
LiteRT est compatible avec Intel OpenVino via l'API CompiledModel pour la compilation AOT et sur l'appareil.
API Python
Configurer l'environnement de développement
Linux (x86_64) :
- Ubuntu 22.04 ou 24.04 LTS
- Python 3.10 ou version ultérieure : installez-le depuis python.org
ou votre distribution (
sudo apt install python3 python3-venv). - Pilote Intel NPU v1.32.1 : consultez la section Configuration du NPU Linux.
Windows (x86_64) :
- Windows 10 ou 11
- Python 3.10 ou version ultérieure : installez-le depuis python.org.
- Pilote Intel NPU 32.0.100.4724+ : consultez Configuration du NPU Windows.
Pour la compilation à partir de la source, Bazel 7.4.1+ utilisant Bazelisk ou la compilation Docker hermétique est également requis.
SoC compatibles
| Plate-forme | NPU | Nom de code | OS |
|---|---|---|---|
| Intel Core Ultra série 2 | NPU4000 | Lunar Lake (LNL) | Linux, Windows |
| Intel Core Ultra Series 3 | NPU5010 | Panther Lake (PTL) | Linux, Windows |
Démarrage rapide
1. Installer les pilotes NPU
Consultez Configuration de l'unité de traitement neuronal (NPU) sous Linux ou Configuration de l'unité de traitement neuronal (NPU) sous Windows. Ignorez cette étape si vous n'avez besoin que de l'AOT.
Le pilote NPU n'est nécessaire que sur les systèmes qui exécutent le modèle sur le matériel NPU. Les systèmes de compilation AOT pure peuvent l'ignorer.
Remarque :
ai-edge-litert-sdk-intel-nightlyépingle la roue nightly OpenVINO correspondante par version PEP 440 (par exemple,openvino==2026.2.0.dev20260506). pip a donc besoin de--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightlypour la localiser. Sur Linux, si la détection automatique de la distribution choisit la mauvaise archive, définissezLITERT_OV_OS_ID=ubuntu22ouubuntu24avantpip install.
2. Créer un environnement virtuel Python
Il est recommandé de conserver la roue openvino nightly isolée de toute installation OpenVINO à l'échelle du système.
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
3. Installer le package pip
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
Le --extra-index-url permet à pip de résoudre la roue openvino quotidienne épinglée à partir de l'index OpenVINO en même temps que les packages sur PyPI.
4. Vérifier l'installation
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
Points à vérifier dans le résultat :
SDK libslistelibopenvino_intel_npu_compiler.so(Linux) ouopenvino_intel_npu_compiler.dll(Windows), obligatoire pour AOT.Available devicesinclutNPU: cela confirme que le pilote NPU est installé et qu'OpenVINO peut communiquer avec l'appareil.NPUsera absent des systèmes AOT uniquement (où le pilote n'est pas installé) et des systèmes sans matériel Intel NPU.
5. Compilation AOT (facultatif)
- Précompile un
.tflitepour une cible NPU Intel spécifique (PTL ou LNL) afin que l'environnement d'exécution ignore l'étape du plug-in du compilateur. - N'a pas besoin d'un NPU physique ni du pilote NPU. Seuls
ai-edge-litert-nightlyetai-edge-litert-sdk-intel-nightlysont nécessaires. - La compilation croisée est acceptée : compilez sur n'importe quel hôte Linux ou Windows, envoyez le
.tfliteobtenu à une cible de l'un ou l'autre des OS et exécutez-le.
Les fichiers de sortie sont nommés <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite.
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
6. Exécuter l'inférence NPU
LiteRT est compatible avec deux chemins d'inférence sur l'unité de traitement neuronal Intel :
- JIT : charge un
.tflitebrut. Le plug-in du compilateur partitionne et compile les opérations compatibles pour la NPU au moment de l'exécutionCompiledModel.from_file(). Ajoute une latence de première exécution (variable selon le modèle). - Compilation AOT : chargez un
<model>_IntelOpenVINO_<SoC>_apply_plugin.tfliteproduit à l'étape 4. Ignore l'étape de partitionnement et de compilation au moment du chargement.
