
LiteRT, Intel OpenVino के साथ काम करता है. इसके लिए, यह CompiledModel API का इस्तेमाल करता है. यह AOT और डिवाइस पर कंपाइल करने, दोनों के लिए काम करता है.
Python API
डेवलपमेंट एनवायरमेंट सेट अप करना
Linux (x86_64):
- Ubuntu 22.04 या 24.04 एलटीएस
- Python 3.10 या इसके बाद का वर्शन — इसे python.org से इंस्टॉल करें
या अपने डिस्ट्रो (
sudo apt install python3 python3-venv) से इंस्टॉल करें - Intel NPU ड्राइवर v1.32.1 — Linux NPU सेटअप देखें
Windows (x86_64):
- Windows 10 या 11
- Python 3.10 या इसके बाद का वर्शन — इसे python.org से इंस्टॉल करें
- Intel NPU ड्राइवर 32.0.100.4724+ — Windows NPU सेटअप देखें
सोर्स से बनाने के लिए, Bazelisk का इस्तेमाल करने वाले Bazel 7.4.1+ या हर्मेटिक Docker बिल्ड की भी ज़रूरत होती है.
साथ काम करने वाले SoCs
| प्लैटफ़ॉर्म | एनपीयू | कोडनाम | ओएस |
|---|---|---|---|
| Intel Core Ultra सीरीज़ 2 | NPU4000 | लूनर लेक (LNL) | Linux, Windows |
| Intel Core Ultra Series 3 | NPU5010 | पैंथर लेक (पीटीएल) | Linux, Windows |
क्विक स्टार्ट
1. एनपीयू ड्राइवर इंस्टॉल करना
Linux NPU सेटअप या Windows NPU सेटअप देखें. अगर आपको सिर्फ़ एओटी की ज़रूरत है, तो इस चरण को छोड़ दें.
एनपीयू ड्राइवर की ज़रूरत सिर्फ़ उन सिस्टम पर होती है जो एनपीयू हार्डवेयर पर मॉडल को लागू करते हैं. पूरी तरह से एओटी-बिल्ड वाले सिस्टम इसे स्किप कर सकते हैं.
ध्यान दें:
ai-edge-litert-sdk-intel-nightlyPEP 440 वर्शन (जैसे किopenvino==2026.2.0.dev20260506) के हिसाब से, OpenVINO के मैचिंग नाइटली व्हील को पिन करता है. इसलिए, pip को इसे ढूंढने के लिए--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightlyकी ज़रूरत होती है. Linux पर, अगर डिस्ट्रो अपने-आप गलत संग्रह चुन लेता है, तोpip installसे पहलेLITERT_OV_OS_ID=ubuntu22याubuntu24सेट करें.
2. Python का वर्चुअल एनवायरमेंट बनाना
हमारा सुझाव है कि हर रात openvino व्हील को सिस्टम-वाइड OpenVINO इंस्टॉल से अलग रखा जाए.
python -m venv litert_env
# Linux / macOS
source litert_env/bin/activate
# Windows (PowerShell)
.\litert_env\Scripts\Activate.ps1
python -m pip install --upgrade pip
3. pip पैकेज इंस्टॉल करना
pip install --pre \
--extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly \
ai-edge-litert-nightly ai-edge-litert-sdk-intel-nightly
--extra-index-url की मदद से, pip, PyPI पर मौजूद पैकेज के साथ-साथ OpenVINO के इंडेक्स से पिन किए गए openvino नाइटली व्हील को हल कर सकता है.
4. इंस्टॉलेशन की पुष्टि करना
python -c "
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend
import ai_edge_litert_sdk_intel, openvino, os
print('Backend:', intel_openvino_backend.IntelOpenVinoBackend.id())
print('Dispatch:', intel_openvino_backend.get_dispatch_dir())
print('OpenVINO:', openvino.__version__)
print('SDK libs:', sorted(os.listdir(ai_edge_litert_sdk_intel.path_to_sdk_libs())))
print('Available devices:', openvino.Core().available_devices)
"
आउटपुट में क्या देखना है:
SDK libsसूचियांlibopenvino_intel_npu_compiler.so(Linux) याopenvino_intel_npu_compiler.dll(Windows) — AOT के लिए ज़रूरी है.Available devicesमेंNPUशामिल है. इससे पुष्टि होती है कि एनपीयू ड्राइवर इंस्टॉल है और OpenVINO, डिवाइस से कम्यूनिकेट कर सकता है.NPU, सिर्फ़ एओटी वाले सिस्टम (जहां ड्राइवर इंस्टॉल नहीं है) और Intel NPU हार्डवेयर के बिना सिस्टम पर मौजूद नहीं होगा.
5. AOT कंपाइल (ज़रूरी नहीं)
- यह किसी खास Intel NPU टारगेट (PTL या LNL) के लिए
.tfliteको पहले से कंपाइल करता है, ताकि रनटाइम कंपाइलर प्लग-इन वाले चरण को छोड़ सके. - इसके लिए, किसी फ़िज़िकल एनपीयू या एनपीयू ड्राइवर की ज़रूरत नहीं होती. इसके लिए, सिर्फ़
ai-edge-litert-nightlyऔरai-edge-litert-sdk-intel-nightlyकी ज़रूरत होती है. - क्रॉस-कंपाइलेशन की सुविधा उपलब्ध है: किसी भी Linux या Windows होस्ट पर कंपाइल करें. इसके बाद, नतीजे के तौर पर मिले
.tfliteको किसी भी ओएस के टारगेट पर भेजें और वहां चलाएं.
