
LiteRT mendukung Intel OpenVino melalui API CompiledModel untuk kompilasi AOT dan di perangkat.
Python API
Menyiapkan lingkungan pengembangan
Linux (x86_64):
- Ubuntu 22.04 atau 24.04 LTS
- Python 3.10+ — instal dari python.org
atau distro Anda (
sudo apt install python3 python3-venv) - Driver NPU Intel v1.32.1 — lihat Penyiapan NPU Linux
Windows (x86_64):
- Windows 10 atau 11
- Python 3.10+ — instal dari python.org
- Driver NPU Intel 32.0.100.4724+ — lihat Penyiapan NPU Windows
Untuk membangun dari sumber, Bazel 7.4.1+ menggunakan Bazelisk atau build Docker hermetik juga diperlukan.
SoC yang didukung
| Platform | NPU | Namakode | OS |
|---|---|---|---|
| Intel Core Ultra Series 2 | NPU4000 | Lunar Lake (LNL) | Linux, Windows |
| Intel Core Ultra Seri 3 | NPU5010 | Panther Lake (PTL) | Linux, Windows |
Mulai Cepat
1. Menginstal Driver NPU
Lihat Penyiapan NPU Linux atau Penyiapan NPU Windows. Lewati jika Anda hanya memerlukan AOT.
Driver NPU hanya diperlukan pada sistem yang mengeksekusi model di hardware NPU. Sistem build AOT murni dapat melewatinya.
Catatan:
ai-edge-litert-sdk-intel-nightlymenyematkan paket nightly OpenVINO yang cocok berdasarkan versi PEP 440 (misalnya,openvino==2026.2.0.dev20260506), sehingga pip memerlukan--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightlyuntuk menemukannya. Di Linux, jika deteksi otomatis distro memilih arsip yang salah, tetapkanLITERT_OV_OS_ID=ubuntu22atauubuntu24sebelumpip install.
2. Buat Lingkungan Virtual Python
Direkomendasikan untuk menjaga roda openvino malam tetap terisolasi dari penginstalan OpenVINO di seluruh sistem.
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
3. Menginstal Paket pip
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
--extra-index-url memungkinkan pip menyelesaikan wheel malam openvino yang disematkan
dari indeks OpenVINO bersama dengan paket di PyPI.
4. Verifikasi Penginstalan
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
Yang perlu diperiksa dalam output:
SDK libsmencantumkanlibopenvino_intel_npu_compiler.so(Linux) atauopenvino_intel_npu_compiler.dll(Windows) — diperlukan untuk AOT.Available devicesmencakupNPU— mengonfirmasi bahwa driver NPU telah diinstal dan OpenVINO dapat berkomunikasi dengan perangkat.NPUtidak akan ada di sistem khusus AOT (tempat driver tidak diinstal) dan di sistem tanpa hardware Intel NPU.
5. Kompilasi AOT (Opsional)
- Melakukan pra-kompilasi
.tfliteuntuk target NPU Intel tertentu (PTL atau LNL) sehingga runtime melewati langkah plugin compiler. - Tidak memerlukan NPU fisik atau driver NPU — hanya
ai-edge-litert-nightlydanai-edge-litert-sdk-intel-nightly. - Kompilasi silang didukung: kompilasi di host Linux atau Windows mana pun, kirim
.tfliteyang dihasilkan ke target OS mana pun dan jalankan di sana.
File output diberi nama <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite.
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
6. Menjalankan Inferensi NPU
LiteRT mendukung dua jalur inferensi di NPU Intel:
- JIT — memuat
.tflitementah; plugin compiler mempartisi dan mengompilasi operasi yang didukung untuk NPU pada waktuCompiledModel.from_file(). Menambahkan beberapa latensi pertama kali (berbeda-beda menurut model). - Dikompilasi AOT — memuat
<model>_IntelOpenVINO_<SoC>_apply_plugin.tfliteyang dihasilkan oleh langkah 4. Melewati langkah partisi dan kompilasi pada waktu pemuatan.
