
تتوافق LiteRT مع Intel OpenVino من خلال واجهة برمجة التطبيقات CompiledModel لكلّ من الترجمة المسبقة (AOT) والترجمة على الجهاز.
واجهة Python API
إعداد بيئة التطوير
Linux (x86_64):
- Ubuntu 22.04 أو 24.04 LTS
- Python 3.10 والإصدارات الأحدث: يمكنك التثبيت من python.org
أو من توزيعتك (
sudo apt install python3 python3-venv) - برنامج تشغيل وحدة المعالجة العصبية (NPU) من Intel v1.32.1 — يُرجى الاطّلاع على إعداد وحدة المعالجة العصبية (NPU) في Linux
Windows (x86_64):
- Windows 10 أو 11
- Python 3.10 أو إصدار أحدث: يمكنك التثبيت من python.org
- برنامج تشغيل وحدة المعالجة العصبية (NPU) من Intel 32.0.100.4724+ — يمكنك الاطّلاع على إعداد وحدة المعالجة العصبية (NPU) في Windows
لإنشاء التطبيق من المصدر، يجب أيضًا استخدام الإصدار 7.4.1 من Bazel أو إصدار أحدث باستخدام Bazelisk أو إصدار Docker محكم.
المنظومات على الرقاقة المتوافقة
| النظام الأساسي | NPU | الاسم الرمزي | نظام التشغيل |
|---|---|---|---|
| Intel Core Ultra Series 2 | NPU4000 | Lunar Lake (LNL) | Linux وWindows |
| Intel Core Ultra Series 3 | NPU5010 | Panther Lake (PTL) | Linux وWindows |
البدء بسرعة
1. تثبيت برامج تشغيل وحدة المعالجة العصبية
راجِع إعداد وحدة المعالجة العصبية (NPU) في Linux أو إعداد وحدة المعالجة العصبية (NPU) في Windows. تخطَّ هذه الخطوة إذا كنت بحاجة إلى AOT فقط.
لا يلزم توفّر برنامج تشغيل وحدة المعالجة العصبية إلا على الأنظمة التي تنفِّذ النموذج على أجهزة وحدة المعالجة العصبية. يمكن لأنظمة الإنشاء التي تستخدم AOT فقط تخطّي هذه الخطوة.
ملاحظة: يثبّت
ai-edge-litert-sdk-intel-nightlyحزمة OpenVINO الليلية المطابقة حسب إصدار PEP 440 (مثلopenvino==2026.2.0.dev20260506)، لذا يحتاج pip إلى--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightlyلتحديد موقعها. على نظام التشغيل Linux، إذا اختار التعرّف التلقائي على التوزيعة الأرشيف الخاطئ، اضبطLITERT_OV_OS_ID=ubuntu22أوubuntu24قبلpip install.
2. إنشاء بيئة Python افتراضية
يُنصح بإبقاء حزمة openvino الليلية منفصلة عن أي عملية تثبيت OpenVINO على مستوى النظام.
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
3- تثبيت حزمة pip
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
يتيح --extra-index-url لـ pip حلّ openvino عجلة الإصدار الليلي المثبّتة
من فهرس OpenVINO إلى جانب الحِزم على PyPI.
4. التحقّق من التثبيت
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
ما يجب التأكّد منه في الناتج:
SDK libsقوائمlibopenvino_intel_npu_compiler.so(Linux) أوopenvino_intel_npu_compiler.dll(Windows) — مطلوبة لتنفيذ عملية التحويل المسبق.- يتضمّن
Available devicesNPU— يؤكّد تثبيت برنامج تشغيل وحدة المعالجة العصبية وأنّ OpenVINO يمكنه التواصل مع الجهاز. لن يتوفّرNPUعلى الأنظمة التي تستخدم الترجمة المسبقة فقط (حيث لم يتم تثبيت برنامج التشغيل) وعلى الأنظمة التي لا تتضمّن أجهزة Intel NPU.
