
LiteRT supporta Intel OpenVino tramite l'API CompiledModel
per la compilazione AOT e on-device.
API Python
Configura l'ambiente di sviluppo
Linux (x86_64):
- Ubuntu 22.04 o 24.04 LTS
- Python 3.10+ - installa da python.org
o dalla tua distribuzione (
sudo apt install python3 python3-venv) - Driver NPU Intel v1.32.1: vedi Configurazione della NPU Linux
Windows (x86_64):
- Windows 10 o 11
- Python 3.10+ - installa da python.org
- Driver NPU Intel 32.0.100.4724+. Vedi Configurazione della NPU di Windows
Per la compilazione dal codice sorgente, è necessario anche Bazel 7.4.1+ che utilizza Bazelisk o la build Docker ermetica.
SoC supportati
| Piattaforma | NPU | Nome in codice | Sistema operativo |
|---|---|---|---|
| Intel Core Ultra Serie 2 | NPU4000 | Lunar Lake (LNL) | Linux, Windows |
| Intel Core Ultra Serie 3 | NPU5010 | Panther Lake (PTL) | Linux, Windows |
Avvio rapido
1. Installare i driver NPU
Consulta Configurazione della NPU Linux o Configurazione della NPU Windows. Salta se hai bisogno solo di AOT.
Il driver NPU è necessario solo sui sistemi che eseguono il modello sull'hardware NPU. I sistemi di compilazione AOT pura possono ignorarlo.
Nota:
ai-edge-litert-sdk-intel-nightlyblocca la ruota notturna OpenVINO corrispondente in base alla versione PEP 440 (ad es.openvino==2026.2.0.dev20260506), quindi pip ha bisogno di--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightlyper individuarla. Su Linux, se il rilevamento automatico della distribuzione sceglie l'archivio sbagliato, impostaLITERT_OV_OS_ID=ubuntu22oubuntu24prima dipip install.
2. Crea un ambiente virtuale Python
Consigliamo di mantenere la ruota openvino notturna isolata da qualsiasi installazione OpenVINO a livello di sistema.
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
3. Installa il pacchetto pip
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
--extra-index-url consente a pip di risolvere la ruota notturna openvino
dall'indice di OpenVINO insieme ai pacchetti su PyPI.
4. Verifica dell'installazione
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
Cosa controllare nell'output:
SDK libselencalibopenvino_intel_npu_compiler.so(Linux) oopenvino_intel_npu_compiler.dll(Windows), richiesti per AOT.Available devicesincludeNPU: conferma che il driver NPU è installato e che OpenVINO può comunicare con il dispositivo.NPUnon sarà presente sui sistemi solo AOT (in cui il driver non è installato) e sui sistemi senza hardware Intel NPU.
5. Compilazione AOT (facoltativa)
- Precompila un
.tfliteper un target NPU Intel specifico (PTL o LNL) in modo che il runtime salti il passaggio del plug-in del compilatore. - Non ha bisogno di una NPU fisica o del driver NPU, solo di
ai-edge-litert-nightlyeai-edge-litert-sdk-intel-nightly. - È supportata la compilazione incrociata: compila su qualsiasi host Linux o Windows, invia
il
.tfliterisultante a una destinazione di uno dei due sistemi operativi ed eseguilo lì.
I file di output sono denominati <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite.
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
6. Esegui inferenza NPU
LiteRT supporta due percorsi di inferenza sulla NPU Intel:
- JIT: carica un
.tflitenon elaborato; il plug-in del compilatore partiziona e compila le operazioni supportate per la NPU al momento diCompiledModel.from_file(). Aggiunge una latenza di primo avvio (varia in base al modello). - Compilato AOT: carica un
<model>_IntelOpenVINO_<SoC>_apply_plugin.tfliteprodotto dal passaggio 4. Salta il passaggio di partizionamento e compilazione al momento del caricamento.
