
LiteRT obsługuje Intel OpenVino za pomocą interfejsu CompiledModel API zarówno w przypadku kompilacji AOT, jak i kompilacji na urządzeniu.
Python API
Konfigurowanie środowiska programistycznego
Linux (x86_64):
- Ubuntu 22.04 lub 24.04 LTS
- Python 3.10 lub nowszy – zainstaluj go z python.org lub z dystrybucji (
sudo apt install python3 python3-venv). - Sterownik NPU firmy Intel v1.32.1 – zobacz Konfiguracja NPU w systemie Linux
Windows (x86_64):
- Windows 10 lub 11
- Python 3.10 lub nowszy – zainstaluj z python.org
- Sterownik NPU Intel 32.0.100.4724+ – zobacz konfigurację NPU w systemie Windows
W przypadku kompilacji ze źródeł wymagana jest też usługa Bazel w wersji 7.4.1 lub nowszej z użyciem Bazeliska lub hermetyczna kompilacja Dockera.
Obsługiwane układy SoC
| Platforma | NPU | Kryptonim | System operacyjny |
|---|---|---|---|
| Intel Core Ultra Series 2 | NPU4000 | Lunar Lake (LNL) | Linux, Windows |
| Intel Core Ultra Series 3 | NPU5010 | Panther Lake (PTL) | Linux, Windows |
Szybki start
1. Instalowanie sterowników NPU
Zobacz Konfiguracja NPU w systemie Linux lub Konfiguracja NPU w systemie Windows. Pomiń ten krok, jeśli potrzebujesz tylko kompilacji AOT.
Sterownik NPU jest potrzebny tylko w systemach, które wykonują model na sprzęcie NPU. Systemy kompilacji AOT mogą pominąć ten krok.
Uwaga:
ai-edge-litert-sdk-intel-nightlyprzypina pasujące koło OpenVINO nightly według wersji PEP 440 (np.openvino==2026.2.0.dev20260506), więc pip potrzebuje--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly, aby je znaleźć. Jeśli na Linuxie automatyczne wykrywanie dystrybucji wybierze nieprawidłowe archiwum, przedpip installustawLITERT_OV_OS_ID=ubuntu22lububuntu24.
2. Tworzenie środowiska wirtualnego Pythona
Zalecamy, aby plik openvino był odizolowany od instalacji OpenVINO w całym systemie.
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
3. Instalowanie pakietu pip
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
Symbol --extra-index-url umożliwia narzędziu pip rozpoznawanie przypiętego openvino nightly wheel
z indeksu OpenVINO wraz z pakietami w PyPI.
4. Weryfikacja instalacji
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
Co sprawdzić w danych wyjściowych:
SDK libslistslibopenvino_intel_npu_compiler.so(Linux) lubopenvino_intel_npu_compiler.dll(Windows) – wymagane w przypadku kompilacji AOT.Available deviceszawieraNPU– potwierdza, że sterownik NPU jest zainstalowany i OpenVINO może komunikować się z urządzeniem.NPUnie będzie dostępny w systemach, w których działa tylko kompilacja AOT (bez zainstalowanego sterownika), ani w systemach bez sprzętu Intel NPU.
5. Kompilacja AOT (opcjonalnie)
- Wstępnie kompiluje
.tflitedla konkretnego procesora NPU firmy Intel (PTL lub LNL), aby środowisko wykonawcze pominęło krok wtyczki kompilatora. - Nie wymaga fizycznego procesora NPU ani sterownika NPU – wystarczą tylko
ai-edge-litert-nightlyiai-edge-litert-sdk-intel-nightly. - Obsługiwana jest kompilacja skrośna: kompiluj na dowolnym hoście z systemem Linux lub Windows, przesyłaj wynikowy plik
.tflitena urządzenie docelowe z dowolnym systemem operacyjnym i uruchamiaj go tam.
Pliki wyjściowe mają nazwy <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite.
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
6. Uruchom wnioskowanie NPU
LiteRT obsługuje 2 ścieżki wnioskowania na procesorze NPU firmy Intel:
- JIT – wczytuje surowy plik
.tflite; wtyczka kompilatora dzieli i kompiluje obsługiwane operacje dla NPU w czasieCompiledModel.from_file(). Dodaje opóźnienie pierwszego uruchomienia (różni się w zależności od modelu). - Skompilowany AOT – wczytaj
<model>_IntelOpenVINO_<SoC>_apply_plugin.tfliteutworzony w kroku 4. Pomija krok partycjonowania i kompilacji w czasie wczytywania.