5- الترجمة المسبقة (اختياري)
- يتم تجميع
.tfliteمسبقًا لاستهداف وحدة معالجة عصبية (NPU) محدّدة من Intel (PTL أو LNL) حتى يتخطى وقت التشغيل خطوة المكوّن الإضافي للمجمّع. - لا تحتاج إلى وحدة معالجة عصبية (NPU) أو برنامج تشغيل لوحدة المعالجة العصبية، بل تحتاج فقط إلى
ai-edge-litert-nightlyوai-edge-litert-sdk-intel-nightly. - يتيح هذا الخيار إمكانية الترجمة البرمجية المتوافقة مع أنظمة متعددة: يمكنك الترجمة البرمجية على أي مضيف Linux أو Windows، ونقل
.tfliteالناتج إلى نظام التشغيل المستهدف وتشغيله هناك.
تتم تسمية ملفات الإخراج <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite.
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
6. تشغيل الاستنتاج باستخدام وحدة المعالجة العصبية
تتيح LiteRT مسارَين للاستدلال على وحدة المعالجة العصبية (NPU) من Intel:
- التجميع أثناء التشغيل (JIT): لتحميل
.tfliteغير معالَج، يقسّم المكوّن الإضافي لبرنامج التجميع العمليات المتوافقة مع وحدة المعالجة العصبية (NPU) ويجمّعها في وقتCompiledModel.from_file(). تتم إضافة بعض وقت الاستجابة عند التشغيل لأول مرة (يختلف حسب الطراز). - تم تجميعها مسبقًا (AOT): يتم تحميل
<model>_IntelOpenVINO_<SoC>_apply_plugin.tfliteالذي تم إنشاؤه في الخطوة 4. تتخطّى خطوة التقسيم والتجميع في مدّة التحميل.
يعمل هذا المقتطف مع كلّ من:
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
تأكيد تنفيذ التجميع أثناء التنفيذ
عندما تنجح عملية JIT، يحتوي السجلّ على ما يلي (امتداد الملف هو .so على نظام التشغيل Linux و.dll على نظام التشغيل Windows):
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
في حال عدم توفّر هذه الأسطر مع استمرار عرض Fully accelerated: True، يعني ذلك أنّه تم تشغيل النموذج على XNNPACK CPU الاحتياطي، وليس على وحدة المعالجة العصبية (NPU). راجِع صف حلّ المشاكل في JIT.
7. مقياس الأداء
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
العلامات الشائعة:
| علم | تلقائي | الوصف |
|---|---|---|
--model PATH
|
— | مسار .tflite النموذج (مطلوب). |
--signature KEY |
أولية | مفتاح التوقيع المطلوب تشغيله |
--use_cpu / --no_cpu
|
تشغيل | يمكنك تفعيل أو إيقاف مسرّع وحدة المعالجة المركزية أو استخدام وحدة المعالجة المركزية كخيار احتياطي. |
--use_gpu |
إيقاف | فعِّل مسرِّع وحدة معالجة الرسومات. |
--use_npu |
إيقاف | فعِّل مسرّع Intel NPU. |
--require_full_delegation
|
إيقاف | يحدث خطأ إذا لم يتم نقل النموذج بالكامل إلى أداة التسريع المحدّدة. |
--num_runs N
|
50 | عدد تكرارات الاستدلال الموقّت. |
--warmup_runs N
|
5 | عدد مرات التكرار غير المحدَّدة المدة للإحماء قبل القياس |
--num_threads N |
1 | عدد سلاسل وحدة المعالجة المركزية |
--result_json PATH
|
— | اكتب ملخّصًا بتنسيق JSON (إحصاءات وقت الاستجابة ومعدّل النقل وقائمة أدوات التسريع). |
--verbose |
إيقاف | تسجيل إضافي لوقت التشغيل |
العلامات المتقدّمة / علامات التجاوز — مطلوبة فقط للإشارة إلى إصدارات مخصّصة:
--dispatch_library_path و--compiler_plugin_path و--runtime_path.
