
Ogni calcolatrice è un nodo di un grafico. Descriviamo come creare un nuovo
una calcolatrice, come inizializzare una calcolatrice, come eseguire i suoi calcoli,
flussi di input e output, timestamp e opzioni. Ciascun nodo del grafico
implementato come Calculator. La maggior parte dell'esecuzione del grafico avviene all'interno del suo
calcolatrici. Un calcolatore potrebbe ricevere zero o più flussi di input e/o laterali
e produce zero o più flussi di output e/o pacchetti laterali.
CalculatorBase
Viene creata una calcolatrice definendo una nuova sottoclasse del
CalculatorBase
mediante l'implementazione di vari metodi e la registrazione della nuova sottoclasse
Mediapipe. Come minimo, un nuovo calcolatore deve implementare i quattro metodi seguenti
GetContract()- Gli autori dei calcolatori possono specificare i tipi di input e output previsti di una calcolatrice in GetContract(). Quando un grafico viene inizializzato, chiama un metodo statico per verificare se i tipi di pacchetto gli ingressi e le uscite connessi corrispondono alle informazioni e la specifica del prodotto.
Open()- Dopo l'avvio del grafico, il framework chiama
Open(). Il lato di input a questo punto sono disponibili pacchetti per il calcolatore.Open()Interpreta le operazioni di configurazione dei nodi (vedi Grafici) e prepara lo stato della calcolatrice per esecuzione di un grafico. Questa funzione può scrivere pacchetti negli output della calcolatrice. Un errore durante il periodoOpen()può per terminare l'esecuzione del grafico.
- Dopo l'avvio del grafico, il framework chiama
Process()- Per un calcolatore con input, il framework chiama ripetutamente
Process()ogni volta che almeno un flusso di input ha un pacchetto disponibile. Il framework per impostazione predefinita garantisce che tutti gli input abbiano lo stesso timestamp (vedi Sincronizzazione per ulteriori informazioni). Più di unoProcess()chiamate possono essere richiamate contemporaneamente durante l'esecuzione parallela sia abilitato. Se si verifica un errore duranteProcess(), il framework chiamaClose()e l'esecuzione del grafico termina.
- Per un calcolatore con input, il framework chiama ripetutamente
Close()- Al termine di tutte le chiamate a
Process()o quando tutti gli stream di input si chiudono, il framework chiamaClose(). Questa funzione viene sempre chiamata seOpen()è stato chiamato e ha avuto esito positivo anche se l'esecuzione del grafico è terminata a causa di un errore. Nessun input disponibile tramite flussi di input duranteClose(), ma ha ancora accesso ai pacchetti lato di input e pertanto possono scrivere output. Dopo il ritorno diClose(), la calcolatrice dovrebbe essere considerato un nodo inattivo. L'oggetto Calcolatore viene eliminato al termine del grafico.
- Al termine di tutte le chiamate a
Di seguito sono riportati snippet di codice CalculatorBase.h.
class CalculatorBase {
public:
...
// The subclasses of CalculatorBase must implement GetContract.
// ...
static absl::Status GetContract(CalculatorContract* cc);
// Open is called before any Process() calls, on a freshly constructed
// calculator. Subclasses may override this method to perform necessary
// setup, and possibly output Packets and/or set output streams' headers.
// ...
virtual absl::Status Open(CalculatorContext* cc) {
return absl::OkStatus();
}
// Processes the incoming inputs. May call the methods on cc to access
// inputs and produce outputs.
// ...
virtual absl::Status Process(CalculatorContext* cc) = 0;
// Is called if Open() was called and succeeded. Is called either
// immediately after processing is complete or after a graph run has ended
// (if an error occurred in the graph). ...
virtual absl::Status Close(CalculatorContext* cc) {
return absl::OkStatus();
}
...
};
La vita di una calcolatrice
Durante l'inizializzazione di un grafico MediaPipe, il framework chiama una
GetContract() metodo statico per determinare i tipi di pacchetti previsti.
Il framework crea e distrugge l'intero calcolatore per ogni esecuzione del grafico (ad es. una volta per video o una volta per immagine). Oggetti costosi o di grandi dimensioni che rimangono costante tra le esecuzioni del grafico deve essere fornita come pacchetti sul lato di input in modo che i calcoli non vengono ripetuti nelle esecuzioni successive.
