
LiteRT поддерживает Intel OpenVino через API CompiledModel как для компиляции AOT, так и для компиляции на устройстве.
API Python
Настройка среды разработки
Linux (x86_64):
- Ubuntu 22.04 или 24.04 LTS
- Python 3.10+ — установите с python.org или из вашего дистрибутива (
sudo apt install python3 python3-venv) - Драйвер Intel NPU версии 1.32.1 — см. раздел «Настройка NPU в Linux».
Windows (x86_64):
- Windows 10 или 11
- Python 3.10+ — установите с сайта python.org
- Драйвер Intel NPU 32.0.100.4724+ — см. раздел «Настройка NPU в Windows».
Для сборки из исходного кода также требуется Bazel 7.4.1+ с использованием Bazelisk или герметичной сборки Docker.
Поддерживаемые SoC
| Платформа | НПУ | Кодовое имя | ОС |
|---|---|---|---|
| Intel Core Ultra Series 2 | НПУ4000 | Лунное озеро (LNL) | Linux, Windows |
| Intel Core Ultra Series 3 | НПУ5010 | Озеро Пантер (PTL) | Linux, Windows |
Быстрый старт
1. Установите драйверы NPU.
См. раздел «Настройка NPU в Linux» или «Настройка NPU в Windows» . Пропустите этот шаг, если вам нужен только AOT.
Драйвер NPU необходим только в системах, которые выполняют модель на аппаратном обеспечении NPU. Системы, использующие исключительно AOT-сборку, могут его пропустить.
Примечание:
ai-edge-litert-sdk-intel-nightlyфиксирует соответствующий ночной пакет OpenVINO по версии PEP 440 (например,openvino==2026.2.0.dev20260506), поэтому pip требуется--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightlyдля его поиска. В Linux, если автоматическое определение дистрибутива выбирает неправильный архив, установитеLITERT_OV_OS_ID=ubuntu22илиubuntu24передpip install.
2. Создайте виртуальную среду Python.
Рекомендуется изолировать ночную сборку openvino от любой системной установки OpenVINO.
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
3. Установите пакет pip.
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
Параметр --extra-index-url позволяет pip получать доступ к закрепленному ночному пакету openvino из индекса OpenVINO, а также к пакетам из PyPI.
4. Проверьте установку.
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
Что нужно проверить в выходных данных:
- В списке
SDK libsуказаныlibopenvino_intel_npu_compiler.so(Linux) илиopenvino_intel_npu_compiler.dll(Windows) — необходимые для AOT. -
Available devicesвключаютNPU— подтверждает, что драйвер NPU установлен и OpenVINO может взаимодействовать с устройством.NPUбудет отсутствовать в системах только с AOT (где драйвер не установлен) и в системах без аппаратного обеспечения Intel NPU.
5. AOT-компиляция (необязательно)
- Предварительно компилирует файл
.tfliteдля конкретной целевой платформы Intel NPU (PTL или LNL), поэтому среда выполнения пропускает этап компиляции плагина. - Для работы не требуется физический NPU или драйвер NPU — достаточно
ai-edge-litert-nightlyиai-edge-litert-sdk-intel-nightly. - Поддерживается кросс-компиляция: скомпилируйте на любой хост-системе Linux или Windows, отправьте полученный файл
.tfliteна целевую систему любой из этих ОС и запустите его там.
Выходные файлы называются <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite .
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
6. Запустите вывод NPU.
LiteRT поддерживает два пути выполнения инференции на NPU Intel:
- JIT — загрузка необработанного файла
.tflite; плагин компилятора разделяет и компилирует поддерживаемые операции для NPU во времяCompiledModel.from_file(). Добавляет некоторую задержку при первом запуске (зависит от модели). - Компиляция AOT — загрузка файла
<model>_IntelOpenVINO_<SoC>_apply_plugin.tflite, созданного на шаге 4. Пропускает этап разбиения на разделы и компиляции во время загрузки.
