
LiteRT รองรับ Intel OpenVino ผ่าน CompiledModel API
ทั้งสำหรับการคอมไพล์ AOT และการคอมไพล์ในอุปกรณ์
Python API
ตั้งค่าสภาพแวดล้อมในการพัฒนาซอฟต์แวร์
Linux (x86_64):
- Ubuntu 22.04 หรือ 24.04 LTS
- Python 3.10 ขึ้นไป - ติดตั้งจาก python.org
หรือจาก distro (
sudo apt install python3 python3-venv) - ไดรเวอร์ NPU ของ Intel v1.32.1 - ดูการตั้งค่า NPU ของ Linux
Windows (x86_64):
- Windows 10 หรือ 11
- Python 3.10 ขึ้นไป - ติดตั้งจาก python.org
- ไดรเวอร์ NPU ของ Intel 32.0.100.4724+ — ดูการตั้งค่า NPU ของ Windows
สำหรับการสร้างจากแหล่งที่มา คุณต้องใช้ Bazel 7.4.1 ขึ้นไปโดยใช้ Bazelisk หรือบิลด์ Docker แบบปิด
SoC ที่รองรับ
| แพลตฟอร์ม | NPU | ชื่อรหัส | ระบบปฏิบัติการ |
|---|---|---|---|
| Intel Core Ultra Series 2 | NPU4000 | Lunar Lake (LNL) | Linux, Windows |
| Intel Core Ultra Series 3 | NPU5010 | Panther Lake (PTL) | Linux, Windows |
คู่มือเริ่มต้นฉบับย่อ
1. ติดตั้งไดรเวอร์ NPU
ดูการตั้งค่า NPU ใน Linux หรือ การตั้งค่า NPU ใน Windows ข้ามหากคุณต้องการใช้เฉพาะ AOT
คุณจะต้องมีไดรเวอร์ NPU ในระบบที่เรียกใช้โมเดลในฮาร์ดแวร์ NPU เท่านั้น ระบบที่สร้างด้วย AOT อย่างเดียวจะข้ามขั้นตอนนี้ได้
หมายเหตุ:
ai-edge-litert-sdk-intel-nightlyจะปักหมุดวงล้อ OpenVINO รุ่นทดลองรายคืนที่ตรงกันตามเวอร์ชัน PEP 440 (เช่นopenvino==2026.2.0.dev20260506) ดังนั้น pip จึงต้องใช้--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightlyเพื่อค้นหา ใน Linux หากการตรวจหาอัตโนมัติของ Distro เลือกที่เก็บที่ไม่ถูกต้อง ให้ตั้งค่าLITERT_OV_OS_ID=ubuntu22หรือubuntu24ก่อนpip install
2. สร้างสภาพแวดล้อมเสมือนของ Python
ขอแนะนำให้แยกวงล้อ openvino ของรุ่นทดลองรายคืนออกจาก OpenVINO ที่ติดตั้งทั่วทั้งระบบ
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
3. ติดตั้งแพ็กเกจ pip
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
--extra-index-url ช่วยให้ pip แก้ไข openvino ไนท์ลีวีล
ที่ปักหมุดจากดัชนีของ OpenVINO พร้อมกับแพ็กเกจใน PyPI
4. ยืนยันการติดตั้ง
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
สิ่งที่ต้องตรวจสอบในเอาต์พุต
