
LiteRT admite Intel OpenVino a través de la API de CompiledModel para la compilación AOT y la compilación integrado en el dispositivo.
API de Python
Cómo configurar el entorno de desarrollo
Linux (x86_64):
- Ubuntu 22.04 o 24.04 LTS
- Python 3.10 o versiones posteriores: Instala desde python.org o tu distribución (
sudo apt install python3 python3-venv). - Controlador de NPU de Intel v1.32.1: Consulta Configuración de la NPU en Linux
Windows (x86_64):
- Windows 10 u 11
- Python 3.10 o versiones posteriores: Instala desde python.org.
- Controlador de NPU de Intel 32.0.100.4724+: Consulta Configuración de la NPU de Windows
Para compilar desde la fuente, también se requiere Bazel 7.4.1 o versiones posteriores con Bazelisk o la compilación hermética de Docker.
SoCs compatibles
| Plataforma | NPU | Nombre interno | SO |
|---|---|---|---|
| Intel Core Ultra, serie 2 | NPU4000 | Lunar Lake (LNL) | Linux, Windows |
| Intel Core Ultra Serie 3 | NPU5010 | Panther Lake (PTL) | Linux, Windows |
Inicio rápido
1. Instala los controladores de la NPU
Consulta Configuración de la NPU en Linux o Configuración de la NPU en Windows. Omite este paso si solo necesitas la compilación AOT.
El controlador de la NPU solo es necesario en los sistemas que ejecutan el modelo en hardware de la NPU. Los sistemas de compilación AOT puros pueden omitirlo.
Nota:
ai-edge-litert-sdk-intel-nightlyfija la versión de la rueda de OpenVINO nocturna coincidente según la versión de PEP 440 (p.ej.,openvino==2026.2.0.dev20260506), por lo que pip necesita--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightlypara ubicarla. En Linux, si la detección automática de la distribución elige el archivo incorrecto, estableceLITERT_OV_OS_ID=ubuntu22oubuntu24antes depip install.
2. Crea un entorno virtual de Python
Se recomienda mantener la rueda openvino de la versión nocturna aislada de cualquier instalación de OpenVINO en todo el sistema.
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
3. Instala el paquete pip
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
El --extra-index-url permite que pip resuelva la rueda nocturna openvino fijada del índice de OpenVINO junto con los paquetes en PyPI.
4. Verifique la instalación
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
Qué verificar en el resultado:
SDK libsenumeralibopenvino_intel_npu_compiler.so(Linux) oopenvino_intel_npu_compiler.dll(Windows), que se requiere para la compilación anticipada.Available devicesincluyeNPU, lo que confirma que el controlador de la NPU está instalado y que OpenVINO puede comunicarse con el dispositivo.NPUno estará presente en los sistemas solo con AOT (en los que no se instala el controlador) ni en los sistemas sin hardware de NPU de Intel.
5. Compilación AOT (opcional)
- Precompila un
.tflitepara un destino específico de NPU de Intel (PTL o LNL) de modo que el tiempo de ejecución omita el paso del complemento del compilador. - No necesita una NPU física ni el controlador de la NPU, solo
ai-edge-litert-nightlyyai-edge-litert-sdk-intel-nightly. - Se admite la compilación cruzada: Compila en cualquier host de Linux o Windows, envía el
.tfliteresultante a un destino de cualquiera de los SOs y ejecútalo allí.
Los archivos de salida se denominan <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite.
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
6. Ejecuta la inferencia de la NPU
LiteRT admite dos rutas de inferencia en la NPU de Intel:
- JIT: Carga un
.tflitesin procesar. El complemento del compilador particiona y compila las operaciones compatibles para la NPU en el momento deCompiledModel.from_file(). Agrega algo de latencia en el primer inicio (varía según el modelo). - Compilado con AOT: Carga un
<model>_IntelOpenVINO_<SoC>_apply_plugin.tfliteproducido en el paso 4. Se salta el paso de partición y compilación en el tiempo de carga.