Этот фрагмент кода работает в обоих случаях:
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
Подтвердите, что JIT-компиляция действительно выполнилась.
Когда JIT-компиляция проходит успешно, в логе содержится следующая информация (расширение файла: .so в Linux, .dll в Windows):
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
Если эти строки отсутствуют, но при этом по-прежнему отображается Fully accelerated: True , значит, модель была запущена на резервном процессоре XNNPACK, а не на нейронном процессоре — см. строку устранения неполадок JIT.
7. Эталонные показатели
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
Общие флаги:
| Флаг | По умолчанию | Описание |
|---|---|---|
--model PATH | — | Путь к модели .tflite (обязательно). |
--signature KEY | первый | Ключ подписи для запуска. |
--use_cpu / --no_cpu | на | Переключите режим работы процессора на ускорение / резервный режим работы процессора. |
--use_gpu | выключенный | Включите графический ускоритель. |
--use_npu | выключенный | Включите ускоритель Intel NPU. |
--require_full_delegation | выключенный | Ошибка произойдет, если модель не будет полностью перенесена на выбранный акселератор. |
--num_runs N | 50 | Количество итераций вывода с заданным временем. |
--warmup_runs N | 5 | Перед измерением проводятся разминочные итерации без ограничения по времени. |
--num_threads N | 1 | Количество потоков ЦП. |
--result_json PATH | — | Напишите сводку в формате JSON (статистика задержки, пропускная способность, список ускорителей). |
--verbose | выключенный | Дополнительное логирование во время выполнения. |
Дополнительные/переопределяющие флаги — необходимы только для указания пользовательских сборок: --dispatch_library_path , --compiler_plugin_path , --runtime_path .
Смешанные поставщики: привязка JIT к Intel OV
Примечание: При вызове
Environment.create()без явного указания путей, программа автоматически обнаруживает поставщиков в каталогеai_edge_litert/vendors/в алфавитном порядке и регистрирует первого найденного. В случае установки с использованием компонентов разных производителей это может быть не Intel OV — укажите каталоги Intel OV явно, чтобы принудительно выбрать правильный вариант.
- В состав пакета pip входят плагины компилятора для каждого зарегистрированного производителя (
intel_openvino/,google_tensor/,mediatek/,qualcomm/,samsung/). - Чтобы принудительно указать путь к файлам Intel OV (рекомендуется при установке SDK нескольких производителей), укажите каталоги Intel OV вручную:
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
Среда выполнения загружает все найденные в указанном каталоге разделяемые библиотеки, поэтому указание на vendors/intel_openvino/compiler/ загружает только плагин Intel; плагины Google Tensor / MediaTek / Qualcomm / Samsung в соседних каталогах никогда не затрагиваются.
Для интерфейса командной строки эквивалентными флагами являются:
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
Проверка выполнения NPU
Чтобы убедиться, что модель действительно работала на нейропроцессоре, проверьте наличие обоих сигналов:
- В журнале содержится
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}— загружена библиотека диспетчеризации Intel (.soв Linux,.dllв Windows). -
model.is_fully_accelerated()возвращаетTrue— каждая операция была перенесена на выбранный акселератор.
Одной лишь is_fully_accelerated() недостаточно : если библиотека диспетчеризации так и не загрузилась, операции были полностью перенесены на XNNPACK/CPU, а не на NPU.
Настройка NPU в Linux
Примечание: Пропустите этот раздел, если вам нужен только AOT — физический NPU не требуется.
Информация: Используйте драйвер NPU версии 1.32.1 (в паре с OpenVINO 2026.1). Более старые драйверы завершаются с ошибкой
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE.
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
Затем выполните фрагмент кода установки и проверки из раздела "Быстрый старт" .
Настройка NPU в Windows
Примечание: Пропустите этот раздел, если вам нужен только AOT — физический NPU не требуется.