SDK libslibopenvino_intel_npu_compiler.so(Linux) หรือopenvino_intel_npu_compiler.dll(Windows) — ต้องระบุสำหรับ AOTAvailable devicesมีNPUซึ่งยืนยันว่าได้ติดตั้งไดรเวอร์ NPU แล้ว และ OpenVINO สามารถสื่อสารกับอุปกรณ์ได้NPUจะไม่มีในระบบที่ใช้ AOT เท่านั้น (ซึ่งไม่ได้ติดตั้งไดรเวอร์) และในระบบที่ไม่มีฮาร์ดแวร์ Intel NPU
5. การคอมไพล์ AOT (ไม่บังคับ)
- คอมไพล์ล่วงหน้าสำหรับเป้าหมาย Intel NPU ที่เฉพาะเจาะจง (PTL หรือ LNL) เพื่อให้รันไทม์ข้ามขั้นตอนปลั๊กอินคอมไพเลอร์
.tflite - ไม่จำเป็นต้องมี NPU จริงหรือไดรเวอร์ NPU เพียงแค่
ai-edge-litert-nightlyและai-edge-litert-sdk-intel-nightly - รองรับการคอมไพล์แบบข้ามระบบ: คอมไพล์แบบข้ามระบบในโฮสต์ Linux หรือ Windows ใดก็ได้ แล้วส่ง
.tfliteที่ได้ไปยังเป้าหมายของระบบปฏิบัติการใดก็ได้และดำเนินการที่นั่น
ไฟล์เอาต์พุตจะตั้งชื่อเป็น <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
6. เรียกใช้การอนุมาน NPU
LiteRT รองรับเส้นทางการอนุมาน 2 เส้นทางใน NPU ของ Intel ดังนี้
- JIT - โหลด
.tfliteดิบ ปลั๊กอินคอมไพเลอร์จะแบ่งพาร์ติชันและคอมไพล์ การดำเนินการที่รองรับสำหรับ NPU ในเวลาCompiledModel.from_file()เพิ่มเวลาในการตอบสนองครั้งแรก (แตกต่างกันไปตามรุ่น) - คอมไพล์ AOT - โหลด
<model>_IntelOpenVINO_<SoC>_apply_plugin.tfliteที่สร้างขึ้นในขั้นตอนที่ 4 ข้ามขั้นตอนการแบ่งพาร์ติชันและการคอมไพล์ในเวลาที่ใช้ในการโหลด
ข้อมูลโค้ดนี้ใช้ได้กับทั้ง 2 อย่างต่อไปนี้
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
ยืนยันว่า JIT ทำงานแล้ว
เมื่อ JIT ทำงานสำเร็จ บันทึกจะมี (นามสกุลไฟล์คือ .so ใน Linux และ .dll ใน
Windows)
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
หากไม่มีบรรทัดดังกล่าว แต่ยังมีการรายงาน Fully accelerated: True แสดงว่าโมเดลทำงานใน XNNPACK CPU Fallback ไม่ใช่ใน NPU โปรดดูแถวการแก้ปัญหา JIT
7. เปรียบเทียบ
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
แฟล็กที่ใช้กันทั่วไป
| ธง | ค่าเริ่มต้น | คำอธิบาย |
|---|---|---|
--model PATH
|
— | เส้นทางไปยังโมเดล .tflite
(ต้องระบุ) |
--signature KEY |
ที่หนึ่ง | คีย์ลายเซ็นที่จะเรียกใช้ |
--use_cpu / --no_cpu
|
เปิด | สลับตัวเร่ง CPU / CPU สำรอง |
--use_gpu |
ปิด | เปิดใช้ตัวเร่ง GPU |
--use_npu |
ปิด | เปิดใช้ตัวเร่ง Intel NPU |
--require_full_delegation
|
ปิด | ล้มเหลวหากไม่ได้ ส่งต่อโมเดลไปยัง ตัวเร่งความเร็วที่เลือกอย่างเต็มรูปแบบ |
--num_runs N
