
LiteRT از طریق رابط برنامهنویسی کاربردی CompiledModel از Intel OpenVino برای AOT و کامپایل روی دستگاه پشتیبانی میکند.
رابط برنامهنویسی پایتون
محیط توسعه را تنظیم کنید
لینوکس (x86_64):
- اوبونتو ۲۲.۰۴ یا ۲۴.۰۴ LTS
- پایتون ۳.۱۰+ - از python.org یا توزیع مورد نظر خود نصب کنید (
sudo apt install python3 python3-venv) - درایور NPU اینتل نسخه ۱.۳۲.۱ - به تنظیمات NPU لینوکس مراجعه کنید
ویندوز (x86_64):
- ویندوز ۱۰ یا ۱۱
- پایتون ۳.۱۰+ - نصب از python.org
- درایور NPU اینتل نسخه ۳۲.۰.۱۰۰.۴۷۲۴+ - به تنظیمات NPU ویندوز مراجعه کنید
برای ساخت از منبع، Bazel 7.4.1+ با استفاده از Bazelisk یا نسخه هرمتیک Docker نیز مورد نیاز است.
SoC های پشتیبانی شده
| پلتفرم | ان پی یو | نام رمز | سیستم عامل |
|---|---|---|---|
| اینتل کور اولترا سری ۲ | NPU4000 | دریاچه قمری (LNL) | لینوکس، ویندوز |
| اینتل کور اولترا سری ۳ | NPU5010 | دریاچه پلنگ (PTL) | لینوکس، ویندوز |
شروع سریع
۱. درایورهای NPU را نصب کنید
به بخش تنظیمات NPU لینوکس یا تنظیمات NPU ویندوز مراجعه کنید. اگر فقط به AOT نیاز دارید، از این مرحله صرف نظر کنید.
درایور NPU فقط در سیستمهایی که مدل را روی سختافزار NPU اجرا میکنند مورد نیاز است. سیستمهایی که صرفاً از AOT-build استفاده میکنند میتوانند از آن صرف نظر کنند.
توجه:
ai-edge-litert-sdk-intel-nightlyچرخ شبانه OpenVINO مطابق با نسخه PEP 440 (مثلاًopenvino==2026.2.0.dev20260506) را پین میکند، بنابراین pip برای یافتن آن--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightlyنیاز دارد. در لینوکس، اگر تشخیص خودکار توزیع، بایگانی اشتباه را انتخاب کرد، قبل ازpip install،LITERT_OV_OS_ID=ubuntu22یاubuntu24را تنظیم کنید.
۲. ایجاد یک محیط مجازی پایتون
توصیه میشود چرخ شبانه openvino را از هرگونه نصب OpenVINO در کل سیستم جدا نگه دارید.
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
۳. بسته pip را نصب کنید
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
دستور --extra-index-url به pip اجازه میدهد تا چرخ شبانهی پینشدهی openvino را از فهرست OpenVINO در کنار بستههای موجود در PyPI شناسایی کند.
۴. تأیید نصب
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
چه مواردی را در خروجی بررسی کنیم:
-
SDK libslibopenvino_intel_npu_compiler.so(لینوکس) یاopenvino_intel_npu_compiler.dll(ویندوز) را فهرست میکنند - که برای AOT مورد نیاز است. -
Available devicesشاملNPUهستند - تأیید میکند که درایور NPU نصب شده است و OpenVINO میتواند با دستگاه ارتباط برقرار کند.NPUدر سیستمهای فقط AOT (که درایور نصب نشده است) و در سیستمهای بدون سختافزار Intel NPU وجود نخواهد داشت.
۵. کامپایل AOT (اختیاری)
- یک فایل
.tfliteرا برای یک هدف خاص Intel NPU (PTL یا LNL) از قبل کامپایل میکند، بنابراین زمان اجرا از مرحله افزونه کامپایلر صرف نظر میکند. - به واحد پردازش عصبی فیزیکی یا درایور NPU نیاز ندارد — فقط به
ai-edge-litert-nightlyوai-edge-litert-sdk-intel-nightlyنیاز دارد. - کامپایل متقابل پشتیبانی میشود: روی هر میزبان لینوکس یا ویندوز کامپایل کنید، فایل
.tfliteحاصل را به مقصد هر یک از سیستم عاملها ارسال کنید و آن را در آنجا اجرا کنید.
