
O LiteRT é compatível com o Intel OpenVino pela API CompiledModel
para compilação AOT e no dispositivo.
API Python
Configurar o ambiente de desenvolvimento
Linux (x86_64):
- Ubuntu 22.04 ou 24.04 LTS
- Python 3.10 ou mais recente: instale em python.org
ou na sua distribuição (
sudo apt install python3 python3-venv) - Driver da NPU da Intel v1.32.1: consulte Configuração da NPU do Linux
Windows (x86_64):
- Windows 10 ou 11
- Python 3.10 ou mais recente: instale em python.org
- Driver da NPU Intel 32.0.100.4724+. Consulte Configuração da NPU do Windows.
Para criar do código-fonte, também é necessário o Bazel 7.4.1+ usando o Bazelisk ou o build hermético do Docker.
SoCs compatíveis
| Plataforma | NPU | Codinome | SO |
|---|---|---|---|
| Intel Core Ultra Série 2 | NPU4000 | Lunar Lake (LNL) | Linux, Windows |
| Intel Core Ultra Série 3 | NPU5010 | Panther Lake (PTL) | Linux, Windows |
Início rápido
1. Instalar drivers de NPU
Consulte Configuração da NPU no Linux ou Configuração da NPU no Windows. Pule se você só precisar de AOT.
O driver da NPU só é necessário em sistemas que executam o modelo no hardware da NPU. Sistemas de build AOT puro podem ignorar essa etapa.
Observação:
ai-edge-litert-sdk-intel-nightlyfixa a roda noturna correspondente do OpenVINO pela versão PEP 440 (por exemplo,openvino==2026.2.0.dev20260506). Portanto, o pip precisa de--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightlypara localizá-la. No Linux, se a detecção automática de distribuição escolher o arquivo errado, definaLITERT_OV_OS_ID=ubuntu22ouubuntu24antes depip install.
2. Criar um ambiente virtual em Python
Recomendado para manter a roda openvino noturna isolada de qualquer instalação do OpenVINO em todo o sistema.
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
3. Instalar o pacote pip
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
O --extra-index-url permite que o pip resolva a roda noturna openvino fixada
do índice do OpenVINO junto com os pacotes no PyPI.
4. Verifique a instalação
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
O que verificar na saída:
SDK libslistalibopenvino_intel_npu_compiler.so(Linux) ouopenvino_intel_npu_compiler.dll(Windows), obrigatório para AOT.Available devicesincluiNPU: confirma que o driver da NPU está instalado e que o OpenVINO pode se comunicar com o dispositivo. ONPUnão vai aparecer em sistemas somente com AOT (em que o driver não está instalado) e em sistemas sem hardware de NPU Intel.
5. Compilação AOT (opcional)
- Pré-compila um
.tflitepara um destino específico da NPU Intel (PTL ou LNL) para que o tempo de execução pule a etapa do plug-in do compilador. - Não precisa de uma NPU física ou do driver de NPU, apenas
ai-edge-litert-nightlyeai-edge-litert-sdk-intel-nightly. - A compilação cruzada é compatível: compile em qualquer host Linux ou Windows, envie
o
.tfliteresultante para um destino de qualquer SO e execute-o lá.
Os arquivos de saída são nomeados como <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite.
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
6. Executar inferência de NPU
O LiteRT é compatível com dois caminhos de inferência na NPU da Intel:
- JIT: carrega um
.tflitebruto. O plug-in do compilador particiona e compila operações compatíveis para a NPU no tempoCompiledModel.from_file(). Adiciona alguma latência de primeira execução (varia de acordo com o modelo). - Compilado com AOT: carrega um
<model>_IntelOpenVINO_<SoC>_apply_plugin.tfliteproduzido na etapa 4. Pula a etapa de partição e compilação no tempo de carregamento.
Este snippet funciona para os dois casos:
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
Confirmar se o JIT foi executado
Quando o JIT é bem-sucedido, o registro contém (a extensão do arquivo é .so no Linux e .dll no
Windows):
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
Se essas linhas estiverem ausentes, mas Fully accelerated: True ainda for informado, o modelo foi executado no fallback da CPU XNNPACK, não na NPU. Consulte a linha de solução de problemas do JIT.