|
50 | จำนวนการวนซ้ำของการอนุมานที่กำหนดเวลา |
--warmup_runs N
|
5 | การวนซ้ำการวอร์มอัพแบบไม่จำกัดเวลาก่อน การวัด |
--num_threads N |
1 | จำนวนเทรดของ CPU |
--result_json PATH
|
— | เขียนข้อมูลสรุป JSON (สถิติเวลาในการตอบสนอง ปริมาณงาน รายชื่อตัวเร่ง) |
--verbose |
ปิด | การบันทึกรันไทม์เพิ่มเติม |
Flag ขั้นสูง / การลบล้าง - จำเป็นต้องใช้เฉพาะเมื่อต้องการชี้ไปยังบิลด์ที่กำหนดเอง
--dispatch_library_path, --compiler_plugin_path, --runtime_path
ล้อที่มีผู้จำหน่ายหลายราย: ปักหมุด JIT ไปยัง Intel OV
หมายเหตุ: เมื่อเรียกใช้
Environment.create()โดยไม่มีเส้นทางที่ชัดเจน ระบบจะ ค้นหาผู้ให้บริการภายใต้ai_edge_litert/vendors/โดยอัตโนมัติตามลำดับตัวอักษร และลงทะเบียนผู้ให้บริการรายแรกที่พบ ในการติดตั้งแบบผสมผู้ให้บริการ ไดเรกทอรีนี้อาจไม่ใช่ Intel OV ให้ส่งไดเรกทอรี Intel OV อย่างชัดเจนเพื่อบังคับให้เลือกไดเรกทอรีที่ถูกต้อง
- วงล้อ pip จะจัดส่งปลั๊กอินคอมไพเลอร์สำหรับผู้ให้บริการที่ลงทะเบียนทุกราย
(
intel_openvino/,google_tensor/,mediatek/,qualcomm/,samsung/) - หากต้องการบังคับใช้เส้นทาง Intel OV (แนะนำเมื่อติดตั้ง SDK ของผู้ให้บริการหลายราย) ให้ส่งไดเรกทอรี Intel OV ด้วยตนเอง
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
รันไทม์จะโหลดไลบรารีที่ใช้ร่วมกันทั้งหมดที่พบในไดเรกทอรีที่ระบุ ดังนั้น
การชี้ไปที่ vendors/intel_openvino/compiler/ จะโหลดเฉพาะปลั๊กอิน Intel ส่วนปลั๊กอิน
Google Tensor / MediaTek / Qualcomm / Samsung ในไดเรกทอรีระดับเดียวกัน
จะไม่ได้รับการแตะต้อง
สำหรับ CLI แฟล็กที่เทียบเท่าคือ
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
ยืนยันการดำเนินการ NPU
หากต้องการยืนยันว่าโมเดลทำงานบน NPU จริง ให้ตรวจสอบสัญญาณทั้ง 2 อย่าง
- บันทึกมี
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}— โหลดไลบรารีการจัดส่งของ Intel แล้ว (.soใน Linux,.dllใน Windows) model.is_fully_accelerated()จะส่งคืนTrue— ระบบจะส่งต่อทุกการดำเนินการไปยัง Accelerator ที่เลือก
is_fully_accelerated() อย่างเดียวไม่เพียงพอ: หากโหลดไลบรารีการจัดส่งไม่ได้
ระบบจะส่งต่อการดำเนินการทั้งหมดไปยัง XNNPACK/CPU ไม่ใช่ NPU
การตั้งค่า NPU ใน Linux
หมายเหตุ: ข้ามส่วนนี้หากคุณต้องการใช้เฉพาะ AOT โดยไม่จำเป็นต้องมี NPU จริง