Questo snippet funziona per:
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
Conferma che il provisioning JIT sia stato eseguito
Quando la compilazione JIT ha esito positivo, il log contiene (l'estensione del file è .so su Linux, .dll su
Windows):
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
Se queste righe non sono presenti, ma Fully accelerated: True viene comunque segnalato, il
modello è stato eseguito sul fallback della CPU XNNPACK, non sulla NPU. Consulta la riga
di risoluzione dei problemi JIT.
7. Benchmark
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
Flag comuni:
| Flag | Predefinito | Descrizione |
|---|---|---|
--model PATH
|
— | Percorso del modello .tflite (obbligatorio). |
--signature KEY |
prima | Chiave di firma da eseguire. |
--use_cpu/--no_cpu
|
on | Attiva/disattiva l'acceleratore CPU/il fallback della CPU. |
--use_gpu |
off | Attiva l'acceleratore GPU. |
--use_npu |
off | Attiva l'acceleratore NPU Intel. |
--require_full_delegation
|
off | Errore se il modello non è completamente scaricato sull'acceleratore selezionato. |
--num_runs N
|
50 | Numero di iterazioni di inferenza temporizzata. |
--warmup_runs N
|
5 | Iterazioni di riscaldamento senza limiti di tempo prima della misurazione. |
--num_threads N |
1 | Conteggio thread CPU. |
--result_json PATH
|
— | Scrivi un riepilogo JSON (statistiche di latenza, throughput, elenco degli acceleratori). |
--verbose |
off | Logging di runtime aggiuntivo. |
Flag avanzati / di override: necessari solo per indicare build personalizzate:
--dispatch_library_path, --compiler_plugin_path, --runtime_path.
Ruote di fornitori misti: blocco di JIT su Intel OV
Nota:quando
Environment.create()viene chiamato senza percorsi espliciti, rileva automaticamente i fornitori inai_edge_litert/vendors/in ordine alfabetico e registra il primo che trova. In un'installazione di più fornitori, questo potrebbe non essere Intel OV. Trasferisci esplicitamente le directory Intel OV per forzare la scelta corretta.
- Il pacchetto pip include i plug-in del compilatore per ogni fornitore registrato
(
intel_openvino/,google_tensor/,mediatek/,qualcomm/,samsung/). - Per forzare il percorso Intel OV (consigliato quando sono installati più SDK di fornitori), passa manualmente le directory Intel OV:
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
Il runtime carica ogni libreria condivisa che trova nella directory specificata, quindi
se punti a vendors/intel_openvino/compiler/ viene caricato solo il plug-in Intel; i
plug-in Google Tensor / MediaTek / Qualcomm / Samsung nelle directory di pari livello non vengono
mai toccati.
Per la CLI, i flag equivalenti sono:
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
Verifica dell'esecuzione della NPU
Per verificare che il modello sia stato eseguito effettivamente sulla NPU, controlla entrambi i segnali:
- Il log contiene
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}: la libreria di invio Intel è stata caricata (.sosu Linux,.dllsu Windows). model.is_fully_accelerated()restituisceTrue: ogni operazione è stata scaricata sull'acceleratore selezionato.
is_fully_accelerated() da solo non è sufficiente: se la libreria di distribuzione non è mai stata caricata, le operazioni sono state completamente scaricate su XNNPACK/CPU, non sulla NPU.
Configurazione della NPU Linux
Nota:salta questa sezione se hai bisogno solo di AOT. Non è necessario un NPU fisico.
Informazioni:utilizza il driver NPU v1.32.1 (abbinato a OpenVINO 2026.1). I driver meno recenti non funzionano con
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE.
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
Quindi esegui lo snippet di installazione e verifica dalla Avvio rapido.
Configurazione della NPU di Windows
Nota:salta questa sezione se hai bisogno solo di AOT. Non è necessario un NPU fisico.
- Installa il driver NPU Intel (32.0.100.4724+) dal Centro download Intel.