عجلات من مورّدين مختلفين: تثبيت JIT على Intel OV
ملاحظة: عند استدعاء
Environment.create()بدون مسارات صريحة، يتم تلقائيًا البحث عن المورّدين ضمنai_edge_litert/vendors/بالترتيب الأبجدي، ويتم تسجيل أول مورد يتم العثور عليه. في عملية تثبيت من عدة مورّدين، قد لا يكون ذلك Intel OV، لذا يجب تمرير أدلة Intel OV بشكل صريح لفرض الاختيار الصحيح.
- تتضمّن حزمة pip عجلة برامج التجميع الإضافية لكل مورّد مسجّل
(
intel_openvino/وgoogle_tensor/وmediatek/وqualcomm/وsamsung/). - لفرض مسار Intel OV (يُنصح به عند تثبيت حِزم SDK متعددة من مورّدين مختلفين)، مرِّر أدلة Intel OV يدويًا:
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
يحمّل وقت التشغيل كل مكتبة مشتركة يعثر عليها في الدليل المحدّد، لذا فإنّ
الإشارة إلى vendors/intel_openvino/compiler/ تؤدي إلى تحميل مكوّن Intel الإضافي فقط،
بينما لا يتم مطلقًا الوصول إلى مكوّنات Google Tensor / MediaTek / Qualcomm / Samsung الإضافية في الأدلة الفرعية.
بالنسبة إلى واجهة سطر الأوامر، تكون العلامات المكافئة هي:
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
التحقّق من تنفيذ وحدة المعالجة العصبية
للتأكّد من أنّ النموذج تم تنفيذه على وحدة المعالجة العصبية، ابحث عن كلتا الإشارتين التاليتين:
- يحتوي السجلّ على
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}، ما يعني أنّه تم تحميل مكتبة الإرسال الخاصة بشركة Intel (.soعلى نظام التشغيل Linux و.dllعلى نظام التشغيل Windows). - تعرض
model.is_fully_accelerated()القيمةTrue، ما يعني أنّه تم نقل كل عملية إلى أداة التسريع المحدّدة.
is_fully_accelerated() وحده غير كافٍ: إذا لم يتم تحميل مكتبة الإرسال مطلقًا، سيتم نقل العمليات بالكامل إلى XNNPACK/وحدة المعالجة المركزية، وليس إلى وحدة المعالجة العصبية.
إعداد NPU على Linux
ملاحظة: يمكنك تخطّي هذا القسم إذا كنت بحاجة إلى AOT فقط، إذ لا يلزم توفّر وحدة معالجة عصبية فعلية.
المعلومات: استخدِم برنامج تشغيل NPU v1.32.1 (المتوافق مع OpenVINO 2026.1). السائقون الأكبر سنًا لا ينجحون في
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE.
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
بعد ذلك، شغِّل مقتطف التثبيت والتحقّق من البدء السريع.
إعداد وحدة المعالجة العصبية (NPU) في Windows
ملاحظة: يمكنك تخطّي هذا القسم إذا كنت بحاجة إلى AOT فقط، إذ لا يلزم توفّر وحدة معالجة عصبية فعلية.
- ثبِّت برنامج تشغيل Intel NPU (32.0.100.4724+) من مركز التنزيل من Intel.
- تأكَّد من أنّ أداة إدارة الأجهزة تُدرِج جهاز وحدة المعالجة العصبية ضمن معالجات عصبية
(تظهر على شكل
Intel(R) AI BoostأوIntel(R) NPUحسب برنامج التشغيل). - نفِّذ مقتطف التثبيت والتحقّق من البدء السريع، مع استبدال
pipبـpython -m pip.
معلومات: تسجّل
import ai_edge_litertتلقائيًا أدلة ملفات DLL باستخدامos.add_dll_directory()، لذا لا تحتاج النصوص البرمجية في Python إلى إعدادPATH. بالنسبة إلى مستخدمي غير Python، شغِّلsetupvars.batأو أضِف<openvino>/libsإلى بدايةPATH.