ข้อมูล: ใช้ไดรเวอร์ NPU v1.32.1 (จับคู่กับ OpenVINO 2026.1) ไดรเวอร์รุ่นเก่าจะล้มเหลวด้วย
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
จากนั้นเรียกใช้ข้อมูลโค้ดการติดตั้ง + ยืนยันจากคู่มือเริ่มต้นฉบับย่อ
การตั้งค่า NPU ของ Windows
หมายเหตุ: ข้ามส่วนนี้หากคุณต้องการใช้เฉพาะ AOT โดยไม่จำเป็นต้องมี NPU จริง
- ติดตั้งไดรเวอร์ NPU ของ Intel (32.0.100.4724+) จาก ศูนย์ดาวน์โหลดของ Intel
- ตรวจสอบว่าตัวจัดการอุปกรณ์แสดงรายการอุปกรณ์ NPU ในส่วนโปรเซสเซอร์แบบนิวรอล
(แสดงเป็น
Intel(R) AI BoostหรือIntel(R) NPUขึ้นอยู่กับไดรเวอร์) - เรียกใช้ข้อมูลโค้ดการติดตั้ง + ยืนยันจากคู่มือเริ่มต้นฉบับย่อ โดยแทนที่
pipด้วยpython -m pip
ข้อมูล:
import ai_edge_litertจะลงทะเบียนไดเรกทอรี DLL โดยอัตโนมัติโดยใช้os.add_dll_directory()ดังนั้นสคริปต์ Python จึงไม่จำเป็นต้องมีการตั้งค่าPATHสำหรับผู้ใช้ที่ไม่ใช่ Python ให้เรียกใช้setupvars.batหรือเติม<openvino>/libsนำหน้าPATH
สร้างจากแหล่งที่มา
ใช้พร็อกซีอยู่ใช่ไหม ส่งออก
http_proxy/https_proxy/no_proxyก่อน เรียกใช้สคริปต์บิลด์ ซึ่งจะส่งต่อตัวแปรเหล่านี้ไปยัง Docker และคอนเทนเนอร์
Linux (Docker, hermetic):
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
Windows (PowerShell, Bazel ใน PATH):
.\ci\build_pip_package_with_bazel_windows.ps1
เอาต์พุตจะอยู่ใน dist/
ai_edge_litert-*.whl- วงล้อรันไทม์ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz— vendor sdists- sdist ของ Intel มีขนาดประมาณ 5 KB ส่วนคอมไพเลอร์ NPU
.so/.dllจะดึงข้อมูลในpip installดังนั้น sdist เดียวกันจึงใช้ได้ทั้งใน Linux และ Windows
การทดสอบหน่วย
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
การแก้ปัญหา
| ปัญหา | แก้ไข |
|---|---|
AOT ไม่สำเร็จ: Device with "NPU" name is not registered |
ไม่ได้ดึงข้อมูลคอมไพเลอร์ NPU ดูai_edge_litert_sdk_intel.path_to_sdk_libs()รายการlibopenvino_intel_npu_compiler.so / .dll หากว่าง ให้ติดตั้งอีกครั้งโดยใช้สิทธิ์เข้าถึงเครือข่าย หรือตั้งค่า LITERT_OV_OS_ID=ubuntu22/ubuntu24 |
JIT ทำงานบน CPU แทน NPU (ไม่มีPartitioned subgraphบันทึก ไม่มีLoaded pluginบันทึก แต่Fully accelerated: Trueยังคงพิมพ์) |
