
LiteRT תומך ב-Intel OpenVino דרך CompiledModel API גם עבור AOT וגם עבור קומפילציה במכשיר.
Python API
הגדרת סביבת פיתוח
Linux (x86_64):
- Ubuntu 22.04 או 24.04 LTS
- Python 3.10 ואילך – אפשר להתקין מ-python.org או מההפצה שלכם (
sudo apt install python3 python3-venv) - Intel NPU driver v1.32.1 – ראו Linux NPU Setup
Windows (x86_64):
- Windows 10 או 11
- Python 3.10 ואילך – אפשר להתקין מ-python.org
- מנהל התקן Intel NPU 32.0.100.4724+ – ראו הגדרה של Windows NPU
כדי לבצע build מקוד המקור, נדרשת גם גרסה 7.4.1 ואילך של Bazel באמצעות Bazelisk או build הרמטי של Docker.
מערכות SoC נתמכות
| פלטפורמה | NPU | שם קוד | מערכת ההפעלה |
|---|---|---|---|
| סדרת Intel Core Ultra 2 | NPU4000 | Lunar Lake (LNL) | Linux, Windows |
| Intel Core Ultra Series 3 | NPU5010 | Panther Lake (PTL) | Linux, Windows |
התחלה מהירה
1. התקנה של מנהלי התקנים של NPU
מידע נוסף מופיע במאמר בנושא הגדרת NPU ב-Linux או הגדרת NPU ב-Windows. אפשר לדלג על השלב הזה אם אתם צריכים רק AOT.
דרייבר ה-NPU נדרש רק במערכות שמריצות את המודל בחומרת NPU. מערכות build של AOT טהור יכולות לדלג על השלב הזה.
הערה:
ai-edge-litert-sdk-intel-nightlyמצמיד את גלגל OpenVINO nightly התואם לפי גרסת PEP 440 (למשל,openvino==2026.2.0.dev20260506), ולכן pip צריך--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightlyכדי לאתר אותו. ב-Linux, אם הזיהוי האוטומטי של ההפצה בוחר בארכיון הלא נכון, צריך להגדיר אתLITERT_OV_OS_ID=ubuntu22אוubuntu24לפניpip install.
2. יצירת סביבה וירטואלית של Python
מומלץ להשאיר את גלגל openvino של הלילה מבודד מכל התקנה של OpenVINO ברמת המערכת.
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
3. התקנת חבילת pip
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
הפקודה --extra-index-url מאפשרת ל-pip לפתור את הגלגל היומי openvino המוצמד של OpenVINO מהאינדקס שלו לצד חבילות ב-PyPI.
4. אימות ההתקנה
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
מה צריך לבדוק בפלט:
- רשימות
SDK libs(Linux) אוopenvino_intel_npu_compiler.dll(Windows) – נדרש ל-AOT.libopenvino_intel_npu_compiler.so -
Available devicesכוללNPU– מאשר שמנהל ההתקן של NPU מותקן ו-OpenVINO יכול לתקשר עם המכשיר. האפליקציהNPUלא תופיע במערכות שבהן יש רק קומפילציה מראש (AOT) (שבהן לא מותקן מנהל ההתקן) ובמערכות ללא חומרת Intel NPU.
5. קומפילציה של AOT (אופציונלי)
- מבצע קומפילציה מראש של
.tfliteעבור יעד ספציפי של Intel NPU (PTL או LNL) כדי שזמן הריצה ידלג על שלב הפלאגין של הקומפיילר. - לא צריך NPU פיזי או את מנהל ההתקן של ה-NPU – רק
ai-edge-litert-nightlyו-ai-edge-litert-sdk-intel-nightly. - קומפילציה צולבת נתמכת: אפשר לבצע קומפילציה בכל מארח Linux או Windows, לשלוח את
.tfliteשנוצר אל יעד של אחת ממערכות ההפעלה ולהריץ אותו שם.