إنشاء التطبيق من المصدر
هل أنت تستخدم خادم وكيل؟ تصدير
http_proxy/https_proxy/no_proxyقبل تشغيل نصوص الإنشاء البرمجية، لأنّها تعيد توجيهها إلى Docker والحاوية
Linux (Docker، إصدار مستقل):
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
نظام التشغيل Windows (PowerShell، Bazel في PATH):
.\ci\build_pip_package_with_bazel_windows.ps1
يتم تخزين النواتج في dist/:
ai_edge_litert-*.whl— عجلة وقت التشغيل-
ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz— مورّد sdists. - يبلغ حجم حزمة sdist من Intel حوالي 5 كيلوبايت، ويتم جلب برنامج NPU المجمّع
.so/.dllفي وقتpip install، لذا تعمل حزمة sdist نفسها على نظامَي التشغيل Linux وWindows.
اختبارات الوحدات
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
تحديد المشاكل وحلّها
| المشكلة | تعديل الإجابات |
|---|---|
تعذُّر تنفيذ AOT: Device with "NPU" name is not registered |
لم يتم استرجاع برنامج التحويل البرمجي لوحدة المعالجة العصبية. راجِع ai_edge_litert_sdk_intel.path_to_sdk_libs() القوائم libopenvino_intel_npu_compiler.so / .dll. إذا كان فارغًا، أعِد التثبيت مع إمكانية الوصول إلى الشبكة، أو اضبط LITERT_OV_OS_ID=ubuntu22/ubuntu24. |
يتم تشغيل JIT على وحدة المعالجة المركزية (CPU) بدلاً من وحدة المعالجة العصبية (NPU) (لا يوجد سجلّ Partitioned subgraph، ولا يوجد سجلّ Loaded plugin، ولكن لا يزال يتم عرض Fully accelerated: True) |
لم يتم العثور على المكوّن الإضافي للمترجم. تؤكّد السمة ov.get_compiler_plugin_dir() أنّها تعرض مسارًا ضمن ai_edge_litert/vendors/intel_openvino/compiler/. في حال تثبيت حِزم SDK متعددة خاصة بمورّدين، يجب تمرير compiler_plugin_path=ov.get_compiler_plugin_dir() بشكلٍ صريح إلى Environment.create() (أو --compiler_plugin_path=... إلى litert-benchmark). |
تعذُّر التجميع أثناء التنفيذ: Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so (Linux) / openvino_intel_npu_compiler.dll (Windows) |
تنسخ حزمة sdist الخاصة بحزمة تطوير البرامج (SDK) برنامج NPU المجمّع إلى openvino/libs/ عند تنفيذ import ai_edge_litert_sdk_intel للمرة الأولى. إذا تم تخطّي النسخ (نظام ملفات للقراءة فقط، openvino غير متوفّر)، أعِد تثبيت ai-edge-litert-sdk-intel بعد تثبيت openvino، ثم import ai_edge_litert في عملية جديدة. |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE |
ترقية برنامج تشغيل وحدة المعالجة العصبية إلى الإصدار 1.32.1 (Linux) |
لم يتم العثور على /dev/accel/accel0 |
sudo dmesg | grep -i vpu لتصحيح أخطاء برنامج التشغيل، وأعِد التشغيل بعد التثبيت. |
| تم رفض الإذن على وحدة المعالجة العصبية | sudo gpasswd -a ${USER} render && newgrp render. |
| Windows: وحدة المعالجة العصبية غير متوفّرة في "إدارة الأجهزة" | ثبِّت برنامج تشغيل NPU 32.0.100.4724+ من مركز التنزيل من Intel. |
Windows: Failed to initialize Dispatch API / ملفات DLL مفقودة |
تأكَّد من تشغيل import ai_edge_litert أولاً (تسجيل أدلة DLL تلقائيًا). بالنسبة إلى المتصلين غير Python، شغِّل setupvars.bat أو أضِف <openvino>/libs إلى PATH. |
إصدار Windows: LNK2001 fixed_address_empty_string أو C2491 dllimport أو Python 3.12+ fails |
قيود توافق واجهة التطبيق الثنائية (ABI) مع Protobuf / إصدار Python — يمكنك الاطّلاع على ci/build_pip_package_with_bazel_windows.ps1، وتتطلّب إصدارات Windows الإصدار 3.11 من Python. |
القيود
لا يتوافق مع مسار الإرسال OpenVINO إلا جهاز NPU. بالنسبة إلى الاستدلال على وحدة المعالجة المركزية، استخدِم HardwareAccelerator.CPU فقط (XNNPACK).