ไม่พบปลั๊กอินคอมไพเลอร์ ยืนยันว่า ov.get_compiler_plugin_dir() จะแสดงเส้นทางภายใต้ ai_edge_litert/vendors/intel_openvino/compiler/ หากติดตั้ง SDK ของผู้ให้บริการหลายราย ให้ส่ง compiler_plugin_path=ov.get_compiler_plugin_dir() ไปยัง Environment.create() (หรือ --compiler_plugin_path=... ไปยัง litert-benchmark) อย่างชัดเจน |
JIT ล้มเหลว: Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so (Linux) / openvino_intel_npu_compiler.dll (Windows) |
SDK sdist จะคัดลอกคอมไพเลอร์ NPU ไปยัง openvino/libs/ ใน import ai_edge_litert_sdk_intel ครั้งแรก หากระบบข้ามการคัดลอก (FS แบบอ่านอย่างเดียว, ไม่มี openvino) ให้ติดตั้ง ai-edge-litert-sdk-intel อีกครั้งหลังจากติดตั้ง openvino แล้ว จากนั้นให้ติดตั้ง import ai_edge_litert ในกระบวนการใหม่ |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE |
อัปเกรดไดรเวอร์ NPU เป็น v1.32.1 (Linux) |
ไม่พบ /dev/accel/accel0 |
sudo dmesg | grep -i vpu เพื่อแก้ไขข้อบกพร่องของไดรเวอร์ รีบูตหลังการติดตั้ง |
| ไม่ได้รับอนุญาตใน NPU | sudo gpasswd -a ${USER} render && newgrp render |
| Windows: NPU ไม่อยู่ในตัวจัดการอุปกรณ์ | ติดตั้งไดรเวอร์ NPU 32.0.100.4724 ขึ้นไปจากศูนย์ดาวน์โหลดของ Intel |
Windows: Failed to initialize Dispatch API / DLL ที่ขาดหายไป |
ตรวจสอบว่า import ai_edge_litert ทำงานก่อน (ลงทะเบียนไดเรกทอรี DLL โดยอัตโนมัติ) สำหรับผู้เรียกที่ไม่ใช่ Python ให้เรียกใช้ setupvars.bat หรือเพิ่ม <openvino>/libs ไว้หน้า PATH |
บิลด์ของ Windows: LNK2001 fixed_address_empty_string, C2491 dllimport, Python 3.12+ fails |
ข้อจำกัด ABI ของ Protobuf / เวอร์ชัน Python — ดู ci/build_pip_package_with_bazel_windows.ps1; บิลด์ Windows ต้องใช้ Python 3.11 |
ข้อจำกัด
รองรับเฉพาะอุปกรณ์ NPU ผ่านเส้นทางการจัดส่ง OpenVINO สำหรับการอนุมาน CPU
ให้ใช้ HardwareAccelerator.CPU เพียงอย่างเดียว (XNNPACK)
C++ API
ข้อกำหนดเบื้องต้นและการตั้งค่าบิลด์
สร้างข้อกำหนดเบื้องต้น
- Visual Studio 2022 ขึ้นไป (ต้องติดตั้งเครื่องมือพัฒนา C++)
- git: ติดตั้ง git จาก https://git-scm.com/install/ ตรวจสอบว่า
C:\Program Files\Git\bin and C:\Program Files\Git\cmdรวมอยู่ในตัวแปรสภาพแวดล้อม PATH ของระบบ เพื่อให้กระบวนการบิลด์ LiteRT/LiteRT-LM ค้นหา bash.exe และ git.exe ได้ - Bazelisk: ติดตั้ง Bazelisk และระบุตำแหน่งในตัวแปรสภาพแวดล้อม
