
LiteRT는 AOT 및 기기 내 컴파일 모두에 CompiledModel API를 통해 Intel OpenVino를 지원합니다.
Python API
개발 환경 설정
Linux (x86_64):
- Ubuntu 22.04 또는 24.04 LTS
- Python 3.10 이상: python.org 또는 배포판 (
sudo apt install python3 python3-venv)에서 설치 - Intel NPU 드라이버 v1.32.1 — Linux NPU 설정 참고
Windows (x86_64):
- Windows 10 또는 11
- Python 3.10 이상 - python.org에서 설치
- Intel NPU 드라이버 32.0.100.4724+ - Windows NPU 설정 참고
소스에서 빌드하려면 Bazelisk 또는 hermetic Docker 빌드를 사용하는 Bazel 7.4.1 이상도 필요합니다.
지원되는 SoC
| 플랫폼 | NPU | 코드명 | OS |
|---|---|---|---|
| Intel Core Ultra 시리즈 2 | NPU4000 | Lunar Lake (LNL) | Linux, Windows |
| Intel Core Ultra 시리즈 3 | NPU5010 | Panther Lake (PTL) | Linux, Windows |
빠른 시작
1. NPU 드라이버 설치
Linux NPU 설정 또는 Windows NPU 설정을 참고하세요. AOT만 필요한 경우 건너뜁니다.
NPU 드라이버는 NPU 하드웨어에서 모델을 실행하는 시스템에만 필요합니다. 순수 AOT 빌드 시스템은 이를 건너뛸 수 있습니다.
참고:
ai-edge-litert-sdk-intel-nightly는 PEP 440 버전 (예:openvino==2026.2.0.dev20260506)별로 일치하는 OpenVINO 야간 빌드 휠을 고정하므로 pip가 이를 찾으려면--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly가 필요합니다. Linux에서 배포 자동 감지가 잘못된 보관 파일을 선택하는 경우pip install전에LITERT_OV_OS_ID=ubuntu22또는ubuntu24을 설정하세요.
2. Python 가상 환경 만들기
야간 openvino 휠은 시스템 전체 OpenVINO 설치와 격리하는 것이 좋습니다.
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
3. pip 패키지 설치
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
--extra-index-url를 사용하면 pip가 PyPI의 패키지와 함께 OpenVINO의 색인에서 고정된 openvino 야간 휠을 확인할 수 있습니다.
4. 설치 확인
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
출력에서 확인할 사항:
SDK libs에는 AOT에 필요한libopenvino_intel_npu_compiler.so(Linux) 또는openvino_intel_npu_compiler.dll(Windows)이 나열됩니다.Available devices에는NPU가 포함되어 있습니다. 이는 NPU 드라이버가 설치되어 있고 OpenVINO가 기기와 통신할 수 있음을 확인합니다.NPU는 AOT 전용 시스템 (드라이버가 설치되지 않은 경우)과 Intel NPU 하드웨어가 없는 시스템에는 없습니다.
5. AOT 컴파일 (선택사항)
- 런타임이 컴파일러 플러그인 단계를 건너뛰도록 특정 Intel NPU 타겟 (PTL 또는 LNL)용
.tflite를 사전 컴파일합니다. - 실제 NPU나 NPU 드라이버가 필요하지 않습니다.
ai-edge-litert-nightly및ai-edge-litert-sdk-intel-nightly만 필요합니다. - 크로스 컴파일이 지원됩니다. Linux 또는 Windows 호스트에서 컴파일하고 결과
.tflite를 OS 타겟으로 전송하여 거기에서 운영합니다.
출력 파일의 이름은 <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite입니다.
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
6. NPU 추론 실행
LiteRT는 Intel NPU에서 두 가지 추론 경로를 지원합니다.
- JIT - 원시
.tflite를 로드합니다. 컴파일러 플러그인은CompiledModel.from_file()시간에 NPU용 지원되는 작업을 파티셔닝하고 컴파일합니다. 첫 실행 지연 시간을 추가합니다 (모델에 따라 다름). - AOT 컴파일됨 - 4단계에서 생성된
<model>_IntelOpenVINO_<SoC>_apply_plugin.tflite을 로드합니다. 로드 시 파티션 및 컴파일 단계를 건너뜁니다.