Este fragmento funciona para ambos casos:
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
Confirma que JIT se haya ejecutado
Cuando la compilación JIT se realiza correctamente, el registro contiene lo siguiente (la extensión de archivo es .so en Linux y .dll en Windows):
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
Si esas líneas no están presentes, pero aún se informa Fully accelerated: True, el modelo se ejecutó en la CPU de resguardo de XNNPACK, no en la NPU. Consulta la fila de solución de problemas de JIT.
7. Comparativa
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
Marcas comunes:
| Marcar | Valor predeterminado | Descripción |
|---|---|---|
--model PATH
|
— | Ruta de acceso al modelo .tflite (obligatorio). |
--signature KEY |
primera | Es la clave de firma que se ejecutará. |
--use_cpu/--no_cpu
|
el | Activa o desactiva el acelerador de CPU o la CPU de resguardo. |
--use_gpu |
desactivada | Habilita el acelerador de GPU. |
--use_npu |
desactivada | Habilita el acelerador de NPU de Intel. |
--require_full_delegation
|
desactivada | Falla si el modelo no se descarga por completo en el acelerador seleccionado. |
--num_runs N
|
50 | Cantidad de iteraciones de inferencia cronometradas. |
--warmup_runs N
|
5 | Iteraciones de calentamiento sin límite de tiempo antes de la medición. |
--num_threads N |
1 | Recuento de subprocesos de la CPU. |
--result_json PATH
|
— | Escribe un resumen en formato JSON (estadísticas de latencia, capacidad de procesamiento, lista de aceleradores). |
--verbose |
desactivada | Registro adicional del entorno de ejecución. |
Marcas avanzadas o de anulación: Solo se necesitan para apuntar a compilaciones personalizadas: --dispatch_library_path, --compiler_plugin_path, --runtime_path.
Ruedas de varios proveedores: Fijación de JIT en Intel OV
Nota: Cuando se llama a
Environment.create()sin rutas explícitas, se detectan automáticamente los proveedores enai_edge_litert/vendors/en orden alfabético y se registra el primero que se encuentra. En una instalación de varios proveedores, es posible que no sea Intel OV. Pasa los directorios de Intel OV de forma explícita para forzar la selección correcta.
- La rueda de pip incluye complementos del compilador para cada proveedor registrado (
intel_openvino/,google_tensor/,mediatek/,qualcomm/,samsung/). - Para forzar la ruta de Intel OV (se recomienda cuando hay varios SDKs de proveedores instalados), pasa los directorios de Intel OV de forma manual:
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
El entorno de ejecución carga cada biblioteca compartida que encuentra en el directorio determinado, por lo que apuntar a vendors/intel_openvino/compiler/ carga solo el complemento de Intel; los complementos de Google Tensor, MediaTek, Qualcomm y Samsung en directorios hermanos nunca se tocan.
En la CLI, las marcas equivalentes son las siguientes:
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
Verifica la ejecución de la NPU
Para confirmar que el modelo se ejecutó en la NPU, verifica ambos indicadores:
- El registro contiene
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}, lo que indica que se cargó la biblioteca de envío de Intel (.soen Linux y.dllen Windows). model.is_fully_accelerated()devuelveTrue: Cada operación se descargó en el acelerador seleccionado.
is_fully_accelerated() por sí solo no es suficiente: Si la biblioteca de envío nunca se cargó, las operaciones se descargaron por completo en XNNPACK/CPU, no en la NPU.
Configuración de NPU en Linux
Nota: Omite esta sección si solo necesitas AOT, ya que no se requiere una NPU física.
Info: Usa el controlador de NPU v1.32.1 (vinculado con OpenVINO 2026.1). Los controladores más antiguos fallan con
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE.
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
Luego, ejecuta el fragmento de código de instalación y verificación desde Inicio rápido.
Configuración de la NPU de Windows
Nota: Omite esta sección si solo necesitas AOT, ya que no se requiere una NPU física.