- Установите драйвер Intel NPU ( 32.0.100.4724+ ) из Центра загрузок Intel .
- В диспетчере устройств устройство NPU отображается в разделе «Нейронные процессоры » (в зависимости от драйвера —
Intel(R) AI BoostилиIntel(R) NPU). - Выполните фрагмент кода установки и проверки из раздела «Быстрый старт» , заменив
pipнаpython -m pip.
Информация:
import ai_edge_litertавтоматически регистрирует каталоги DLL с помощьюos.add_dll_directory(), поэтому скриптам Python не требуется настройкаPATH. Для пользователей, не использующих Python, запуститеsetupvars.batили добавьте вPATHпеременную<openvino>/libs.
Сборка из исходного кода
Используете прокси-сервер? Перед запуском скриптов сборки экспортируйте
http_proxy/https_proxy/no_proxy— они перенаправят их в Docker и контейнер.
Linux (Docker, герметичный):
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
Windows (PowerShell, Bazel в PATH):
.\ci\build_pip_package_with_bazel_windows.ps1
Выходные данные поступают в dist/ :
-
ai_edge_litert-*.whl— колесо среды выполнения. -
ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz— сдисты поставщика. - Размер дистрибутива Intel составляет примерно 5 КБ; файлы
.so/.dllкомпилятора NPU загружаются во времяpip install, поэтому один и тот же дистрибутив работает как в Linux, так и в Windows.
Модульные тесты
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
Поиск неисправностей
| Проблема | Исправить |
|---|---|
Сбой AOT: Device with "NPU" name is not registered | Компилятор NPU не загружен. Проверьте, что в списке ai_edge_litert_sdk_intel.path_to_sdk_libs() указан libopenvino_intel_npu_compiler.so / .dll . Если список пуст, переустановите программу с доступом по сети или установите LITERT_OV_OS_ID=ubuntu22 / ubuntu24 . |
JIT-компилятор работает на ЦП, а не на НПУ (нет записи в журнале Partitioned subgraph , нет записи в журнале Loaded plugin , Fully accelerated: True по-прежнему выводится). | Плагин компилятора не обнаружен. Убедитесь, что ov.get_compiler_plugin_dir() возвращает путь в ai_edge_litert/vendors/intel_openvino/compiler/ . Если установлено несколько SDK от разных производителей, явно передайте compiler_plugin_path=ov.get_compiler_plugin_dir() в Environment.create() (или --compiler_plugin_path=... в litert-benchmark ). |
Ошибка JIT: Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so (Linux) / openvino_intel_npu_compiler.dll (Windows) | При первом import ai_edge_litert_sdk_intel SDK sdist копирует компилятор NPU в openvino/libs/ . Если копирование было пропущено (файловая система только для чтения, отсутствует openvino ), переустановите ai-edge-litert-sdk-intel после установки openvino , а затем import ai_edge_litert в новом процессе. |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE | Обновите драйвер NPU до версии 1.32.1 (Linux). |
/dev/accel/accel0 не найден | Для отладки драйвера выполните команду sudo dmesg | grep -i vpu ; после установки перезагрузите компьютер. |
| Доступ к NPU запрещен. | sudo gpasswd -a ${USER} render && newgrp render . |
| Windows: NPU отсутствует в Диспетчере устройств | Установите драйвер NPU версии 32.0.100.4724+ из Центра загрузок Intel . |
Windows: Failed to initialize Dispatch API / отсутствуют DLL-файлы. | Убедитесь, что сначала выполняется import ai_edge_litert (она автоматически регистрирует каталоги DLL); для вызовов, не относящихся к Python, запустите setupvars.bat или добавьте <openvino>/libs в PATH . |
Сборка для Windows: LNK2001 fixed_address_empty_string , C2491 dllimport , Python 3.12+ fails | Ограничение по ABI Protobuf / версии Python — см. ci/build_pip_package_with_bazel_windows.ps1 ; для сборки под Windows требуется Python 3.11. |
Ограничения
В рамках протокола OpenVINO поддерживается только устройство NPU. Для вывода данных на ЦП используйте только HardwareAccelerator.CPU (XNNPACK).