Dopo l'inizializzazione, per ogni esecuzione del grafico si verifica la seguente sequenza:
Open()Process()(ripetutamente)Close()
Il framework chiama Open() per inizializzare il calcolatore. Open() deve
interpretare le opzioni e impostare lo stato di esecuzione di un singolo grafico della calcolatrice. Open()
potrebbe ottenere pacchetti sul lato di input e scrivere pacchetti negli output del calcolatore. Se
appropriato, deve chiamare SetOffset() per ridurre il potenziale buffering di pacchetti
di flussi di input.
Se si verifica un errore durante Open() o Process() (come indicato da uno di essi)
e restituisce uno stato diverso da Ok), l'esecuzione del grafico viene terminata senza ulteriori chiamate
ai metodi della calcolatrice e quest'ultima viene distrutta.
Per un calcolatore con input, il framework chiama Process() ogni volta che almeno
in un input è disponibile un pacchetto. Il framework garantisce che tutti gli input abbiano
lo stesso timestamp, i timestamp aumentano con ogni chiamata a Process() e
la consegna di tutti i pacchetti. Di conseguenza, per alcuni input potrebbero non essere disponibili
pacchetti quando viene chiamato Process(). Un input il cui pacchetto è mancante sembra
e produrre un pacchetto vuoto (senza timestamp).
Il framework chiama Close() dopo tutte le chiamate a Process(). Tutti gli input
esaurito, ma Close() ha accesso ai pacchetti lato di input e può
scrivere output. Dopo il reso Close, la calcolatrice viene distrutta.
Le calcolatrici senza input sono chiamate origini. Un calcolatore di origine
continua a ricevere Process() chiamato finché restituisce uno stato Ok. R
il calcolatore di origine indica che è esaurito restituendo uno stato di interruzione.
ad esempio mediaPipe::tool::StatusStop().
Identificazione di input e output
L'interfaccia pubblica di un calcolatore è composta da un insieme di flussi di input e
i flussi di dati di output. In un CalculatorGraphConfiguration, gli output di alcune
le calcolatrici sono collegate agli input di altre calcolatrici utilizzando
i flussi di dati. I nomi dei flussi sono in genere minuscoli, mentre i tag di input e output sono
di solito in MAIUSCOLO. Nell'esempio riportato di seguito, l'output con il nome tag VIDEO è
collegato all'input con nome tag VIDEO_IN tramite lo stream denominato
video_stream.
# Graph describing calculator SomeAudioVideoCalculator
node {
calculator: "SomeAudioVideoCalculator"
input_stream: "INPUT:combined_input"
output_stream: "VIDEO:video_stream"
}
node {
calculator: "SomeVideoCalculator"
input_stream: "VIDEO_IN:video_stream"
output_stream: "VIDEO_OUT:processed_video"
}
I flussi di input e output possono essere identificati da numero di indice, nome tag o da un
combinazione di nome tag e numero di indice. Puoi vedere alcuni esempi di input
di output nell'esempio riportato di seguito. SomeAudioVideoCalculator identifica
l'output video per tag e l'audio generato dalla combinazione di tag e
indice. L'input con il tag VIDEO è connesso allo stream denominato
video_stream. Gli output con tag AUDIO e indici 0 e 1 sono
connesso agli stream denominati audio_left e audio_right.
SomeAudioCalculator identifica i propri input audio solo in base all'indice (non è necessario alcun tag).
# Graph describing calculator SomeAudioVideoCalculator
node {
calculator: "SomeAudioVideoCalculator"
input_stream: "combined_input"
output_stream: "VIDEO:video_stream"
output_stream: "AUDIO:0:audio_left"
output_stream: "AUDIO:1:audio_right"
}
node {
calculator: "SomeAudioCalculator"
input_stream: "audio_left"
input_stream: "audio_right"
output_stream: "audio_energy"
}
Nell'implementazione del calcolatore, gli input e gli output sono identificati anche da tag nome e numero di indice. Nella funzione riportata di seguito sono indicati input e output:
- In base al numero di indice: il flusso di input combinato è identificato semplicemente dall'indice
0. - Per nome tag: lo stream di output video è identificato dal nome del tag "VIDEO".