Cuplikan ini berfungsi untuk keduanya:
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
Mengonfirmasi bahwa JIT benar-benar berjalan
Jika JIT berhasil, log akan berisi (ekstensi file adalah .so di Linux, .dll di
Windows):
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
Jika baris tersebut tidak ada, tetapi Fully accelerated: True masih dilaporkan, model dijalankan pada penggantian CPU XNNPACK, bukan pada NPU — lihat baris pemecahan masalah JIT.
7. Benchmark
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
Flag umum:
| Bendera | Default | Deskripsi |
|---|---|---|
--model PATH
|
— | Jalur ke model .tflite (wajib). |
--signature KEY |
pertama | Kunci tanda tangan yang akan dijalankan. |
--use_cpu / --no_cpu
|
aktif | Mengalihkan akselerator CPU / penggantian CPU. |
--use_gpu |
nonaktif | Aktifkan akselerator GPU. |
--use_npu |
nonaktif | Aktifkan akselerator NPU Intel. |
--require_full_delegation
|
nonaktif | Gagal jika model tidak sepenuhnya di-offload ke akselerator yang dipilih. |
--num_runs N
|
50 | Jumlah iterasi inferensi berwaktu. |
--warmup_runs N
|
5 | Iterasi pemanasan tanpa waktu sebelum pengukuran. |
--num_threads N |
1 | Jumlah thread CPU. |
--result_json PATH
|
— | Menulis ringkasan JSON (statistik latensi, throughput, daftar akselerator). |
--verbose |
nonaktif | Logging runtime tambahan. |
Flag lanjutan / penggantian — hanya diperlukan untuk menunjuk ke build kustom:
--dispatch_library_path, --compiler_plugin_path, --runtime_path.
Roda kemudi vendor campuran: menyematkan JIT ke Intel OV
Catatan: Jika
Environment.create()dipanggil tanpa jalur eksplisit, metode ini akan otomatis menemukan vendor diai_edge_litert/vendors/dalam urutan abjad dan mendaftarkan vendor pertama yang ditemukannya. Dalam penginstalan vendor campuran, ini mungkin bukan Intel OV — teruskan direktori Intel OV secara eksplisit untuk memaksa pilihan yang tepat.
- Roda pip mengirimkan plugin compiler untuk setiap vendor terdaftar
(
intel_openvino/,google_tensor/,mediatek/,qualcomm/,samsung/). - Untuk memaksakan jalur Intel OV (direkomendasikan saat beberapa SDK vendor diinstal), teruskan direktori Intel OV secara manual:
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
Runtime memuat setiap library bersama yang ditemukannya di direktori tertentu, sehingga
menunjuk ke vendors/intel_openvino/compiler/ hanya memuat plugin Intel; plugin
Google Tensor / MediaTek / Qualcomm / Samsung di direktori saudara tidak
pernah disentuh.
Untuk CLI, tanda yang setara adalah:
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
Memverifikasi Eksekusi NPU
Untuk mengonfirmasi bahwa model benar-benar berjalan di NPU, periksa kedua sinyal:
- Log berisi
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}— library pengiriman Intel dimuat (.sodi Linux,.dlldi Windows). model.is_fully_accelerated()menampilkanTrue— setiap operasi di-offload ke akselerator yang dipilih.
is_fully_accelerated() saja tidak cukup: jika library pengiriman
tidak pernah dimuat, operasi akan sepenuhnya di-offload ke XNNPACK/CPU, bukan NPU.
Penyiapan NPU Linux
Catatan: Lewati bagian ini jika Anda hanya memerlukan AOT — NPU fisik tidak diperlukan.
Info: Gunakan driver NPU v1.32.1 (dipasangkan dengan OpenVINO 2026.1). Driver lama gagal dengan
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE.
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
Kemudian, jalankan cuplikan penginstalan + verifikasi dari Mulai Cepat.
Penyiapan NPU Windows
Catatan: Lewati bagian ini jika Anda hanya memerlukan AOT — NPU fisik tidak diperlukan.
- Instal driver NPU Intel (32.0.100.4724+) dari Pusat Download Intel.