आउटपुट फ़ाइलों का नाम <model>_IntelOpenVINO_<SoC>_apply_plugin.tflite होता है.
from ai_edge_litert.aot import aot_compile
from ai_edge_litert.aot.vendors.intel_openvino import target as intel_target
# Compile for a single Intel NPU target (PTL or LNL).
aot_compile.aot_compile(
"model.tflite",
output_dir="out",
target=intel_target.Target(soc_model=intel_target.SocModel.PTL),
)
# Or omit target= to compile for every registered backend/target.
aot_compile.aot_compile("model.tflite", output_dir="out", keep_going=True)
6. एनपीयू पर अनुमान लगाने की सुविधा चालू करना
LiteRT, Intel NPU पर दो अनुमान लगाने वाले पाथ के साथ काम करता है:
- JIT — एक रॉ
.tfliteलोड करता है; कंपाइलर प्लगिन,CompiledModel.from_file()समय पर NPU के लिए काम करने वाले ऑप्स को बांटता है और कंपाइल करता है. इससे पहली बार चलने में कुछ समय लगता है. यह समय, मॉडल के हिसाब से अलग-अलग होता है. - AOT-compiled — चौथे चरण में तैयार किया गया
<model>_IntelOpenVINO_<SoC>_apply_plugin.tfliteलोड करें. यह लोड होने के समय, पार्टिशन और कंपाइलेशन के चरण को छोड़ देता है.
यह स्निपेट इन दोनों के लिए काम करता है:
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
model = CompiledModel.from_file(
"model.tflite", # raw tflite (JIT) or ..._apply_plugin.tflite (AOT)
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
)
sig_key = list(model.get_signature_list().keys())[0]
sig_idx = model.get_signature_index(sig_key)
input_buffers = model.create_input_buffers(sig_idx)
output_buffers = model.create_output_buffers(sig_idx)
model.run_by_index(sig_idx, input_buffers, output_buffers)
print("Fully accelerated:", model.is_fully_accelerated())
पुष्टि करें कि जेआईटी सुविधा काम कर रही है
JIT के पूरा होने पर, लॉग में यह जानकारी शामिल होती है (फ़ाइल एक्सटेंशन Linux पर .so और Windows पर .dll होता है):
INFO: [compiler_plugin.cc:236] Loaded plugin at: .../LiteRtCompilerPlugin_IntelOpenvino.{so,dll}
INFO: [compiler_plugin.cc:690] Partitioned subgraph<0>, selected N ops, from a total of N ops
INFO: [compiled_model.cc:1006] JIT compilation changed model, reserializing...
अगर ये लाइनें मौजूद नहीं हैं, लेकिन Fully accelerated: True अब भी रिपोर्ट किया गया है, तो इसका मतलब है कि मॉडल को NPU पर नहीं, बल्कि XNNPACK CPU फ़ॉलबैक पर चलाया गया था. JIT से जुड़ी समस्या हल करने वाली लाइन देखें.
7. मानदंड
# Dispatch library and the NPU compiler are auto-discovered from the wheel.
litert-benchmark --model=model.tflite --use_npu --num_runs=50
आम तौर पर इस्तेमाल होने वाले फ़्लैग:
| झंडा | डिफ़ॉल्ट | ब्यौरा |
|---|---|---|
--model PATH
|
— | .tflite मॉडल का पाथ
(ज़रूरी है). |
--signature KEY |
पहला | हस्ताक्षर कुंजी को चलाने के लिए. |
--use_cpu / --no_cpu
|
चालू है | सीपीयू ऐक्सलरेटर / सीपीयू फ़ॉलबैक को टॉगल करें. |
--use_gpu |
बंद है | जीपीयू ऐक्सेलरेटर चालू करें. |
--use_npu |
बंद है | Intel NPU ऐक्सलरेटर चालू करें. |
--require_full_delegation
|
बंद है | अगर मॉडल को चुने गए ऐक्सलरेटर पर पूरी तरह से ऑफ़लोड नहीं किया जाता है, तो यह जांच पूरी नहीं होगी. |
--num_runs N
|
50 | समय के हिसाब से अनुमान लगाने की प्रोसेस को दोहराने की संख्या. |
--warmup_runs N
|
5 | मेज़रमेंट से पहले, बिना समय तय किए वार्म-अप के लिए दोहराव. |
--num_threads N |
1 | सीपीयू थ्रेड की संख्या. |
--result_json PATH
|
— | लेटेंसी के आंकड़े, थ्रूपुट, और ऐक्सलरेटर की सूची के बारे में JSON फ़ॉर्मैट में खास जानकारी लिखो. |
--verbose |
बंद है | रनटाइम के दौरान लॉग इकट्ठा करने की अतिरिक्त सुविधा. |
ऐडवांस / ओवरराइड फ़्लैग — सिर्फ़ कस्टम बिल्ड की ओर ले जाने के लिए ज़रूरी हैं:
--dispatch_library_path, --compiler_plugin_path, --runtime_path.