Cet extrait fonctionne pour les deux :
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
Vérifier que la compilation JIT a bien été exécutée
Lorsque la compilation JIT réussit, le journal contient les informations suivantes (l'extension de fichier est .so sur Linux et .dll sur Windows) :
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
Si ces lignes sont absentes, mais que Fully accelerated: True est toujours signalé, cela signifie que le modèle a été exécuté sur le processeur de secours XNNPACK et non sur l'unité de traitement neuronal. Consultez la ligne de dépannage JIT.
7. Benchmark
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
Options courantes :
| Option | Valeur par défaut | Description |
|---|---|---|
--model PATH
|
— | Chemin d'accès au modèle .tflite (obligatoire). |
--signature KEY |
première | Clé de signature à exécuter. |
--use_cpu/--no_cpu
|
le | Activez/Désactivez l'accélérateur de processeur/le processeur de secours. |
--use_gpu |
désactivé | Activez l'accélérateur GPU. |
--use_npu |
désactivé | Activez l'accélérateur Intel NPU. |
--require_full_delegation
|
désactivé | Échec si le modèle n'est pas entièrement déchargé sur l'accélérateur sélectionné. |
--num_runs N
|
50 | Nombre d'itérations d'inférence chronométrées. |
--warmup_runs N
|
5 | Itérations d'échauffement non chronométrées avant la mesure. |
--num_threads N |
1 | Nombre de threads du CPU. |
--result_json PATH
|
— | Rédige un résumé JSON (statistiques de latence, débit, liste des accélérateurs). |
--verbose |
désactivé | Journalisation d'exécution supplémentaire. |
Options avancées / de remplacement : ne sont nécessaires que pour pointer vers des versions personnalisées : --dispatch_library_path, --compiler_plugin_path, --runtime_path.
Roues de différents fournisseurs : épingler JIT à Intel OV
Remarque : Lorsque
Environment.create()est appelé sans chemins d'accès explicites, il détecte automatiquement les fournisseurs sousai_edge_litert/vendors/par ordre alphabétique et enregistre le premier qu'il trouve. Dans une installation multi-fournisseurs, il se peut que ce ne soit pas Intel OV. Transmettez explicitement les répertoires Intel OV pour forcer la bonne sélection.
- La roue pip fournit des plug-ins de compilateur pour chaque fournisseur enregistré (
intel_openvino/,google_tensor/,mediatek/,qualcomm/,samsung/). - Pour forcer le chemin d'accès Intel OV (recommandé lorsque plusieurs SDK de fournisseurs sont installés), transmettez manuellement les répertoires Intel OV :
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
L'environnement d'exécution charge toutes les bibliothèques partagées qu'il trouve dans le répertoire donné. Par conséquent, en pointant sur vendors/intel_openvino/compiler/, seul le plug-in Intel est chargé. Les plug-ins Google Tensor / MediaTek / Qualcomm / Samsung dans les répertoires frères ne sont jamais utilisés.
Pour la CLI, les indicateurs équivalents sont les suivants :
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
Vérifier l'exécution de l'unité de traitement neuronal
Pour vérifier que le modèle s'est bien exécuté sur l'unité de traitement neuronal, recherchez les deux signaux suivants :
- Le journal contient
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}: la bibliothèque de répartition Intel a été chargée (.sosur Linux,.dllsur Windows). model.is_fully_accelerated()renvoieTrue: chaque opération a été déchargée sur l'accélérateur sélectionné.
is_fully_accelerated() seul ne suffit pas : si la bibliothèque de répartition n'a jamais été chargée, les opérations ont été entièrement déchargées sur XNNPACK/CPU, et non sur l'unité de traitement neuronal.
Configuration du NPU Linux
Remarque : Ignorez cette section si vous n'avez besoin que d'AOT. Un NPU physique n'est pas nécessaire.
Info : Utiliser le pilote NPU v1.32.1 (associé à OpenVINO 2026.1). Les pilotes plus anciens échouent avec
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE.
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
Exécutez ensuite l'extrait d'installation et de vérification à partir du guide de démarrage rapide.