API на C++
Предварительные требования и настройка сборки
Создайте необходимые компоненты:
- Visual Studio 2022 или более поздняя версия (необходимо установить инструменты разработки на C++).
- git: Установите git с сайта https://git-scm.com/install/. Убедитесь, что
C:\Program Files\Git\bin and C:\Program Files\Git\cmdдобавлены в переменную среды PATH вашей системы, чтобы процессы сборки LiteRT/LiteRT-LM могли найти bash.exe и git.exe. - bazelisk: Установите bazelisk и добавьте его путь в переменную среды
PATHвашей системы: https://bazel.build/install/bazelisk. - CMake: Установите CMake версии 4.3.0 или выше с сайта https://cmake.org/download/, убедившись, что CMake добавлен в переменную PATH вашей системы.
- Python: Убедитесь, что установлен Python 3.11 или более поздней версии, и что python.exe добавлен в переменную PATH.
- Параметры Windows: Включите режим разработчика в параметрах Windows.
Разработка инструментов и плагинов LiteRT для NPU Intel.
Для запуска моделей на NPU Intel с помощью LiteRT необходимо, чтобы они были скомпилированы с использованием плагина компилятора LiteRT Intel OpenVINO; кроме того, любая скомпилированная модель, предназначенная для выполнения на NPU Intel, должна быть передана плагину диспетчеризации LiteRT Intel OpenVINO.
Далее показан механизм, с помощью которого LiteRT вызывает эти плагины:
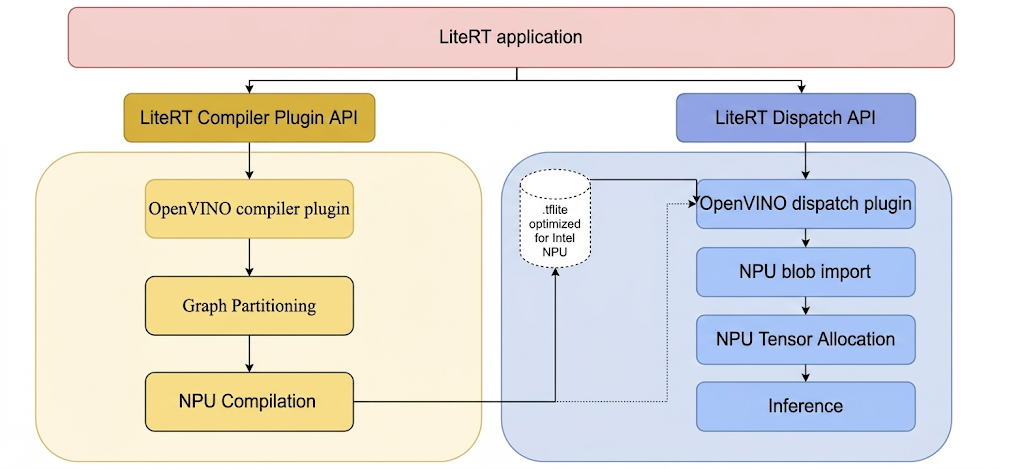
Этапы сборки инструментов LiteRT и плагинов Intel.
Перед сборкой любого исполняемого файла или библиотеки из LiteRT создайте локальную директорию, например, C:\bzl. Выходной двоичный файл сборки будет собран из этой директории. Соберите плагин диспетчеризации Intel OpenVINO.
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
В качестве альтернативы вы также можете собрать плагин диспетчеризации из репозитория LiteRT-LM, добавив префикс @litert к целевому объекту. Аналогичные действия выполняются для всех последующих целевых объектов из репозитория LiteRT.
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Соберите плагин компилятора Intel OpenVINO.