فایلهای خروجی با نام <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite نامگذاری شدهاند.
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
۶. اجرای استنتاج NPU
LiteRT از دو مسیر استنتاج در واحد پردازش عصبی اینتل (NPU) پشتیبانی میکند:
- JIT — یک فایل خام
.tfliteرا بارگذاری میکند؛ افزونه کامپایلر، عملیات پشتیبانیشده برای NPU را در زمانCompiledModel.from_file()پارتیشنبندی و کامپایل میکند. مقداری تأخیر در اولین اجرا اضافه میکند (بسته به مدل متفاوت است). - کامپایل شده با AOT — یک
<model>_IntelOpenVINO_<SoC>_apply_plugin.tfliteتولید شده توسط مرحله ۴ را بارگذاری میکند. در زمان بارگذاری، مرحله پارتیشنبندی و کامپایل را رد میکند.
این قطعه کد برای هر دو کار میکند:
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
تأیید کنید که JIT واقعاً اجرا شده است
وقتی JIT با موفقیت اجرا شود، فایل گزارش شامل موارد زیر است (پسوند فایل در لینوکس .so و در ویندوز .dll است):
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
اگر آن خطوط وجود ندارند اما Fully accelerated: True ، مدل روی CPU fallback XNNPACK اجرا شده است، نه روی NPU — به ردیف عیبیابی JIT مراجعه کنید.
۷. معیار
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
پرچمهای رایج:
| پرچم | پیشفرض | توضیحات |
|---|---|---|
--model PATH | — | مسیر مدل .tflite (الزامی). |
--signature KEY | اول | کلید امضا برای اجرا. |
--use_cpu / --no_cpu | روی | شتابدهنده CPU / پشتیبان CPU را تغییر دهید. |
--use_gpu | خاموش | شتابدهندهی پردازندهی گرافیکی (GPU) را فعال کنید. |
--use_npu | خاموش | شتابدهندهی NPU اینتل را فعال کنید. |
--require_full_delegation | خاموش | اگر مدل به طور کامل به شتابدهنده انتخابشده منتقل نشده باشد، با شکست مواجه میشود. |
--num_runs N | ۵۰ | تعداد تکرارهای استنتاج زمانبندیشده. |
--warmup_runs N | ۵ | تکرارهای گرم کردن بدون زمان قبل از اندازهگیری. |
--num_threads N | ۱ | تعداد رشتههای پردازنده (Threads) |
--result_json PATH | — | خلاصهای از JSON بنویسید (آمار تأخیر، توان عملیاتی، فهرست شتابدهنده). |
--verbose | خاموش | ثبت وقایع اضافی در زمان اجرا. |
پرچمهای پیشرفته / لغو - فقط برای اشاره به ساختهای سفارشی مورد نیاز هستند: --dispatch_library_path ، --compiler_plugin_path ، --runtime_path .
چرخهای چندفروشندهای: اتصال JIT به Intel OV
نکته: وقتی
Environment.create()بدون مسیرهای صریح فراخوانی میشود، به طور خودکار فروشندگان را درai_edge_litert/vendors/به ترتیب حروف الفبا کشف میکند و اولین موردی را که پیدا میکند ثبت میکند. در یک نصب با فروشندگان مختلف، این ممکن است Intel OV نباشد - دایرکتوریهای Intel OV را به صراحت ارسال کنید تا انتخاب صحیح را اعمال کند.