Ten fragment kodu działa w przypadku obu tych przypadków:
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
Sprawdź, czy kompilacja JIT została uruchomiona
Jeśli kompilacja JIT się powiedzie, dziennik będzie zawierać (rozszerzenie pliku to .so w systemie Linux i .dll w systemie Windows):
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
Jeśli tych wierszy nie ma, ale nadal zgłaszana jest wartość Fully accelerated: True, model został uruchomiony na procesorze z XNNPACK, a nie na NPU. Zobacz wiersz dotyczący rozwiązywania problemów z JIT.
7. Test porównawczy
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
Typowe flagi:
| Flaga | Domyślny | Opis |
|---|---|---|
--model PATH
|
– | Ścieżka do modelu .tflite (wymagana). |
--signature KEY |
pierwszy | Klucz podpisu do uruchomienia. |
--use_cpu/--no_cpu
|
włączono | Przełącz akcelerator procesora / rezerwowy procesor. |
--use_gpu |
wył. | Włącz akcelerator GPU. |
--use_npu |
wył. | Włącz akcelerator NPU firmy Intel. |
--require_full_delegation
|
wył. | Niepowodzenie, jeśli model nie jest w pełni przeniesiony na wybrany akcelerator. |
--num_runs N
|
50 | Liczba iteracji wnioskowania z pomiarem czasu. |
--warmup_runs N
|
5 | Nieograniczone czasowo iteracje rozgrzewki przed pomiarem. |
--num_threads N |
1 | Liczba wątków procesora. |
--result_json PATH
|
– | Napisz podsumowanie w formacie JSON (statystyki opóźnienia, przepustowość, lista akceleratorów). |
--verbose |
wył. | Dodatkowe logowanie w środowisku wykonawczym. |
Flagi zaawansowane / zastępujące – potrzebne tylko do wskazywania niestandardowych kompilacji:--dispatch_library_path, --compiler_plugin_path, --runtime_path.
Koła różnych dostawców: przypinanie JIT do Intel OV
Uwaga: jeśli funkcja
Environment.create()zostanie wywołana bez podania ścieżek, automatycznie wykryje dostawców w folderzeai_edge_litert/vendors/w porządku alfabetycznym i zarejestruje pierwszego znalezionego dostawcę. W przypadku instalacji z urządzeniami różnych producentów może to nie być Intel OV – przekaż katalogi Intel OV wprost, aby wymusić prawidłowy wybór.
- Pakiet pip zawiera wtyczki kompilatora dla każdego zarejestrowanego dostawcy (
intel_openvino/,google_tensor/,mediatek/,qualcomm/,samsung/). - Aby wymusić ścieżkę Intel OV (zalecane, gdy zainstalowanych jest wiele pakietów SDK różnych dostawców), ręcznie przekaż katalogi Intel OV:
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
Środowisko wykonawcze wczytuje każdą bibliotekę współdzieloną, którą znajdzie w danym katalogu, więc wskazanie katalogu vendors/intel_openvino/compiler/ powoduje wczytanie tylko wtyczki Intel. Wtyczki Google Tensor, MediaTek, Qualcomm i Samsung w katalogach równorzędnych nigdy nie są używane.
W przypadku interfejsu CLI odpowiednie flagi to:
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
Weryfikacja wykonania na NPU
Aby sprawdzić, czy model został uruchomiony na NPU, poszukaj obu sygnałów:
- Dziennik zawiera
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}– biblioteka wysyłania Intel została załadowana (.sow systemie Linux,.dllw systemie Windows). model.is_fully_accelerated()zwracaTrue– wszystkie operacje zostały przeniesione na wybrany akcelerator.
Sam znak is_fully_accelerated() nie wystarczy: jeśli biblioteka wysyłania nigdy nie została załadowana, operacje były w pełni przenoszone na XNNPACK/CPU, a nie na NPU.
Konfiguracja NPU w systemie Linux
Uwaga: pomiń tę sekcję, jeśli potrzebujesz tylko AOT – fizyczny procesor NPU nie jest wymagany.
Informacje: użyj sterownika NPU v1.32.1 (w połączeniu z OpenVINO 2026.1). Starsze sterowniki nie działają z błędem
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE.
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
Następnie uruchom fragment kodu instalacji i weryfikacji z Szybkiego startu.