अलग-अलग वेंडर के पहिए: JIT को Intel OV पर पिन करना
ध्यान दें: जब
Environment.create()को साफ़ तौर पर पाथ के बिना कॉल किया जाता है, तो यह वर्णमाला के क्रम मेंai_edge_litert/vendors/के तहत आने वाले वेंडर का अपने-आप पता लगाता है. साथ ही, यह सबसे पहले मिलने वाले वेंडर को रजिस्टर करता है. अलग-अलग वेंडर के सॉफ़्टवेयर इंस्टॉल करने पर, हो सकता है कि यह Intel OV न हो. सही फ़ोल्डर चुनने के लिए, Intel OV डायरेक्ट्री को साफ़ तौर पर पास करें.
- pip व्हील, रजिस्टर किए गए हर वेंडर के लिए कंपाइलर प्लगिन शिप करता है
(
intel_openvino/,google_tensor/,mediatek/,qualcomm/,samsung/). - Intel OV पाथ को फ़ोर्स करने के लिए (जब कई वेंडर एसडीके इंस्टॉल किए गए हों, तब यह तरीका अपनाने का सुझाव दिया जाता है), Intel OV डायरेक्ट्री को मैन्युअल तरीके से पास करें:
from ai_edge_litert.environment import Environment
from ai_edge_litert.compiled_model import CompiledModel
from ai_edge_litert.hardware_accelerator import HardwareAccelerator
from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov
env = Environment.create(
compiler_plugin_path=ov.get_compiler_plugin_dir(), # JIT compiler
dispatch_library_path=ov.get_dispatch_dir(), # runtime
)
model = CompiledModel.from_file(
"model.tflite",
hardware_accel=HardwareAccelerator.NPU | HardwareAccelerator.CPU,
environment=env,
)
रनटाइम, दी गई डायरेक्ट्री में मौजूद हर शेयर की गई लाइब्रेरी को लोड करता है. इसलिए, vendors/intel_openvino/compiler/ पर पॉइंट करने से सिर्फ़ Intel प्लगिन लोड होता है. साथ ही, सिबलिंग डायरेक्ट्री में मौजूद Google Tensor / MediaTek / Qualcomm / Samsung प्लगिन कभी नहीं बदले जाते.
सीएलआई के लिए, मिलते-जुलते फ़्लैग ये हैं:
DISPATCH_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_dispatch_dir())')
COMPILER_DIR=$(python3 -c 'from ai_edge_litert.aot.vendors.intel_openvino import intel_openvino_backend as ov; print(ov.get_compiler_plugin_dir())')
litert-benchmark --model=model.tflite --use_npu \
--compiler_plugin_path=$COMPILER_DIR \
--dispatch_library_path=$DISPATCH_DIR
एनपीयू के इस्तेमाल की पुष्टि करना
इस बात की पुष्टि करने के लिए कि मॉडल असल में एनपीयू पर चला है, दोनों सिग्नल देखें:
- लॉग में
Loading shared library: .../LiteRtDispatch_IntelOpenvino.{so,dll}शामिल है. इसका मतलब है कि Intel dispatch library लोड हो गई है (Linux पर.soऔर Windows पर.dll). model.is_fully_accelerated()रिटर्नTrue— हर ऑपरेशन को चुने गए ऐक्सलरेटर पर ऑफ़लोड किया गया.
सिर्फ़ is_fully_accelerated() का इस्तेमाल करना काफ़ी नहीं है: अगर डिस्पैच लाइब्रेरी कभी लोड नहीं हुई, तो सभी ऑप्स को NPU के बजाय XNNPACK/CPU पर पूरी तरह से ऑफ़लोड कर दिया गया.
Linux NPU सेटअप
ध्यान दें: अगर आपको सिर्फ़ एओटी की ज़रूरत है, तो इस सेक्शन को स्किप करें. इसके लिए, फ़िज़िकल एनपीयू की ज़रूरत नहीं होती.
जानकारी: एनपीयू ड्राइवर v1.32.1 (OpenVINO 2026.1 के साथ काम करता है) का इस्तेमाल करें. पुराने ड्राइवर,
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATUREके साथ काम नहीं करते.
# 1. NPU driver (Ubuntu 24.04 use -ubuntu2204 tarball for 22.04).
sudo dpkg --purge --force-remove-reinstreq \
intel-driver-compiler-npu intel-fw-npu intel-level-zero-npu intel-level-zero-npu-dbgsym || true
wget https://github.com/intel/linux-npu-driver/releases/download/v1.32.1/linux-npu-driver-v1.32.1.20260422-24767473183-ubuntu2404.tar.gz
tar -xf linux-npu-driver-v1.32.1.*.tar.gz
sudo apt update && sudo apt install -y libtbb12
sudo dpkg -i intel-fw-npu_*.deb intel-level-zero-npu_*.deb intel-driver-compiler-npu_*.deb
# 2. Level Zero loader v1.27.0.
wget https://snapshot.ppa.launchpadcontent.net/kobuk-team/intel-graphics/ubuntu/20260324T100000Z/pool/main/l/level-zero-loader/libze1_1.27.0-1~24.04~ppa2_amd64.deb
sudo dpkg -i libze1_*.deb
# 3. Permissions + verify.
sudo gpasswd -a ${USER} render && newgrp render
ls /dev/accel/accel0 # must exist after reboot
इसके बाद, क्विक स्टार्ट से इंस्टॉल + पुष्टि करने वाला स्निपेट चलाएं.