- pip wheel افزونههای کامپایلر را برای هر فروشنده ثبتشده (
intel_openvino/،google_tensor/،mediatek/،qualcomm/،samsung/) ارائه میدهد. - برای اعمال مسیر Intel OV (که در صورت نصب چندین SDK از فروشندگان مختلف توصیه میشود)، دایرکتوریهای Intel OV را به صورت دستی وارد کنید:
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
زمان اجرا هر کتابخانه اشتراکی را که در دایرکتوری داده شده پیدا کند، بارگذاری میکند، بنابراین اشاره به vendors/intel_openvino/compiler/ فقط افزونه اینتل را بارگذاری میکند؛ افزونههای Google Tensor / MediaTek / Qualcomm / Samsung که در دایرکتوریهای خواهر و برادر قرار دارند، هرگز دستکاری نمیشوند.
برای CLI، پرچمهای معادل عبارتند از:
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
تأیید اجرای NPU
برای تأیید اینکه مدل واقعاً روی NPU اجرا شده است، هر دو سیگنال را بررسی کنید:
- این گزارش شامل
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}است - کتابخانه اعزام اینتل بارگذاری شده است (.soدر لینوکس،.dllدر ویندوز). -
model.is_fully_accelerated()Trueرا برمیگرداند - هر عملیات به شتابدهنده انتخاب شده منتقل شد.
is_fully_accelerated() به تنهایی کافی نیست : اگر کتابخانه dispatch هرگز بارگذاری نشود، عملیاتها به طور کامل به XNNPACK/CPU منتقل میشوند، نه به NPU.
راهاندازی NPU لینوکس
توجه: اگر فقط به AOT نیاز دارید، از این بخش صرف نظر کنید - NPU فیزیکی لازم نیست.
اطلاعات: از درایور NPU نسخه ۱.۳۲.۱ (همراه با OpenVINO 2026.1) استفاده کنید. درایورهای قدیمیتر با
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATUREمواجه میشوند.
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
سپس قطعه کد install + verify را از Quick Start اجرا کنید.
تنظیمات NPU ویندوز
توجه: اگر فقط به AOT نیاز دارید، از این بخش صرف نظر کنید - NPU فیزیکی لازم نیست.
- درایور Intel NPU ( نسخه 32.0.100.4724+ ) را از مرکز دانلود اینتل نصب کنید.
- تأیید کنید که مدیر دستگاه، دستگاه NPU را در زیر پردازندههای عصبی (Neural processors) فهرست میکند (که بسته به درایور، با عنوان
Intel(R) AI BoostیاIntel(R) NPUنشان داده میشود). - قطعه کد install + verify را از Quick Start اجرا کنید و
pipباpython -m pipجایگزین کنید.
اطلاعات:
import ai_edge_litertدایرکتوریهای DLL ثبت خودکار را با استفاده ازos.add_dll_directory()وارد میکند، بنابراین اسکریپتهای پایتون نیازی به تنظیمPATHندارند. برای مصرفکنندگان غیر پایتون،setupvars.batرا اجرا کنید یا<openvino>/libsرا بهPATHاضافه کنید.
ساخت از منبع
پشت یک پروکسی؟ قبل از اجرای اسکریپتهای ساخت،
http_proxy/https_proxy/no_proxyرا صادر کنید - آنها این اسکریپتها را به داکر و کانتینر ارسال میکنند.
لینوکس (داکر، هرمتیک):
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
ویندوز (PowerShell، Bazel در PATH):
.\ci\build_pip_package_with_bazel_windows.ps1
خروجیها در dist/ قرار میگیرند:
-
ai_edge_litert-*.whl— چرخ زمان اجرا. -
ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz— فروشنده sdists. - sdist اینتل حدود ۵ کیلوبایت است؛ کامپایلر NPU
.so/.dllدر زمانpip installفراخوانی میشود، بنابراین sdist یکسانی روی لینوکس و ویندوز کار میکند.
