
Gemma 3
Ensemble de modèles ouverts, légers et de pointe conçus à partir des mêmes recherches et technologies que celles qui sous-tendent nos modèles Gemini 2.0

Gérer des tâches complexes
La fenêtre de contexte de 128 000 jetons de Gemma 3 permet à vos applications de traiter et d'interpréter d'énormes quantités d'informations, ce qui offre des fonctionnalités d'IA plus sophistiquées.

Développez votre activité à l'international, instantanément
Communiquez facilement dans plusieurs langues grâce aux capacités multilingues inégalées de Gemma 3. Développez des applications qui touchent une audience mondiale, avec la prise en charge de plus de 140 langues.

Comprendre les mots et les images
Créez facilement des applications qui analysent des images, du texte et des vidéos, ce qui ouvre de nouvelles possibilités pour les applications interactives et intelligentes.
Créer avec le meilleur modèle à accélérateur unique au monde


Commencer à créer avec Gemma




Faire avancer la recherche avec Gemma
Découvrez une collection croissante de modèles Gemma spécialisés pour la recherche avancée.


ShieldGemma 2 nouveau
PaliGemma 2 Nouveau
Champ d'application de Gemma
Visualiser les benchmarks Gemma 3
Interagissez avec le graphique pour afficher les résultats de Gemma 3 sur une gamme de benchmarks de LLM.
MMLU-Pro
Le benchmark MMLU (Massive Multitask Language Understanding) mesure l'étendue des connaissances et les capacités de résolution de problèmes acquises par les grands modèles de langage lors du pré-entraînement.
LiveCodeBench
Évalue les capacités de génération de code sur des problèmes de codage concrets provenant de plates-formes telles que LeetCode et Codeforces.
dev
Bird-SQL
Teste la capacité d'un modèle à traduire des questions en langage naturel en requêtes SQL complexes dans différents domaines.
Diamant GPQA
Défiez les modèles avec des questions difficiles rédigées par des docteurs en biologie, physique et chimie.
SimpleQA
Évalue la capacité d'un modèle à répondre à des questions factuelles simples par de courtes phrases.
FACTS Grounding
Évalue si les réponses du LLM sont factuellement exactes et suffisamment détaillées, en fonction des documents d'entrée donnés.
MATH
MATH évalue la capacité d'un modèle de langage à résoudre des problèmes mathématiques complexes, qui nécessitent du raisonnement, la résolution de problèmes en plusieurs étapes et la compréhension de concepts mathématiques.
HiddenMath
Ensemble interne de problèmes mathématiques de compétition.
val
MMMU
Évalue la compréhension et le raisonnement multimodal dans différentes disciplines nécessitant des connaissances de niveau universitaire.
100 %
75 %
50 %
25 %
0 %
100 %
75 %
50 %
25 %
0 %
*Pour en savoir plus sur les performances avec d'autres méthodes, consultez le rapport technique. Lire le rapport technique

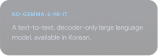

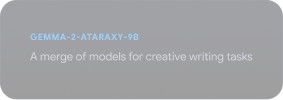
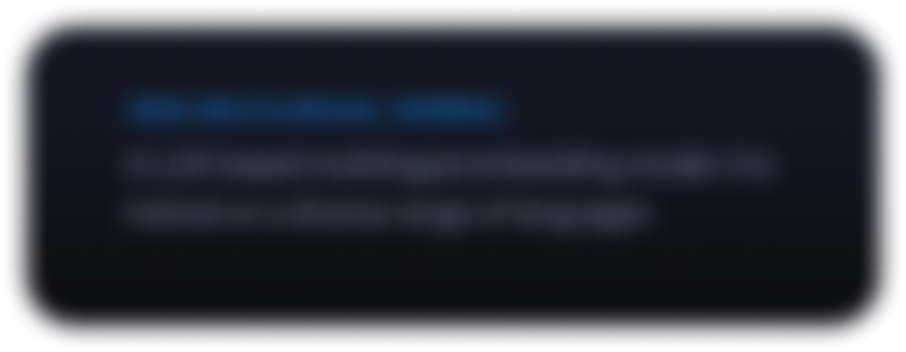
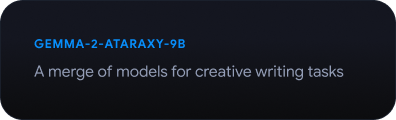

Explorer le Gemmaverse
Un vaste écosystème de modèles et d'outils Gemma créés par la communauté, prêts à alimenter et à inspirer votre innovation
Choisir votre cible de déploiement
![]() Mobile
Mobile
Déployer sur l'appareil avec Google AI Edge
Déployez directement sur les appareils pour bénéficier d'une fonctionnalité hors connexion à faible latence. Idéal pour les applications nécessitant une réactivité et une confidentialité en temps réel, telles que les applications mobiles, les appareils IoT et les systèmes embarqués.
![]() Web
Web
Intégration parfaite aux applications Web
Donnez à vos sites Web et services Web les moyens de proposer des fonctionnalités interactives, du contenu personnalisé et une automatisation intelligente grâce aux fonctionnalités avancées d'IA.
![]() Cloud
Cloud
Évoluez sans effort avec une infrastructure cloud
Exploitez l'évolutivité et la flexibilité du cloud pour gérer les déploiements à grande échelle, les charges de travail exigeantes et les applications d'IA complexes.
Accélérer la recherche universitaire grâce à des crédits Google Cloud
Faites progresser vos recherches avec les modèles Gemma 3 dans Google Cloud. Demandez dès aujourd'hui des crédits Google Cloud pour repousser les limites de vos recherches et contribuer au progrès de la communauté scientifique.
Des chercheurs sélectionnés recevront des crédits Google Cloud pour accélérer leurs travaux scientifiques
S'inscrire