PATHของระบบ: https://bazel.build/install/bazelisk - Cmake: ติดตั้ง Cmake เวอร์ชัน 4.3.0 ขึ้นไปจาก https://cmake.org/download/ โดยตรวจสอบว่า Cmake รวมอยู่ใน PATH ของระบบ
- Python: ตรวจสอบว่าได้ติดตั้ง Python 3.11 ขึ้นไปแล้ว และ python.exe อยู่ใน PATH
- การตั้งค่า Windows: เปิดใช้โหมดนักพัฒนาแอปในการตั้งค่า Windows
สร้างเครื่องมือและปลั๊กอิน LiteRT สำหรับ NPU ของ Intel
หากต้องการเรียกใช้โมเดลใน NPU ของ Intel ด้วย LiteRT คุณต้องคอมไพล์โมเดลโดยใช้ปลั๊กอินคอมไพเลอร์ LiteRT Intel OpenVINO นอกจากนี้ โมเดลที่คอมไพล์แล้วซึ่งมีไว้สำหรับการดำเนินการใน NPU ของ Intel ต้องได้รับมอบหมายให้ปลั๊กอินการจัดส่ง LiteRT Intel OpenVINO
กลไกที่ LiteRT เรียกใช้ปลั๊กอินเหล่านี้จะแสดงในส่วนถัดไป
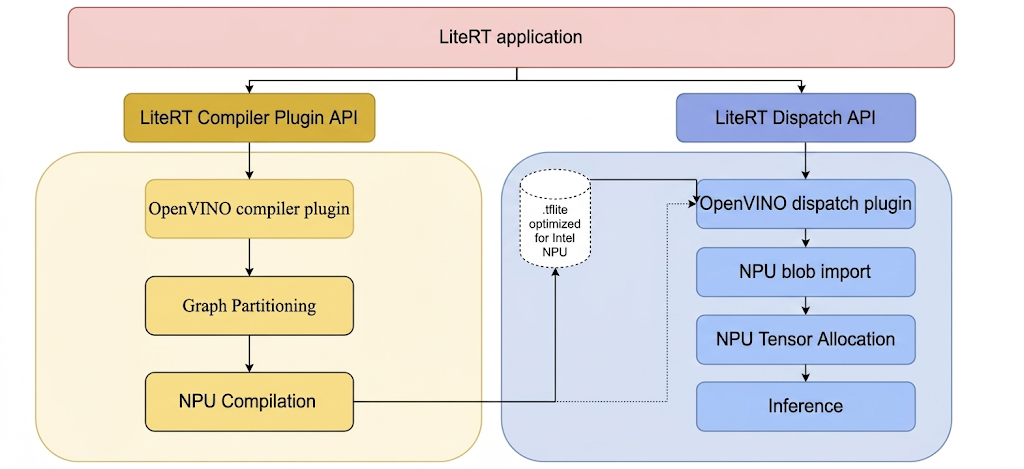
ขั้นตอนในการสร้างเครื่องมือ LiteRT และปลั๊กอิน Intel
ก่อนที่จะสร้างไฟล์ปฏิบัติการหรือไลบรารีจาก LiteRT ให้สร้างไดเรกทอรีในเครื่อง เช่น C:\bzl ระบบจะรวบรวมไบนารีเอาต์พุตของบิลด์จากไดเรกทอรีนี้ สร้างปลั๊กอินการจัดส่ง Intel OpenVINO
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
หรือคุณจะสร้างปลั๊กอินการจัดส่งจากที่เก็บ LiteRT-LM
โดยเพิ่มคำนำหน้า @litert ในเป้าหมายก็ได้ ซึ่งคล้ายกันสำหรับเป้าหมายทั้งหมด
ต่อไปนี้จากที่เก็บ LiteRT
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
สร้างปลั๊กอินคอมไพเลอร์ Intel OpenVINO
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
สร้างยูทิลิตีคอมไพเลอร์ Ahead-of-Time (AOT) ของ LiteRT เครื่องมือ LiteRT บางอย่างต้องมีการคอมไพล์ AOT ที่ชัดเจนของโมเดลก่อนที่จะเรียกใช้ ใน NPU ของ Intel วิธีการสร้างยูทิลิตีคอมไพเลอร์ AOT ของ LiteRT
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
สร้างโปรแกรมเรียกใช้โมเดล LiteRT คุณสามารถใช้โปรแกรมเรียกใช้โมเดล LiteRT เพื่อเรียกใช้โมเดลใน NPU ของ Intel ได้ ไม่ว่าจะเป็น โมเดลที่ไม่ได้คอมไพล์ล่วงหน้าหรือโมเดลที่คอมไพล์ AOT วิธีการสร้างโปรแกรมเรียกใช้โมเดล
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
สร้างยูทิลิตีโมเดลการเปรียบเทียบ LiteRT เครื่องมือเปรียบเทียบโมเดล LiteRT สามารถใช้เพื่อเปรียบเทียบประสิทธิภาพของ การอนุมานโมเดลใน NPU ของ Intel หากมีวิธีการสร้างเครื่องมือเปรียบเทียบ
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