واجهة برمجة تطبيقات C++
المتطلّبات الأساسية وإعداد الإصدار
المتطلبات الأساسية للإصدار:
- Visual Studio 2022 أو إصدار أحدث (يجب تثبيت أدوات تطوير C++).
- git: ثبِّت git من https://git-scm.com/install/. تأكَّد من تضمين
C:\Program Files\Git\bin and C:\Program Files\Git\cmdفي متغير بيئة PATH الخاص بالنظام للسماح لعمليات إنشاء LiteRT/LiteRT-LM بتحديد موقع bash.exe وgit.exe. - bazelisk: ثبِّت bazelisk وأدرِج موقعه الجغرافي في متغيّر بيئة
PATHفي نظامك: https://bazel.build/install/bazelisk. - Cmake: ثبِّت الإصدار 4.3.0 أو إصدارًا أحدث من Cmake من https://cmake.org/download/، وتأكَّد من تضمين Cmake في PATH الخاص بنظامك.
- Python: تأكَّد من تثبيت الإصدار 3.11 أو إصدار أحدث من Python، ومن أنّ python.exe متوفّر في PATH.
- إعدادات Windows: فعِّل "وضع المطوّر" ضمن "إعدادات Windows".
إنشاء أدوات ومكوّنات إضافية لـ LiteRT من أجل وحدة المعالجة العصبية (NPU) من Intel
لتشغيل النماذج على وحدة المعالجة العصبية من Intel باستخدام LiteRT، يجب تجميعها باستخدام المكوّن الإضافي لمجمّع LiteRT Intel OpenVINO. بالإضافة إلى ذلك، يجب تفويض أي نموذج مجمّع مخصّص للتنفيذ على وحدة المعالجة العصبية من Intel إلى المكوّن الإضافي لتوزيع LiteRT Intel OpenVINO.
في ما يلي توضيح لآلية استدعاء LiteRT لهذه المكوّنات الإضافية:
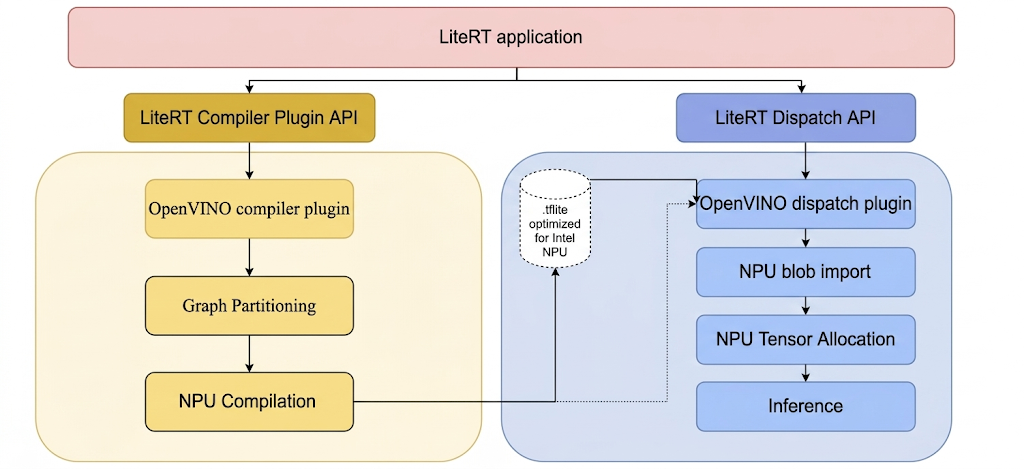
خطوات إنشاء أدوات LiteRT ومكوّنات Intel الإضافية
قبل إنشاء أي ملف تنفيذي أو مكتبة من LiteRT، أنشئ دليلاً محليًا، مثل C:\bzl. سيتم جمع رمز الإخراج الثنائي للإنشاء من هذا الدليل. إنشاء مكوّن Intel OpenVINO الإضافي الخاص بالإرسال
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
بدلاً من ذلك، يمكنك أيضًا إنشاء إضافة الإرسال من مستودع LiteRT-LM
، وذلك عن طريق إضافة البادئة @litert إلى الهدف. وينطبق الأمر نفسه على جميع
الاستهدافات التالية من مستودع LiteRT.