7. Comparativo de mercado
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
Flags comuns:
| Sinalização | padrão | Descrição |
|---|---|---|
--model PATH
|
— | Caminho para o modelo .tflite (obrigatório). |
--signature KEY |
primeiro | Chave de assinatura a ser executada. |
--use_cpu / --no_cpu
|
ativado | Ative/desative o acelerador de CPU / fallback de CPU. |
--use_gpu |
desativado | Ative o acelerador de GPU. |
--use_npu |
desativado | Ative o acelerador Intel NPU. |
--require_full_delegation
|
desativado | Falha se o modelo não for totalmente descarregado para o acelerador selecionado. |
--num_runs N
|
50 | Número de iterações de inferência com tempo. |
--warmup_runs N
|
5 | Iterações de aquecimento sem tempo antes da medição. |
--num_threads N |
1 | Contagem de linhas de execução da CPU. |
--result_json PATH
|
— | Escreva um resumo em JSON (estatísticas de latência, capacidade de processamento, lista de aceleradores). |
--verbose |
desativado | Registro extra do ambiente de execução. |
Flags avançadas / de substituição: necessárias apenas para apontar para builds personalizados:
--dispatch_library_path, --compiler_plugin_path, --runtime_path.
Roda de vários fornecedores: fixação do JIT no Intel OV
Observação:quando
Environment.create()é chamado sem caminhos explícitos, ele descobre automaticamente os fornecedores emai_edge_litert/vendors/em ordem alfabética e registra o primeiro que encontrar. Em uma instalação de vários fornecedores, talvez não seja o OV da Intel. Transmita os diretórios do OV da Intel explicitamente para forçar a escolha certa.
- A roda do pip envia plug-ins de compilador para todos os fornecedores registrados
(
intel_openvino/,google_tensor/,mediatek/,qualcomm/,samsung/). - Para forçar o caminho do Intel OV (recomendado quando vários SDKs de fornecedores estão instalados), transmita os diretórios do Intel OV manualmente:
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
O ambiente de execução carrega todas as bibliotecas compartilhadas encontradas no diretório especificado. Portanto, apontar para vendors/intel_openvino/compiler/ carrega apenas o plug-in da Intel. Os plug-ins do Google Tensor / MediaTek / Qualcomm / Samsung em diretórios irmãos nunca são tocados.
Para a CLI, as flags equivalentes são:
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
Verificar a execução da NPU
Para confirmar se o modelo foi executado na NPU, verifique os dois indicadores:
- O registro contém
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}. A biblioteca de envio da Intel foi carregada (.sono Linux,.dllno Windows). model.is_fully_accelerated()retornaTrue: todas as operações foram descarregadas para o acelerador selecionado.
Apenas is_fully_accelerated() não é suficiente: se a biblioteca de
envio nunca for carregada, as operações serão totalmente descarregadas para XNNPACK/CPU, não para a NPU.
Configuração da NPU do Linux
Observação:ignore esta seção se você só precisar de AOT. Uma NPU física não é necessária.
Informações:use o driver de NPU v1.32.1 (combinado com o OpenVINO 2026.1). Drivers mais antigos falham com
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE.
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
Em seguida, execute o snippet de instalação e verificação do início rápido.
Configuração da NPU do Windows
Observação:ignore esta seção se você só precisar de AOT. Uma NPU física não é necessária.
- Instale o driver da NPU Intel (32.0.100.4724+) na Central de downloads da Intel.
- Verifique se o Gerenciador de dispositivos lista o dispositivo NPU em Processadores neurais
(mostrado como
Intel(R) AI BoostouIntel(R) NPU, dependendo do driver). - Execute o snippet de instalação e verificação do início rápido, substituindo
pipporpython -m pip.
Informação:o
import ai_edge_litertregistra automaticamente os diretórios de DLL usandoos.add_dll_directory(). Portanto, os scripts Python não precisam de configuração dePATH. Para consumidores que não usam Python, executesetupvars.batou adicione<openvino>/libsantes dePATH.
Criar a partir da fonte
Atrás de um proxy? Exporte
http_proxy/https_proxy/no_proxyantes de executar os scripts de build. Eles encaminham essas informações para o Docker e o contêiner.
Linux (Docker, hermético):
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
Windows (PowerShell, Bazel em PATH):
.\ci\build_pip_package_with_bazel_windows.ps1
As saídas ficam em dist/:
ai_edge_litert-*.whl: a roda de ambiente de execução.ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz— sdists do fornecedor.- O sdist da Intel tem cerca de 5 KB. O compilador de NPU
.so/.dllé buscado no tempopip install. Assim, o mesmo sdist funciona no Linux e no Windows.