שמות קובצי הפלט הם <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite.
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
6. הרצת היקשים ב-NPU
LiteRT תומך בשני נתיבי הסקה ב-NPU של Intel:
- JIT – טעינה של
.tfliteגולמי. פלאגין הקומפיילר מחלק ומקמפל את הפעולות הנתמכות עבור ה-NPU בזמןCompiledModel.from_file(). מוסיף זמן אחזור מסוים בהפעלה הראשונה (משתנה בהתאם למודל). - AOT-compiled – טעינה של
<model>_IntelOpenVINO_<SoC>_apply_plugin.tfliteשנוצר בשלב 4. מדלג על שלב החלוקה למחיצות ועל שלב ההידור בזמן הטעינה.
קטע הקוד הזה פועל גם עבור:
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
אישור שהידור JIT אכן פעל
אם ה-JIT מצליח, היומן מכיל (סיומת הקובץ היא .so ב-Linux, .dll ב-Windows):
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
אם השורות האלה לא מופיעות אבל עדיין מדווח על Fully accelerated: True, המודל הופעל בגיבוי של XNNPACK CPU, ולא ב-NPU – אפשר לעיין בשורה של פתרון בעיות ב-JIT.
7. השוואה לשוק
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
סימונים נפוצים:
| דגל | ברירת מחדל | תיאור |
|---|---|---|
--model PATH
|
— | הנתיב למודל .tflite (חובה). |
--signature KEY |
הראשון | מפתח החתימה להרצה. |
--use_cpu / --no_cpu
|
מופעל | החלפת המצב של האצת המעבד או של חזרה למעבד. |
--use_gpu |
מושבתת | מפעילים את מאיץ ה-GPU. |
--use_npu |
מושבתת | מפעילים את מאיץ ה-NPU של Intel. |
--require_full_delegation
|
מושבתת | הפעולה תיכשל אם המודל לא יועבר במלואו אל המאיץ שנבחר. |
--num_runs N
|
50 | מספר האיטרציות של הסקת מסקנות מתוזמנת. |
--warmup_runs N
|
5 | חזרות לחימום ללא הגבלת זמן לפני המדידה. |
--num_threads N |
1 | מספר ה-threads של המעבד. |
--result_json PATH
|
— | תכתוב סיכום ב-JSON (נתוני השהיה, קצב העברת הנתונים, רשימת המאיצים). |
--verbose |
מושבתת | רישום נוסף ביומן בזמן הריצה. |
דגלים מתקדמים / דגלי ביטול – נדרשים רק כדי להפנות אל גרסאות בהתאמה אישית:
--dispatch_library_path, --compiler_plugin_path, --runtime_path.
גלגלים של ספקים שונים: הצמדת JIT ל-Intel OV
הערה: כשקוראים לפונקציה
Environment.create()בלי לציין נתיבים, היא מאתרת באופן אוטומטי ספקים בתיקייהai_edge_litert/vendors/לפי סדר אלפביתי ורושמת את הראשון שהיא מוצאת. בהתקנה של ספקים שונים, יכול להיות שזה לא יהיה Intel OV – צריך להעביר את ספריות Intel OV באופן מפורש כדי לבחור את האפשרות הנכונה.
- ה-pip wheel שולח קומפיילר פלאגין לכל ספק רשום
(
intel_openvino/,google_tensor/,mediatek/,qualcomm/,samsung/). - כדי לכפות את הנתיב של Intel OV (מומלץ כשמותקנות כמה ערכות SDK של ספקים), מעבירים את הספריות של Intel OV באופן ידני:
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
סביבת זמן הריצה טוענת כל ספרייה משותפת שהיא מוצאת בספרייה הנתונה, ולכן אם מצביעים על vendors/intel_openvino/compiler/ נטען רק הפלאגין של Intel. הפלאגינים של Google Tensor / MediaTek / Qualcomm / Samsung בספריות מקבילות לא נטענים אף פעם.