- Pastikan Pengelola Perangkat mencantumkan perangkat NPU di bagian Prosesor neural
(ditampilkan sebagai
Intel(R) AI BoostatauIntel(R) NPU, bergantung pada driver). - Jalankan cuplikan penginstalan + verifikasi dari Mulai Cepat, dengan mengganti
pipdenganpython -m pip.
Info:
import ai_edge_litertotomatis mendaftarkan direktori DLL menggunakanos.add_dll_directory(), sehingga skrip Python tidak memerlukan penyiapanPATH. Untuk konsumen non-Python, jalankansetupvars.batatau tambahkan<openvino>/libskePATH.
Membangun dari Sumber
Menggunakan proxy? Ekspor
http_proxy/https_proxy/no_proxysebelum menjalankan skrip build — skrip ini meneruskannya ke Docker dan container.
Linux (Docker, hermetis):
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
Windows (PowerShell, Bazel di PATH):
.\ci\build_pip_package_with_bazel_windows.ps1
Output mendarat di dist/:
ai_edge_litert-*.whl— roda runtime.ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz— vendor sdists.- sdist Intel berukuran ~5 KB; pengompilasi NPU
.so/.dlldiambil pada waktupip install, sehingga sdist yang sama berfungsi di Linux dan Windows.
Pengujian Unit
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
Pemecahan masalah
| Masalah | Perbaiki |
|---|---|
AOT gagal: Device with "NPU" name is not registered |
Compiler NPU tidak diambil. Periksa ai_edge_litert_sdk_intel.path_to_sdk_libs() daftar libopenvino_intel_npu_compiler.so / .dll. Jika kosong, instal ulang dengan akses jaringan, atau setel LITERT_OV_OS_ID=ubuntu22/ubuntu24. |
JIT berjalan di CPU, bukan NPU (tidak ada log Partitioned subgraph, tidak ada log Loaded plugin, Fully accelerated: True masih dicetak) |
Plugin compiler tidak ditemukan. Konfirmasi bahwa ov.get_compiler_plugin_dir() menampilkan jalur di bawah ai_edge_litert/vendors/intel_openvino/compiler/. Jika beberapa SDK vendor diinstal, teruskan compiler_plugin_path=ov.get_compiler_plugin_dir() secara eksplisit ke Environment.create() (atau --compiler_plugin_path=... ke litert-benchmark). |
JIT gagal: Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so (Linux) / openvino_intel_npu_compiler.dll (Windows) |
Sdist SDK menyalin compiler NPU ke openvino/libs/ pada import ai_edge_litert_sdk_intel pertama. Jika penyalinan dilewati (FS hanya baca, openvino tidak ada), instal ulang ai-edge-litert-sdk-intel setelah openvino diinstal, lalu import ai_edge_litert dalam proses baru. |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE |
Upgrade driver NPU ke v1.32.1 (Linux). |
/dev/accel/accel0 tidak ditemukan |
sudo dmesg | grep -i vpu untuk men-debug driver; mulai ulang setelah penginstalan. |
| Izin ditolak di NPU | sudo gpasswd -a ${USER} render && newgrp render. |
| Windows: NPU tidak ada di Pengelola Perangkat | Instal driver NPU 32.0.100.4724+ dari Pusat Download Intel. |
Windows: Failed to initialize Dispatch API / DLL hilang |
Pastikan import ai_edge_litert dijalankan terlebih dahulu (mendaftarkan direktori DLL secara otomatis); untuk pemanggil non-Python, jalankan setupvars.bat atau tambahkan <openvino>/libs ke PATH. |
Build Windows: LNK2001 fixed_address_empty_string, C2491 dllimport, Python 3.12+ fails |
Batasan ABI Protobuf / versi Python — lihat ci/build_pip_package_with_bazel_windows.ps1; build Windows memerlukan Python 3.11. |
Batasan
Hanya perangkat NPU yang didukung melalui jalur pengiriman OpenVINO. Untuk inferensi CPU, gunakan HardwareAccelerator.CPU saja (XNNPACK).