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
Сборка утилиты компиляции LiteRT Ahead-of-Time (AOT). Некоторые инструменты LiteRT требуют явной компиляции моделей AOT перед их запуском на NPU Intel. Инструкция по сборке утилиты компиляции LiteRT AOT:
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
Сборка средства запуска моделей LiteRT. Средство запуска моделей LiteRT позволяет запускать модели на процессорах Intel NPU, как некомпилированные, так и скомпилированные с помощью AOT. Инструкция по сборке средства запуска моделей:
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
Сборка утилиты для тестирования производительности модели LiteRT. Инструмент для тестирования производительности модели LiteRT можно использовать для оценки производительности вывода модели на NPU Intel. Если требуется инструкция по сборке инструмента тестирования:
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
Создайте утилиту для проверки числовых данных LiteRT.
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
Расширенные возможности использования: сборка с использованием специализированного SDK Intel OpenVINO.
Система сборки LiteRT автоматически загружает предварительно собранный Intel OpenVINO SDK при компиляции плагинов компилятора и диспетчеризации.
Если для вашего проекта требуется определенная или модифицированная версия Intel OpenVINO SDK, выполните следующие дополнительные шаги по настройке перед началом сборки плагина:
- Загрузите последнюю версию бинарного файла OpenVINO для Windows с сайта https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html и распакуйте его на локальный диск, например,
C:\Intel\intel_openvino. - Убедитесь, что единственная дочерняя директория в этом пути называется "openvino" и содержит подкаталоги, такие как "runtime" и "include".
- Перейдите в корневой каталог клонированного репозитория LiteRT в консоли (командной строке или PowerShell) и установите переменную OPENVINO_NATIVE_DIR (убедитесь, что в конце нет символа
\`), for example:set OPENVINO_NATIVE_DIR=C:\Intel\intel_openvino`
Сборка пользовательских моделей AOT
В этом разделе выполняется подготовка среды и компиляция AOT пользовательских моделей TFLite, PyTorch или JAX для LiteRT.
В процессе компиляции модели для NPU Intel, LiteRT проверяет граф модели на соответствие операторам, поддерживаемым плагином компилятора LiteRT Intel OpenVINO. Для операторов или подграфов, совместимых с плагином компилятора, LiteRT компилирует каждый такой подграф в DISPATCH_OP, который впоследствии заменяет исходный подграф в графе. Операторы, не включенные в набор поддерживаемых операторов компилятором Intel OpenVINO, остаются неизменными в графе. Следовательно, AOT-компиляция может привести к созданию либо полностью делегированной, либо частично делегированной модели. Вот пример полностью делегированной модели, скомпилированной с помощью AOT:
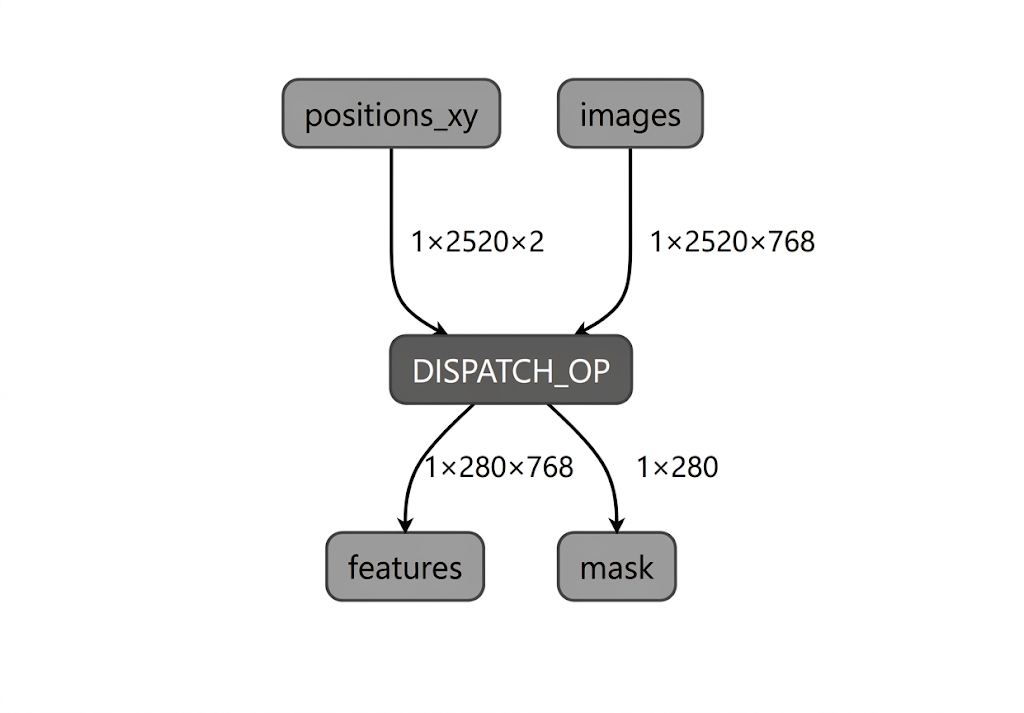