이 스니펫은 다음 두 가지 모두에 적용됩니다.
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
JIT가 실제로 실행되었는지 확인
JIT가 성공하면 로그에 다음이 포함됩니다 (파일 확장자는 Linux에서는 .so, Windows에서는 .dll).
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
이러한 줄이 없지만 Fully accelerated: True가 계속 보고되면 모델이 NPU가 아닌 XNNPACK CPU 대체에서 실행된 것입니다. JIT 문제 해결 행을 참고하세요.
7. 벤치마킹
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
일반적인 플래그:
| 플래그 | 기본값 | 설명 |
|---|---|---|
--model PATH
|
— | .tflite 모델의 경로입니다(필수). |
--signature KEY |
처음 | 실행할 서명 키입니다. |
--use_cpu/--no_cpu
|
위치 | CPU 가속기 / CPU 대체를 전환합니다. |
--use_gpu |
사용 안함 | GPU 가속기를 사용 설정합니다. |
--use_npu |
사용 안함 | Intel NPU 액셀러레이터를 사용 설정합니다. |
--require_full_delegation
|
사용 안함 | 모델이 선택한 액셀러레이터로 완전히 오프로드되지 않으면 실패합니다. |
--num_runs N
|
50 | 시간이 지정된 추론 반복 횟수입니다. |
--warmup_runs N
|
5 | 측정 전 시간 제한이 없는 워밍업 반복입니다. |
--num_threads N |
1 | CPU 스레드 수입니다. |
--result_json PATH
|
— | JSON 요약 (지연 시간 통계, 처리량, 액셀러레이터 목록)을 작성합니다. |
--verbose |
사용 안함 | 추가 런타임 로깅 |
고급 / 재정의 플래그: 맞춤 빌드를 가리키는 데만 필요합니다. --dispatch_library_path, --compiler_plugin_path, --runtime_path
혼합 공급업체 휠: JIT를 Intel OV에 고정
참고: 명시적 경로 없이
Environment.create()를 호출하면 알파벳순으로ai_edge_litert/vendors/아래의 공급업체를 자동 검색하고 찾은 첫 번째 공급업체를 등록합니다. 혼합 공급업체 설치에서는 Intel OV가 아닐 수 있습니다. 올바른 선택을 강제하려면 Intel OV 디렉터리를 명시적으로 전달하세요.
- pip 휠은 등록된 모든 공급업체(
intel_openvino/,google_tensor/,mediatek/,qualcomm/,samsung/)의 컴파일러 플러그인을 제공합니다. - Intel OV 경로를 강제하려면 (여러 공급업체 SDK가 설치된 경우 권장) Intel OV 디렉터리를 직접 전달하세요.
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
런타임은 지정된 디렉터리에서 찾은 모든 공유 라이브러리를 로드하므로 vendors/intel_openvino/compiler/를 가리키면 Intel 플러그인만 로드됩니다. 형제 디렉터리에 있는 Google Tensor / MediaTek / Qualcomm / Samsung 플러그인은 절대 건드리지 않습니다.
CLI의 경우 이에 상응하는 플래그는 다음과 같습니다.
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
NPU 실행 확인
모델이 실제로 NPU에서 실행되었는지 확인하려면 두 가지 신호를 모두 확인하세요.
- 로그에
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}이 포함되어 있습니다. Intel 디스패치 라이브러리가 로드되었습니다 (Linux의 경우.so, Windows의 경우.dll). model.is_fully_accelerated()는True를 반환합니다. 모든 작업이 선택된 가속기로 오프로드되었습니다.
is_fully_accelerated()만으로는 충분하지 않습니다. 디스패치 라이브러리가 로드되지 않으면 작업이 NPU가 아닌 XNNPACK/CPU로 완전히 오프로드됩니다.
Linux NPU 설정
참고: AOT만 필요한 경우 이 섹션을 건너뛰세요. 실제 NPU는 필요하지 않습니다.
정보: NPU 드라이버 v1.32.1(OpenVINO 2026.1과 페어링됨)을 사용합니다. 이전 드라이버가
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE로 인해 실패합니다.
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
그런 다음 퀵스타트에서 설치 + 확인 스니펫을 실행합니다.
Windows NPU 설정
참고: AOT만 필요한 경우 이 섹션을 건너뛰세요. 실제 NPU는 필요하지 않습니다.