Konfiguracja NPU w systemie Windows
Uwaga: pomiń tę sekcję, jeśli potrzebujesz tylko AOT – fizyczny procesor NPU nie jest wymagany.
- Zainstaluj sterownik NPU firmy Intel (32.0.100.4724+) z Centrum pobierania Intel.
- Sprawdź, czy w Menedżerze urządzeń w sekcji Procesory neuronowe znajduje się urządzenie NPU (wyświetlane jako
Intel(R) AI BoostlubIntel(R) NPUw zależności od sterownika). - Uruchom fragment kodu instalacji i weryfikacji z Szybkiego startu, zastępując
pipciągiempython -m pip.
Informacje:
import ai_edge_litertautomatycznie rejestruje katalogi DLL za pomocąos.add_dll_directory(), więc skrypty Pythona nie wymagająPATHkonfiguracji. W przypadku użytkowników niekorzystających z Pythona uruchomsetupvars.batlub dodaj<openvino>/libsprzedPATH.
Kompilacja ze źródła
Używasz serwera proxy? Wyeksportuj
http_proxy/https_proxy/no_proxyprzed uruchomieniem skryptów kompilacji – przekazują one te informacje do Dockera i kontenera.
Linux (Docker, hermetyczny):
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
Windows (PowerShell, Bazel w PATH):
.\ci\build_pip_package_with_bazel_windows.ps1
Dane wyjściowe trafiają do dist/:
ai_edge_litert-*.whl– koło środowiska wykonawczego.ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz– dostawca sdists.- Dystrybucja źródłowa Intela ma około 5 KB. Kompilator NPU
.so/.dlljest pobierany w czasiepip install, więc ta sama dystrybucja źródłowa działa w systemach Linux i Windows.
Testy jednostkowe
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
Rozwiązywanie problemów
| Problem | Napraw |
|---|---|
Błędy AOT: Device with "NPU" name is not registered |
Nie udało się pobrać kompilatora NPU. Sprawdź ai_edge_litert_sdk_intel.path_to_sdk_libs()listylibopenvino_intel_npu_compiler.so / .dll. Jeśli jest pusta, zainstaluj ją ponownie z dostępem do sieci lub ustaw LITERT_OV_OS_ID=ubuntu22/ubuntu24. |
JIT działa na procesorze zamiast na NPU (brak logu Partitioned subgraph, brak logu Loaded plugin, log Fully accelerated: True nadal drukowany) |
Nie wykryto wtyczki kompilatora. Sprawdź, czy ov.get_compiler_plugin_dir() zwraca ścieżkę w ai_edge_litert/vendors/intel_openvino/compiler/. Jeśli zainstalowanych jest kilka pakietów SDK dostawców, przekaż compiler_plugin_path=ov.get_compiler_plugin_dir() do Environment.create() (lub --compiler_plugin_path=... do litert-benchmark) w sposób jawny. |
Błąd JIT: Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so (Linux) / openvino_intel_npu_compiler.dll (Windows) |
Pakiet SDK sdist kopiuje kompilator NPU do openvino/libs/ przy pierwszym import ai_edge_litert_sdk_intel. Jeśli kopiowanie zostało pominięte (system plików tylko do odczytu, brak openvino), po zainstalowaniu openvino ponownie zainstaluj ai-edge-litert-sdk-intel, a następnie import ai_edge_litert w nowym procesie. |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE |
Uaktualnij sterownik NPU do wersji 1.32.1 (Linux). |
Nie udało się znaleźć zasobu /dev/accel/accel0 |
sudo dmesg | grep -i vpu, aby debugować sterownik; po instalacji uruchom ponownie komputer. |
| Odmowa dostępu do NPU | sudo gpasswd -a ${USER} render && newgrp render. |
| Windows: procesor NPU nie jest widoczny w Menedżerze urządzeń | Zainstaluj sterownik NPU w wersji 32.0.100.4724 lub nowszej z Centrum pobierania Intel. |
Windows: Failed to initialize Dispatch API / brakujące biblioteki DLL |
Upewnij się, że najpierw uruchomisz import ai_edge_litert (automatycznie rejestruje katalogi DLL); w przypadku wywołań spoza Pythona uruchom setupvars.bat lub dodaj <openvino>/libs przed PATH. |
Wersja Windows: LNK2001 fixed_address_empty_string, C2491 dllimport, Python 3.12+ fails |
Ograniczenie wersji Protobuf ABI / Python – patrz ci/build_pip_package_with_bazel_windows.ps1; kompilacje w systemie Windows wymagają Pythona 3.11. |
Ograniczenia
Tylko urządzenie NPU jest obsługiwane na ścieżce wysyłania OpenVINO. W przypadku wnioskowania na procesorze używaj tylko HardwareAccelerator.CPU (XNNPACK).