- Instala el controlador de la NPU de Intel (32.0.100.4724+) desde el Centro de descargas de Intel.
- Verifica que el Administrador de dispositivos muestre el dispositivo de la NPU en Procesadores neuronales (se muestra como
Intel(R) AI BoostoIntel(R) NPUsegún el controlador). - Ejecuta el fragmento de instalación y verificación desde Inicio rápido, reemplazando
pipporpython -m pip.
Nota:
import ai_edge_litertregistra automáticamente los directorios de DLL conos.add_dll_directory(), por lo que las secuencias de comandos de Python no necesitan configuración dePATH. Para los consumidores que no usan Python, ejecutasetupvars.bato antepone<openvino>/libsaPATH.
Compila desde el origen
¿Estás detrás de un proxy? Exporta
http_proxy/https_proxy/no_proxyantes de ejecutar las secuencias de comandos de compilación, ya que las reenvían a Docker y al contenedor.
Linux (Docker, hermético):
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
Windows (PowerShell, Bazel en PATH):
.\ci\build_pip_package_with_bazel_windows.ps1
Los resultados se publican en dist/:
ai_edge_litert-*.whl: Es la rueda de tiempo de ejecución.ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz: Es el proveedor de sdists.- El sdist de Intel es de aproximadamente 5 KB; el compilador de la NPU
.so/.dllse recupera en el momento depip install, por lo que el mismo sdist funciona en Linux y Windows.
Pruebas de unidades
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
Solución de problemas
| Problema | Corregir |
|---|---|
Falla de AOT: Device with "NPU" name is not registered |
No se recuperó el compilador de la NPU. Revisa las listas ai_edge_litert_sdk_intel.path_to_sdk_libs() libopenvino_intel_npu_compiler.so / .dll. Si está vacío, reinstala con acceso a la red o configura LITERT_OV_OS_ID=ubuntu22/ubuntu24. |
La compilación JIT se ejecuta en la CPU en lugar de la NPU (no hay registro de Partitioned subgraph ni de Loaded plugin, pero sí se imprime Fully accelerated: True). |
No se descubrió el complemento del compilador. Confirma que ov.get_compiler_plugin_dir() devuelve una ruta de acceso en ai_edge_litert/vendors/intel_openvino/compiler/. Si hay varios SDKs de proveedores instalados, pasa compiler_plugin_path=ov.get_compiler_plugin_dir() de forma explícita a Environment.create() (o --compiler_plugin_path=... a litert-benchmark). |
Falla de JIT: Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so (Linux) o openvino_intel_npu_compiler.dll (Windows) |
El sdist del SDK copia el compilador de la NPU en openvino/libs/ en el primer import ai_edge_litert_sdk_intel. Si se omitió la copia (FS de solo lectura, falta openvino), reinstala ai-edge-litert-sdk-intel después de que se instale openvino y, luego, import ai_edge_litert en un proceso nuevo. |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE |
Se actualizó el controlador de la NPU a la versión 1.32.1 (Linux). |
No se encontró /dev/accel/accel0 |
sudo dmesg | grep -i vpu para depurar el controlador; reinicia después de la instalación. |
| Permiso denegado en la NPU | sudo gpasswd -a ${USER} render && newgrp render. |
| Windows: La NPU no aparece en el Administrador de dispositivos | Instala el controlador de la NPU 32.0.100.4724+ desde el Centro de descargas de Intel. |
Windows: Failed to initialize Dispatch API o faltan DLL |
Asegúrate de que import ai_edge_litert se ejecute primero (registra automáticamente los directorios de DLL); para los llamadores que no son de Python, ejecuta setupvars.bat o antepone <openvino>/libs a PATH. |
Compilación de Windows: LNK2001 fixed_address_empty_string, C2491 dllimport, Python 3.12+ fails |
Restricción de ABI de Protobuf / versión de Python: Consulta ci/build_pip_package_with_bazel_windows.ps1. Las compilaciones de Windows requieren Python 3.11. |
Limitaciones
Solo se admite el dispositivo NPU a través de la ruta de envío de OpenVINO. Para la inferencia en la CPU, usa solo HardwareAccelerator.CPU (XNNPACK).