Для этой цели можно использовать утилиту LiteRT apply_plugin_main (apply_plugin_main.exe) — утилиту AOT-компиляции. Пример использования утилиты на платформе Intel:
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
Обратите внимание, что для процессоров Intel Core Ultra Series 2 и последующих моделей используется стандартный компилятор NPU, входящий в состав бинарного дистрибутива Intel OpenVINO SDK. Если модель компилируется для NPU, не входящего в список поддерживаемых, тип компилятора необходимо указать явно (хотя для Intel Core Ultra 2 и более поздних моделей это остается необязательным).
set IE_NPU_COMPILER_TYPE=PLUGIN
JIT-компиляция против AOT-компиляции в вашем приложении
Для компиляции моделей в вашем собственном приложении LiteRT существует два подхода: компиляция AOT, которую мы уже рассматривали, и компиляция Just-in-time (JIT).
При AOT-компиляции модель компилируется в автономном режиме перед развертыванием и может быть сохранена для последующего использования — это часто используется, когда компиляция слишком ресурсоемка для выполнения на устройстве. Не обязательно выполнять ее на том же устройстве, на котором развертывается модель. Пример AOT-компиляции в вашем коде:
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
Способ вывода результатов с помощью модели, скомпилированной в AOT:
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
Альтернативный подход заключается в JIT-компиляции модели во время выполнения на устройстве. Он более гибкий: требуется всего один файл модели, не зависящий от бэкенда.
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
Сравнительный анализ с использованием модели benchmark_model.
Утилита LiteRT benchmark_model (benchmark_model.exe) специально разработана для тестирования производительности модели, скомпилированной с помощью AOT, на NPU и может использоваться для сравнения производительности с бэкендом CPU (XNNPack) в LiteRT. Пример команды для тестирования производительности модели, скомпилированной с помощью AOT, на Intel NPU:
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
Проверка точности с помощью npu_numerics_check
Утилита npu_numerics_check используется для проверки численной точности модели, скомпилированной на NPU, по сравнению с базовой моделью (обычно это бэкенд для CPU, XNNPack). Этот шаг имеет решающее значение для обеспечения того, чтобы передача данных на NPU не приводила к неприемлемым численным отклонениям, которые могут повлиять на качество модели.
Проверка численных параметров. Утилита требует наличия модели, скомпилированной с помощью AOT, и сравнивает ее выходные данные с исходной моделью без делегирования, запущенной на ЦП.
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
Следующие шаги
- Начните с единого руководства по NPU: ускорение NPU с помощью LiteRT.
- Следуйте инструкциям по преобразованию и развертыванию, указанным там, выбрав Qualcomm, где это применимо.
- Для LLM-модулей см. раздел «Выполнение LLM-модулей на NPU с использованием LiteRT-LM» .