
Atender las consultas de los clientes, incluidos los correos electrónicos, es una parte necesaria de la administración de muchas empresas, pero puede resultar abrumador rápidamente. Con un poco de esfuerzo, los modelos de inteligencia artificial (IA) como Gemma pueden ayudar a facilitar este trabajo.
Cada empresa maneja las consultas, como los correos electrónicos, de una manera un poco diferente, por lo que es importante poder adaptar tecnologías como la IA generativa a las necesidades de tu empresa. Este proyecto aborda el problema específico de extraer información de pedidos de correos electrónicos a una panadería y convertirla en datos estructurados para que se pueda agregar rápidamente a un sistema de procesamiento de pedidos. Con 10 a 20 ejemplos de consultas y el resultado que deseas, puedes ajustar un modelo de Gemma para procesar los correos electrónicos de tus clientes, ayudarte a responder rápidamente y realizar la integración con tus sistemas comerciales existentes. Este proyecto se creó como un patrón de aplicación de IA que puedes extender y adaptar para obtener valor de los modelos de Gemma para tu empresa.
Para obtener una descripción general en video del proyecto y cómo extenderlo, incluidas las estadísticas de las personas que lo crearon, consulta el video de Asistente de IA para correos electrónicos empresariales de Build with Google AI. También puedes revisar el código de este proyecto en el repositorio de código de Gemma Cookbook. De lo contrario, puedes comenzar a extender el proyecto con las siguientes instrucciones.
Descripción general
En este instructivo, se explica cómo configurar, ejecutar y extender una aplicación de asistente de correo electrónico empresarial creada con Gemma, Python y Flask. El proyecto proporciona una interfaz de usuario web básica que puedes modificar para que se ajuste a tus necesidades. La aplicación está diseñada para extraer datos de los correos electrónicos de los clientes y estructurarlos para una panadería ficticia. Puedes usar este patrón de aplicación para cualquier tarea comercial que use entrada y salida de texto.
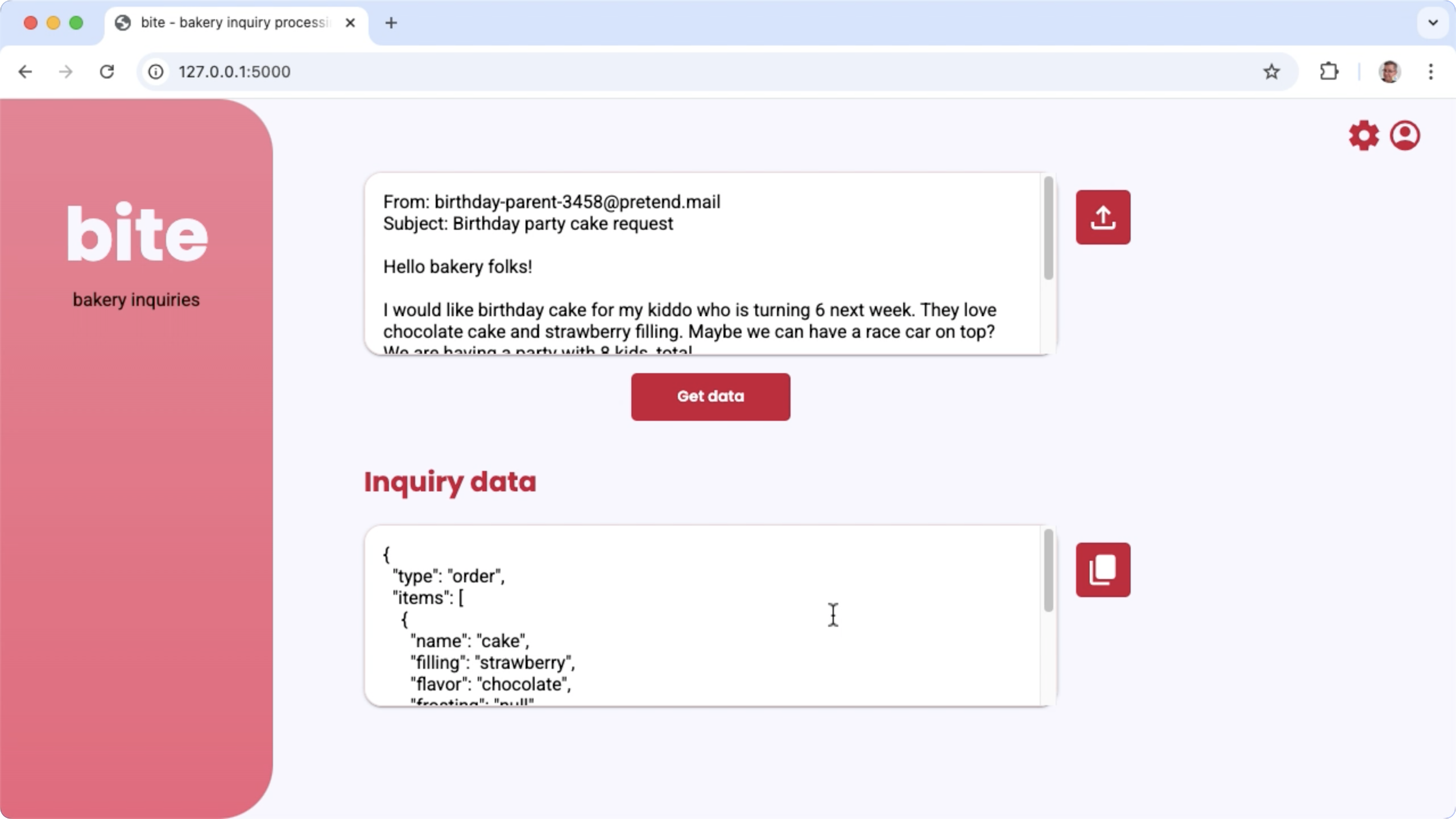
Figura 1: Interfaz de usuario del proyecto para procesar consultas por correo electrónico de la panadería
Requisitos de hardware
Ejecuta este proceso de ajuste en una computadora con una unidad de procesamiento gráfico (GPU) o una unidad de procesamiento tensorial (TPU), y con suficiente memoria de GPU o TPU para contener el modelo existente, además de los datos de ajuste. Para ejecutar la configuración de ajuste en este proyecto, necesitas alrededor de 16 GB de memoria de GPU, aproximadamente la misma cantidad de RAM normal y un mínimo de 50 GB de espacio en disco.