- Verifica che Gestione dispositivi elenchi il dispositivo NPU nella sezione Processori neurali
(visualizzato come
Intel(R) AI BoostoIntel(R) NPUa seconda del driver). - Esegui lo snippet di installazione e verifica da Avvio rapido, sostituendo
pipconpython -m pip.
Informazioni:
import ai_edge_litertregistra automaticamente le directory DLL utilizzandoos.add_dll_directory(), quindi gli script Python non richiedono alcuna configurazionePATH. Per i consumatori non Python, eseguisetupvars.bato anteponi<openvino>/libsaPATH.
Compilare dall'origine
Dietro un proxy? Esporta
http_proxy/https_proxy/no_proxyprima di eseguire gli script di build, in quanto li inoltrano a Docker e al container.
Linux (Docker, ermetico):
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
Windows (PowerShell, Bazel in PATH):
.\ci\build_pip_package_with_bazel_windows.ps1
Gli output vengono inseriti in dist/:
ai_edge_litert-*.whl: la rotellina del runtime.ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz— vendor sdists.- L'sdist di Intel è di circa 5 KB; il compilatore NPU
.so/.dllviene recuperato al momentopip install, quindi lo stesso sdist funziona su Linux e Windows.
Test delle unità
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
Risoluzione dei problemi
| Problema | Correggi |
|---|---|
Errori AOT: Device with "NPU" name is not registered |
Compilatore NPU non recuperato. Controlla gli elenchi ai_edge_litert_sdk_intel.path_to_sdk_libs()libopenvino_intel_npu_compiler.so / .dll. Se è vuoto, reinstalla con l'accesso alla rete o imposta LITERT_OV_OS_ID=ubuntu22/ubuntu24. |
JIT viene eseguito sulla CPU anziché sulla NPU (nessun log Partitioned subgraph, nessun log Loaded plugin, Fully accelerated: True ancora stampato) |
Il plug-in del compilatore non è stato rilevato. Verifica che ov.get_compiler_plugin_dir() restituisca un percorso in ai_edge_litert/vendors/intel_openvino/compiler/. Se sono installati più SDK fornitore, passa compiler_plugin_path=ov.get_compiler_plugin_dir() in modo esplicito a Environment.create() (o --compiler_plugin_path=... a litert-benchmark). |
Errori JIT: Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so (Linux) / openvino_intel_npu_compiler.dll (Windows) |
L'SDK sdist copia il compilatore NPU in openvino/libs/ al primo import ai_edge_litert_sdk_intel. Se la copia è stata ignorata (FS di sola lettura, openvino mancante), reinstalla ai-edge-litert-sdk-intel dopo l'installazione di openvino, quindi import ai_edge_litert in un nuovo processo. |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE |
Esegui l'upgrade del driver NPU alla versione 1.32.1 (Linux). |
Risorsa /dev/accel/accel0 non trovata |
sudo dmesg | grep -i vpu per eseguire il debug del driver; riavvia dopo l'installazione. |
| Autorizzazione negata sulla NPU | sudo gpasswd -a ${USER} render && newgrp render. |
| Windows: NPU non presente in Gestione dispositivi | Installa il driver NPU 32.0.100.4724+ dal Centro download Intel. |
Windows: Failed to initialize Dispatch API / DLL mancanti |
Assicurati che import ai_edge_litert venga eseguito per primo (registra automaticamente le directory DLL); per i chiamanti non Python, esegui setupvars.bat o anteponi <openvino>/libs a PATH. |
Build di Windows: LNK2001 fixed_address_empty_string, C2491 dllimport, Python 3.12+ fails |
Vincolo ABI / versione Python di Protobuf: vedi ci/build_pip_package_with_bazel_windows.ps1; le build di Windows richiedono Python 3.11. |
Limitazioni
Solo il dispositivo NPU è supportato tramite il percorso di distribuzione OpenVINO. Per l'inferenza
della CPU, utilizza solo HardwareAccelerator.CPU (XNNPACK).