C++ API
Wymagania wstępne i konfiguracja kompilacji
Wymagania wstępne:
- Visual Studio 2022 lub nowszy (musi mieć zainstalowane narzędzia do programowania w C++).
- git: zainstaluj git z https://git-scm.com/install/. Upewnij się, że
C:\Program Files\Git\bin and C:\Program Files\Git\cmdsą uwzględnione w zmiennej środowiskowej PATH systemu, aby procesy kompilacji LiteRT/LiteRT-LM mogły znaleźć pliki bash.exe i git.exe. - bazelisk: zainstaluj bazelisk i dodaj jego lokalizację do zmiennej środowiskowej
PATHw systemie: https://bazel.build/install/bazelisk. - Cmake: zainstaluj Cmake w wersji 4.3.0 lub nowszej ze strony https://cmake.org/download/ i upewnij się, że Cmake jest uwzględniony w ścieżce PATH systemu.
- Python: sprawdź, czy masz zainstalowaną wersję Pythona 3.11 lub nowszą, a plik python.exe znajduje się w zmiennej PATH.
- Ustawienia systemu Windows: włącz tryb programisty w Ustawieniach systemu Windows.
Tworzenie narzędzi i wtyczek LiteRT dla procesora NPU firmy Intel
Aby uruchamiać modele na procesorze NPU firmy Intel za pomocą LiteRT, należy je skompilować za pomocą wtyczki kompilatora LiteRT Intel OpenVINO. Ponadto każdy skompilowany model przeznaczony do wykonania na procesorze NPU firmy Intel musi być przekazany do wtyczki wysyłającej LiteRT Intel OpenVINO.
Mechanizm, za pomocą którego LiteRT wywołuje te wtyczki, jest przedstawiony poniżej:
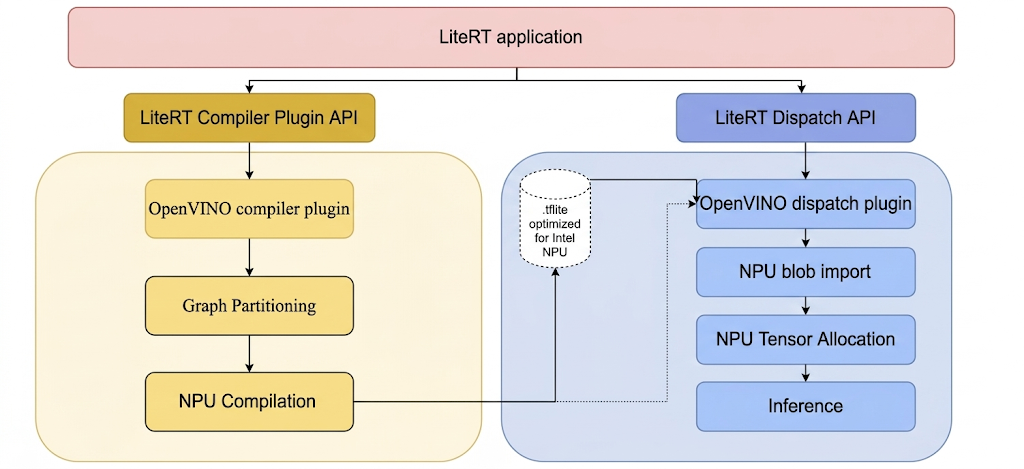
Instrukcje tworzenia narzędzi LiteRT i wtyczek Intel.
Zanim utworzysz z LiteRT jakikolwiek plik wykonywalny lub bibliotekę, utwórz lokalny katalog, np. C:\bzl. Binarny plik wyjściowy kompilacji zostanie pobrany z tego katalogu. Tworzenie wtyczki wysyłającej Intel OpenVINO
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Możesz też utworzyć wtyczkę wysyłania z repozytorium LiteRT-LM, dodając do elementu docelowego prefiks @litert. Podobnie jest w przypadku wszystkich poniższych celów z repozytorium LiteRT.