Configuration du NPU Windows
Remarque : Ignorez cette section si vous n'avez besoin que d'AOT. Un NPU physique n'est pas nécessaire.
- Installez le pilote Intel NPU (32.0.100.4724+) depuis le Centre de téléchargement Intel.
- Vérifiez que le Gestionnaire de périphériques liste l'appareil NPU sous Processeurs neuronaux (affiché sous la forme
Intel(R) AI BoostouIntel(R) NPUselon le pilote). - Exécutez l'extrait d'installation et de validation du démarrage rapide en remplaçant
pipparpython -m pip.
Info :
import ai_edge_litertenregistre automatiquement les répertoires DLL à l'aide deos.add_dll_directory(). Les scripts Python n'ont donc pas besoin de configurationPATH. Pour les consommateurs non Python, exécutezsetupvars.batou ajoutez<openvino>/libsàPATH.
Créer à partir de la source
Derrière un proxy ? Exportez
http_proxy/https_proxy/no_proxyavant d'exécuter les scripts de compilation. Ils les transmettent à Docker et au conteneur.
Linux (Docker, hermétique) :
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
Windows (PowerShell, Bazel dans PATH) :
.\ci\build_pip_package_with_bazel_windows.ps1
Les résultats s'affichent dans dist/ :
ai_edge_litert-*.whl: roue de l'environnement d'exécution.ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz: distributions de sources du fournisseur.- La sdist Intel est d'environ 5 Ko. Le compilateur NPU
.so/.dllest récupéré au moment depip install. La même sdist fonctionne donc sur Linux et Windows.
Tests unitaires
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
Dépannage
| Problème | Corriger |
|---|---|
Échecs AOT : Device with "NPU" name is not registered |
Le compilateur NPU n'a pas été récupéré. Consultez les listes ai_edge_litert_sdk_intel.path_to_sdk_libs() libopenvino_intel_npu_compiler.so / .dll. Si elle est vide, réinstallez-la avec un accès au réseau ou définissez LITERT_OV_OS_ID=ubuntu22/ubuntu24. |
JIT s'exécute sur le processeur au lieu de la NPU (aucun journal Partitioned subgraph, aucun journal Loaded plugin, Fully accelerated: True toujours affiché) |
Le plug-in du compilateur n'a pas été détecté. Confirm ov.get_compiler_plugin_dir() renvoie un chemin d'accès sous ai_edge_litert/vendors/intel_openvino/compiler/. Si plusieurs SDK de fournisseurs sont installés, transmettez explicitement compiler_plugin_path=ov.get_compiler_plugin_dir() à Environment.create() (ou --compiler_plugin_path=... à litert-benchmark). |
Échec du JIT : Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so (Linux) / openvino_intel_npu_compiler.dll (Windows) |
Le sdist du SDK copie le compilateur NPU vers openvino/libs/ lors du premier import ai_edge_litert_sdk_intel. Si la copie a été ignorée (système de fichiers en lecture seule, openvino manquant), réinstallez ai-edge-litert-sdk-intel après l'installation de openvino, puis import ai_edge_litert dans un nouveau processus. |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE |
Mise à niveau du pilote NPU vers la version 1.32.1 (Linux). |
/dev/accel/accel0 introuvable |
sudo dmesg | grep -i vpu pour déboguer le pilote ; redémarrez après l'installation. |
| Autorisation refusée sur l'unité de traitement neuronal | sudo gpasswd -a ${USER} render && newgrp render. |
| Windows : NPU non répertée dans le Gestionnaire de périphériques | Installez le pilote NPU 32.0.100.4724 ou version ultérieure depuis le Centre de téléchargement Intel. |
Windows : Failed to initialize Dispatch API / DLL manquantes |
Assurez-vous que import ai_edge_litert s'exécute en premier (enregistre automatiquement les répertoires DLL). Pour les appelants non Python, exécutez setupvars.bat ou ajoutez <openvino>/libs à PATH. |
Version de Windows : LNK2001 fixed_address_empty_string, C2491 dllimport, Python 3.12+ fails |
Contrainte de version Protobuf ABI / Python : consultez ci/build_pip_package_with_bazel_windows.ps1. Les builds Windows nécessitent Python 3.11. |
Limites
Seul l'appareil NPU est compatible avec le chemin de répartition OpenVINO. Pour l'inférence du CPU, utilisez uniquement HardwareAccelerator.CPU (XNNPACK).