ב-CLI, הדגלים המקבילים הם:
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
אימות הביצוע של NPU
כדי לוודא שהמודל באמת פעל ב-NPU, צריך לבדוק אם מופיעים שני האותות:
- היומן מכיל את
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}– ספריית השליחה של Intel נטענה (.soב-Linux, .dllב-Windows). -
model.is_fully_accelerated()returnsTrue— every op was offloaded to the selected accelerator.
השימוש ב-is_fully_accelerated() לבד לא מספיק: אם ספריית השליחה לא נטענה אף פעם, הפעולות הועברו במלואן ל-XNNPACK/CPU, ולא ל-NPU.
הגדרת NPU ב-Linux
הערה: אם אתם צריכים רק AOT, אתם יכולים לדלג על הקטע הזה כי לא נדרש NPU פיזי.
מידע: שימוש במנהל התקן של NPU v1.32.1 (בצירוף OpenVINO 2026.1). התקנה של דרייברים ישנים יותר נכשלת עם השגיאה
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE.
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
לאחר מכן מריצים את קטע הקוד להתקנה ולאימות מתוך התחלה מהירה.
הגדרה של NPU ב-Windows
הערה: אם אתם צריכים רק AOT, אתם יכולים לדלג על הקטע הזה כי לא נדרש NPU פיזי.
- מתקינים את הדרייבר של Intel NPU (32.0.100.4724+) ממרכז ההורדות של Intel.
- מוודאים שמנהל המכשירים מציג את מכשיר ה-NPU בקטע מעבדים עצביים (מוצג כ-
Intel(R) AI Boostאו כ-Intel(R) NPUבהתאם לדרייבר). - מריצים את קטע הקוד להתקנה ולאימות מתוך התחלה מהירה, ומחליפים את
pipב-python -m pip.
מידע:
import ai_edge_litertמתבצעת הרשמה אוטומטית של ספריות DLL באמצעותos.add_dll_directory(), כך שלא נדרשת הגדרה שלPATHבסקריפטים של Python. לצרכנים שאינם משתמשים ב-Python, מריצים את הפקודהsetupvars.batאו מוסיפים את הקידומת<openvino>/libsל-PATH.
בנייה ממקור
האם אתם משתמשים בשרת Proxy? ייצוא
http_proxy/https_proxy/no_proxyלפני הרצת סקריפטים של build – הם מעבירים את זה ל-Docker ולמאגר.
Linux (Docker, hermetic):
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
Windows (PowerShell, Bazel בנתיב):
.\ci\build_pip_package_with_bazel_windows.ps1
הפלט נשמר ב-dist/:
-
ai_edge_litert-*.whl– גלגל זמן הריצה. -
ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz— vendor sdists. - קובץ ה-sdist של Intel הוא בנפח של כ-5KB. קומפיילר ה-NPU
.so/.dllמאוחזר בזמןpip install, כך שאותו קובץ sdist פועל ב-Linux וב-Windows.