Windows NPU Setup
ध्यान दें: अगर आपको सिर्फ़ एओटी की ज़रूरत है, तो इस सेक्शन को स्किप करें. इसके लिए, फ़िज़िकल एनपीयू की ज़रूरत नहीं होती.
- Intel Download Center से, Intel NPU ड्राइवर (32.0.100.4724+) इंस्टॉल करें.
- पुष्टि करें कि डिवाइस मैनेजर, एनपीयू डिवाइस को न्यूरल प्रोसेसर में दिखाता है
(ड्राइवर के हिसाब से, इसे
Intel(R) AI BoostयाIntel(R) NPUके तौर पर दिखाया जाता है). - क्विक स्टार्ट से, इंस्टॉल करने और पुष्टि करने वाला स्निपेट चलाएं. साथ ही,
pipकोpython -m pipसे बदलें.
जानकारी:
import ai_edge_litert, DLL डायरेक्ट्री को अपने-आप रजिस्टर करता है. इसलिए, Python स्क्रिप्ट कोPATHसेटअप करने की ज़रूरत नहीं होती.os.add_dll_directory()Python का इस्तेमाल न करने वाले लोगों के लिए,setupvars.batचलाएं याPATHसे पहले<openvino>/libsजोड़ें.
सोर्स से बनाना
क्या आपका नेटवर्क प्रॉक्सी के पीछे है? बिल्ड स्क्रिप्ट चलाने से पहले,
http_proxy/https_proxy/no_proxyएक्सपोर्ट करें. ये इन्हें Docker और कंटेनर में फ़ॉरवर्ड करती हैं.
Linux (Docker, hermetic):
cd LiteRT/docker_build && ./build_wheel_with_docker.sh
Windows (PowerShell, Bazel in PATH):
.\ci\build_pip_package_with_bazel_windows.ps1
आउटपुट dist/ में दिखते हैं:
ai_edge_litert-*.whl— रनटाइम व्हील.ai_edge_litert_sdk_{intel,qualcomm,mediatek,samsung}-*.tar.gz— वेंडर sdists.- Intel sdist का साइज़ ~5 केबी है. NPU कंपाइलर
.so/.dllकोpip installसमय पर फ़ेच किया जाता है. इसलिए, एक ही sdist Linux और Windows पर काम करता है.
यूनिट टेस्ट
bazel test \
//litert/python/aot/vendors/intel_openvino:intel_openvino_backend_test \
//litert/c/options:litert_intel_openvino_options_test \
//litert/cc/options:litert_intel_openvino_options_test \
//litert/tools/flags/vendors:intel_openvino_flags_test
समस्या का हल
| समस्या | ठीक करें |
|---|---|
AOT फ़ेल हो गया: Device with "NPU" name is not registered |
एनपीयू कंपाइलर फ़ेच नहीं किया गया. ai_edge_litert_sdk_intel.path_to_sdk_libs() सूचियां libopenvino_intel_npu_compiler.so / .dll देखें. अगर यह खाली है, तो नेटवर्क ऐक्सेस के साथ फिर से इंस्टॉल करें या LITERT_OV_OS_ID=ubuntu22/ubuntu24 सेट करें. |
JIT, एनपीयू के बजाय सीपीयू पर काम करता है (कोई Partitioned subgraph लॉग नहीं, कोई Loaded plugin लॉग नहीं, Fully accelerated: True अब भी प्रिंट किया गया) |
कंपाइलर प्लगिन नहीं मिला. पुष्टि करें कि ov.get_compiler_plugin_dir(), ai_edge_litert/vendors/intel_openvino/compiler/ के तहत पाथ दिखाता है. अगर एक से ज़्यादा वेंडर एसडीके इंस्टॉल किए गए हैं, तो Environment.create() को साफ़ तौर पर Environment.create() (या --compiler_plugin_path=... को litert-benchmark) पर पास करें.compiler_plugin_path=ov.get_compiler_plugin_dir() |
JIT फ़ेल हो गया: Cannot load library .../openvino/libs/libopenvino_intel_npu_compiler.so (Linux) / openvino_intel_npu_compiler.dll (Windows) |
एसडीके sdist, NPU कंपाइलर को पहली बार import ai_edge_litert_sdk_intel पर openvino/libs/ में कॉपी करता है. अगर कॉपी करने की प्रोसेस को छोड़ दिया गया है (रीड ओनली फ़ाइल सिस्टम, openvino मौजूद नहीं है), तो openvino इंस्टॉल होने के बाद, ai-edge-litert-sdk-intel को फिर से इंस्टॉल करें. इसके बाद, import ai_edge_litert को नई प्रोसेस में इंस्टॉल करें. |
Level0 pfnCreate2 result: ZE_RESULT_ERROR_UNSUPPORTED_FEATURE |
NPU ड्राइवर को v1.32.1 (Linux) पर अपग्रेड किया गया है. |
/dev/accel/accel0 नहीं मिला |
ड्राइवर को डीबग करने के लिए sudo dmesg | grep -i vpu; इंस्टॉल करने के बाद रीबूट करें. |
| एनपीयू पर अनुमति नहीं दी गई | sudo gpasswd -a ${USER} render && newgrp render. |
| Windows: डिवाइस मैनेजर में एनपीयू मौजूद नहीं है | Intel Download Center से NPU ड्राइवर 32.0.100.4724+ इंस्टॉल करें. |
Windows: Failed to initialize Dispatch API / missing DLLs |
पक्का करें कि import ai_edge_litert पहले चले (DLL डायरेक्ट्री अपने-आप रजिस्टर हो जाती हैं); Python का इस्तेमाल न करने वाले कॉलर के लिए, setupvars.bat चलाएं या PATH से पहले <openvino>/libs जोड़ें. |
Windows बिल्ड: LNK2001 fixed_address_empty_string, C2491 dllimport, Python 3.12+ fails |
Protobuf ABI / Python वर्शन की ज़रूरी शर्तें — ci/build_pip_package_with_bazel_windows.ps1 देखें; Windows के लिए Python 3.11 की ज़रूरत होती है. |
सीमाएं
OpenVINO डिसपैच पाथ के ज़रिए, सिर्फ़ एनपीयू डिवाइस का इस्तेमाल किया जा सकता है. सीपीयू पर अनुमान लगाने के लिए, सिर्फ़ HardwareAccelerator.CPU (XNNPACK) का इस्तेमाल करें.