تستهای واحد
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
عیبیابی
| مسئله | رفع |
|---|---|
خطای AOT: Device with "NPU" name is not registered | کامپایلر NPU دریافت نشد. لیستهای ai_edge_litert_sdk_intel.path_to_sdk_libs() libopenvino_intel_npu_compiler.so / .dll را در ai_edge_litert_sdk_intel.path_to_sdk_libs() بررسی کنید. اگر خالی بود، با دسترسی به شبکه دوباره نصب کنید، یا LITERT_OV_OS_ID=ubuntu22 / ubuntu24 را تنظیم کنید. |
JIT به جای NPU روی CPU اجرا میشود (بدون لاگ Partitioned subgraph ، بدون لاگ Loaded plugin ، Fully accelerated: True هنوز هم چاپ میشود) | افزونه کامپایلر پیدا نشد. تأیید کنید که ov.get_compiler_plugin_dir() مسیری را در زیر ai_edge_litert/vendors/intel_openvino/compiler/ برمیگرداند. اگر چندین SDK فروشنده نصب شده است، compiler_plugin_path=ov.get_compiler_plugin_dir() را صریحاً به Environment.create() (یا --compiler_plugin_path=... به litert-benchmark ) ارسال کنید. |
JIT با خطا مواجه میشود: Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so (لینوکس) / openvino_intel_npu_compiler.dll (ویندوز) | SDK sdist با اولین import ai_edge_litert_sdk_intel ، کامپایلر NPU را در openvino/libs/ کپی میکند. اگر این کپی نادیده گرفته شده باشد (فایل سیستم فقط خواندنی باشد، openvino وجود نداشته باشد)، ai-edge-litert-sdk-intel را پس از نصب openvino دوباره نصب کنید، سپس import ai_edge_litert . |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE | درایور NPU را به نسخه ۱.۳۲.۱ (لینوکس) ارتقا دهید. |
/dev/accel/accel0 پیدا نشد | sudo dmesg | grep -i vpu برای اشکالزدایی درایور؛ پس از نصب، سیستم را مجدداً راهاندازی کنید. |
| مجوز برای NPU رد شد | sudo gpasswd -a ${USER} render && newgrp render . |
| ویندوز: NPU در Device Manager نیست | درایور NPU نسخه ۳۲.۰.۱۰۰.۴۷۲۴+ را از مرکز دانلود اینتل نصب کنید. |
ویندوز: Failed to initialize Dispatch API / DLL ها از دست رفته اند | مطمئن شوید که import ai_edge_litert ابتدا اجرا میشود (فایلهای DLL را به صورت خودکار ثبت میکند)؛ برای فراخوانیکنندههای غیر پایتون، setupvars.bat را اجرا کنید یا <openvino>/libs را به PATH اضافه کنید. |
نسخه ویندوز: LNK2001 fixed_address_empty_string ، C2491 dllimport ، Python 3.12+ fails | محدودیت نسخه Protobuf ABI / Python — به ci/build_pip_package_with_bazel_windows.ps1 مراجعه کنید؛ نسخههای ویندوز به پایتون ۳.۱۱ نیاز دارند. |
محدودیتها
فقط دستگاه NPU از طریق مسیر ارسال OpenVINO پشتیبانی میشود. برای استنتاج CPU، فقط از HardwareAccelerator.CPU (XNNPACK) استفاده کنید.
رابط برنامهنویسی کاربردی سیپلاسپلاس
پیشنیازها و تنظیمات ساخت
پیشنیازهای ساخت:
- ویژوال استودیو ۲۰۲۲ یا بالاتر (ابزارهای توسعه ++C باید نصب شده باشند).
- git: گیت را از https://git-scm.com/install/ نصب کنید. مطمئن شوید که
C:\Program Files\Git\bin and C:\Program Files\Git\cmdدر متغیر محیطی PATH سیستم شما گنجانده شدهاند تا به bash.exe و git.exe اجازه داده شود تا توسط فرآیندهای ساخت LiteRT/LiteRT-LM پیدا شوند. - bazelisk: bazelisk را نصب کنید و مکان آن را در متغیر محیطی
PATHسیستم خود قرار دهید: https://bazel.build/install/bazelisk. - Cmake: نسخه ۴.۳.۰ یا بالاتر Cmake را از https://cmake.org/download/ نصب کنید و مطمئن شوید که Cmake در PATH سیستم شما موجود است.
- پایتون: مطمئن شوید که پایتون ۳.۱۱ یا بالاتر نصب شده است و فایل python.exe در مسیر (PATH) شما قرار دارد.