בדיקות יחידה
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
פתרון בעיות
| בעיה | תיקון |
|---|---|
ה-AOT נכשל: Device with "NPU" name is not registered |
הקומפיילר של ה-NPU לא אוחזר. כדאי לבדוק את ai_edge_litert_sdk_intel.path_to_sdk_libs() הרשימות libopenvino_intel_npu_compiler.so / .dll. אם הוא ריק, צריך להתקין מחדש עם גישה לרשת או להגדיר LITERT_OV_OS_ID=ubuntu22/ubuntu24. |
ה-JIT פועל במעבד במקום ביחידת העיבוד העצבי (אין יומן Partitioned subgraph, אין יומן Loaded plugin, Fully accelerated: True עדיין מודפס) |
לא זוהה פלאגין של קומפיילר. מאשרים ov.get_compiler_plugin_dir() מוחזר נתיב מתחת ל-ai_edge_litert/vendors/intel_openvino/compiler/. אם מותקנים כמה ערכות SDK של ספקים, צריך להעביר את compiler_plugin_path=ov.get_compiler_plugin_dir() באופן מפורש אל Environment.create() (או את --compiler_plugin_path=... אל litert-benchmark). |
הפעלת JIT נכשלת: Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so (Linux) / openvino_intel_npu_compiler.dll (Windows) |
בפעם הראשונה שמריצים את הפקודה import ai_edge_litert_sdk_intel, ה-SDK sdist מעתיק את קומפיילר ה-NPU אל openvino/libs/. אם הועתקה דילוג (מערכת קבצים לקריאה בלבד, חסר openvino), צריך להתקין מחדש את ai-edge-litert-sdk-intel אחרי שמתקינים את openvino, ואז את import ai_edge_litert בתהליך חדש. |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE |
שדרוג מנהל ההתקן של NPU לגרסה v1.32.1 (Linux). |
/dev/accel/accel0 לא נמצא |
sudo dmesg | grep -i vpu כדי לנפות באגים במנהל ההתקן. צריך להפעיל מחדש את המחשב אחרי ההתקנה. |
| ההרשאה נדחתה ב-NPU | sudo gpasswd -a ${USER} render && newgrp render. |
| Windows: NPU לא מופיע במנהל ההתקנים | מתקינים את מנהל ההתקן NPU 32.0.100.4724+ ממרכז ההורדות של Intel. |
Windows: Failed to initialize Dispatch API / חסרים קובצי DLL |
מוודאים שהפקודה import ai_edge_litert מופעלת קודם (רישום אוטומטי של ספריות DLL). אם מדובר בשיחות שלא מבוססות על Python, מריצים את הפקודה setupvars.bat או מוסיפים את <openvino>/libs לפני PATH. |
גרסת Windows: LNK2001 fixed_address_empty_string, C2491 dllimport, Python 3.12+ fails |
מגבלת גרסה של Python / Protobuf ABI – ראו ci/build_pip_package_with_bazel_windows.ps1; גרסאות Windows מחייבות Python 3.11. |
מגבלות
רק מכשיר ה-NPU נתמך דרך נתיב השליחה של OpenVINO. למסקנות של CPU, משתמשים רק ב-HardwareAccelerator.CPU (XNNPACK).
C++ API
דרישות מוקדמות והגדרת בנייה
דרישות מוקדמות:
- Visual Studio 2022 ואילך (צריך להתקין כלי פיתוח של C++).
- git: מתקינים את git מהכתובת https://git-scm.com/install/. מוודאים שהנתיבים
C:\Program Files\Git\bin and C:\Program Files\Git\cmdכלולים במשתנה הסביבה PATH של המערכת, כדי שתהליכי הבנייה של LiteRT/LiteRT-LM יוכלו לאתר את bash.exe ואת git.exe. - bazelisk: מתקינים את bazelisk וכוללים את המיקום שלו במשתנה הסביבה
PATHשל המערכת: https://bazel.build/install/bazelisk. - Cmake: מתקינים את Cmake בגרסה 4.3.0 ואילך מכתובת https://cmake.org/download/, ומוודאים ש-Cmake כלול בנתיב המערכת.
- Python: מוודאים שגרסה Python 3.11 ואילך מותקנת, ושהקובץ python.exe נמצא בנתיב.
- הגדרות Windows: מפעילים את מצב הפיתוח בהגדרות Windows.
פיתוח כלים ותוספים של LiteRT ל-NPU של Intel
כדי להריץ מודלים ב-Intel NPU באמצעות LiteRT, צריך לקמפל אותם באמצעות פלאגין הקומפיילר LiteRT Intel OpenVINO. בנוסף, כל מודל מקומפל שמיועד להרצה ב-Intel NPU צריך להיות מוקצה לפלאגין השליחה LiteRT Intel OpenVINO.