C++ API
ज़रूरी शर्तें और बिल्ड सेटअप
ज़रूरी शर्तें:
- Visual Studio 2022 या इसके बाद का वर्शन (C++ डेवलपमेंट टूल इंस्टॉल होने चाहिए).
- git: https://git-scm.com/install/ से git इंस्टॉल करें. पक्का करें कि
C:\Program Files\Git\bin and C:\Program Files\Git\cmdको आपके सिस्टम के PATH एनवायरमेंट वैरिएबल में शामिल किया गया हो, ताकि bash.exe और git.exe को LiteRT/LiteRT-LM की बिल्ड प्रोसेस से खोजा जा सके. - bazelisk: bazelisk इंस्टॉल करें और इसकी जगह को अपने सिस्टम के
PATHएनवायरमेंट वैरिएबल में शामिल करें: https://bazel.build/install/bazelisk. - Cmake: https://cmake.org/download/ से Cmake 4.3.0 या इसके बाद का वर्शन इंस्टॉल करें. साथ ही, यह पुष्टि करें कि Cmake आपके सिस्टम के पाथ में शामिल है.
- Python: पक्का करें कि Python 3.11 या इसके बाद का वर्शन इंस्टॉल हो और python.exe आपके PATH में हो.
- Windows की सेटिंग: Windows की सेटिंग में जाकर, डेवलपर मोड चालू करें.
Intel NPU के लिए LiteRT टूल और प्लगिन बनाना
LiteRT के साथ Intel NPU पर मॉडल चलाने के लिए, उन्हें LiteRT Intel OpenVINO कंपाइलर प्लगिन का इस्तेमाल करके कंपाइल करना होगा. इसके अलावा, Intel NPU पर एक्ज़ीक्यूट किए जाने वाले किसी भी कंपाइल किए गए मॉडल को LiteRT Intel OpenVINO डिस्पैच प्लगिन को सौंपना होगा.
LiteRT, इन प्लगिन को जिस तरीके से चालू करता है उसके बारे में यहां बताया गया है:
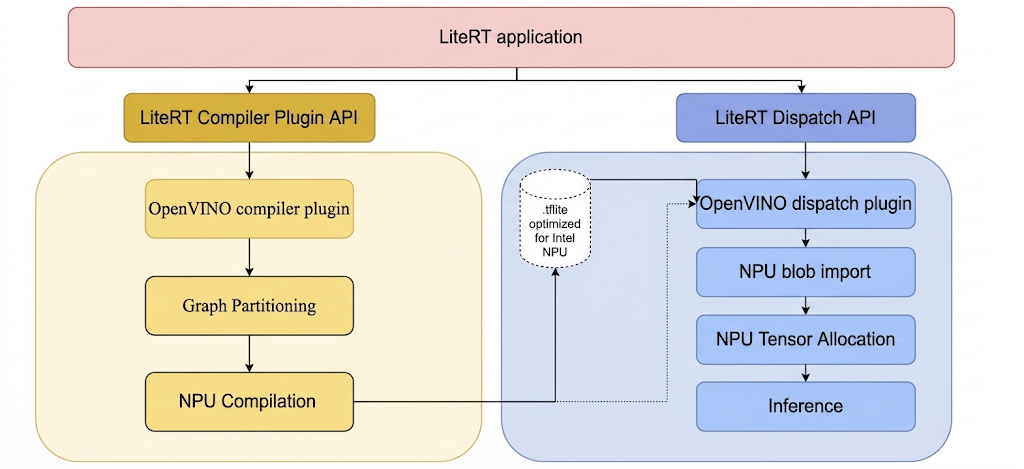
LiteRT टूल और Intel प्लगिन बनाने का तरीका.