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
إنشاء المكوّن الإضافي لبرنامج تجميع Intel OpenVINO
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
إنشاء أداة تجميع LiteRT Ahead-of-Time (AOT) تتطلّب بعض أدوات LiteRT تجميع AOT صريح للنماذج قبل تشغيلها على وحدة المعالجة العصبية (NPU) من Intel. تعليمات إنشاء أداة تجميع AOT في LiteRT:
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
إنشاء أداة تشغيل نماذج LiteRT يمكن استخدام أداة تشغيل نماذج LiteRT لتشغيل نموذج على وحدة المعالجة العصبية (NPU) من Intel، سواء كان نموذجًا غير مجمَّع مسبقًا أو نموذجًا مجمَّعًا باستخدام AOT. التعليمات اللازمة لإنشاء أداة تنفيذ النموذج:
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
إنشاء أداة مساعدة لنموذج قياس أداء LiteRT يمكن استخدام أداة قياس أداء نموذج LiteRT لقياس أداء الاستدلال الخاص بنموذج على وحدة المعالجة العصبية (NPU) من Intel. في حال توفّر تعليمات لإنشاء أداة قياس الأداء:
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
إنشاء أداة للتحقّق من الأرقام في LiteRT
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
الاستخدام المتقدّم: إنشاء تطبيقات باستخدام حزمة تطوير البرامج (SDK) المخصّصة من Intel OpenVINO
يجلب نظام التصميم LiteRT حزمة تطوير البرامج (SDK) من Intel OpenVINO المُنشأة مسبقًا تلقائيًا عند تجميع المكوّن الإضافي لبرنامج التجميع وتوزيع المهام.
إذا كان مشروعك يتطلّب إصدارًا محدّدًا أو مخصّصًا من حزمة تطوير البرامج (SDK) الخاصة بـ Intel OpenVINO، عليك إكمال خطوات الإعداد الإضافية التالية قبل بدء إنشاء المكوّن الإضافي:
- نزِّل أحدث إصدار ثنائي من OpenVINO لنظام التشغيل Windows من
https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html،
واستخرِجه إلى القرص المحلي، على سبيل المثال،
C:\Intel\intel_openvino. - تأكَّد من أنّ دليل العنصر الفرعي الوحيد ضمن هذا المسار يحمل الاسم "openvino"، ويحتوي على أدلة فرعية مثل "runtime" و "include".
- انتقِل إلى الدليل الجذر لمستودع LiteRT المستنسخ في وحدة التحكّم
(موجه الأوامر أو PowerShell)، واضبط المتغيّر OPENVINO_NATIVE_DIR
(تأكَّد من عدم وجود
\`), for example:set OPENVINO_NATIVE_DIR=C:\Intel\intel_openvino`
تجميع نماذج مخصّصة مسبقًا (AOT)
يعدّ هذا القسم البيئة وينفّذ عملية تجميع AOT لنماذج TFLite أو PyTorch أو JAX المخصّصة لـ LiteRT.