C++ API
Prasyarat dan penyiapan build
Prasyarat build:
- Visual Studio 2022 atau yang lebih baru (alat pengembangan C++ harus diinstal).
- git: Instal git dari https://git-scm.com/install/. Pastikan
C:\Program Files\Git\bin and C:\Program Files\Git\cmddisertakan dalam variabel lingkungan PATH sistem Anda agar bash.exe dan git.exe dapat ditemukan oleh proses build LiteRT/LiteRT-LM. - bazelisk: Instal bazelisk dan sertakan lokasinya dalam variabel lingkungan
PATHsistem Anda: https://bazel.build/install/bazelisk. - Cmake: Instal Cmake versi 4.3.0 atau yang lebih baru dari https://cmake.org/download/, dengan memverifikasi bahwa Cmake disertakan dalam PATH sistem Anda.
- Python: Pastikan python 3.11 atau yang lebih baru telah diinstal, dan python.exe ada di PATH Anda.
- Setelan Windows: Aktifkan Mode Developer dalam Setelan Windows.
Membangun alat dan plugin LiteRT untuk NPU Intel
Untuk menjalankan model di NPU Intel dengan LiteRT, model tersebut harus dikompilasi menggunakan plugin compiler LiteRT Intel OpenVINO; Selain itu, setiap model yang dikompilasi yang ditujukan untuk dieksekusi di NPU Intel harus didelegasikan ke plugin dispatch LiteRT Intel OpenVINO.
Mekanisme yang digunakan LiteRT untuk memanggil plugin ini akan diilustrasikan selanjutnya:
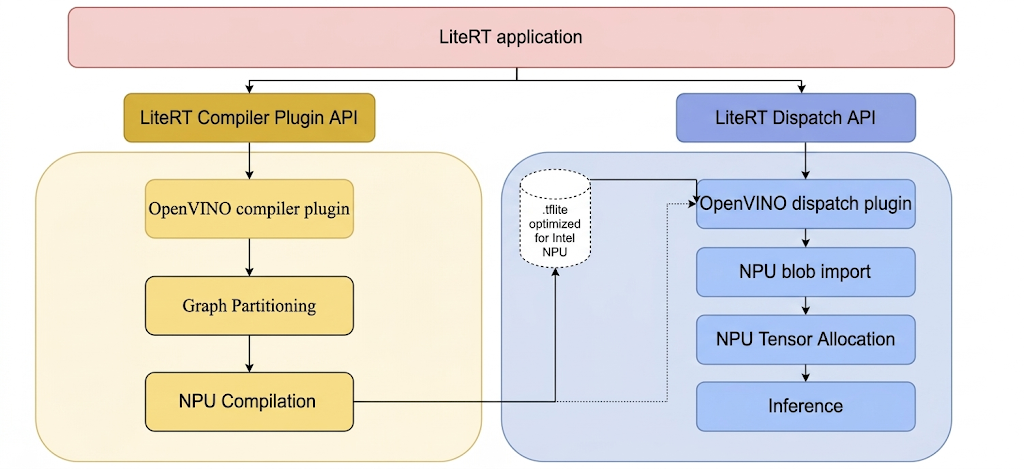
Langkah-langkah untuk membuat alat LiteRT dan plugin Intel.
Sebelum Anda membuat library atau file yang dapat dieksekusi dari LiteRT, buat direktori lokal, misalnya, C:\bzl. Biner output build akan dikumpulkan dari direktori ini. Membangun plugin pengiriman Intel OpenVINO
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Atau, Anda juga dapat membuat plugin pengiriman dari repositori LiteRT-LM dengan menambahkan awalan @litert pada target. Hal ini serupa untuk semua
target berikut dari repositori LiteRT.