Testes de unidade
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
Solução de problemas
| Problema | Correção |
|---|---|
Falha na AOT: Device with "NPU" name is not registered |
O compilador da NPU não foi buscado. Confira as listas ai_edge_litert_sdk_intel.path_to_sdk_libs() libopenvino_intel_npu_compiler.so / .dll. Se estiver vazio, reinstale com acesso à rede ou defina LITERT_OV_OS_ID=ubuntu22/ubuntu24. |
O JIT é executado na CPU em vez da NPU (sem registro Partitioned subgraph, sem registro Loaded plugin, Fully accelerated: True ainda impresso) |
O plug-in do compilador não foi descoberto. Confirme se ov.get_compiler_plugin_dir() retorna um caminho em ai_edge_litert/vendors/intel_openvino/compiler/. Se vários SDKs de fornecedores estiverem instalados, transmita compiler_plugin_path=ov.get_compiler_plugin_dir() explicitamente para Environment.create() (ou --compiler_plugin_path=... para litert-benchmark). |
Falha no JIT: Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so (Linux) / openvino_intel_npu_compiler.dll (Windows) |
O sdist do SDK copia o compilador de NPU para openvino/libs/ na primeira import ai_edge_litert_sdk_intel. Se a cópia foi ignorada (sistema de arquivos somente leitura, openvino ausente), reinstale ai-edge-litert-sdk-intel depois que openvino for instalado e, em seguida, import ai_edge_litert em um novo processo. |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE |
Faça upgrade do driver de NPU para a v1.32.1 (Linux). |
/dev/accel/accel0 não encontrado |
sudo dmesg | grep -i vpu para depurar o driver; reinicie após a instalação. |
| Permissão negada na NPU | sudo gpasswd -a ${USER} render && newgrp render. |
| Windows: a NPU não está no Gerenciador de dispositivos | Instale o driver da NPU 32.0.100.4724+ na Central de downloads da Intel. |
Windows: Failed to initialize Dispatch API / DLLs ausentes |
Verifique se import ai_edge_litert é executado primeiro (registra automaticamente os diretórios de DLL). Para chamadores que não são Python, execute setupvars.bat ou adicione <openvino>/libs antes de PATH. |
Build do Windows: LNK2001 fixed_address_empty_string, C2491 dllimport, Python 3.12+ fails |
Restrição de ABI do Protobuf / versão do Python: consulte ci/build_pip_package_with_bazel_windows.ps1. Os builds do Windows exigem o Python 3.11. |
Limitações
Somente o dispositivo NPU é compatível com o caminho de envio do OpenVINO. Para inferência de CPU, use apenas HardwareAccelerator.CPU (XNNPACK).
API C++
Pré-requisitos e configuração de build
Pré-requisitos de build:
- Visual Studio 2022 ou mais recente (as ferramentas de desenvolvimento em C++ precisam estar instaladas).
- git: instale o git em https://git-scm.com/install/. Verifique se
C:\Program Files\Git\bin and C:\Program Files\Git\cmdestão incluídos na variável de ambiente PATH do sistema para permitir que bash.exe e git.exe sejam localizados pelos processos de build do LiteRT/LiteRT-LM. - bazelisk: instale o bazelisk e inclua o local dele na variável de ambiente
PATHdo seu sistema: https://bazel.build/install/bazelisk. - Cmake: instale a versão 4.3.0 ou mais recente em https://cmake.org/download/ e verifique se o Cmake está incluído no PATH do sistema.
- Python: verifique se o Python 3.11 ou uma versão mais recente está instalado e se o python.exe está no seu PATH.
- Configurações do Windows: ative o modo de desenvolvedor nas configurações do Windows.
Criar ferramentas e plug-ins LiteRT para a NPU da Intel
Para executar modelos na NPU da Intel com o LiteRT, eles precisam ser compilados usando o plug-in compilador LiteRT Intel OpenVINO. Além disso, qualquer modelo compilado destinado à execução na NPU da Intel precisa ser delegado ao plug-in de despacho LiteRT Intel OpenVINO.