API de C++
Requisitos previos y configuración de la compilación
Requisitos previos de compilación:
- Visual Studio 2022 o una versión posterior (se deben instalar las herramientas de desarrollo de C++).
- git: Instala git desde https://git-scm.com/install/. Asegúrate de que
C:\Program Files\Git\bin and C:\Program Files\Git\cmdse incluya en la variable de entorno PATH del sistema para permitir que los procesos de compilación de LiteRT/LiteRT-LM ubiquen bash.exe y git.exe. - bazelisk: Instala bazelisk y agrega su ubicación a la variable de entorno
PATHde tu sistema: https://bazel.build/install/bazelisk. - Cmake: Instala la versión 4.3.0 o una posterior de Cmake desde https://cmake.org/download/ y verifica que Cmake esté incluido en la ruta de acceso del sistema.
- Python: Asegúrate de que Python 3.11 o una versión posterior esté instalado y de que python.exe esté en tu PATH.
- Configuración de Windows: Habilita el modo de desarrollador en la configuración de Windows.
Compila herramientas y complementos de LiteRT para la NPU de Intel
Para ejecutar modelos en la NPU de Intel con LiteRT, deben compilarse con el complemento del compilador de Intel OpenVINO de LiteRT. Además, cualquier modelo compilado que se pretenda ejecutar en la NPU de Intel debe delegarse en el complemento de envío de Intel OpenVINO de LiteRT.
A continuación, se ilustra el mecanismo por el que LiteRT invoca estos complementos:
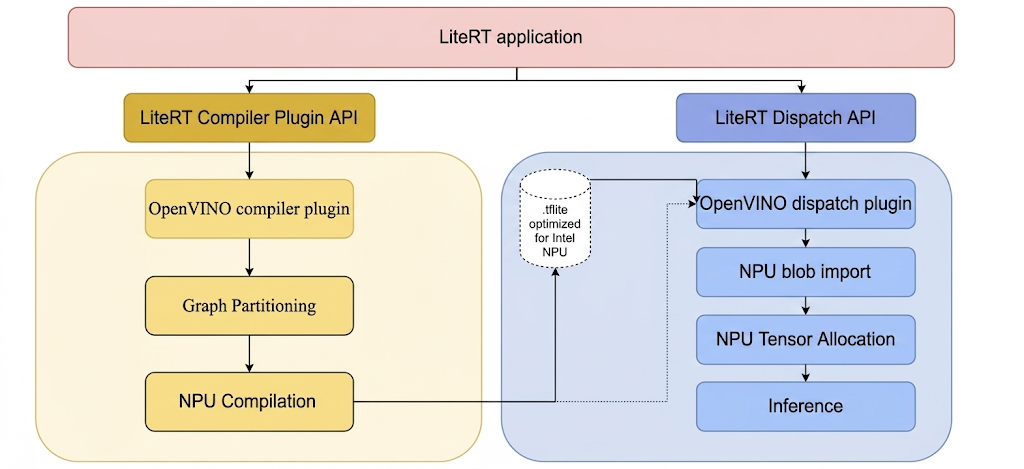
Pasos para compilar las herramientas de LiteRT y los complementos de Intel.
Antes de compilar cualquier biblioteca o ejecutable desde LiteRT, crea un directorio local, por ejemplo, C:\bzl. El objeto binario de salida de la compilación se recopilará de este directorio. Compila el complemento de envío de Intel OpenVINO
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Como alternativa, también puedes compilar el complemento de envío desde el repositorio de LiteRT-LM agregando un prefijo @litert en el destino. Esto es similar para todos los objetivos siguientes del repositorio de LiteRT.