API C++
Prerequisiti e configurazione della build
Prerequisiti per la build:
- Visual Studio 2022 o versioni successive (devono essere installati gli strumenti di sviluppo C++).
- git: installa git da https://git-scm.com/install/. Assicurati che
C:\Program Files\Git\bin and C:\Program Files\Git\cmdsiano inclusi nella variabile di ambiente PATH del sistema per consentire ai processi di compilazione LiteRT/LiteRT-LM di individuare bash.exe e git.exe. - bazelisk: installa bazelisk e includi la sua posizione nella variabile di ambiente
PATHdel sistema: https://bazel.build/install/bazelisk. - Cmake: installa Cmake versione 4.3.0 o successive da https://cmake.org/download/, verificando che Cmake sia incluso nel PATH del sistema.
- Python: assicurati che sia installato Python 3.11 o versioni successive e che python.exe si trovi nel PATH.
- Impostazioni di Windows: attiva la modalità Sviluppatore nelle impostazioni di Windows.
Crea strumenti e plug-in LiteRT per l'NPU Intel
Per eseguire modelli sulla NPU Intel con LiteRT, è necessario compilarli utilizzando il plug-in del compilatore LiteRT Intel OpenVINO. Inoltre, qualsiasi modello compilato destinato all'esecuzione sulla NPU Intel deve essere delegato al plug-in di distribuzione LiteRT Intel OpenVINO.
Il meccanismo con cui LiteRT richiama questi plug-in è illustrato di seguito:
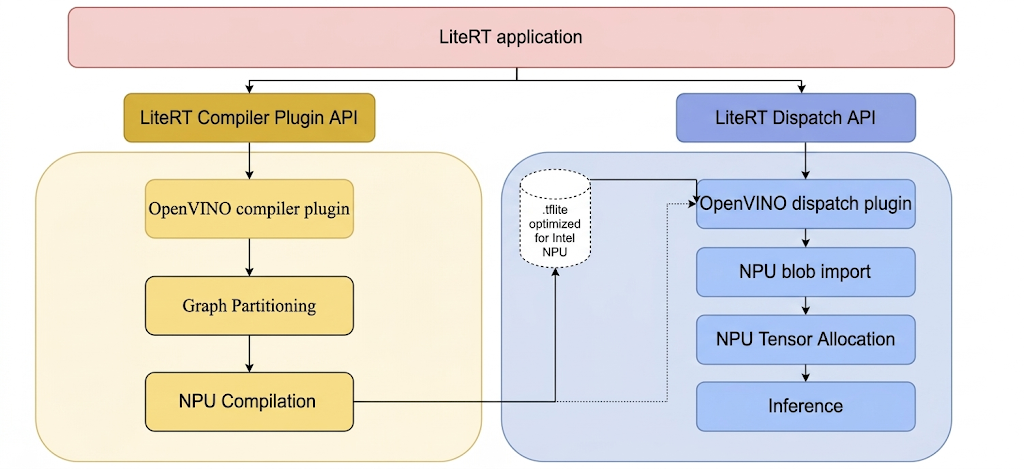
Passaggi per creare gli strumenti LiteRT e i plug-in Intel.
Prima di creare qualsiasi eseguibile o libreria da LiteRT, crea una directory locale, ad esempio C:\bzl. Il binario di output della build verrà raccolto da questa directory. Crea il plug-in di distribuzione Intel OpenVINO
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
In alternativa, puoi anche creare il plug-in di distribuzione dal repository LiteRT-LM
aggiungendo un prefisso @litert alla destinazione. Lo stesso vale per tutti
i seguenti target del repository LiteRT.