- تنظیمات ویندوز: حالت توسعهدهنده را در تنظیمات ویندوز فعال کنید.
ساخت ابزارها و افزونههای LiteRT برای Intel NPU
برای اجرای مدلها روی Intel NPU با LiteRT، لازم است که آنها با استفاده از افزونه کامپایلر LiteRT Intel OpenVINO کامپایل شوند؛ علاوه بر این، هر مدل کامپایل شدهای که برای اجرا روی Intel NPU در نظر گرفته شده است، باید به افزونه ارسال LiteRT Intel OpenVINO واگذار شود.
مکانیسمی که LiteRT از طریق آن این افزونهها را فراخوانی میکند، متعاقباً نشان داده شده است:
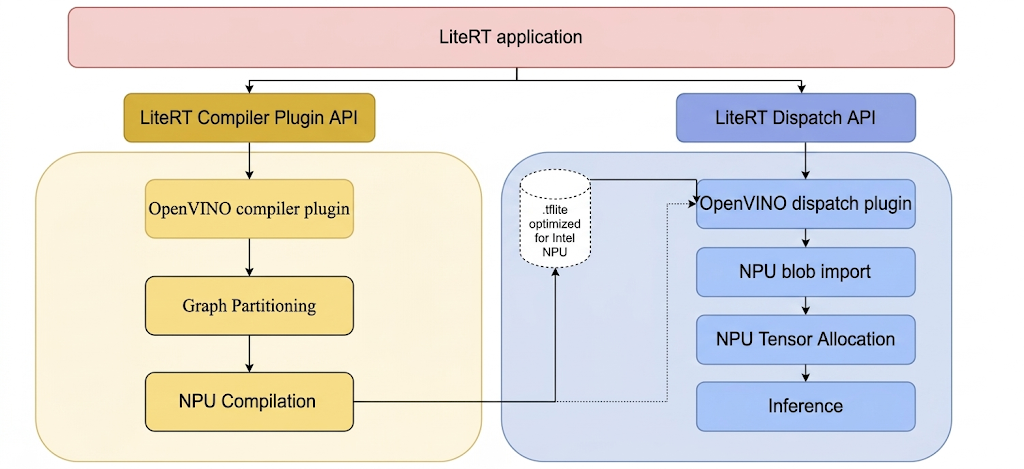
مراحل ساخت ابزارهای LiteRT و افزونههای Intel.
قبل از ساخت هرگونه فایل اجرایی یا کتابخانهای از LiteRT، یک دایرکتوری محلی، مثلاً C:\bzl، ایجاد کنید. فایل باینری خروجی ساخت از این دایرکتوری جمعآوری خواهد شد. افزونهی اعزام Intel OpenVINO را بسازید.
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
به عنوان یک روش جایگزین، میتوانید افزونه dispatch را از مخزن LiteRT-LM با اضافه کردن پیشوند @litert به هدف، بسازید. این روش برای همه اهداف زیر از مخزن LiteRT مشابه است.
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
ساخت افزونه کامپایلر Intel OpenVINO
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
ابزار کامپایلر LiteRT Ahead-of-Time (AOT) را بسازید. برخی از ابزارهای LiteRT قبل از اجرای مدلها روی Intel NPU، نیاز به کامپایل صریح AOT دارند. دستورالعمل ساخت ابزار کامپایلر LiteRT AOT:
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
ساخت اجراکننده مدل LiteRT اجراکننده مدل LiteRT میتواند برای اجرای یک مدل روی Intel NPU، چه مدل از پیش کامپایل نشده و چه مدل کامپایل شده با AOT، استفاده شود. دستورالعمل ساخت اجراکننده مدل:
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
ابزار ساخت مدل بنچمارک LiteRT ابزار بنچمارک مدل LiteRT میتواند برای سنجش عملکرد استنتاج یک مدل روی Intel NPU استفاده شود. اگر دستورالعمل ساخت ابزار بنچمارک:
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
ساخت ابزار بررسی عددی LiteRT
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
استفاده پیشرفته: با Intel OpenVINO SDK سفارشی ساخته شده است
سیستم ساخت LiteRT هنگام کامپایل کامپایلر و ارسال افزونهها، Intel OpenVINO SDK از پیش ساخته شده را به طور خودکار دریافت میکند.