- In base al nome del tag e al numero di indice: gli stream audio in uscita sono identificati dal simbolo
combinazione del nome del tag
AUDIOe dei numeri di indice0e1.
// c++ Code snippet describing the SomeAudioVideoCalculator GetContract() method
class SomeAudioVideoCalculator : public CalculatorBase {
public:
static absl::Status GetContract(CalculatorContract* cc) {
cc->Inputs().Index(0).SetAny();
// SetAny() is used to specify that whatever the type of the
// stream is, it's acceptable. This does not mean that any
// packet is acceptable. Packets in the stream still have a
// particular type. SetAny() has the same effect as explicitly
// setting the type to be the stream's type.
cc->Outputs().Tag("VIDEO").Set<ImageFrame>();
cc->Outputs().Get("AUDIO", 0).Set<Matrix>();
cc->Outputs().Get("AUDIO", 1).Set<Matrix>();
return absl::OkStatus();
}
Elaborazione
La chiamata Process() chiamata su un nodo non di origine deve restituire absl::OkStatus() a
indicare che tutto è andato a buon fine o utilizzare qualsiasi altro codice di stato per segnalare un errore
Se un calcolatore non di origine restituisce tool::StatusStop(), viene indicata la
verrà annullato in anticipo. In questo caso, tutte le calcolatrici e i grafici di origine
i flussi di input verranno chiusi (e i pacchetti rimanenti si propagheranno attraverso
grafico).
Un nodo di origine in un grafico continuerà a ricevere Process(), finché
che restituisce absl::OkStatus(). Per indicare che non sono disponibili altri dati.
ritorno generato: tool::StatusStop(). Qualsiasi altro stato indica che un errore è stato rilevato
si è verificato un errore.
Close() restituisce absl::OkStatus() per indicare l'esito positivo. Qualsiasi altro stato
indica un errore.
Ecco la funzione di base di Process(). Utilizza il metodo Input() (che può
da utilizzare solo se la calcolatrice ha un singolo input) per richiedere i suoi dati di input. it
quindi utilizza std::unique_ptr per allocare la memoria necessaria per il pacchetto di output,
ed esegue i calcoli. Al termine, rilascia il puntatore quando lo aggiunge
il flusso di output.
absl::Status MyCalculator::Process() {
const Matrix& input = Input()->Get<Matrix>();
std::unique_ptr<Matrix> output(new Matrix(input.rows(), input.cols()));
// do your magic here....
// output->row(n) = ...
Output()->Add(output.release(), InputTimestamp());
return absl::OkStatus();
}
Opzioni della calcolatrice
I calcolatori accettano i parametri di elaborazione tramite (1) pacchetti di flussi di input (2)
e (3) opzioni di calcolo. Opzioni della calcolatrice, se
specificato, vengono visualizzati come valori letterali nel campo node_options della
CalculatorGraphConfiguration.Node messaggio.
node {
calculator: "TfLiteInferenceCalculator"
input_stream: "TENSORS:main_model_input"
output_stream: "TENSORS:main_model_output"
node_options: {
[type.googleapis.com/mediapipe.TfLiteInferenceCalculatorOptions] {
model_path: "mediapipe/models/detection_model.tflite"
}
}
}
Il campo node_options accetta la sintassi proto3. In alternativa, calcolatrice
le opzioni possono essere specificate nel campo options utilizzando la sintassi proto2.
node {
calculator: "TfLiteInferenceCalculator"
input_stream: "TENSORS:main_model_input"
output_stream: "TENSORS:main_model_output"
node_options: {
[type.googleapis.com/mediapipe.TfLiteInferenceCalculatorOptions] {
model_path: "mediapipe/models/detection_model.tflite"
}
}
}
Non tutti i calcolatori accettano queste opzioni. Per accettare opzioni,
calcolatrice di solito definirà un nuovo tipo di messaggio protobuf per rappresentare il suo
quali PacketClonerCalculatorOptions. La calcolatrice
leggere quel messaggio protobuf nel suo metodo CalculatorBase::Open ed eventualmente
anche nella sua funzione CalculatorBase::GetContract o nella sua
CalculatorBase::Process. Di solito, il nuovo tipo di messaggio protobuf
essere definito come schema protobuf utilizzando un file ".proto" e un file YAML
mediapipe_proto_library() regola di build.