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Crea il plug-in del compilatore Intel OpenVINO
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
Crea l'utilità di compilazione Ahead-of-Time (AOT) di LiteRT Alcuni strumenti LiteRT richiedono la compilazione AOT esplicita dei modelli prima di eseguirli sulla NPU Intel. Istruzioni di compilazione dell'utilità di compilazione AOT LiteRT:
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
Crea l'esecutore del modello LiteRT L'esecutore del modello LiteRT può essere utilizzato per eseguire un modello sulla NPU Intel, sia un modello non precompilato sia un modello compilato AOT. L'istruzione per creare il runner del modello:
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
Utilità di benchmark del modello Build LiteRT Lo strumento di benchmark del modello LiteRT può essere utilizzato per confrontare le prestazioni dell'inferenza di un modello sulla NPU Intel. Se istruzioni per creare lo strumento di benchmarking:
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
Crea l'utilità di controllo numerico LiteRT
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
Utilizzo avanzato: esegui la build con l'SDK Intel OpenVINO personalizzato
Il sistema di compilazione LiteRT recupera automaticamente l'SDK Intel OpenVINO precompilato durante la compilazione del compilatore e dei plug-in di distribuzione.
Se il tuo progetto richiede una versione specifica o personalizzata dell'SDK Intel OpenVINO, completa questi passaggi di configurazione aggiuntivi prima di iniziare la build del plug-in:
- Scarica l'ultimo file binario della release di OpenVINO per Windows da
https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html,
ed estrailo sul disco locale, ad esempio
C:\Intel\intel_openvino. - Assicurati che l'unica directory secondaria in questo percorso sia denominata "openvino" e contenga sottodirectory come "runtime" e "include".
- Vai alla directory root del repository LiteRT clonato nella console
(prompt dei comandi o PowerShell) e imposta la variabile OPENVINO_NATIVE_DIR
(assicurati che non ci sia un
\`), for example:set OPENVINO_NATIVE_DIR=C:\Intel\intel_openvino`
Compilazione AOT di modelli personalizzati
Questa sezione prepara l'ambiente ed esegue la compilazione AOT di modelli TFLite, PyTorch o JAX personalizzati per LiteRT.
Durante il processo di compilazione del modello per la NPU Intel, LiteRT convalida il grafico del modello rispetto agli operatori supportati dal plug-in del compilatore LiteRT Intel OpenVINO. Per gli operatori o i sottografi compatibili con il plug-in del compilatore, LiteRT compila ogni sottografo in un DISPATCH_OP che successivamente sostituisce il sottografo originale all'interno del grafico. Gli operatori non inclusi nell'opset supportato dal compilatore Intel OpenVINO rimangono invariati all'interno del grafico. Di conseguenza, la compilazione AOT può produrre un modello completamente delegato o parzialmente delegato. Ecco un esempio di modello compilato AOT completamente delegato:
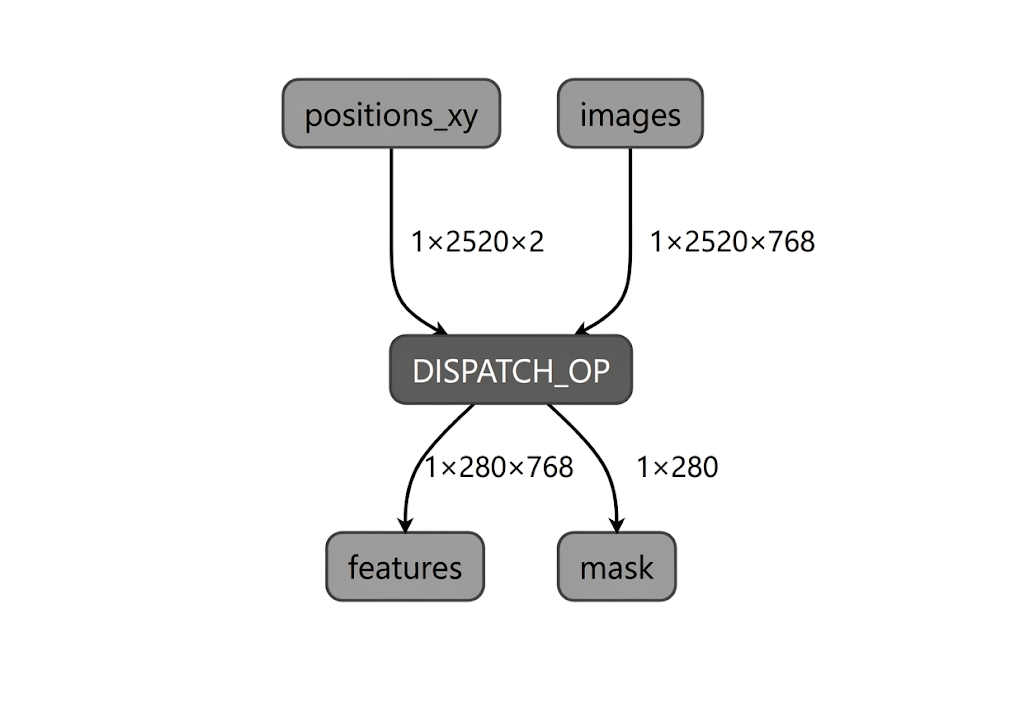
L'utilità LiteRT apply_plugin_main (apply_plugin_main.exe) è l'utilità di compilazione AOT che puoi utilizzare a questo scopo. Un esempio di utilizzo dell'utilità sulla piattaforma Intel:
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
Tieni presente che il compilatore NPU sottostante predefinito, incluso nella distribuzione binaria dell'SDK Intel OpenVINO, viene utilizzato per Intel Core Ultra Serie 2 e SoC successivi. Se un modello viene compilato per una NPU non presente nell'elenco supportato, il tipo di compilatore deve essere specificato in modo esplicito (anche se rimane facoltativo per Intel Core Ultra 2 e versioni successive).
set IE_NPU_COMPILER_TYPE=PLUGIN
Compilazione JIT e AOT nella tua applicazione
Per compilare i modelli nella tua applicazione LiteRT, esistono due approcci: la compilazione AOT che abbiamo già introdotto e la compilazione Just-in-time (JIT).
Con la compilazione AOT, la modalità viene compilata offline prima del deployment e può essere salvata per un utilizzo successivo. Questa modalità è di uso comune quando la compilazione richiede troppe risorse per essere eseguita sul dispositivo. Non è necessario eseguire questa operazione sullo stesso dispositivo su cui esegui il deployment del modello. Un esempio di compilazione AOT nel tuo codice:
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
Il modo per eseguire l'inferenza con un modello compilato AOT:
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
L'approccio alternativo consiste nel compilare JIT il modello in fase di runtime sul dispositivo. È più flessibile: richiede un solo file del modello indipendente dal backend.
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
Benchmark con benchmark_model
L'utilità benchmark_model di LiteRT (benchmark_model.exe) è progettata specificamente per il benchmarking di un modello compilato AOT sulla NPU e può essere utilizzata per confrontare le prestazioni rispetto al backend della CPU (XNNPack) in LiteRT. Comando di esempio per il benchmarking di un modello compilato AOT sulla NPU Intel:
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
Controllo accuratezza con npu_numerics_check
L'utilità npu_numerics_check viene utilizzata per verificare l'accuratezza numerica di un modello compilato per la NPU rispetto a una baseline (in genere il backend della CPU, XNNPack). Questo passaggio è fondamentale per garantire che la delega alla NPU non introduca deviazioni numeriche inaccettabili che potrebbero influire sulla qualità del modello.
Esegui il controllo numerico L'utilità richiede il modello compilato AOT e confronta i suoi output con quelli del modello originale non delegato eseguito sulla CPU.
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
Passaggi successivi
- Inizia con la guida NPU unificata: Accelerazione NPU con LiteRT
- Segui i passaggi per la conversione e l'implementazione, scegliendo Qualcomm dove applicabile.
- Per gli LLM, consulta Eseguire LLM sulla NPU utilizzando LiteRT-LM.