LiteRT से कोई भी एक्ज़ीक्यूटेबल या लाइब्रेरी बनाने से पहले, एक लोकल डायरेक्ट्री बनाएं. उदाहरण के लिए, C:\bzl. बिल्ड आउटपुट बाइनरी को इस डायरेक्ट्री से इकट्ठा किया जाएगा. Intel OpenVINO dispatch प्लगइन बनाना
# At the top-level directory of LiteRT repository
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
इसके अलावा, टारगेट पर @litert प्रीफ़िक्स जोड़कर, LiteRT-LM रिपॉज़िटरी से भी डिसपैच प्लगिन बनाया जा सकता है. LiteRT रिपॉज़िटरी से फ़ॉलो किए जाने वाले सभी टारगेट के लिए, यह एक जैसा होता है.
# At the top-level directory of LiteRT-LM repository
bazelisk --output_base=C:\bzl build @litert//litert/vendors/intel_openvino/dispatch:LiteRtDispatch --config=windows
Intel OpenVINO कंपाइलर प्लगिन बनाना
bazelisk --output_base=C:\bzl build //litert/vendors/intel_openvino/compiler:LiteRtCompilerPlugin --config=windows
LiteRT Ahead-of-Time (AOT) कंपाइलर यूटिलिटी बनाएं LiteRT के कुछ टूल को Intel NPU पर चलाने से पहले, मॉडल के लिए AOT कंपाइलेशन की ज़रूरत होती है. LiteRT AOT कंपाइलर यूटिलिटी के लिए बिल्ड निर्देश:
bazelisk --output_base=C:\bzl build
//litert/tools:apply_plugin_main --config=windows
LiteRT मॉडल रनर बनाना LiteRT मॉडल रनर का इस्तेमाल, Intel NPU पर मॉडल चलाने के लिए किया जा सकता है. इसके लिए, नॉन-प्रीकंपाइल मॉडल या AOT-कंपाइल मॉडल का इस्तेमाल किया जा सकता है. मॉडल रनर बनाने के लिए निर्देश:
bazelisk --output_base=C:\bzl build //litert/tools:run_model --config=windows
LiteRT मॉडल के लिए बेंचमार्क मॉडल यूटिलिटी बनाना LiteRT मॉडल के लिए बेंचमार्क टूल का इस्तेमाल, Intel NPU पर किसी मॉडल के अनुमान की परफ़ॉर्मेंस को बेंचमार्क करने के लिए किया जा सकता है. अगर बेंचमार्क टूल बनाने का निर्देश दिया गया है, तो:
bazelisk --output_base=C:\bzl build //litert/tools:benchmark_model --config=windows --define=protobuf_allow_msvc=true
LiteRT में न्यूमेरिक वैल्यू की जांच करने वाला टूल बनाना
bazelisk --output_base=C:\bzl build //litert/tools:npu_numerics_check --config=windows
ऐडवांस इस्तेमाल: Intel OpenVINO SDK को पसंद के मुताबिक बनाकर इस्तेमाल करना
कंपाइलर और डिसपैच प्लगिन को कंपाइल करते समय, LiteRT बिल्ड सिस्टम, पहले से बने Intel OpenVINO SDK को अपने-आप फ़ेच करता है.
अगर आपके प्रोजेक्ट के लिए Intel OpenVINO SDK का कोई खास या कस्टम वर्शन ज़रूरी है, तो प्लगिन बनाना शुरू करने से पहले, कॉन्फ़िगरेशन के ये अतिरिक्त चरण पूरे करें:
- Windows के लिए, OpenVINO की नई रिलीज़ का बाइनरी डाउनलोड करें. इसके लिए, https://www.intel.com/content/www/us/en/download/753640/intel-distribution-of-openvino-toolkit.html पर जाएं. इसके बाद, इसे लोकल डिस्क में निकालें. उदाहरण के लिए,
C:\Intel\intel_openvino. - पक्का करें कि इस पाथ के तहत मौजूद चाइल्ड डायरेक्ट्री का नाम "openvino" हो. इसमें "runtime" और "include" जैसी सब-डायरेक्ट्री शामिल हों.
- अपनी कंसोल (कमांड प्रॉम्प्ट या PowerShell) में, क्लोन की गई LiteRT रिपॉज़िटरी की रूट डायरेक्ट्री पर जाएं. इसके बाद, OPENVINO_NATIVE_DIR वैरिएबल सेट करें. पक्का करें कि इसके आखिर में कोई
\`), for example:न हो.\`), for example:set OPENVINO_NATIVE_DIR=C:\Intel\intel_openvino`
कस्टम मॉडल का एओटी कंपाइलेशन
इस सेक्शन में, एनवायरमेंट तैयार किया जाता है. साथ ही, LiteRT के लिए कस्टम TFLite, PyTorch या JAX मॉडल का एओटी कंपाइलेशन किया जाता है.