اگر پروژه شما به نسخهای خاص یا سفارشی از Intel OpenVINO SDK نیاز دارد، قبل از شروع ساخت افزونه، این مراحل پیکربندی اضافی را انجام دهید:
- آخرین نسخه باینری OpenVINO برای ویندوز را از https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html دانلود کنید و آن را در دیسک محلی، مثلاً
C:\Intel\intel_openvino، استخراج کنید. - مطمئن شوید که تنها دایرکتوری فرزند در این مسیر «openvino» نام دارد و شامل زیرشاخههایی مانند «runtime» و «include» نیز میشود.
- به دایرکتوری ریشه مخزن LiteRT کلون شده در کنسول خود (خط فرمان یا PowerShell) بروید و متغیر OPENVINO_NATIVE_DIR را تنظیم کنید (مطمئن شوید که هیچ
\`), for example:set OPENVINO_NATIVE_DIR=C:\Intel\intel_openvino`
گردآوری AOT از مدلهای سفارشی
این بخش محیط را آماده میکند و کامپایل AOT مدلهای سفارشی TFLite، PyTorch یا JAX را برای LiteRT انجام میدهد.
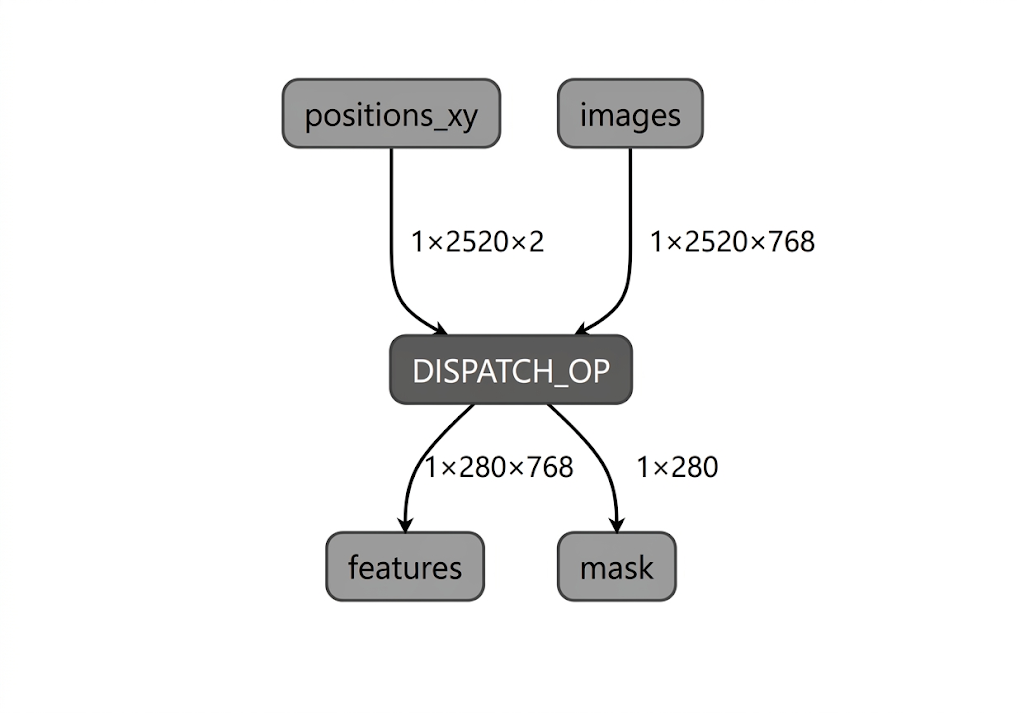
در طول فرآیند کامپایل مدل برای Intel NPU، LiteRT گراف مدل را در برابر عملگرهای پشتیبانی شده توسط افزونه کامپایلر LiteRT Intel OpenVINO اعتبارسنجی میکند. برای عملگرها یا زیرگرافهایی که با افزونه کامپایلر سازگار هستند، LiteRT هر زیرگراف را در یک DISPATCH_OP کامپایل میکند که متعاقباً جایگزین زیرگراف اصلی در گراف میشود. عملگرهایی که در مجموعه پشتیبانی شده توسط کامپایلر Intel OpenVINO گنجانده نشدهاند، در گراف بدون تغییر باقی میمانند. در نتیجه، کامپایل AOT ممکن است یک مدل کاملاً تفویض شده یا جزئی تفویض شده را ارائه دهد. در اینجا مثالی از مدل کامپایل شده AOT کاملاً تفویض شده آورده شده است:
ابزار LiteRT apply_plugin_main (apply_plugin_main.exe) یک ابزار کامپایل AOT است که میتوانید برای این منظور از آن استفاده کنید. نمونهای از کاربرد این ابزار در پلتفرم اینتل:
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
لطفاً توجه داشته باشید که کامپایلر NPU پیشفرض که در توزیع باینری Intel OpenVINO SDK گنجانده شده است، برای Intel Core Ultra Series 2 و SoC های بعدی استفاده میشود. اگر مدلی برای NPU که در لیست پشتیبانی شده نیست کامپایل میشود، نوع کامپایلر باید صریحاً مشخص شود (اگرچه این مورد برای Intel Core Ultra 2 و بالاتر اختیاری است).