המנגנון שבאמצעותו LiteRT מפעיל את הפלאגינים האלה מוסבר בהמשך:
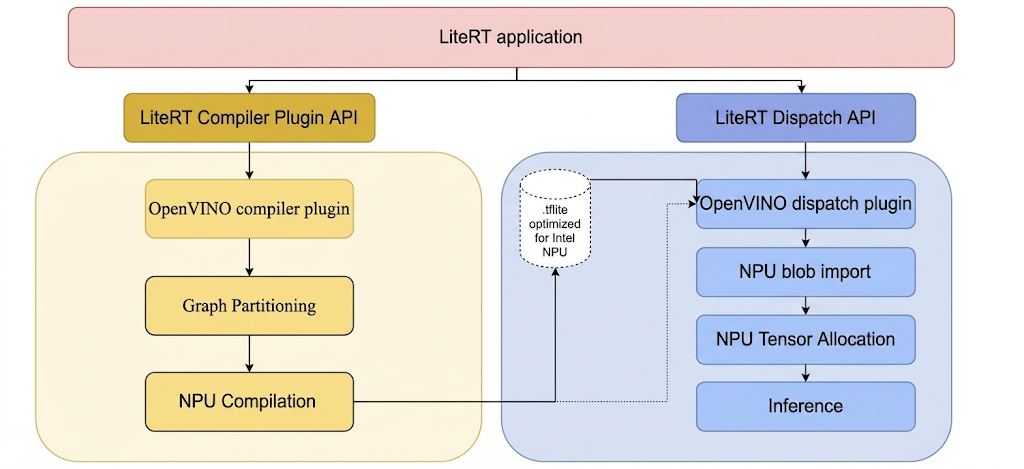
שלבים ליצירת כלי LiteRT ותוספים של Intel.
לפני שיוצרים קובץ הפעלה או ספרייה מ-LiteRT, צריך ליצור ספרייה מקומית, למשל C:\bzl. הקובץ הבינארי של פלט ה-build ייאסף מהספרייה הזו. יצירת הפלאגין Intel OpenVINO dispatch
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
אפשרות אחרת היא ליצור את תוסף השליחה ממאגר LiteRT-LM על ידי הוספת הקידומת @litert ליעד. הדבר נכון לכל היעדים הבאים ממאגר LiteRT.
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
יצירת פלאגין של מהדר Intel OpenVINO
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
כלי הידור Ahead-of-Time (AOT) של LiteRT חלק מהכלים של LiteRT דורשים הידור AOT מפורש של מודלים לפני שמריצים אותם ב-NPU של Intel. הוראות לבנייה של כלי ההידור AOT של LiteRT:
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
Build LiteRT model runner אפשר להשתמש ב-LiteRT model runner כדי להריץ מודל ב-Intel NPU, מודל שלא עבר קומפילציה מראש או מודל שעבר קומפילציה מראש (AOT). ההוראה לבניית רכיב ההפעלה של המודל:
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
כלי השירות לבניית מודל מידוד LiteRT אפשר להשתמש בכלי המידוד של מודל LiteRT כדי לבצע מידוד של ביצועי ההסקה של מודל ב-NPU של Intel. אם ההוראה היא ליצור את כלי ההשוואה לשוק:
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
יצירת כלי לבדיקת נתונים מספריים ב-LiteRT
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
שימוש מתקדם: פיתוח באמצעות Intel OpenVINO SDK בהתאמה אישית
מערכת ה-build של LiteRT מאחזרת באופן אוטומטי את Intel OpenVINO SDK מוכן מראש כשמבצעים קומפילציה של הקומפיילר ותוספי השליחה.