Puedes ejecutar la parte de ajuste del modelo de Gemma de este instructivo con un entorno de Colab con un tiempo de ejecución de GPU T4. Si compilas este proyecto en una instancia de VM de Google Cloud, configura la instancia según estos requisitos:
- Hardware de GPU: Se requiere una GPU NVIDIA T4 para ejecutar este proyecto (se recomienda NVIDIA L4 o superior).
- Sistema operativo: Elige una opción de Aprendizaje profundo en Linux, específicamente VM de aprendizaje profundo con CUDA 12.3 M124 con controladores de software de GPU preinstalados.
- Tamaño del disco de arranque: Asigna al menos 50 GB de espacio en disco para tus datos, modelos y software complementario.
Configura el proyecto
Estas instrucciones te guiarán para preparar este proyecto para el desarrollo y las pruebas. Los pasos generales de configuración incluyen la instalación del software previo, la clonación del proyecto desde el repositorio de código, la configuración de algunas variables de entorno, la instalación de bibliotecas de Python y la prueba de la aplicación web.
Instalación y configuración
Este proyecto usa Python 3 y entornos virtuales (venv) para administrar paquetes y ejecutar la aplicación. Las siguientes instrucciones de instalación son para una máquina host de Linux.
Para instalar el software necesario, sigue estos pasos:
Instala Python 3 y el paquete de entorno virtual
venvpara Python:sudo apt update sudo apt install git pip python3-venv
Clona el proyecto
Descarga el código del proyecto en tu computadora de desarrollo. Necesitas el software de control de código fuente git para recuperar el código fuente del proyecto.
Para descargar el código del proyecto, sigue estos pasos:
Clona el repositorio de Git con el siguiente comando:
git clone https://github.com/google-gemini/gemma-cookbook.gitDe manera opcional, configura tu repositorio de Git local para que use la extracción dispersa, de modo que solo tengas los archivos del proyecto:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
Instala bibliotecas de Python
Instala las bibliotecas de Python con el entorno virtual de Python venv activado para administrar los paquetes y las dependencias de Python. Asegúrate de activar el entorno virtual de Python antes de instalar las bibliotecas de Python con el instalador de pip. Para obtener más información sobre el uso de entornos virtuales de Python, consulta la documentación de venv de Python.