O mecanismo pelo qual o LiteRT invoca esses plug-ins é ilustrado a seguir:
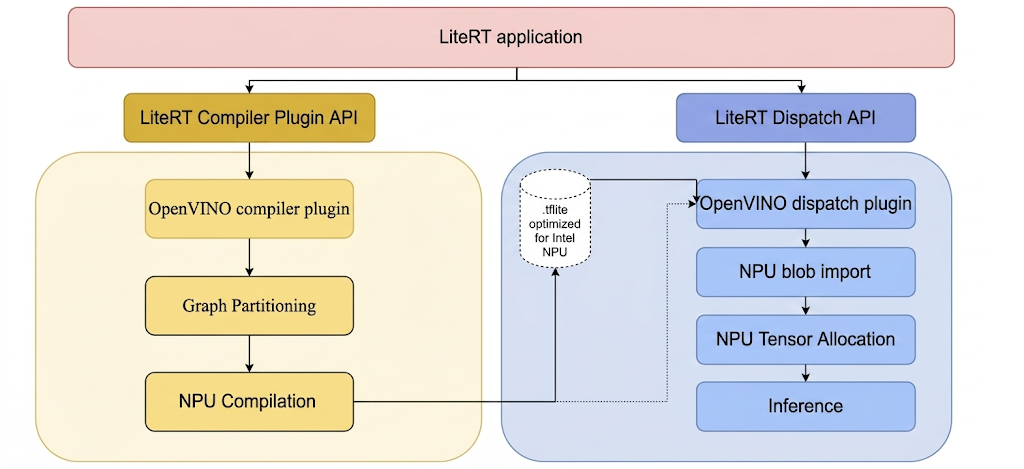
Etapas para criar ferramentas LiteRT e plug-ins Intel.
Antes de criar qualquer executável ou biblioteca do LiteRT, crie um diretório local, por exemplo, C:\bzl. O binário de saída do build será coletado deste diretório. Criar o plug-in de envio do Intel OpenVINO
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Como alternativa, você também pode criar o plug-in de envio do repositório
LiteRT-LM adicionando um prefixo @litert à meta. Isso é semelhante para todas as metas a seguir do repositório LiteRT.
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Criar o plug-in do compilador Intel OpenVINO
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
Crie o utilitário do compilador LiteRT Ahead-of-Time (AOT). Algumas ferramentas do LiteRT exigem a compilação AOT explícita de modelos antes de serem executados na NPU da Intel. Instrução de build do utilitário do compilador AOT do LiteRT:
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
Criar um executor de modelos LiteRT O executor de modelos LiteRT pode ser usado para executar um modelo na NPU da Intel, seja um modelo não pré-compilado ou um modelo compilado com AOT. A instrução para criar o executor de modelos:
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
Criar uma utilidade de modelo de comparativo de mercado do LiteRT A ferramenta de comparativo de mercado do modelo LiteRT pode ser usada para comparar o desempenho da inferência de um modelo na NPU da Intel. Se a instrução for para criar a ferramenta de comparativo:
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
Criar utilitário de verificação de números LiteRT
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
Uso avançado: crie com o SDK Intel OpenVINO personalizado
O sistema de build do LiteRT busca automaticamente o SDK Intel OpenVINO pré-criado ao compilar o compilador e os plug-ins de envio.
Se o projeto exigir uma versão específica ou personalizada do SDK Intel OpenVINO, conclua estas etapas de configuração adicionais antes de iniciar o build do plug-in:
- Faça o download do binário da versão mais recente do OpenVINO para Windows em
https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html,
e extraia para o disco local, por exemplo,
C:\Intel\intel_openvino. - Verifique se o único diretório filho nesse caminho se chama "openvino" e contém subdiretórios como "runtime" e "include".
- Acesse o diretório raiz do repositório LiteRT clonado no console
(prompt de comando ou PowerShell) e defina a variável OPENVINO_NATIVE_DIR.
(verifique se não há um
\`), for example:set OPENVINO_NATIVE_DIR=C:\Intel\intel_openvino`
Compilação AOT de modelos personalizados
Esta seção prepara o ambiente e realiza a compilação AOT de modelos personalizados do TFLite, PyTorch ou JAX para o LiteRT.
