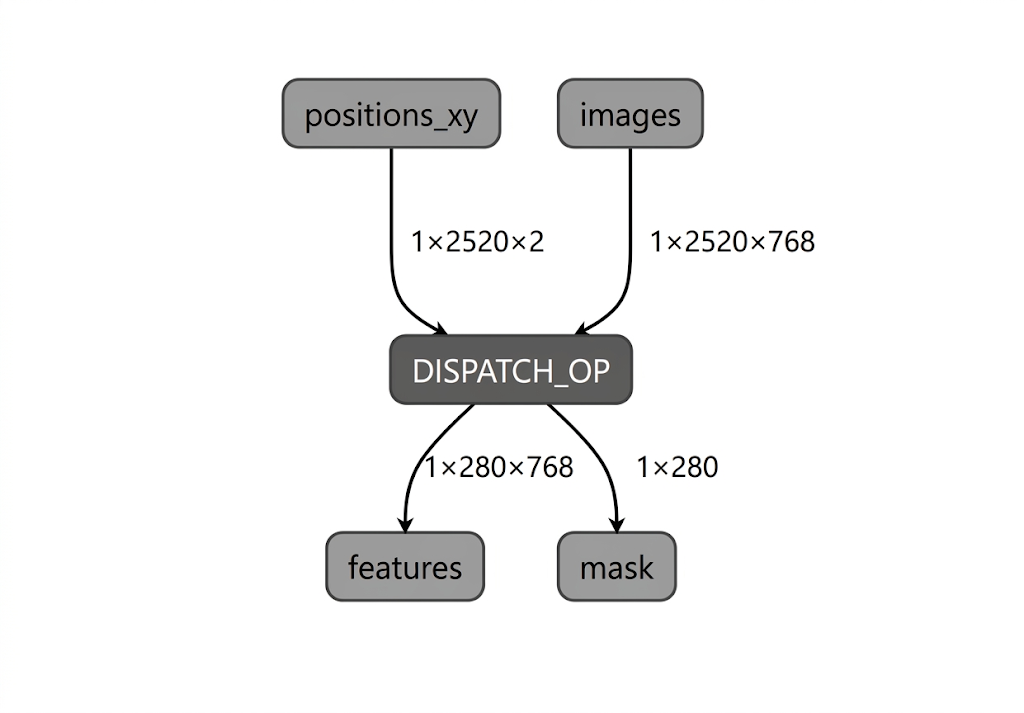
LiteRT apply_plugin_main ユーティリティ(apply_plugin_main.exe)は、この目的で使用できる AOT コンパイル ユーティリティです。Intel プラットフォームでのユーティリティの使用例:
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
Intel OpenVINO SDK のバイナリ ディストリビューションに含まれているデフォルトの基盤となる NPU コンパイラは、Intel Core Ultra シリーズ 2 以降の SoC で使用されます。サポートされているリストにない NPU 用にモデルをコンパイルする場合は、コンパイラのタイプを明示的に指定する必要があります(Intel Core Ultra 2 以降では省略可能です)。
set IE_NPU_COMPILER_TYPE=PLUGIN
アプリケーションでの JIT コンパイルと AOT コンパイル
独自の LiteRT アプリケーションでモデルをコンパイルするには、2 つの方法があります。すでに説明した AOT コンパイルとジャストインタイム(JIT)コンパイルです。
AOT コンパイルでは、モードはデプロイ前にオフラインでコンパイルされ、後で使用するために保存できます。これは、コンパイルがリソースを大量に消費するため、デバイス上で実行できない場合によく使用されます。モデルをデプロイするデバイスと同じデバイスで行う必要はありません。コードでの AOT コンパイルの例:
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
AOT コンパイル済みモデルで推論を行う方法:
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
もう 1 つの方法は、デバイス上のランタイムでモデルを JIT コンパイルすることです。 より柔軟性があり、バックエンドに依存しない単一のモデルファイルのみが必要です。
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
benchmark_model でベンチマークを行う
LiteRT benchmark_model ユーティリティ(benchmark_model.exe)は、NPU 上の AOT コンパイル済みモデルのベンチマーク用に特別に設計されており、LiteRT の CPU バックエンド(XNNPack)とのパフォーマンスを比較するために使用できます。 Intel NPU 上の AOT コンパイル済みモデルをベンチマークするコマンドの例:
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
npu_numerics_check で精度を確認する
npu_numerics_check ユーティリティは、NPU コンパイル済みモデルの数値精度をベースライン(通常は CPU バックエンド、XNNPack)と照らして検証するために使用されます。 このステップは、NPU への委任によって、モデルの品質に影響する可能性のある許容できない数値偏差が発生しないようにするために重要です。
数値チェックを実行する このユーティリティには、AOT コンパイル済みモデルが必要で、その出力を CPU で実行される元の委任されていないモデルと比較します。
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
次のステップ
- 統合 NPU ガイド(LiteRT による NPU アクセラレーション)から始めます。
- 手順に沿って変換とデプロイを行い、該当する場合は Qualcomm を選択します。
- LLM については、LiteRT-LM を使用して NPU で LLM を実行するをご覧ください。