أثناء عملية تجميع النموذج لوحدة المعالجة العصبية من Intel، يتحقّق LiteRT من صحة الرسم البياني للنموذج مقارنةً بالعوامل التي يتيحها مكوّن LiteRT الإضافي لبرنامج التجميع Intel OpenVINO. بالنسبة إلى العمليات أو الرسومات البيانية الفرعية المتوافقة مع المكوّن الإضافي للمترجم، يترجم LiteRT كل رسم بياني فرعي من هذا النوع إلى DISPATCH_OP، والذي يحلّ محل الرسم البياني الفرعي الأصلي في الرسم البياني. تبقى عوامل التشغيل غير المضمّنة في مجموعة عوامل التشغيل المتوافقة مع برنامج التجميع Intel OpenVINO بدون تغيير داخل الرسم البياني. نتيجةً لذلك، قد يؤدي تجميع AOT إلى نموذج مفوَّض بالكامل أو مفوَّض جزئيًا. في ما يلي مثال على نموذج تم تجميع AOT له بالكامل:
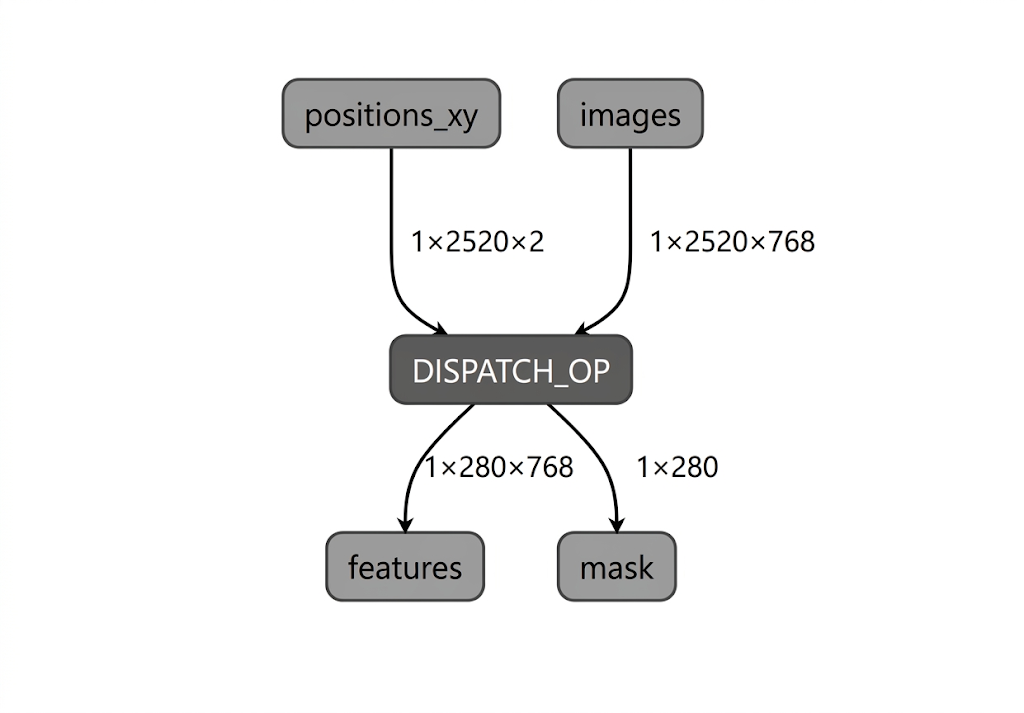
الأداة المساعدة LiteRT apply_plugin_main (apply_plugin_main.exe) هي أداة تجميع AOT التي يمكنك استخدامها لهذا الغرض. في ما يلي مثال على استخدام الأداة على منصة Intel:
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
يُرجى العِلم أنّه يتم استخدام برنامج التجميع الأساسي التلقائي لوحدة المعالجة العصبية (NPU)، والمضمّن في التوزيع الثنائي لحزمة تطوير البرامج (SDK) من Intel OpenVINO، مع معالجات Intel Core Ultra من السلسلة 2 وشرائح النظام على اللوحة (SoC) اللاحقة. إذا كان يتم تجميع نموذج لوحدة معالجة عصبية غير مدرَجة في قائمة الوحدات المتوافقة، يجب تحديد نوع المجمّع بشكل صريح (مع أنّ هذا يبقى اختياريًا في معالجات Intel Core Ultra 2 والإصدارات الأحدث).