- Intel 다운로드 센터에서 Intel NPU 드라이버 (32.0.100.4724+)를 설치합니다.
- 기기 관리자에 NPU 기기가 신경망 프로세서 아래에 나열되는지 확인합니다(드라이버에 따라
Intel(R) AI Boost또는Intel(R) NPU로 표시됨). - 퀵스타트에서 설치 + 확인 스니펫을 실행하여
pip을python -m pip로 바꿉니다.
정보:
import ai_edge_litert는os.add_dll_directory()을 사용하여 DLL 디렉터리를 자동 등록하므로 Python 스크립트에는PATH설정이 필요하지 않습니다. Python이 아닌 소비자의 경우setupvars.bat를 실행하거나PATH에<openvino>/libs를 추가합니다.
소스에서 빌드
프록시 뒤에 있나요? 빌드 스크립트를 실행하기 전에
http_proxy/https_proxy/no_proxy를 내보내세요. Docker 및 컨테이너로 전달됩니다.
Linux (Docker, hermetic):
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
Windows (PowerShell, Bazel이 PATH에 있음):
.\ci\build_pip_package_with_bazel_windows.ps1
dist/에 출력됩니다.
ai_edge_litert-*.whl- 런타임 휠ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz— 공급업체 sdists- Intel sdist는 약 5KB입니다. NPU 컴파일러
.so/.dll는pip install시간에 가져오므로 동일한 sdist가 Linux와 Windows에서 작동합니다.
단위 테스트
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
문제 해결
| 문제 | 수정 |
|---|---|
AOT 실패: Device with "NPU" name is not registered |
NPU 컴파일러를 가져오지 않았습니다. ai_edge_litert_sdk_intel.path_to_sdk_libs() 목록 libopenvino_intel_npu_compiler.so / .dll을 확인합니다. 비어 있으면 네트워크 액세스를 사용하여 다시 설치하거나 LITERT_OV_OS_ID=ubuntu22/ubuntu24을 설정합니다. |
JIT가 NPU 대신 CPU에서 실행됨 (Partitioned subgraph 로그 없음, Loaded plugin 로그 없음, Fully accelerated: True는 계속 출력됨) |
컴파일러 플러그인이 검색되지 않았습니다. ov.get_compiler_plugin_dir()가 ai_edge_litert/vendors/intel_openvino/compiler/ 아래의 경로를 반환하는지 확인합니다. 여러 공급업체 SDK가 설치된 경우 compiler_plugin_path=ov.get_compiler_plugin_dir()를 Environment.create()에 명시적으로 전달합니다 (또는 --compiler_plugin_path=...를 litert-benchmark에 전달). |
JIT 실패: Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so (Linux) / openvino_intel_npu_compiler.dll (Windows) |
SDK sdist는 첫 번째 import ai_edge_litert_sdk_intel에서 NPU 컴파일러를 openvino/libs/에 복사합니다. 복사가 건너뛰어진 경우 (읽기 전용 FS, openvino 누락) openvino가 설치된 후 ai-edge-litert-sdk-intel을 다시 설치하고 새 프로세스에서 import ai_edge_litert을 설치합니다. |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE |
NPU 드라이버를 v1.32.1 (Linux)로 업그레이드 |
/dev/accel/accel0 찾을 수 없음 |
sudo dmesg | grep -i vpu: 드라이버 디버깅, 설치 후 재부팅 |
| NPU에 대한 권한이 거부됨 | sudo gpasswd -a ${USER} render && newgrp render. |
| Windows: 기기 관리자에 NPU가 없음 | Intel 다운로드 센터에서 NPU 드라이버 32.0.100.4724 이상을 설치합니다. |
Windows: Failed to initialize Dispatch API / DLL 누락 |
import ai_edge_litert가 먼저 실행되는지 확인합니다 (DLL 디렉터리 자동 등록). Python이 아닌 호출자의 경우 setupvars.bat를 실행하거나 PATH 앞에 <openvino>/libs를 추가합니다. |
Windows 빌드: LNK2001 fixed_address_empty_string, C2491 dllimport, Python 3.12+ fails |
Protobuf ABI / Python 버전 제약 조건 - ci/build_pip_package_with_bazel_windows.ps1 참고, Windows 빌드에는 Python 3.11이 필요함 |
제한사항
NPU 기기만 OpenVINO 디스패치 경로를 통해 지원됩니다. CPU 추론의 경우 HardwareAccelerator.CPU만 사용합니다 (XNNPACK).