אם הפרויקט שלכם דורש גרסה ספציפית או מותאמת אישית של Intel OpenVINO SDK, צריך לבצע את שלבי ההגדרה הנוספים האלה לפני שמתחילים בבניית הפלאגין:
- מורידים את קובץ ה-binary של הגרסה האחרונה של OpenVINO ל-Windows מהכתובת
https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html,
ומחלצים אותו לדיסק מקומי, למשל,
C:\Intel\intel_openvino. - מוודאים שספריית הצאצא היחידה בנתיב הזה נקראת openvino, ומכילה ספריות משנה כמו runtime ו-include.
- עוברים אל ספריית הבסיס של מאגר LiteRT המשוכפל במסוף (שורת הפקודה או PowerShell) ומגדירים את המשתנה OPENVINO_NATIVE_DIR (מוודאים שאין בסוף
\`), for example:set OPENVINO_NATIVE_DIR=C:\Intel\intel_openvino`
קומפילציה של מודלים בהתאמה אישית מסוג AOT
בקטע הזה מוסבר איך להכין את הסביבה ולבצע קימפול AOT של מודלים מותאמים אישית של TFLite, PyTorch או JAX עבור LiteRT.
במהלך תהליך ההידור של המודל עבור ה-NPU של Intel, LiteRT מאמת את גרף המודל מול האופרטורים שנתמכים על ידי תוסף הקומפיילר LiteRT Intel OpenVINO. עבור אופרטורים או תתי-גרפים שתואמים לפלאגין של הקומפיילר, LiteRT מבצע קומפילציה של כל תת-גרף כזה ל-DISPATCH_OP, שבהמשך מחליף את תת-הגרף המקורי בגרף. אופרטורים שלא נכללים ב-opset הנתמך על ידי מהדר Intel OpenVINO נשארים ללא שינוי בגרף. לכן, קומפילציה של AOT עשויה להניב מודל עם האצלה מלאה או עם האצלה חלקית. דוגמה למודל שעבר קומפילציה מראש (AOT) עם הרשאות מלאות:
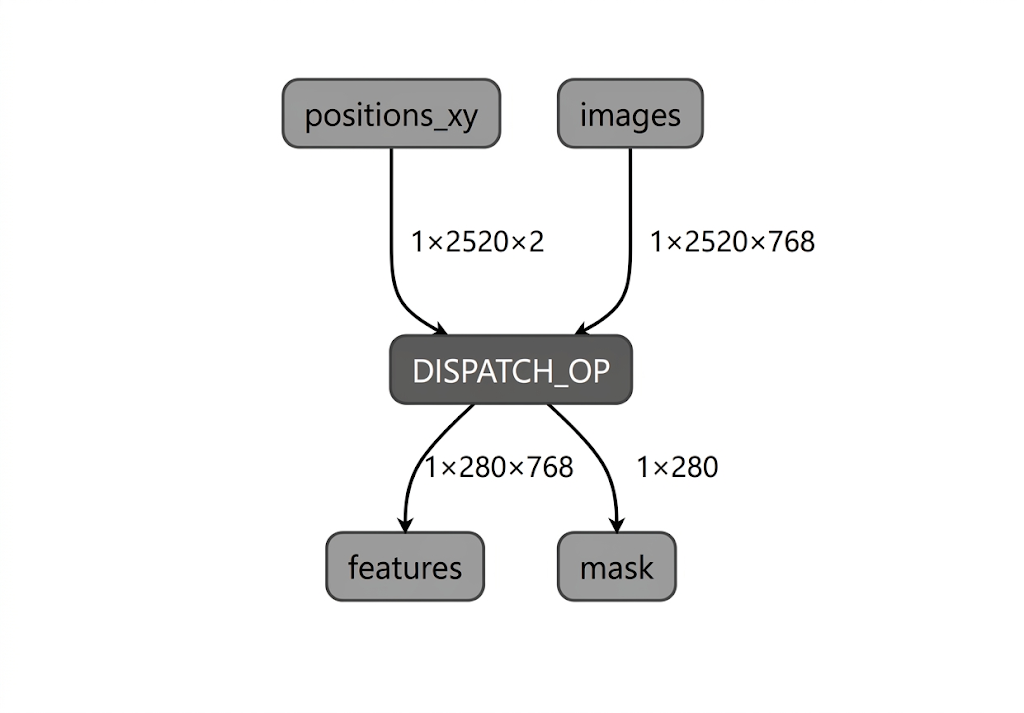
הכלי LiteRT apply_plugin_main (apply_plugin_main.exe) הוא כלי קומפילציה של AOT שבו אפשר להשתמש למטרה הזו. דוגמה לשימוש בכלי בפלטפורמת Intel:
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
חשוב לשים לב שהקומפיילר הבסיסי של ה-NPU, שכלול בהפצה הבינארית של Intel OpenVINO SDK, משמש ל-Intel Core Ultra Series 2 ולמערכות על שבב (SoC) שבאות אחריהן. אם מודל עובר קומפילציה עבור NPU שלא מופיע ברשימת המכשירים הנתמכים, צריך לציין במפורש את סוג הקומפיילר (אבל זה עדיין אופציונלי עבור Intel Core Ultra 2 ומעלה).