mediapipe_proto_library(
name = "packet_cloner_calculator_proto",
srcs = ["packet_cloner_calculator.proto"],
visibility = ["//visibility:public"],
deps = [
"//mediapipe/framework:calculator_options_proto",
"//mediapipe/framework:calculator_proto",
],
)
Calcolatrice di esempio
Questa sezione illustra l'implementazione di PacketClonerCalculator, che
svolge un lavoro relativamente semplice e viene utilizzato in molti grafici di calcolatrici.
PacketClonerCalculator produce semplicemente una copia dei suoi pacchetti di input più recenti
on demand.
PacketClonerCalculator è utile quando i timestamp dei pacchetti di dati in arrivo
non sono perfettamente allineati. Supponiamo di avere una stanza con un microfono, una luce
sensore e una videocamera che raccoglie dati sensoriali. Ciascuno dei sensori
opera in modo indipendente e raccoglie dati a intermittenza. Supponiamo che l'output
di ciascun sensore:
- microfono = volume in decibel del suono nella stanza (numero intero)
- sensore di luce = luminosità della stanza (numero intero)
- videocamera = immagine RGB della stanza (ImageFrame)
La nostra semplice pipeline di percezione è progettata per elaborare i dati sensoriali di questi 3 in modo che in qualsiasi momento quando riceviamo i dati dei fotogrammi dell'immagine dalla fotocamera viene sincronizzato con gli ultimi dati raccolti sul volume del microfono e sulla luce dati sulla luminosità del sensore. Per fare questo con MediaPipe, la nostra pipeline di percezione ha 3 flussi di input:
- room_mic_signal: ogni pacchetto di dati nel flusso di input è costituito da dati interi che rappresentano il volume dell'audio in una stanza con timestamp.
- room_lightening_sensor: ogni pacchetto di dati nel flusso di input è un numero intero dati che rappresentano il livello di luminosità della stanza illuminata con timestamp.
- room_video_tick_signal. Ogni pacchetto di dati nel flusso di input viene frame dei dati video che rappresentano i video raccolti dalla fotocamera nel stanza con timestamp.
Di seguito è riportata l'implementazione del PacketClonerCalculator. Puoi vedere
GetContract(), Open() e Process(), nonché l'istanza
variabile current_ che contiene i pacchetti di input più recenti.
// This takes packets from N+1 streams, A_1, A_2, ..., A_N, B.
// For every packet that appears in B, outputs the most recent packet from each
// of the A_i on a separate stream.
#include <vector>
#include "absl/strings/str_cat.h"
#include "mediapipe/framework/calculator_framework.h"
namespace mediapipe {
// For every packet received on the last stream, output the latest packet
// obtained on all other streams. Therefore, if the last stream outputs at a
// higher rate than the others, this effectively clones the packets from the
// other streams to match the last.
//
// Example config:
// node {
// calculator: "PacketClonerCalculator"
// input_stream: "first_base_signal"
// input_stream: "second_base_signal"
// input_stream: "tick_signal"
// output_stream: "cloned_first_base_signal"
// output_stream: "cloned_second_base_signal"
// }
//
class PacketClonerCalculator : public CalculatorBase {
public:
static absl::Status GetContract(CalculatorContract* cc) {
const int tick_signal_index = cc->Inputs().NumEntries() - 1;
// cc->Inputs().NumEntries() returns the number of input streams
// for the PacketClonerCalculator
for (int i = 0; i < tick_signal_index; ++i) {
cc->Inputs().Index(i).SetAny();
// cc->Inputs().Index(i) returns the input stream pointer by index
cc->Outputs().Index(i).SetSameAs(&cc->Inputs().Index(i));
}
cc->Inputs().Index(tick_signal_index).SetAny();
return absl::OkStatus();
}
absl::Status Open(CalculatorContext* cc) final {
tick_signal_index_ = cc->Inputs().NumEntries() - 1;
current_.resize(tick_signal_index_);
// Pass along the header for each stream if present.