Intel NPU के लिए मॉडल कंपाइल करने की प्रोसेस के दौरान, LiteRT, मॉडल ग्राफ़ की पुष्टि करता है. यह पुष्टि, LiteRT Intel OpenVINO कंपाइलर प्लगिन के साथ काम करने वाले ऑपरेटर के हिसाब से की जाती है. कंपाइलर प्लगिन के साथ काम करने वाले ऑपरेटर या सबग्राफ़ के लिए, LiteRT ऐसे हर सबग्राफ़ को DISPATCH_OP में कंपाइल करता है. इसके बाद, यह DISPATCH_OP, ग्राफ़ में मौजूद ओरिजनल सबग्राफ़ की जगह ले लेता है. Intel OpenVINO कंपाइलर के साथ काम न करने वाले ऑपरेटर, ग्राफ़ में पहले जैसे ही रहते हैं. इसलिए, एओटी कंपाइलेशन से पूरी तरह से डेलिगेट किया गया मॉडल या आंशिक रूप से डेलिगेट किया गया मॉडल मिल सकता है. यहां पूरी तरह से डेलिगेट किए गए, एओटी-कंपाइल किए गए मॉडल का एक उदाहरण दिया गया है:
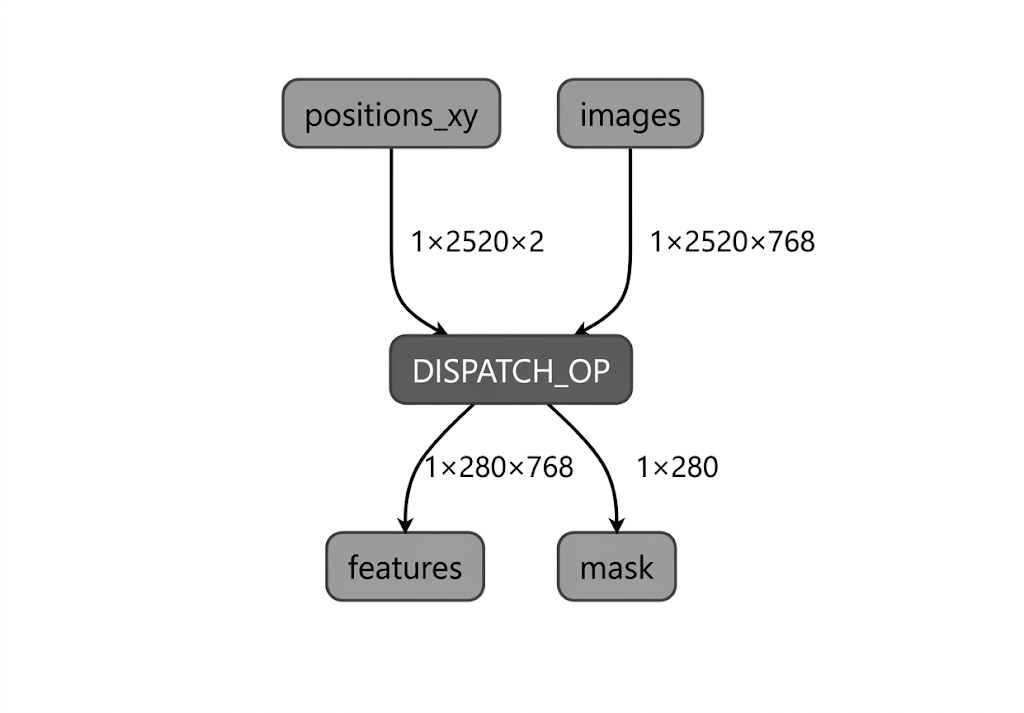
LiteRT की apply_plugin_main यूटिलिटी (apply_plugin_main.exe) एक एओटी कंपाइलेशन यूटिलिटी है. इसका इस्तेमाल इस काम के लिए किया जा सकता है. Intel प्लैटफ़ॉर्म पर इस यूटिलिटी के इस्तेमाल का उदाहरण:
.\apply_plugin_main.exe -cmd apply --model="C:\models\model.tflite" -o C:\models\model_aot.tflite --soc_model=PTL --soc_manufacturer "IntelOpenVINO" --libs C:\litertlibs
कृपया ध्यान दें कि Intel OpenVINO SDK के बाइनरी डिस्ट्रिब्यूशन में शामिल डिफ़ॉल्ट एनपीयू कंपाइलर का इस्तेमाल, Intel Core Ultra सीरीज़ 2 और इसके बाद के एसओसी के लिए किया जाता है. अगर किसी ऐसे एनपीयू के लिए मॉडल कंपाइल किया जा रहा है जो सहायता पाने वाले एनपीयू की सूची में शामिल नहीं है, तो कंपाइलर टाइप साफ़ तौर पर बताना होगा. हालांकि, Intel Core Ultra 2 और इसके बाद के वर्शन के लिए यह ज़रूरी नहीं है.
set IE_NPU_COMPILER_TYPE=PLUGIN
आपके ऐप्लिकेशन में JIT बनाम AOT कंपाइलेशन
अपने LiteRT ऐप्लिकेशन में मॉडल कंपाइल करने के लिए, दो तरीके हैं: AOT कंपाइलेशन, जिसके बारे में हम पहले ही बता चुके हैं. दूसरा तरीका है, Just-in-time (JIT) कंपाइलेशन.