Para instalar las bibliotecas de Python, haz lo siguiente:
En una ventana de la terminal, navega al directorio
business-email-assistant:cd Demos/business-email-assistant/Configura y activa el entorno virtual de Python (venv) para este proyecto:
python3 -m venv venv source venv/bin/activateInstala las bibliotecas de Python necesarias para este proyecto con la secuencia de comandos
setup_python:./setup_python.sh
Configura las variables de entorno
Este proyecto requiere algunas variables de entorno para ejecutarse, incluido un nombre de usuario y un token de la API de Kaggle. Debes tener una cuenta de Kaggle y solicitar acceso a los modelos de Gemma para poder descargarlos. Para este proyecto, agregarás tu nombre de usuario de Kaggle y tu token de la API de Kaggle a dos archivos .env, que leerán la aplicación web y el programa de ajuste, respectivamente.
Para configurar las variables de entorno, haz lo siguiente:
- Para obtener tu nombre de usuario y clave de token de Kaggle, sigue las instrucciones que se indican en la documentación de Kaggle.
- Sigue las instrucciones de Cómo obtener acceso a Gemma en la página Configuración de Gemma para acceder al modelo de Gemma.
- Crea archivos de variables de entorno para el proyecto. Para ello, crea un archivo de texto
.enven cada una de estas ubicaciones en tu clon del proyecto:email-processing-webapp/.env model-tuning/.env
Después de crear los archivos de texto
.env, agrega los siguientes parámetros de configuración a ambos archivos:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
Ejecuta y prueba la aplicación
Una vez que hayas completado la instalación y la configuración del proyecto, ejecuta la aplicación web para confirmar que la configuraste correctamente. Debes hacer esto como una verificación básica antes de editar el proyecto para tu propio uso.
Para ejecutar y probar el proyecto, haz lo siguiente:
En una ventana de la terminal, navega al directorio
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Ejecuta la aplicación con la secuencia de comandos
run_app:./run_app.shDespués de iniciar la aplicación web, el código del programa muestra una URL en la que puedes navegar y realizar pruebas. Por lo general, esta dirección es la siguiente:
http://127.0.0.1:5000/En la interfaz web, presiona el botón Obtener datos debajo del primer campo de entrada para generar una respuesta del modelo.
La primera respuesta del modelo después de ejecutar la aplicación tarda más, ya que debe completar los pasos de inicialización en la primera ejecución de generación. Las solicitudes y la generación de instrucciones posteriores en una aplicación web que ya se está ejecutando se completan en menos tiempo.
Extiende la aplicación
Una vez que la aplicación esté en funcionamiento, puedes extenderla modificando la interfaz de usuario y la lógica empresarial para que funcione con las tareas que son relevantes para ti o tu empresa. También puedes modificar el comportamiento del modelo de Gemma con el código de la aplicación. Para ello, cambia los componentes de la instrucción que la app envía al modelo de IA generativa.
La aplicación proporciona instrucciones al modelo junto con los datos de entrada del usuario, lo que genera una instrucción completa del modelo. Puedes modificar estas instrucciones para cambiar el comportamiento del modelo, por ejemplo, especificar los nombres de los parámetros y la estructura del JSON que se generará. Una forma más sencilla de cambiar el comportamiento del modelo es proporcionarle instrucciones o indicaciones adicionales para su respuesta, como especificar que las respuestas generadas no deben incluir ningún formato de Markdown.
Para modificar las instrucciones de la instrucción, haz lo siguiente:
- En el proyecto de desarrollo, abre el archivo de código
business-email-assistant/email-processing-webapp/app.py. En el código
app.py, agrega instrucciones de adición a la funciónget_prompt()::def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
En este ejemplo, se agrega la frase "sin formato de Markdown adicional" a las instrucciones.
Proporcionar instrucciones adicionales en la instrucción puede influir mucho en el resultado generado y requiere mucho menos esfuerzo para implementarse. Primero, debes probar este método para ver si puedes obtener el comportamiento que deseas del modelo. Sin embargo, el uso de instrucciones en la instrucción para modificar el comportamiento de un modelo de Gemma tiene sus límites. En particular, el límite general de tokens de entrada del modelo, que es de 8,192 tokens para Gemma 2, requiere que equilibres las instrucciones detalladas de la instrucción con el tamaño de los datos nuevos que proporcionas para que no superes ese límite.