C++ API
기본 요건 및 빌드 설정
빌드 기본 요건:
- Visual Studio 2022 이상 (C++ 개발 도구가 설치되어 있어야 함)
- git: https://git-scm.com/install/에서 git을 설치합니다. LiteRT/LiteRT-LM 빌드 프로세스에서 bash.exe 및 git.exe를 찾을 수 있도록
C:\Program Files\Git\bin and C:\Program Files\Git\cmd가 시스템의 PATH 환경 변수에 포함되어 있는지 확인합니다. - bazelisk: bazelisk를 설치하고 시스템의
PATH환경 변수에 위치를 포함합니다(https://bazel.build/install/bazelisk). - CMake: https://cmake.org/download/에서 CMake 버전 4.3.0 이상을 설치하여 CMake가 시스템의 PATH에 포함되어 있는지 확인합니다.
- Python: Python 3.11 이상이 설치되어 있고 python.exe가 PATH에 있는지 확인합니다.
- Windows 설정: Windows 설정 내에서 개발자 모드를 사용 설정합니다.
Intel NPU용 LiteRT 도구 및 플러그인 빌드
LiteRT를 사용하여 Intel NPU에서 모델을 실행하려면 LiteRT Intel OpenVINO 컴파일러 플러그인을 사용하여 컴파일해야 합니다. 또한 Intel NPU에서 실행하기 위해 컴파일된 모델은 LiteRT Intel OpenVINO 디스패치 플러그인에 위임해야 합니다.
LiteRT가 이러한 플러그인을 호출하는 메커니즘은 다음과 같습니다.
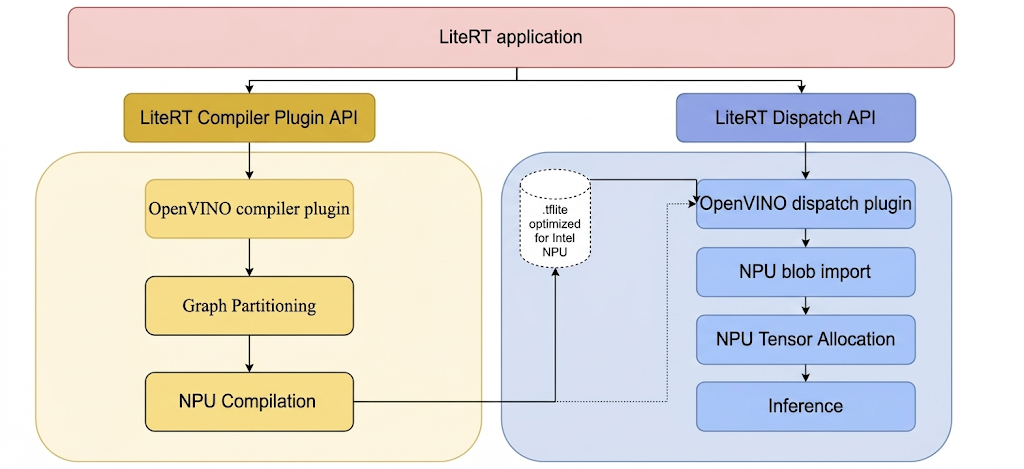
LiteRT 도구 및 Intel 플러그인을 빌드하는 단계
LiteRT에서 실행 파일이나 라이브러리를 빌드하기 전에 C:\bzl과 같은 로컬 디렉터리를 만듭니다. 빌드 출력 바이너리는 이 디렉터리에서 수집됩니다. Intel OpenVINO 디스패치 플러그인 빌드
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
또는 타겟에 @litert 접두사를 추가하여 LiteRT-LM 저장소에서 디스패치 플러그인을 빌드할 수도 있습니다. 이는 LiteRT 저장소의 다음 타겟에도 유사합니다.