set IE_NPU_COMPILER_TYPE=PLUGIN
הידור JIT לעומת הידור AOT באפליקציה
כדי לקמפל מודלים באפליקציית LiteRT שלכם, יש שתי גישות: קומפילציה של AOT, שכבר הצגנו, וקומפילציה של Just-in-time (JIT).
בקומפילציה מסוג AOT, המצב עובר קומפילציה במצב אופליין לפני הפריסה, ואפשר לשמור אותו לשימוש מאוחר יותר. השיטה הזו נפוצה כשקומפילציה דורשת יותר מדי משאבים כדי להפעיל אותה במכשיר. לא צריך לבצע את הפעולה באותו מכשיר שבו פורסים את המודל. דוגמה לקומפילציה של AOT בקוד:
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
הדרך להסיק מסקנות באמצעות מודל שעבר קומפילציה של AOT:
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
הגישה החלופית היא הידור JIT של המודל בזמן הריצה במכשיר. הוא גמיש יותר: הוא דורש רק קובץ מודל אחד שלא תלוי ב-Backend.
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
השוואה לשוק באמצעות benchmark_model
כלי השירות LiteRT benchmark_model (benchmark_model.exe) מיועד במיוחד להשוואת ביצועים של מודל שעבר קומפילציה מראש (AOT) ב-NPU, ואפשר להשתמש בו כדי להשוות את הביצועים לביצועים של קצה העורף של ה-CPU (XNNPack) ב-LiteRT. דוגמה לפקודה להשוואה לבנצ'מרק של מודל שעבר קומפילציה של AOT ב-Intel NPU:
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
בדיקת דיוק באמצעות npu_numerics_check
הכלי npu_numerics_check משמש לאימות הדיוק המספרי של מודל שעבר קומפילציה ב-NPU בהשוואה לנתוני בסיס (בדרך כלל קצה העורפי של ה-CPU, XNNPack). השלב הזה חשוב כדי לוודא שההעברה אל ה-NPU לא גורמת לסטייה מספרית לא מקובלת שעלולה להשפיע על איכות המודל.
הפעלת בדיקה של ערכים מספריים כדי להשתמש בכלי הזה, צריך מודל שעבר קומפילציה של AOT. הכלי משווה את התוצאות של המודל הזה לתוצאות של המודל המקורי שלא עבר קומפילציה, שפועל במעבד.
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
השלבים הבאים
- כדאי להתחיל עם המדריך המאוחד של NPU: האצת NPU באמצעות LiteRT
- פועלים לפי השלבים להמרת הקובץ ולפריסה שלו, ובוחרים באפשרות Qualcomm במקומות הרלוונטיים.
- למודלים של שפה גדולה (LLM), ראו הפעלת LLM ב-NPU באמצעות LiteRT-LM.