API C++
Prérequis et configuration de compilation
Prérequis pour la compilation :
- Visual Studio 2022 ou version ultérieure (les outils de développement C++ doivent être installés).
- git : installez git depuis https://git-scm.com/install/. Assurez-vous que
C:\Program Files\Git\bin and C:\Program Files\Git\cmdest inclus dans la variable d'environnement PATH de votre système pour permettre aux processus de compilation LiteRT/LiteRT-LM de localiser bash.exe et git.exe. - Bazelisk : installez Bazelisk et incluez son emplacement dans la variable d'environnement
PATHde votre système : https://bazel.build/install/bazelisk. - Cmake : installez Cmake version 4.3.0 ou ultérieure depuis https://cmake.org/download/, en vérifiant que Cmake est inclus dans le PATH de votre système.
- Python : assurez-vous que Python 3.11 ou version ultérieure est installé et que python.exe se trouve dans votre PATH.
- Paramètres Windows : activez le mode développeur dans les paramètres Windows.
Créer des outils et des plug-ins LiteRT pour l'unité de traitement neuronal Intel
Pour exécuter des modèles sur l'unité de traitement neuronal Intel avec LiteRT, ils doivent être compilés à l'aide du plug-in de compilation LiteRT Intel OpenVINO. De plus, tout modèle compilé destiné à être exécuté sur l'unité de traitement neuronal Intel doit être délégué au plug-in de répartition LiteRT Intel OpenVINO.
Le mécanisme par lequel LiteRT appelle ces plug-ins est illustré ci-après :
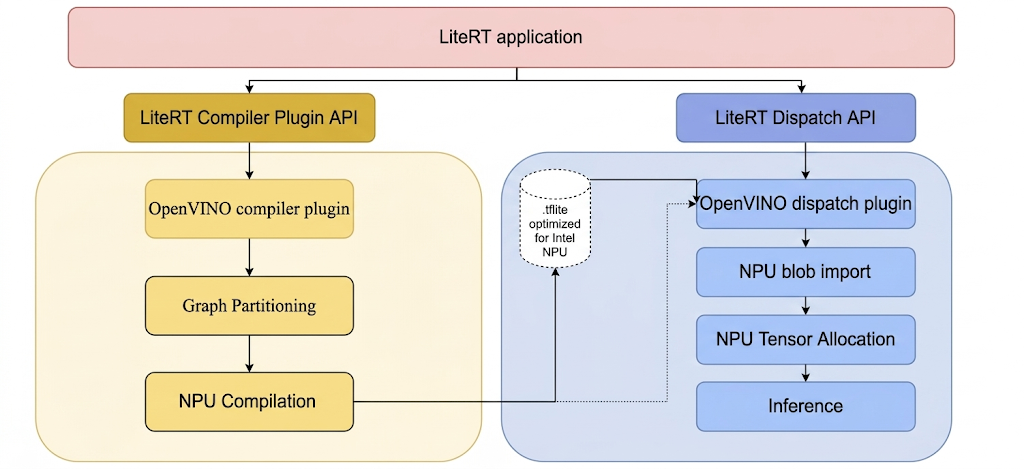
Étapes à suivre pour compiler les outils LiteRT et les plug-ins Intel.
Avant de compiler un exécutable ou une bibliothèque à partir de LiteRT, créez un répertoire local, par exemple C:\bzl. Le binaire de sortie de compilation sera collecté à partir de ce répertoire. Créer le plug-in de répartition Intel OpenVINO
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Vous pouvez également créer le plug-in Dispatch à partir du dépôt LiteRT-LM en ajoutant un préfixe @litert à la cible. Cela s'applique de la même manière à toutes les cibles suivantes du dépôt LiteRT.