set IE_NPU_COMPILER_TYPE=PLUGIN
التجميع أثناء التنفيذ (JIT) مقابل التجميع مسبقًا (AOT) في تطبيقك
لتجميع النماذج في تطبيق LiteRT الخاص بك، يمكنك اتّباع طريقتَين: تجميع AOT الذي سبق أن قدّمناه، والتجميع أثناء التنفيذ (JIT).
باستخدام تجميع AOT، يتم تجميع الوضع بلا إنترنت قبل النشر ويمكن حفظه لاستخدامه لاحقًا، ويتم استخدام هذه الطريقة عادةً عندما يكون التجميع يتطلّب الكثير من الموارد لتشغيله على الجهاز. ليس من الضروري إجراء ذلك على الجهاز نفسه الذي تنشر عليه النموذج. في ما يلي مثال على تجميع AOT في الرمز البرمجي:
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
طريقة الاستدلال باستخدام نموذج تم تجميعه مسبقًا:
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
الأسلوب البديل هو تجميع النموذج أثناء التنفيذ على الجهاز. وهي أكثر مرونة، إذ تتطلّب ملف نموذج واحدًا فقط لا يعتمد على الخلفية.
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
مقارنة الأداء باستخدام benchmark_model
تم تصميم أداة benchmark_model المساعدة في LiteRT (ملف benchmark_model.exe) خصيصًا لتقييم أداء نموذج تم تجميعه مسبقًا (AOT) على وحدة المعالجة العصبية، ويمكن استخدامها لمقارنة الأداء مع الخلفية المستندة إلى وحدة المعالجة المركزية (XNNPack) في LiteRT. مثال على أمر قياس أداء نموذج تم تجميعه مسبقًا (AOT) على وحدة المعالجة العصبية (NPU) من Intel:
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
التحقّق من دقّة البيانات باستخدام npu_numerics_check
يتم استخدام الأداة المساعدة npu_numerics_check للتحقّق من الدقة العددية لنموذج تم تجميعه باستخدام وحدة معالجة عصبية (NPU) مقارنةً بخط أساس (عادةً ما يكون وحدة المعالجة المركزية XNNPack). هذه الخطوة ضرورية لضمان ألا يؤدي التفويض إلى وحدة المعالجة العصبية إلى حدوث انحرافات عددية غير مقبولة قد تؤثر في جودة النموذج.
تشغيل عملية التحقّق من الأرقام تتطلّب الأداة النموذج الذي تم تجميعه مسبقًا (AOT) وتقارن مخرجاته بالمخرجات الأصلية للنموذج الذي لم يتم تفويضه والذي تم تشغيله على وحدة المعالجة المركزية.
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
الخطوات التالية
- ابدأ بدليل وحدة المعالجة العصبية الموحّدة: تسريع وحدة المعالجة العصبية باستخدام LiteRT
- اتّبِع خطوات الإحالة الناجحة والنشر الواردة في هذا القسم، واختَر Qualcomm حيثما ينطبق ذلك.
- بالنسبة إلى النماذج اللغوية الكبيرة، يُرجى الاطّلاع على تنفيذ النماذج اللغوية الكبيرة على وحدة المعالجة العصبية باستخدام LiteRT-LM.