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Membangun plugin compiler Intel OpenVINO
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
Bangun utilitas compiler Ahead-of-Time (AOT) LiteRT Beberapa alat LiteRT memerlukan kompilasi AOT model secara eksplisit sebelum menjalankannya di NPU Intel. Petunjuk build utilitas compiler AOT LiteRT:
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
Membangun pelaksana model LiteRT Pelaksana model LiteRT dapat digunakan untuk menjalankan model di NPU Intel, baik model yang tidak dikompilasi sebelumnya atau model yang dikompilasi AOT. Petunjuk untuk membuat pelari model:
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
Membangun utilitas model tolok ukur LiteRT Alat tolok ukur model LiteRT dapat digunakan untuk mengukur performa inferensi model di NPU Intel. Jika petunjuk untuk membuat alat benchmark:
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
Membangun utilitas pemeriksaan numerik LiteRT
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
Penggunaan lanjutan: membangun dengan Intel OpenVINO SDK yang disesuaikan
Sistem build LiteRT mengambil Intel OpenVINO SDK yang telah dibuat sebelumnya secara otomatis saat mengompilasi plugin compiler dan dispatch.
Jika project Anda memerlukan versi Intel OpenVINO SDK tertentu atau yang disesuaikan, selesaikan langkah-langkah konfigurasi tambahan ini sebelum memulai build plugin:
- Download biner rilis OpenVINO terbaru untuk Windows dari
https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html,
dan ekstrak ke disk lokal, misalnya,
C:\Intel\intel_openvino. - Pastikan satu-satunya direktori turunan di jalur ini diberi nama "openvino", yang berisi subdirektori seperti "runtime" dan "include".
- Buka direktori root repositori LiteRT yang di-clone di konsol Anda
(command prompt atau PowerShell), lalu tetapkan variabel OPENVINO_NATIVE_DIR
(pastikan tidak ada
\`), for example:set OPENVINO_NATIVE_DIR=C:\Intel\intel_openvino`
Kompilasi AOT model kustom
Bagian ini menyiapkan lingkungan dan melakukan kompilasi AOT model TFLite, PyTorch, atau JAX kustom untuk LiteRT.
Selama proses kompilasi model untuk NPU Intel, LiteRT memvalidasi grafik model terhadap operator yang didukung oleh plugin compiler LiteRT Intel OpenVINO. Untuk operator atau subgraf yang kompatibel dengan plugin compiler, LiteRT mengompilasi setiap subgraf tersebut menjadi DISPATCH_OP yang selanjutnya menggantikan subgraf asli dalam grafik. Operator yang tidak disertakan dalam opset yang didukung oleh compiler Intel OpenVINO tetap tidak berubah dalam grafik. Oleh karena itu, kompilasi AOT dapat menghasilkan model yang didelegasikan sepenuhnya atau sebagian. Berikut adalah contoh model yang dikompilasi AOT dengan delegasi penuh:
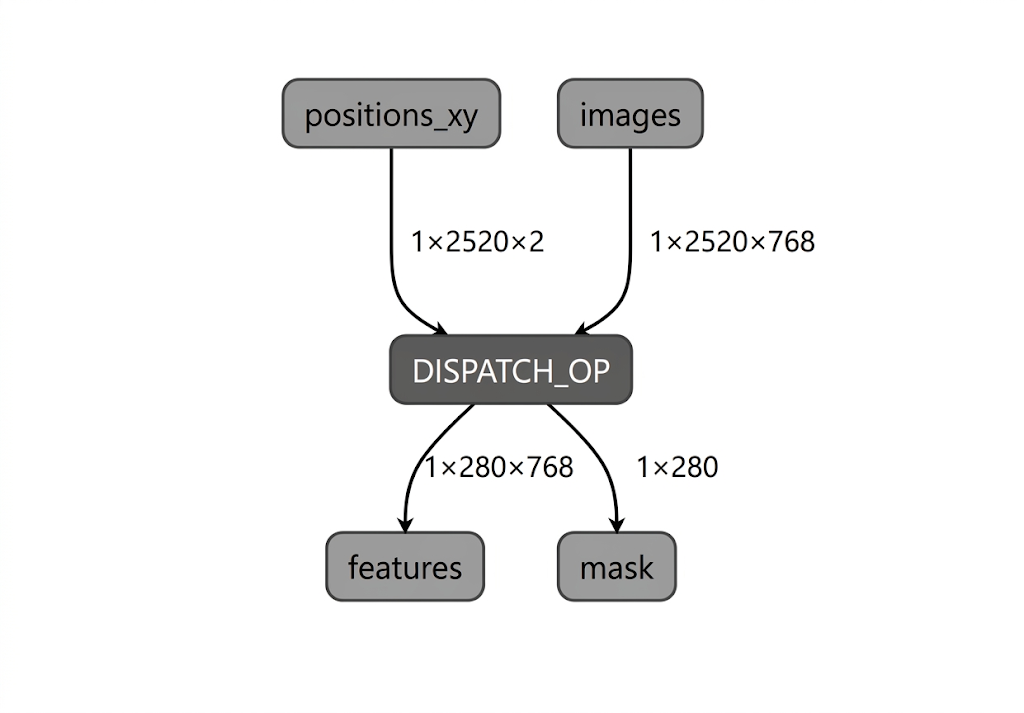