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Kompilowanie wtyczki kompilatora Intel OpenVINO
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
Narzędzie do kompilacji LiteRT Ahead-of-Time (AOT) Niektóre narzędzia LiteRT wymagają jawnej kompilacji AOT modeli przed ich uruchomieniem na procesorze NPU firmy Intel. Instrukcja kompilacji narzędzia kompilatora LiteRT AOT:
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
Tworzenie narzędzia do uruchamiania modeli LiteRT Narzędzia do uruchamiania modeli LiteRT można używać do uruchamiania modeli na procesorze NPU firmy Intel, zarówno modeli niekompilowanych wstępnie, jak i skompilowanych z wyprzedzeniem. Instrukcja tworzenia modułu wykonawczego modelu:
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
Narzędzie do testów porównawczych modelu LiteRT Narzędzie do testów porównawczych modelu LiteRT może służyć do testowania wydajności wnioskowania modelu na NPU firmy Intel. Jeśli instrukcja dotyczy utworzenia narzędzia do testów porównawczych:
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
Tworzenie narzędzia do sprawdzania wartości liczbowych LiteRT
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
Zaawansowane zastosowanie: tworzenie aplikacji przy użyciu dostosowanego pakietu Intel OpenVINO SDK
System kompilacji LiteRT automatycznie pobiera wstępnie skompilowany pakiet Intel OpenVINO SDK podczas kompilowania kompilatora i wtyczek wysyłających.
Jeśli Twój projekt wymaga określonej lub dostosowanej wersji pakietu Intel OpenVINO SDK, przed rozpoczęciem kompilacji wtyczki wykonaj te dodatkowe czynności konfiguracyjne:
- Pobierz najnowszą wersję binarną OpenVINO dla systemu Windows ze strony https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html i wyodrębnij ją na dysk lokalny, np.
C:\Intel\intel_openvino. - Upewnij się, że jedyny katalog podrzędny w tej ścieżce ma nazwę „openvino” i zawiera podkatalogi takie jak „runtime” i „include”.
- W konsoli (wierszu poleceń lub PowerShellu) przejdź do katalogu głównego sklonowanego repozytorium LiteRT i ustaw zmienną OPENVINO_NATIVE_DIR (upewnij się, że na końcu nie ma znaku
\`), for example:set OPENVINO_NATIVE_DIR=C:\Intel\intel_openvino`
Kompilacja modeli niestandardowych AOT
W tej sekcji przygotowujemy środowisko i przeprowadzamy kompilację AOT niestandardowych modeli TFLite, PyTorch lub JAX na potrzeby LiteRT.
Podczas procesu kompilacji modelu dla NPU firmy Intel LiteRT weryfikuje wykres modelu pod kątem operatorów obsługiwanych przez wtyczkę kompilatora LiteRT Intel OpenVINO. W przypadku operatorów lub podgrafów zgodnych z wtyczką kompilatora LiteRT kompiluje każdy taki podgraf do DISPATCH_OP, który następnie zastępuje oryginalny podgraf w grafie. Operatory, które nie są uwzględnione w zestawie obsługiwanych operatorów kompilatora Intel OpenVINO, pozostają w grafie bez zmian. W związku z tym kompilacja AOT może dać w rezultacie model w pełni lub częściowo delegowany. Oto przykład w pełni delegowanego modelu skompilowanego z wyprzedzeniem:
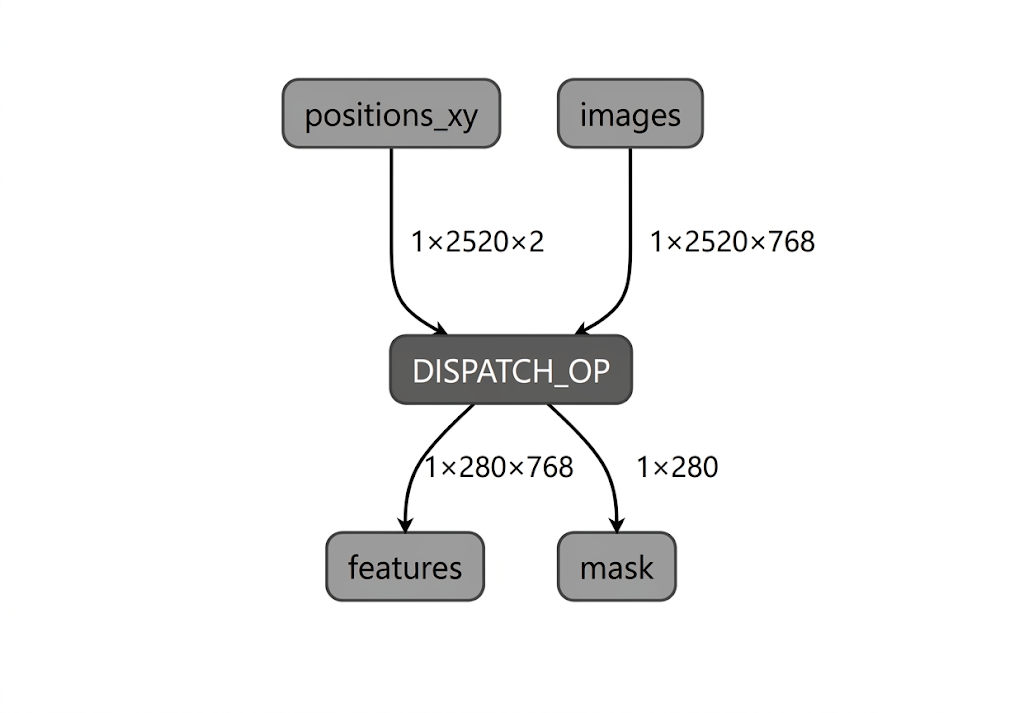