set IE_NPU_COMPILER_TYPE=PLUGIN
کامپایل JIT در مقابل AOT در برنامه شما
برای کامپایل مدلها در برنامه LiteRT خودتان، دو رویکرد وجود دارد: کامپایل AOT که قبلاً معرفی کردیم، و کامپایل Just-in-time (JIT).
با کامپایل AOT، این حالت قبل از استقرار به صورت آفلاین کامپایل میشود و میتواند برای استفاده بعدی ذخیره شود - معمولاً زمانی استفاده میشود که کامپایل برای اجرا روی دستگاه بیش از حد به منابع نیاز دارد. نیازی نیست که روی همان دستگاهی که مدل را مستقر میکنید، انجام شود. نمونهای از کامپایل AOT در کد شما:
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
روش استنتاج با یک مدل کامپایل شده توسط AOT:
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
رویکرد جایگزین، کامپایل JIT مدل در زمان اجرا روی دستگاه است. این روش انعطافپذیرتر است: فقط به یک فایل مدل backend-agnostic نیاز دارد.
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
بنچمارک با benchmark_model
ابزار LiteRT benchmark_model (benchmark_model.exe) به طور خاص برای ارزیابی عملکرد یک مدل کامپایل شده توسط AOT در NPU طراحی شده است و میتواند برای مقایسه عملکرد در برابر CPU backend (XNNPack) در LiteRT مورد استفاده قرار گیرد. دستور نمونه برای ارزیابی عملکرد یک مدل کامپایل شده توسط AOT در Intel NPU:
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
بررسی دقت با npu_numerics_check
ابزار npu_numerics_check برای تأیید دقت عددی یک مدل کامپایل شده توسط NPU در مقایسه با یک خط مبنا (معمولاً CPU backend، XNNPack) استفاده میشود. این مرحله برای اطمینان از اینکه تفویض اختیار به NPU انحرافات عددی غیرقابل قبولی را که میتواند بر کیفیت مدل تأثیر بگذارد، ایجاد نمیکند، بسیار مهم است.
این ابزار به مدل کامپایل شده توسط AOT نیاز دارد و خروجیهای آن را با مدل اصلی و غیر تفویض شده که روی CPU اجرا میشود، مقایسه میکند.
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
مراحل بعدی
- با راهنمای واحد پردازش عصبی یکپارچه شروع کنید: شتابدهی NPU با LiteRT
- مراحل تبدیل و استقرار را در آنجا دنبال کنید و در صورت لزوم، کوالکام را انتخاب کنید.
- برای LLMها، به اجرای LLMها روی NPU با استفاده از LiteRT-LM مراجعه کنید.