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Intel OpenVINO 컴파일러 플러그인 빌드
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
LiteRT Ahead-of-Time (AOT) 컴파일러 유틸리티 빌드 일부 LiteRT 도구는 Intel NPU에서 실행하기 전에 모델의 명시적 AOT 컴파일이 필요합니다. LiteRT AOT 컴파일러 유틸리티의 빌드 안내:
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
LiteRT 모델 러너 빌드 LiteRT 모델 러너는 사전 컴파일되지 않은 모델이나 AOT 컴파일 모델을 비롯한 Intel NPU에서 모델을 실행하는 데 사용할 수 있습니다. 모델 러너를 빌드하는 명령어:
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
LiteRT 벤치마크 모델 유틸리티 빌드 LiteRT 모델 벤치마크 도구를 사용하여 Intel NPU에서 모델 추론 성능을 벤치마크할 수 있습니다. 벤치마크 도구를 빌드하라는 안내가 있는 경우:
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
LiteRT 숫자 확인 유틸리티 빌드
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
고급 사용: 맞춤 Intel OpenVINO SDK로 빌드
LiteRT 빌드 시스템은 컴파일러와 디스패치 플러그인을 컴파일할 때 미리 빌드된 Intel OpenVINO SDK를 자동으로 가져옵니다.
프로젝트에 특정 또는 맞춤 버전의 Intel OpenVINO SDK가 필요한 경우 플러그인 빌드를 시작하기 전에 다음 추가 구성 단계를 완료하세요.
- https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html에서 Windows용 최신 OpenVINO 출시 바이너리를 다운로드하고 로컬 디스크(예:
C:\Intel\intel_openvino)에 추출합니다. - 이 경로 아래의 유일한 하위 디렉터리 이름이 'openvino'이고 'runtime', 'include'와 같은 하위 디렉터리가 포함되어 있는지 확인합니다.
- 콘솔(명령 프롬프트 또는 PowerShell)에서 복제된 LiteRT 저장소의 루트 디렉터리로 이동하고 OPENVINO_NATIVE_DIR 변수를 설정합니다(후행
\`), for example:가 없는지 확인).
커스텀 모델의 AOT 컴파일
이 섹션에서는 환경을 준비하고 LiteRT용 맞춤 TFLite, PyTorch 또는 JAX 모델의 AOT 컴파일을 실행합니다.
Intel NPU의 모델 컴파일 프로세스 중에 LiteRT는 LiteRT Intel OpenVINO 컴파일러 플러그인에서 지원하는 연산자에 대해 모델 그래프를 검증합니다. 컴파일러 플러그인과 호환되는 연산자 또는 하위 그래프의 경우 LiteRT는 이러한 각 하위 그래프를 DISPATCH_OP로 컴파일하며 이는 이후 그래프 내에서 원래 하위 그래프를 대체합니다. Intel OpenVINO 컴파일러에서 지원하는 opset에 포함되지 않은 연산자는 그래프 내에서 변경되지 않습니다. 따라서 AOT 컴파일은 완전히 위임된 모델이나 부분적으로 위임된 모델을 생성할 수 있습니다. 다음은 완전히 위임된 AOT 컴파일 모델의 예입니다.