Ajusta el modelo
Se recomienda ajustar un modelo de Gemma para que responda de manera más confiable a tareas específicas. En particular, si deseas que el modelo genere JSON con una estructura específica, incluidos parámetros con nombres específicos, debes considerar ajustar el modelo para ese comportamiento. Según la tarea que quieras que complete el modelo, puedes lograr una funcionalidad básica con entre 10 y 20 ejemplos. En esta sección del instructivo, se explica cómo configurar y ejecutar el ajuste de un modelo de Gemma para una tarea específica.
En las siguientes instrucciones, se explica cómo realizar la operación de ajuste en un entorno de VM. Sin embargo, también puedes realizar esta operación de ajuste con el notebook de Colab asociado a este proyecto.
Requisitos de hardware
Los requisitos de procesamiento para el ajuste son los mismos que los requisitos de hardware para el resto del proyecto. Puedes ejecutar la operación de ajuste en un entorno de Colab con un tiempo de ejecución de GPU T4 si limitas los tokens de entrada a 256 y el tamaño del lote a 1.
Preparar los datos
Antes de comenzar a ajustar un modelo de Gemma, debes preparar los datos para el ajuste. Cuando ajustas un modelo para una tarea específica, necesitas un conjunto de ejemplos de solicitudes y respuestas. Estos ejemplos deben mostrar el texto de la solicitud, sin ninguna instrucción, y el texto de la respuesta esperada. Para comenzar, debes preparar un conjunto de datos con alrededor de 10 ejemplos. Estos ejemplos deben representar una variedad completa de solicitudes y las respuestas ideales. Asegúrate de que las solicitudes y las respuestas no sean repetitivas, ya que esto puede hacer que las respuestas de los modelos sean repetitivas y no se ajusten de manera adecuada a las variaciones en las solicitudes. Si ajustas el modelo para que produzca un formato de datos estructurados, asegúrate de que todas las respuestas proporcionadas se ajusten estrictamente al formato de salida de datos que deseas. En la siguiente tabla, se muestran algunos registros de muestra del conjunto de datos de este ejemplo de código:
| Solicitud | Respuesta |
|---|---|
| Hola, Indian Bakery Central:\n¿Tienes 10 pendas y treinta bundi ladoos a mano? También venden glaseado de vainilla y pasteles con sabor a chocolate. Busco un tamaño de 6 pulgadas. | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| Vi tu empresa en Google Maps. ¿Venden jellabi y gulab jamun? | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
Tabla 1: Es una lista parcial del conjunto de datos de ajuste del extractor de datos de correos electrónicos de panadería.
Formato y carga de datos
Puedes almacenar tus datos de ajuste en cualquier formato que te resulte conveniente, incluidos registros de bases de datos, archivos JSON, CSV o archivos de texto sin formato, siempre y cuando tengas los medios para recuperar los registros con código de Python. Este proyecto lee archivos JSON de un directorio data en un array de objetos de diccionario.
En este programa de ajuste de ejemplo, el conjunto de datos de ajuste se carga en el módulo model-tuning/main.py con la función prepare_tuning_dataset():
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
Como se mencionó anteriormente, puedes almacenar el conjunto de datos en un formato conveniente, siempre y cuando puedas recuperar las solicitudes con las respuestas asociadas y ensamblarlas en una cadena de texto que se use como registro de ajuste.
Cómo ensamblar registros de ajuste
Para el proceso de ajuste real, el programa ensambla cada solicitud y respuesta en una sola cadena con las instrucciones de la instrucción y el contenido de la respuesta. Luego, el programa de ajuste tokeniza la cadena para que el modelo la consuma. Puedes ver el código para ensamblar un registro de ajuste en la función prepare_tuning_dataset() del módulo model-tuning/main.py, de la siguiente manera:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
Esta función toma los datos como entrada y los formatea agregando un salto de línea entre la instrucción y la respuesta.
Genera pesos del modelo
Una vez que tengas los datos de ajuste cargados, podrás ejecutar el programa de ajuste. El proceso de ajuste de esta aplicación de ejemplo usa la biblioteca de PNL de Keras para ajustar el modelo con una técnica de adaptación de rango bajo, o LoRA, para generar nuevos pesos del modelo. En comparación con el ajuste de precisión completa, el uso de LoRA es mucho más eficiente en cuanto a la memoria porque aproxima los cambios en los pesos del modelo. Luego, puedes superponer estos pesos aproximados sobre los pesos existentes del modelo para cambiar su comportamiento.