สร้างยูทิลิตีตรวจสอบตัวเลข LiteRT
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
การใช้งานขั้นสูง: สร้างด้วย Intel OpenVINO SDK ที่ปรับแต่ง
ระบบบิลด์ LiteRT จะดึงข้อมูล SDK ของ Intel OpenVINO ที่สร้างไว้ล่วงหน้าโดยอัตโนมัติ เมื่อคอมไพล์คอมไพเลอร์และปลั๊กอินการเรียกใช้
หากโปรเจ็กต์ของคุณต้องใช้ Intel OpenVINO SDK เวอร์ชันที่เฉพาะเจาะจงหรือปรับแต่งแล้ว ให้ทำตามขั้นตอนการกำหนดค่าเพิ่มเติมเหล่านี้ก่อนเริ่มสร้างปลั๊กอิน
- ดาวน์โหลดไบนารีของ OpenVINO เวอร์ชันล่าสุดสำหรับ Windows จาก
https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html
และแตกไฟล์ไปยังดิสก์ในเครื่อง เช่น
C:\Intel\intel_openvino - ตรวจสอบว่าไดเรกทอรีย่อยเดียวภายใต้เส้นทางนี้มีชื่อว่า "openvino" ซึ่งมีไดเรกทอรีย่อย เช่น "runtime" และ "include"
- ไปที่ไดเรกทอรีรากของที่เก็บ LiteRT ที่โคลนไว้ในคอนโซล
(Command Prompt หรือ PowerShell) แล้วตั้งค่าตัวแปร OPENVINO_NATIVE_DIR
(ตรวจสอบว่าไม่มี
\`), for example:set OPENVINO_NATIVE_DIR=C:\Intel\intel_openvino`
การคอมไพล์ AOT ของโมเดลที่กำหนดเอง
ส่วนนี้จะเตรียมสภาพแวดล้อมและทำการคอมไพล์ AOT ของโมเดล TFLite, PyTorch หรือ JAX ที่กำหนดเองสำหรับ LiteRT
ในระหว่างกระบวนการคอมไพล์โมเดลสำหรับ NPU ของ Intel นั้น LiteRT จะตรวจสอบกราฟโมเดลกับโอเปอเรเตอร์ที่ปลั๊กอินคอมไพเลอร์ LiteRT Intel OpenVINO รองรับ สำหรับโอเปอเรเตอร์หรือกราฟย่อยที่เข้ากันได้กับ ปลั๊กอินคอมไพเลอร์ LiteRT จะคอมไพล์กราฟย่อยดังกล่าวแต่ละรายการเป็น DISPATCH_OP ซึ่ง จะแทนที่กราฟย่อยเดิมภายในกราฟในภายหลัง โอเปอเรเตอร์ที่ไม่ได้ รวมอยู่ใน Opset ที่รองรับโดยคอมไพเลอร์ Intel OpenVINO จะไม่มีการเปลี่ยนแปลง ภายในกราฟ ด้วยเหตุนี้ การคอมไพล์ AOT จึงอาจทำให้ได้โมเดลที่มอบสิทธิ์ทั้งหมดหรือมอบสิทธิ์บางส่วน ตัวอย่างของโมเดลที่คอมไพล์ AOT แบบมอบสิทธิ์ทั้งหมดมีดังนี้
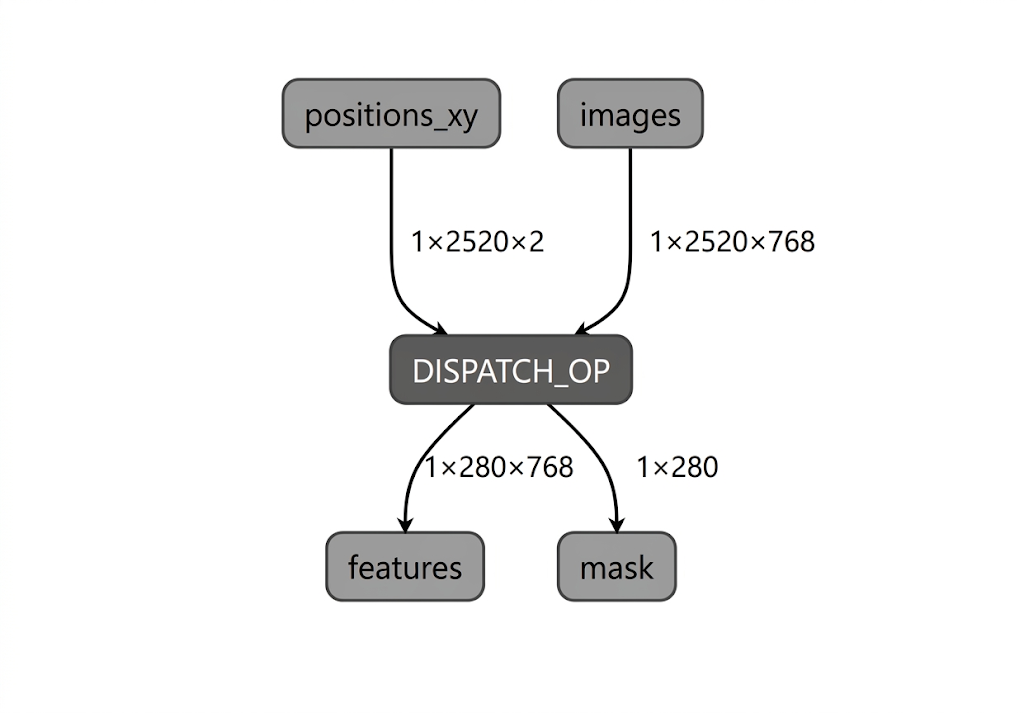
ยูทิลิตี LiteRT apply_plugin_main (apply_plugin_main.exe) เป็นยูทิลิตีการคอมไพล์ AOT ที่คุณใช้เพื่อวัตถุประสงค์นี้ได้ ตัวอย่างการใช้งานยูทิลิตีในแพลตฟอร์ม Intel
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
โปรดทราบว่าคอมไพเลอร์ NPU พื้นฐานเริ่มต้นซึ่งรวมอยู่ใน การเผยแพร่ไบนารีของ Intel OpenVINO SDK จะใช้สำหรับ Intel Core Ultra Series 2 และ SoC ที่ตามมา หากมีการคอมไพล์โมเดลสำหรับ NPU ที่ไม่ได้อยู่ในรายการที่รองรับ คุณต้องระบุประเภทคอมไพเลอร์อย่างชัดเจน (แม้ว่าตัวเลือกนี้จะยังคงไม่บังคับสำหรับ Intel Core Ultra 2 ขึ้นไป)