Durante o processo de compilação do modelo para a NPU da Intel, o LiteRT valida o gráfico do modelo em relação aos operadores compatíveis com o plug-in do compilador LiteRT Intel OpenVINO. Para operadores ou subgrafos compatíveis com o plug-in do compilador, o LiteRT compila cada subgrafo em um DISPATCH_OP que substitui o subgrafo original no gráfico. Os operadores não incluídos no conjunto de operações compatível com o compilador Intel OpenVINO permanecem inalterados no gráfico. Consequentemente, a compilação AOT pode gerar um modelo totalmente delegado ou parcialmente delegado. Confira um exemplo de modelo totalmente delegado e compilado com AOT:
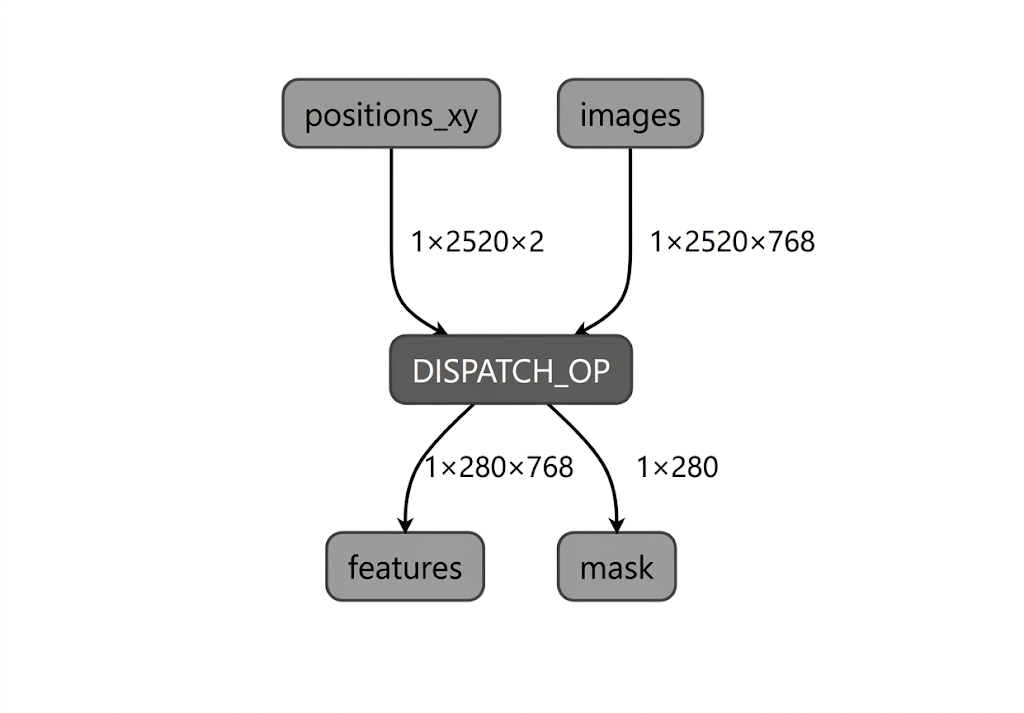
O utilitário LiteRT apply_plugin_main (apply_plugin_main.exe) é o utilitário de compilação AOT que você pode usar para essa finalidade. Um exemplo de uso do utilitário na plataforma Intel:
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
Observe que o compilador de NPU subjacente padrão, que está incluído na distribuição binária do SDK Intel OpenVINO, é utilizado para a série Intel Core Ultra 2 e SoCs subsequentes. Se um modelo estiver sendo compilado para uma NPU que não está na lista de compatibilidade, o tipo de compilador precisará ser especificado explicitamente. No entanto, isso continua sendo opcional para o Intel Core Ultra 2 e versões mais recentes.
set IE_NPU_COMPILER_TYPE=PLUGIN
Compilação JIT x AOT no seu aplicativo
Para compilar modelos no seu próprio aplicativo LiteRT, há duas abordagens: a compilação AOT, que já apresentamos, e a compilação just-in-time (JIT).
Com a compilação AOT, o modo é compilado off-line antes da implantação e pode ser salvo para uso posterior. Isso é usado com frequência quando a compilação é muito pesada para ser executada no dispositivo. Não é necessário fazer isso no mesmo dispositivo em que você está implantando o modelo. Exemplo de compilação AOT no seu código:
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
A maneira de fazer inferência com um modelo compilado com AOT:
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
A abordagem alternativa é compilar o modelo JIT durante a execução no dispositivo. Ele é mais flexível: só exige um arquivo modelo independente do back-end.
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
Comparar com benchmark_model
O utilitário benchmark_model do LiteRT (benchmark_model.exe) foi projetado especificamente para comparar um modelo compilado com AOT em NPU e pode ser usado para comparar o desempenho com o backend da CPU (XNNPack) no LiteRT. Exemplo de comando para fazer o comparativo de um modelo compilado com AOT em uma NPU Intel:
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
Verificação de precisão com npu_numerics_check
O utilitário npu_numerics_check é usado para verificar a precisão numérica de um modelo compilado para NPU em relação a um valor de referência (normalmente o back-end da CPU, XNNPack). Essa etapa é crucial para garantir que a delegação à NPU não introduza desvios numéricos inaceitáveis que possam afetar a qualidade do modelo.
Executar a verificação numérica O utilitário exige o modelo compilado com AOT e compara as saídas dele com o modelo original, não delegado, executado na CPU.
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
Próximas etapas
- Comece com o guia unificado de NPU: Aceleração de NPU com LiteRT
- Siga as etapas de conversão e implantação, escolhendo Qualcomm quando aplicável.
- Para LLMs, consulte Executar LLMs em NPUs usando o LiteRT-LM.