Narzędzie LiteRT apply_plugin_main (apply_plugin_main.exe) to narzędzie do kompilacji AOT, którego możesz użyć w tym celu. Przykładowe użycie narzędzia na platformie Intel:
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
Pamiętaj, że domyślny kompilator NPU, który jest dołączony do binarnej dystrybucji pakietu Intel OpenVINO SDK, jest używany w przypadku procesorów Intel Core Ultra serii 2 i kolejnych układów SoC. Jeśli model jest kompilowany na potrzeby jednostki NPU, której nie ma na liście obsługiwanych urządzeń, należy wyraźnie określić typ kompilatora (chociaż w przypadku procesorów Intel Core Ultra 2 i nowszych pozostaje to opcjonalne).
set IE_NPU_COMPILER_TYPE=PLUGIN
Kompilacja JIT i AOT w aplikacji
Aby skompilować modele we własnej aplikacji LiteRT, możesz skorzystać z 2 metod: kompilacji AOT, którą już przedstawiliśmy, oraz kompilacji JIT (Just-in-time).
W przypadku kompilacji AOT tryb jest kompilowany offline przed wdrożeniem i może zostać zapisany do późniejszego użycia. Jest to powszechnie stosowane, gdy kompilacja jest zbyt zasobochłonna, aby można ją było uruchomić na urządzeniu. Nie musi to być to samo urządzenie, na którym wdrażasz model. Przykład kompilacji AOT w kodzie:
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
Sposób wnioskowania za pomocą modelu skompilowanego z wyprzedzeniem:
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
Alternatywnym podejściem jest kompilacja JIT modelu w czasie działania na urządzeniu. Jest bardziej elastyczny: wymaga tylko jednego pliku modelu niezależnego od backendu.
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
Test porównawczy z użyciem parametru benchmark_model
Narzędzie benchmark_model (benchmark_model.exe) LiteRT zostało zaprojektowane specjalnie do testowania modelu skompilowanego AOT na NPU i może służyć do porównywania wydajności z backendem CPU (XNNPack) w LiteRT. Przykładowe polecenie do testowania wydajności modelu skompilowanego AOT na procesorze NPU firmy Intel:
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
Sprawdzanie dokładności za pomocą funkcji npu_numerics_check
Narzędzie npu_numerics_check służy do weryfikowania dokładności numerycznej modelu skompilowanego pod kątem NPU w porównaniu z wartością bazową (zwykle backend CPU, XNNPack). Ten krok jest kluczowy, aby zapewnić, że przekazanie obliczeń do NPU nie spowoduje niedopuszczalnych odchyleń numerycznych, które mogłyby wpłynąć na jakość modelu.
Uruchomienie testu numerycznego Narzędzie wymaga modelu skompilowanego z wyprzedzeniem i porównuje jego dane wyjściowe z danymi wyjściowymi oryginalnego modelu bez delegowania, który jest uruchamiany na procesorze.
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
Dalsze kroki
- Zacznij od przewodnika po ujednoliconym procesorze NPU: Akceleracja NPU za pomocą LiteRT
- Postępuj zgodnie z instrukcjami dotyczącymi konwersji i wdrażania, wybierając w odpowiednich miejscach Qualcomm.
- W przypadku dużych modeli językowych zapoznaj się z artykułem Uruchamianie dużych modeli językowych na procesorze NPU za pomocą LiteRT-LM.