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Compila el complemento del compilador de Intel OpenVINO
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
Utilidad del compilador Ahead-of-Time (AOT) de LiteRT Algunas herramientas de LiteRT requieren la compilación AOT explícita de los modelos antes de ejecutarlos en la NPU de Intel. Instrucciones de compilación de la utilidad del compilador AOT de LiteRT:
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
Compila el ejecutor del modelo de LiteRT. El ejecutor del modelo de LiteRT se puede usar para ejecutar un modelo en la NPU de Intel, ya sea un modelo no compilado previamente o un modelo compilado con AOT. Instrucción para compilar el ejecutor del modelo:
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
Compila la utilidad del modelo de comparativa de LiteRT. Se puede usar la herramienta de comparativa del modelo de LiteRT para comparar el rendimiento de la inferencia de un modelo en la NPU de Intel. Si se dan instrucciones para compilar la herramienta de comparativas, haz lo siguiente:
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
Crea la utilidad de verificación numérica de LiteRT
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
Uso avanzado: Compila con el SDK de Intel OpenVINO personalizado
El sistema de compilación de LiteRT recupera automáticamente el SDK de Intel OpenVINO precompilado cuando compila los complementos de compilador y de envío.
Si tu proyecto requiere una versión específica o personalizada del SDK de Intel OpenVINO, completa estos pasos de configuración adicionales antes de comenzar la compilación del complemento:
- Descarga el objeto binario de la versión más reciente de OpenVINO para Windows desde https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html y extráelo en el disco local, por ejemplo,
C:\Intel\intel_openvino. - Asegúrate de que el único directorio secundario en esta ruta se llame "openvino" y contenga subdirectorios como "runtime" y "include".
- Ve al directorio raíz del repositorio clonado de LiteRT en tu consola (símbolo del sistema o PowerShell) y establece la variable OPENVINO_NATIVE_DIR (asegúrate de que no haya un
\`), for example:al final de set OPENVINO_NATIVE_DIR=C:\Intel\intel_openvino`).
Compilación AOT de modelos personalizados
En esta sección, se prepara el entorno y se realiza la compilación AOT de modelos personalizados de TFLite, PyTorch o JAX para LiteRT.
Durante el proceso de compilación del modelo para la NPU de Intel, LiteRT valida el grafo del modelo en función de los operadores compatibles con el complemento del compilador de Intel OpenVINO de LiteRT. En el caso de los operadores o subgrafos que son compatibles con el complemento del compilador, LiteRT compila cada uno de esos subgrafos en un DISPATCH_OP que, posteriormente, reemplaza el subgrafo original dentro del grafo. Los operadores que no se incluyen en el conjunto de operadores admitido por el compilador de Intel OpenVINO permanecen sin cambios en el gráfico. Por lo tanto, la compilación AOT puede generar un modelo completamente delegado o parcialmente delegado. Este es un ejemplo de un modelo compilado con AOT completamente delegado:
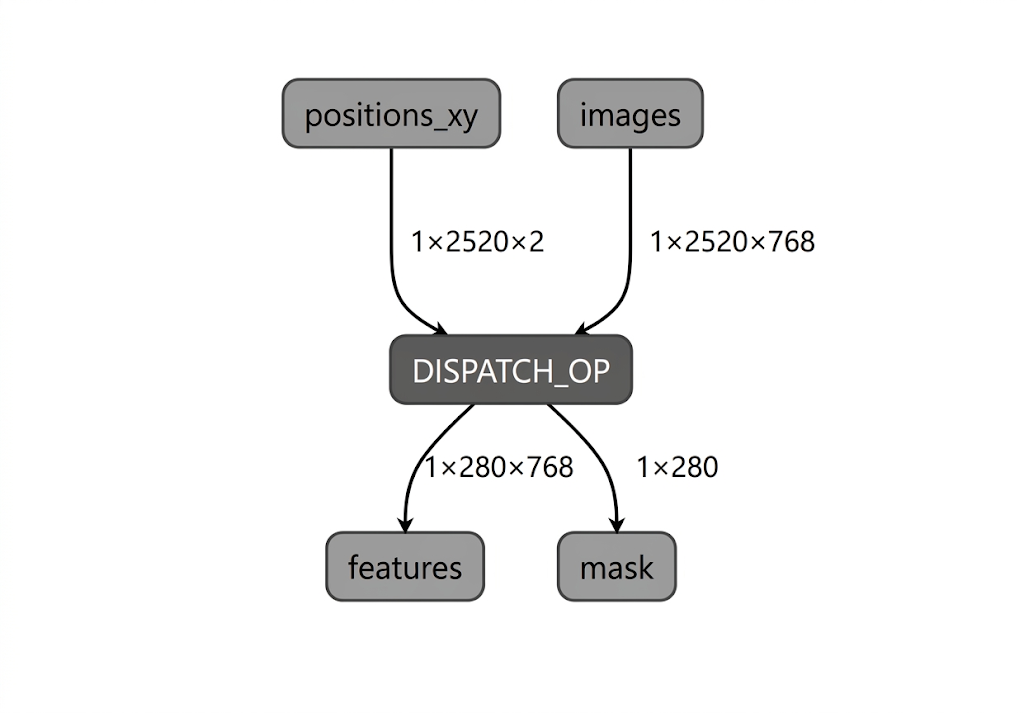
La utilidad apply_plugin_main de LiteRT (apply_plugin_main.exe) es la utilidad de compilación AOT que puedes usar para este propósito. Ejemplo de uso de la utilidad en la plataforma Intel:
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
Ten en cuenta que el compilador de NPU subyacente predeterminado, que se incluye en la distribución binaria del SDK de Intel OpenVINO, se utiliza para la serie 2 de Intel Core Ultra y los SoC posteriores. Si se compila un modelo para una NPU que no está en la lista de dispositivos compatibles, se debe especificar de forma explícita el tipo de compilador (aunque esto sigue siendo opcional para Intel Core Ultra 2 y versiones posteriores).
set IE_NPU_COMPILER_TYPE=PLUGIN
Compilación JIT vs. AOT en tu aplicación
Para compilar modelos en tu propia aplicación de LiteRT, existen dos enfoques: la compilación AOT que ya presentamos y la compilación Just-in-time (JIT).
Con la compilación AOT, el modelo se compila sin conexión antes de la implementación y se puede guardar para su uso posterior, lo que es de uso frecuente cuando la compilación requiere demasiados recursos para ejecutarse integrado en el dispositivo. No es necesario que lo hagas en el mismo dispositivo en el que implementarás el modelo. A continuación, se muestra un ejemplo de compilación AOT en tu código:
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
Así se realiza la inferencia con un modelo compilado con AOT:
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
El enfoque alternativo es compilar el modelo con JIT en el tiempo de ejecución en el dispositivo. Es más flexible: solo requiere un archivo de modelo independiente del backend.
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
Comparativas con benchmark_model
La utilidad benchmark_model de LiteRT (benchmark_model.exe) está diseñada específicamente para realizar comparativas de un modelo compilado con AOT en la NPU y se puede usar para comparar el rendimiento con el backend de CPU (XNNPack) en LiteRT. Comando de ejemplo para comparar el rendimiento de un modelo compilado con AOT en una NPU de Intel:
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
Verificación de precisión con npu_numerics_check
La utilidad npu_numerics_check se usa para verificar la precisión numérica de un modelo compilado para la NPU en comparación con un modelo de referencia (por lo general, el backend de CPU, XNNPack). Este paso es fundamental para garantizar que la delegación en la NPU no introduzca desviaciones numéricas inaceptables que puedan afectar la calidad del modelo.
Ejecuta la verificación numérica. La utilidad requiere el modelo compilado con AOT y compara sus resultados con los del modelo original no delegado que se ejecuta en la CPU.
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
Próximos pasos
- Comienza con la guía de NPU unificada: Aceleración de NPU con LiteRT
- Sigue los pasos de conversión y la implementación que se indican allí, y elige Qualcomm cuando corresponda.
- Para los LLM, consulta Ejecuta LLM en la NPU con LiteRT-LM.