AOT कंपाइलेशन की मदद से, मोड को डिप्लॉयमेंट से पहले ऑफ़लाइन कंपाइल किया जाता है. इसे बाद में इस्तेमाल करने के लिए सेव किया जा सकता है. इसका इस्तेमाल आम तौर पर तब किया जाता है, जब कंपाइलेशन के लिए डिवाइस पर बहुत ज़्यादा संसाधनों की ज़रूरत होती है. यह ज़रूरी नहीं है कि मॉडल को उसी डिवाइस पर डिप्लॉय किया जाए जिस पर ट्रेनिंग दी गई है. आपके कोड में एओटी कंपाइलेशन का उदाहरण:
void AotCompileForOpenVINO() {
auto run = std::make_unique<ApplyPluginRun>();
// Full pipeline: partition → compile → embed bytecode in .tflite
run->cmd = ApplyPluginRun::Cmd::APPLY;
// Path to directory containing LiteRtComplilerPlugin.dll
run->lib_search_paths.push_back("/path/to/plugin/dir/");
// Input model
run->model.emplace("model.tflite");
// Intel OpenVINO target
run->soc_manufacturer.emplace("IntelOpenVINO");
run->soc_models.push_back("PTL"); // or "LNL"
// Output stream for the AOT-compiled model
std::stringstream compiled_output;
run->outs.push_back(compiled_output);
// Run AOT compilation
auto status = ApplyPlugin(std::move(run));
// compiled_output now contains .tflite with embedded OpenVINO bytecode
}
AOT-कंपाइल किए गए मॉडल से अनुमान लगाने का तरीका:
void RunAotCompiledModel() {
auto env = litert::Environment::Create({}).value();
// Load AOT-compiled model, still must specify NPU accelerator
auto compiled_model = litert::CompiledModel::Create(
env, "model_aot.tflite", litert::HwAccelerators::kNpu).value();
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
input_buffers[0].Write<float>({/* data */});
compiled_model.Run(input_buffers, output_buffers);
}
इसका दूसरा तरीका यह है कि मॉडल को डिवाइस पर रनटाइम के दौरान JIT कंपाइल किया जाए. यह ज़्यादा बेहतर है: इसके लिए, सिर्फ़ एक ऐसी मॉडल फ़ाइल की ज़रूरत होती है जो बैकएंड से जुड़ी न हो.
// Create environment
auto env = litert::Environment::Create({}).value();
// JIT compile for NPU
auto compiled_model = litert::CompiledModel::Create(
env, "model.tflite", litert::HwAccelerators::kNpu).value();
// Create I/O buffers
auto input_buffers = compiled_model.CreateInputBuffers().value();
auto output_buffers = compiled_model.CreateOutputBuffers().value();
// Fill inputs
input_buffers[0].Write<float>({/* input data */});
// Run inference
compiled_model.Run(input_buffers, output_buffers);
benchmark_model के साथ बेंचमार्क करना
LiteRT की benchmark_model यूटिलिटी (benchmark_model.exe) को खास तौर पर, एनपीयू पर एओटी-कंपाइल किए गए मॉडल की परफ़ॉर्मेंस की तुलना करने के लिए डिज़ाइन किया गया है. इसका इस्तेमाल, LiteRT में सीपीयू बैकएंड (XNNPack) की परफ़ॉर्मेंस की तुलना करने के लिए किया जा सकता है. Intel NPU पर AOT-कंपाइल किए गए मॉडल की परफ़ॉर्मेंस की तुलना करने के लिए, कमांड का उदाहरण:
.\benchmark_model.exe --graph=C:\models\model_aot.tflite --use_npu=true --compiler_plugin_library_path=C:\litertlib --dispatch_library_path=C:\litertlib --compiler_cache_path=C:\models
npu_numerics_check की मदद से, जवाब में दिए गए आंकड़ों की जांच करना
npu_numerics_check यूटिलिटी का इस्तेमाल, NPU पर कंपाइल किए गए मॉडल की संख्यात्मक सटीकता की पुष्टि करने के लिए किया जाता है. इसकी तुलना, बेसलाइन (आम तौर पर सीपीयू बैकएंड, XNNPack) से की जाती है. यह चरण इसलिए ज़रूरी है, ताकि यह पक्का किया जा सके कि एनपीयू को डेलिगेशन करने से, मॉडल की क्वालिटी पर असर डालने वाले अस्वीकार्य संख्यात्मक विचलन न हों.
संख्याओं की जांच करना इस यूटिलिटी के लिए, एओटी-कंपाइल किए गए मॉडल की ज़रूरत होती है. यह मॉडल के आउटपुट की तुलना, सीपीयू पर चलने वाले ओरिजनल मॉडल से करता है.
.\npu_numerics_check.exe --npu_model=C:\models\model_aot.tflite --cpu_model=C:\models\model.tflite --dispatch_library_path=C:\litertlib
अगले चरण
- यूनिफ़ाइड एनपीयू गाइड से शुरुआत करें: LiteRT की मदद से एनपीयू ऐक्सेलरेट करना
- वहां दिए गए कन्वर्ज़न और डिप्लॉयमेंट के चरणों का पालन करें. साथ ही, जहां लागू हो वहां Qualcomm को चुनें.
- एलएलएम के लिए, LiteRT-LM का इस्तेमाल करके एनपीयू पर एलएलएम को एक्ज़ीक्यूट करना लेख पढ़ें.