Utilitas apply_plugin_main LiteRT (apply_plugin_main.exe) adalah utilitas kompilasi AOT yang dapat Anda gunakan untuk tujuan ini. Contoh penggunaan utilitas di platform Intel:
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
Perhatikan bahwa compiler NPU pokok default, yang disertakan dalam distribusi biner Intel OpenVINO SDK, digunakan untuk SoC Intel Core Ultra Series 2 dan yang berikutnya. Jika model dikompilasi untuk NPU yang tidak ada dalam daftar yang didukung, jenis compiler harus ditentukan secara eksplisit (meskipun tetap opsional untuk Intel Core Ultra 2 dan yang lebih tinggi).
set IE_NPU_COMPILER_TYPE=PLUGIN
Kompilasi JIT vs. AOT di aplikasi Anda
Untuk mengompilasi model di aplikasi LiteRT Anda sendiri, ada dua pendekatan: kompilasi AOT yang telah kami perkenalkan, dan kompilasi Just-in-time (JIT).
Dengan kompilasi AOT, mode dikompilasi secara offline sebelum deployment dan dapat disimpan untuk penggunaan nanti — biasanya digunakan saat kompilasi terlalu banyak menggunakan resource untuk dijalankan di perangkat. Tindakan ini tidak perlu dilakukan di perangkat yang sama dengan perangkat tempat Anda men-deploy model. Contoh kompilasi AOT dalam kode Anda:
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
Cara melakukan inferensi dengan model yang dikompilasi AOT:
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
Pendekatan alternatifnya adalah mengompilasi JIT model saat runtime di perangkat. Lebih fleksibel: hanya memerlukan satu file model yang agnostik terhadap backend.
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
Tolok ukur dengan benchmark_model
Utilitas benchmark_model LiteRT (benchmark_model.exe) dirancang khusus untuk melakukan benchmarking model yang dikompilasi AOT di NPU, dan dapat digunakan untuk membandingkan performa dengan backend CPU (XNNPack) di LiteRT. Contoh perintah untuk mengukur performa model yang dikompilasi AOT di NPU Intel:
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
Pemeriksaan akurasi dengan npu_numerics_check
Utilitas npu_numerics_check digunakan untuk memverifikasi akurasi numerik model yang dikompilasi NPU terhadap baseline (biasanya backend CPU, XNNPack). Langkah ini sangat penting untuk memastikan bahwa delegasi ke NPU tidak menimbulkan penyimpangan numerik yang tidak dapat diterima yang dapat memengaruhi kualitas model.
Menjalankan pemeriksaan numerik Utilitas ini memerlukan model yang dikompilasi AOT dan membandingkan outputnya dengan model asli yang tidak didelegasikan yang dijalankan di CPU.
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
Langkah berikutnya
- Mulai dengan panduan NPU terpadu: Akselerasi NPU dengan LiteRT
- Ikuti langkah-langkah konversi dan deployment di sana, dengan memilih Qualcomm jika berlaku.
- Untuk LLM, lihat Menjalankan LLM di NPU menggunakan LiteRT-LM.