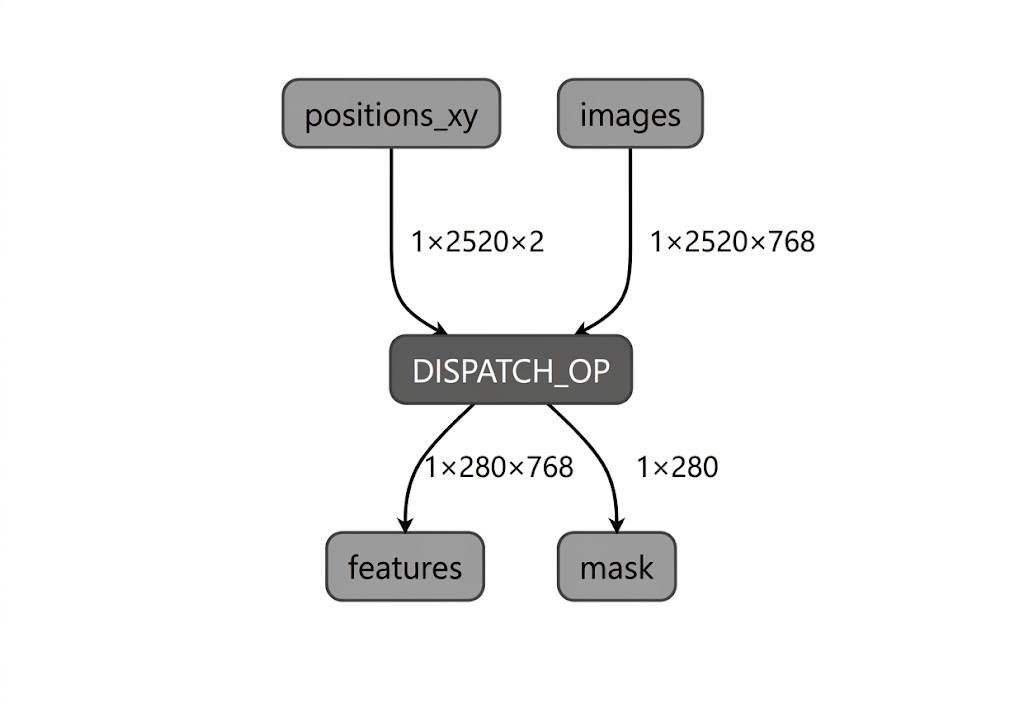
LiteRT apply_plugin_main 유틸리티 (apply_plugin_main.exe)는 이 용도로 사용할 수 있는 AOT 컴파일 유틸리티입니다. Intel 플랫폼에서 유틸리티를 사용하는 샘플은 다음과 같습니다.
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
Intel OpenVINO SDK의 바이너리 배포에 포함된 기본 NPU 컴파일러는 Intel Core Ultra Series 2 및 이후 SoC에 사용됩니다. 지원 목록에 없는 NPU용으로 모델을 컴파일하는 경우 컴파일러 유형을 명시적으로 지정해야 합니다 (Intel Core Ultra 2 이상에서는 선택사항으로 유지됨).
set IE_NPU_COMPILER_TYPE=PLUGIN
애플리케이션의 JIT 컴파일과 AOT 컴파일 비교
자체 LiteRT 애플리케이션에서 모델을 컴파일하는 방법에는 이미 소개한 AOT 컴파일과 JIT (Just-in-time) 컴파일의 두 가지가 있습니다.
AOT 컴파일을 사용하면 배포 전에 오프라인으로 모드가 컴파일되며 나중에 사용할 수 있도록 저장할 수 있습니다. 이는 컴파일이 리소스 집약적이어서 기기에서 실행할 수 없는 경우에 흔히 사용됩니다. 모델을 배포하는 기기에서 실행하지 않아도 됩니다. 코드에서 AOT 컴파일의 예:
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
AOT 컴파일 모델로 추론하는 방법은 다음과 같습니다.
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
대안은 기기에서 런타임에 모델을 JIT 컴파일하는 것입니다. 더 유연합니다. 백엔드에 구애받지 않는 단일 모델 파일만 필요합니다.
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
benchmark_model로 벤치마크
LiteRT benchmark_model 유틸리티 (benchmark_model.exe)는 NPU에서 AOT 컴파일된 모델을 벤치마킹하도록 특별히 설계되었으며, LiteRT에서 CPU 백엔드 (XNNPack)와 성능을 비교하는 데 사용할 수 있습니다. Intel NPU에서 AOT 컴파일된 모델을 벤치마킹하는 명령어의 예는 다음과 같습니다.
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
npu_numerics_check를 사용한 정확성 검사
npu_numerics_check 유틸리티는 NPU 컴파일 모델의 숫자 정확성을 기준 (일반적으로 CPU 백엔드, XNNPack)과 비교하여 확인하는 데 사용됩니다. 이 단계는 NPU에 위임으로 인해 모델 품질에 영향을 미칠 수 있는 허용되지 않는 수치 편차가 발생하지 않도록 하는 데 중요합니다.
숫자 확인 실행 이 유틸리티는 AOT 컴파일된 모델이 필요하며 출력을 CPU에서 실행되는 원래 위임되지 않은 모델과 비교합니다.
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
다음 단계
- 통합 NPU 가이드인 LiteRT를 사용한 NPU 가속을 시작하세요.
- 해당 위치에서 전환 및 배포 단계를 따르고 해당하는 경우 Qualcomm을 선택합니다.
- LLM의 경우 LiteRT-LM을 사용하여 NPU에서 LLM 실행을 참고하세요.