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Créer le plug-in de compilation Intel OpenVINO
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
Créez l'utilitaire de compilation Ahead-of-Time (AOT) LiteRT. Certains outils LiteRT nécessitent une compilation AOT explicite des modèles avant de les exécuter sur l'unité de traitement neuronal Intel. Instructions de compilation de l'utilitaire de compilation AOT LiteRT :
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
Créer un exécuteur de modèle LiteRT L'exécuteur de modèle LiteRT peut être utilisé pour exécuter un modèle sur l'unité de traitement neuronal Intel, qu'il s'agisse d'un modèle non précompilé ou d'un modèle compilé AOT. Instruction pour créer le runner de modèle :
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
Créer un utilitaire de modèle de benchmark LiteRT L'outil de benchmark de modèle LiteRT peut être utilisé pour évaluer les performances d'inférence d'un modèle sur l'unité de traitement neuronal Intel. Si vous avez des instructions pour créer l'outil de benchmark :
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
Compiler l'utilitaire de vérification des valeurs numériques LiteRT
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
Utilisation avancée : créer avec le SDK Intel OpenVINO personnalisé
Le système de compilation LiteRT récupère automatiquement le SDK Intel OpenVINO précompilé lors de la compilation du compilateur et des plug-ins de répartition.
Si votre projet nécessite une version spécifique ou personnalisée du SDK Intel OpenVINO, effectuez les étapes de configuration supplémentaires suivantes avant de commencer la compilation du plug-in :
- Téléchargez le dernier binaire de version OpenVINO pour Windows depuis https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html, puis extrayez-le sur le disque local, par exemple
C:\Intel\intel_openvino. - Assurez-vous que le seul répertoire enfant sous ce chemin d'accès est nommé "openvino" et contient des sous-répertoires tels que "runtime" et "include".
- Accédez au répertoire racine du dépôt LiteRT cloné dans votre console (invite de commandes ou PowerShell), puis définissez la variable OPENVINO_NATIVE_DIR (assurez-vous qu'il n'y a pas de
\`), for example:à la fin de la commande set OPENVINO_NATIVE_DIR=C:\Intel\intel_openvino).
Compilation AOT des modèles personnalisés
Cette section prépare l'environnement et effectue la compilation AOT des modèles TFLite, PyTorch ou JAX personnalisés pour LiteRT.
Lors du processus de compilation du modèle pour l'unité de traitement neuronal Intel, LiteRT valide le graphique du modèle par rapport aux opérateurs compatibles avec le plug-in de compilation LiteRT Intel OpenVINO. Pour les opérateurs ou les sous-graphes compatibles avec le plug-in du compilateur, LiteRT compile chacun de ces sous-graphes en DISPATCH_OP, qui remplace ensuite le sous-graphe d'origine dans le graphe. Les opérateurs non inclus dans l'opset compatible par le compilateur Intel OpenVINO restent inchangés dans le graphique. Par conséquent, la compilation AOT peut générer un modèle entièrement délégué ou partiellement délégué. Voici un exemple de modèle entièrement délégué et compilé AOT :