set IE_NPU_COMPILER_TYPE=PLUGIN
การคอมไพล์ JIT กับ AOT ในแอปพลิเคชัน
หากต้องการคอมไพล์โมเดลในแอปพลิเคชัน LiteRT ของคุณเอง มี 2 วิธี ได้แก่ การคอมไพล์ AOT ที่เราได้แนะนำไปแล้ว และการคอมไพล์ Just-in-time (JIT)
การคอมไพล์ AOT จะคอมไพล์โหมดแบบออฟไลน์ก่อนการทำให้ใช้งานได้และบันทึกไว้ใช้ในภายหลังได้ ซึ่งใช้กันโดยทั่วไปเมื่อการคอมไพล์ใช้ทรัพยากรมากเกินไปที่จะเรียกใช้ในอุปกรณ์ โดยไม่จำเป็นต้องดำเนินการในอุปกรณ์เดียวกับที่คุณกำลังติดตั้งใช้งานโมเดล ตัวอย่างการคอมไพล์ AOT ในโค้ด
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
วิธีอนุมานด้วยโมเดลที่คอมไพล์ AOT
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
อีกวิธีหนึ่งคือการคอมไพล์โมเดล JIT ที่รันไทม์ในอุปกรณ์ มีความยืดหยุ่นมากกว่า เนื่องจากต้องใช้ไฟล์โมเดลเดียวที่ไม่ขึ้นอยู่กับแบ็กเอนด์
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
เปรียบเทียบกับ benchmark_model
ยูทิลิตี benchmark_model ของ LiteRT (benchmark_model.exe) ออกแบบมาโดยเฉพาะ สำหรับการเปรียบเทียบประสิทธิภาพของโมเดลที่คอมไพล์ AOT ใน NPU และใช้เพื่อเปรียบเทียบ ประสิทธิภาพกับแบ็กเอนด์ CPU (XNNPack) ใน LiteRT ได้ ตัวอย่างคำสั่งสำหรับการเปรียบเทียบโมเดลที่คอมไพล์ AOT ใน Intel NPU
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
การตรวจสอบความถูกต้องด้วย npu_numerics_check
ยูทิลิตี npu_numerics_check ใช้เพื่อตรวจสอบความแม่นยำของตัวเลขของโมเดลที่คอมไพล์ NPU กับพื้นฐาน (โดยทั่วไปคือแบ็กเอนด์ CPU, XNNPack) ขั้นตอนนี้มีความสําคัญอย่างยิ่งในการตรวจสอบว่าการมอบสิทธิ์ไปยัง NPU ไม่ได้ ทําให้เกิดค่าเบี่ยงเบนเชิงตัวเลขที่ยอมรับไม่ได้ซึ่งอาจส่งผลต่อคุณภาพของโมเดล
เรียกใช้การตรวจสอบตัวเลข ยูทิลิตีต้องใช้โมเดลที่คอมไพล์ AOT และเปรียบเทียบเอาต์พุตกับโมเดลเดิมที่ไม่ได้มอบสิทธิ์ซึ่งทำงานบน CPU
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
ขั้นตอนถัดไป
- เริ่มต้นด้วยคู่มือ NPU แบบรวม: การเร่งความเร็ว NPU ด้วย LiteRT
- ทำตามขั้นตอนการแปลงและการติดตั้งใช้งานที่นั่น โดยเลือก Qualcomm เมื่อ เกี่ยวข้อง
- สำหรับ LLM โปรดดูเรียกใช้ LLM บน NPU โดยใช้ LiteRT-LM