for (int i = 0; i < tick_signal_index_; ++i) {
if (!cc->Inputs().Index(i).Header().IsEmpty()) {
cc->Outputs().Index(i).SetHeader(cc->Inputs().Index(i).Header());
// Sets the output stream of index i header to be the same as
// the header for the input stream of index i
}
}
return absl::OkStatus();
}
absl::Status Process(CalculatorContext* cc) final {
// Store input signals.
for (int i = 0; i < tick_signal_index_; ++i) {
if (!cc->Inputs().Index(i).Value().IsEmpty()) {
current_[i] = cc->Inputs().Index(i).Value();
}
}
// Output if the tick signal is non-empty.
if (!cc->Inputs().Index(tick_signal_index_).Value().IsEmpty()) {
for (int i = 0; i < tick_signal_index_; ++i) {
if (!current_[i].IsEmpty()) {
cc->Outputs().Index(i).AddPacket(
current_[i].At(cc->InputTimestamp()));
// Add a packet to output stream of index i a packet from inputstream i
// with timestamp common to all present inputs
} else {
cc->Outputs().Index(i).SetNextTimestampBound(
cc->InputTimestamp().NextAllowedInStream());
// if current_[i], 1 packet buffer for input stream i is empty, we will set
// next allowed timestamp for input stream i to be current timestamp + 1
}
}
}
return absl::OkStatus();
}
private:
std::vector<Packet> current_;
int tick_signal_index_;
};
REGISTER_CALCULATOR(PacketClonerCalculator);
} // namespace mediapipe
In genere, una calcolatrice ha solo un file .cc. Non è necessario il file .h perché mediapipe utilizza la registrazione per rendere noti i calcolatori. Dopo aver ottenuto definita la classe Calcolatrice, registrala con una chiamata macro REGISTER_CALCULATOR(calculator_class_name).
Di seguito è riportato un semplice grafico MediaPipe con 3 flussi di input, 1 nodo (PacketClonerCalculator) e due flussi di output.
input_stream: "room_mic_signal"
input_stream: "room_lighting_sensor"
input_stream: "room_video_tick_signal"
node {
calculator: "PacketClonerCalculator"
input_stream: "room_mic_signal"
input_stream: "room_lighting_sensor"
input_stream: "room_video_tick_signal"
output_stream: "cloned_room_mic_signal"
output_stream: "cloned_lighting_sensor"
}
Il diagramma seguente mostra come PacketClonerCalculator definisce il suo output
pacchetti (in basso) in base alla serie di pacchetti di input (in alto).
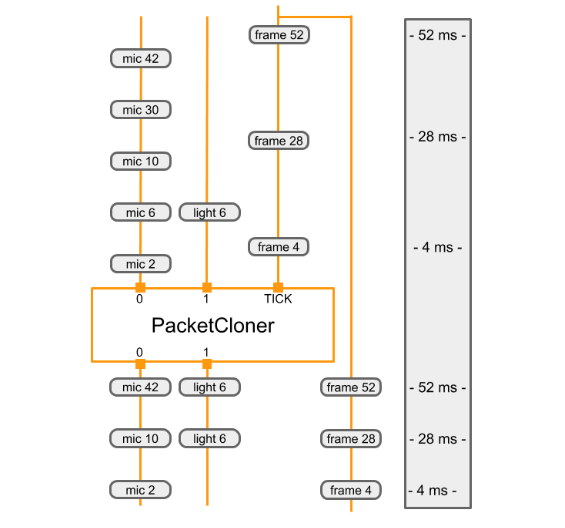 |
|---|
| Ogni volta che riceve un pacchetto nel suo flusso di input TICK, il PacketClonerCalculator emette il pacchetto più recente da ciascuno dei suoi flussi di input. La sequenza dei pacchetti di output (in basso) è determinata dalla sequenza dei pacchetti di input (in alto) e dai relativi timestamp. I timestamp sono mostrati sul lato destro del diagramma. |