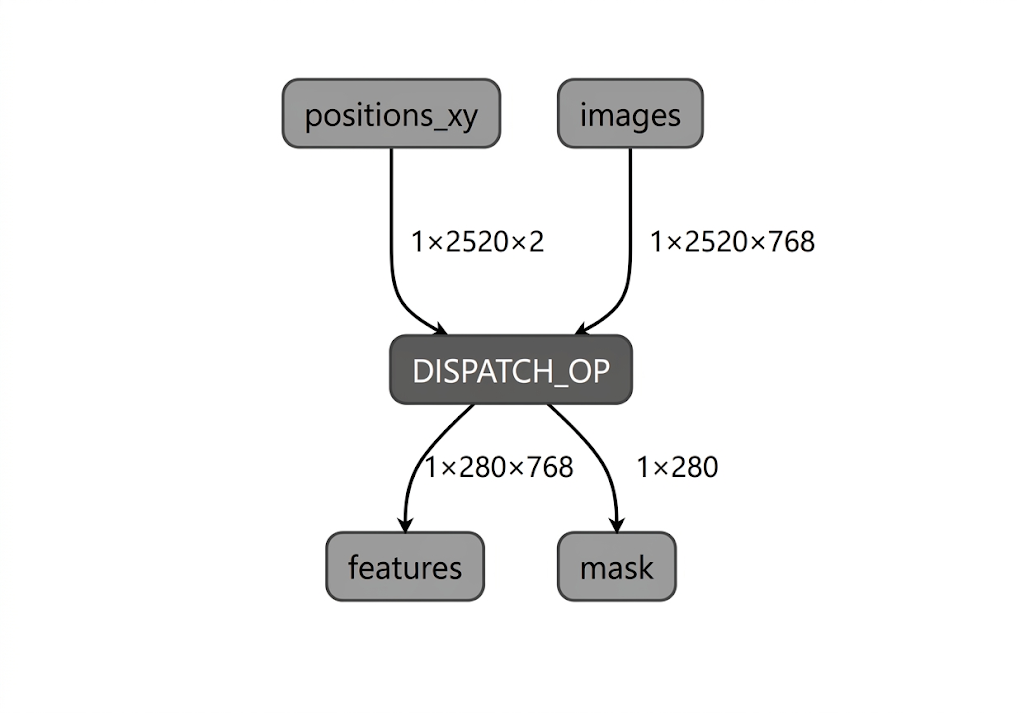
L'utilitaire LiteRT apply_plugin_main (apply_plugin_main.exe) est l'utilitaire de compilation AOT que vous pouvez utiliser à cette fin. Exemple d'utilisation de l'utilitaire sur la plate-forme Intel :
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
Veuillez noter que le compilateur NPU sous-jacent par défaut, inclus dans la distribution binaire du SDK Intel OpenVINO, est utilisé pour les SoC Intel Core Ultra Series 2 et ultérieurs. Si un modèle est compilé pour une NPU qui ne figure pas dans la liste des NPU compatibles, le type de compilateur doit être spécifié explicitement (bien que cela reste facultatif pour Intel Core Ultra 2 et les versions ultérieures).
set IE_NPU_COMPILER_TYPE=PLUGIN
Compilation JIT et AOT dans votre application
Pour compiler des modèles dans votre propre application LiteRT, vous avez le choix entre deux approches : la compilation AOT que nous avons déjà présentée et la compilation JIT (Just-in-time).
Avec la compilation AOT, le modèle est compilé hors connexion avant le déploiement et peut être enregistré pour une utilisation ultérieure. Cette méthode est couramment utilisée lorsque la compilation est trop gourmande en ressources pour être exécutée sur l'appareil. Vous n'avez pas besoin d'effectuer cette opération sur l'appareil sur lequel vous déployez le modèle. Voici un exemple de compilation AOT dans votre code :
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
Voici comment effectuer une inférence avec un modèle compilé AOT :
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
L'autre approche consiste à compiler le modèle JIT au moment de l'exécution sur l'appareil. Il est plus flexible, car il ne nécessite qu'un seul fichier de modèle indépendant du backend.
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
Effectuer un benchmark avec benchmark_model
L'utilitaire benchmark_model de LiteRT (benchmark_model.exe) est spécifiquement conçu pour évaluer un modèle compilé AOT sur NPU. Il peut être utilisé pour comparer les performances par rapport au backend CPU (XNNPack) dans LiteRT. Exemple de commande pour évaluer un modèle compilé AOT sur l'unité de traitement neuronal Intel :
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
Vérification de la précision avec npu_numerics_check
L'utilitaire npu_numerics_check permet de vérifier la précision numérique d'un modèle compilé par NPU par rapport à une référence (généralement le backend CPU, XNNPack). Cette étape est essentielle pour s'assurer que la délégation au NPU n'introduit pas de déviations numériques inacceptables qui pourraient avoir un impact sur la qualité du modèle.
Exécuter la vérification des valeurs numériques L'utilitaire nécessite le modèle compilé AOT et compare ses sorties à celles du modèle d'origine non délégué exécuté sur le processeur.
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
Étapes suivantes
- Commencez par le guide unifié sur les NPU : Accélération des NPU avec LiteRT
- Suivez les étapes de conversion et de déploiement, en choisissant Qualcomm le cas échéant.
- Pour les LLM, consultez Exécuter des LLM sur NPU à l'aide de LiteRT-LM.