Para realizar la ejecución del ajuste y calcular los pesos nuevos, haz lo siguiente:
En una ventana de terminal, navega al directorio
model-tuning/.cd business-email-assistant/model-tuning/Ejecuta el proceso de ajuste con la secuencia de comandos
tune_model:./tune_model.sh
El proceso de ajuste tarda varios minutos, según los recursos de procesamiento disponibles. Cuando se completa correctamente, el programa de ajuste escribe nuevos archivos de pesos *.h5 en el directorio model-tuning/weights con el siguiente formato:
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
Solución de problemas
Si el ajuste no se completa correctamente, es posible que se deba a uno de los dos motivos siguientes:
- Sin memoria o recursos agotados: Estos errores se producen cuando el proceso de ajuste solicita memoria que supera la memoria de GPU o la memoria de CPU disponibles. Asegúrate de no ejecutar la aplicación web mientras se ejecuta el proceso de ajuste. Si realizas ajustes en un dispositivo con 16 GB de memoria de GPU, asegúrate de que
token_limitesté configurado en 256 ybatch_sizeen 1. - Los controladores de GPU no están instalados o no son compatibles con JAX: El proceso de ajuste requiere que el dispositivo de procesamiento tenga instalados controladores de hardware que sean compatibles con la versión de las bibliotecas de JAX. Para obtener más detalles, consulta la documentación de instalación de JAX.
Implementa el modelo ajustado
El proceso de ajuste genera varios pesos según los datos de ajuste y la cantidad total de épocas establecidas en la aplicación de ajuste. De forma predeterminada, el programa de ajuste genera 3 archivos de pesos del modelo, uno para cada época de ajuste. Cada época de ajuste sucesiva produce pesos que reproducen con mayor precisión los resultados de los datos de ajuste. Puedes ver las tasas de exactitud para cada época en el resultado de la terminal del proceso de ajuste, como se muestra a continuación:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
Si bien deseas que la tasa de precisión sea relativamente alta, alrededor de 0.80, no quieres que sea demasiado alta ni muy cercana a 1.00, ya que eso significa que los pesos se acercaron al sobreajuste de los datos de ajuste. Cuando eso sucede, el modelo no funciona bien en las solicitudes que son significativamente diferentes de los ejemplos de ajuste. De forma predeterminada, la secuencia de comandos de implementación elige los pesos de la época 3, que suelen tener una tasa de precisión de alrededor del 0.80.
Para implementar los pesos generados en la aplicación web, haz lo siguiente:
En una ventana de la terminal, navega al directorio
model-tuning:cd business-email-assistant/model-tuning/Ejecuta el proceso de ajuste con la secuencia de comandos
deploy_weights:./deploy_weights.sh
Después de ejecutar esta secuencia de comandos, deberías ver un nuevo archivo *.h5 en el directorio email-processing-webapp/weights/.
Prueba el modelo nuevo
Una vez que hayas implementado los nuevos pesos en la aplicación, es hora de probar el modelo recién ajustado. Para ello, vuelve a ejecutar la aplicación web y genera una respuesta.
Para ejecutar y probar el proyecto, haz lo siguiente:
En una ventana de la terminal, navega al directorio
email-processing-webapp:cd business-email-assistant/email-processing-webapp/Ejecuta la aplicación con la secuencia de comandos
run_app:./run_app.shDespués de iniciar la aplicación web, el código del programa muestra una URL en la que puedes navegar y realizar pruebas. Por lo general, esta dirección es la siguiente:
http://127.0.0.1:5000/En la interfaz web, presiona el botón Obtener datos debajo del primer campo de entrada para generar una respuesta del modelo.
Ahora ajustaste y, luego, implementaste un modelo de Gemma en una aplicación. Experimenta con la aplicación y trata de determinar los límites de la capacidad de generación del modelo ajustado para tu tarea. Si encuentras situaciones en las que el modelo no funciona bien, considera agregar algunas de esas solicitudes a tu lista de datos de ejemplo de ajuste agregando la solicitud y proporcionando una respuesta ideal. Luego, vuelve a ejecutar el proceso de ajuste, vuelve a implementar los pesos nuevos y prueba el resultado.
Recursos adicionales
Para obtener más información sobre este proyecto, consulta el repositorio de código de Gemma Cookbook. Si necesitas ayuda para compilar la aplicación o quieres colaborar con otros desarrolladores, consulta el servidor de Discord de la comunidad de desarrolladores de Google. Para obtener más información sobre los proyectos de Build with Google AI, consulta la playlist de videos.