
Página del modelo: CodeGemma
Recursos y documentación técnica:
Condiciones de Uso: Términos
Autores: Google
Información del modelo
Resumen del modelo
Descripción
CodeGemma es una familia de modelos de código abierto ligeros compilados sobre Gemma. Los modelos de CodeGemma son modelos solo de decodificador de texto a texto y de texto a código, y están disponibles como una variante preentrenada de 7,000 millones que se especializa en tareas de finalización y generación de código, una variante ajustada a instrucciones de 7,000 millones de parámetros para chat de código y seguimiento de instrucciones, y una variante preentrenada de 2,000 millones de parámetros para una finalización de código rápida.
Entradas y salidas
Entrada: Para las variantes de modelos previamente entrenados: prefijo de código y, de manera opcional, sufijo para situaciones de finalización y generación de código, o texto o instrucción de lenguaje natural. Para la variante del modelo ajustado a las instrucciones: texto o instrucción en lenguaje natural.
Resultado: Para las variantes de modelos previamente entrenados: finalización de código con espacios en blanco, código y lenguaje natural. Para la variante de modelo ajustado a instrucciones: código y lenguaje natural.
Cita
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
Datos del modelo
Conjunto de datos de entrenamiento
Con Gemma como modelo base, las variantes preentrenadas de CodeGemma 2B y 7B se entrenan más en 500,000 a 1,000,000 millones de tokens adicionales de datos principalmente en inglés de conjuntos de datos matemáticos de código abierto y código generado de forma sintética.
Procesamiento de datos de entrenamiento
Se aplicaron las siguientes técnicas de procesamiento previo de datos para entrenar CodeGemma:
- FIM: Los modelos de CodeGemma previamente entrenados se enfocan en tareas de completar el medio (FIM). Los modelos se entrenan para funcionar con los modos PSM y SPM. Nuestra configuración de FIM es de una tasa de FIM del 80% al 90% con PSM/SPM de 50-50.
- Técnicas de empaquetado léxico basado en el grafo de dependencias y pruebas de unidades: Para mejorar la alineación del modelo con las aplicaciones del mundo real, estructuramos ejemplos de entrenamiento a nivel del proyecto o repositorio para colocar los archivos de origen más relevantes dentro de cada repositorio. Específicamente, empleamos dos técnicas heurísticas: empaquetado basado en el gráfico de dependencias y empaquetado léxico basado en pruebas de unidades.
- Desarrollamos una técnica novedosa para dividir los documentos en prefijo, medio y sufijo para que el sufijo comience en un punto más natural sintácticamente en lugar de una distribución puramente aleatoria.
- Seguridad: Al igual que Gemma, implementamos filtros de seguridad rigurosos, incluidos los de datos personales, CSAM y otros basados en la calidad y seguridad del contenido, de acuerdo con nuestras políticas.
Información de implementación
Hardware y frameworks que se usan durante el entrenamiento
Al igual que Gemma, CodeGemma se entrenó en la generación más reciente de hardware de unidad de procesamiento tensorial (TPU) (TPUv5e), con JAX y rutas de acceso de AA.
Información de la evaluación
Resultados de comparativas
Enfoque de evaluación
- Comparativas de finalización de código: HumanEval (HE) (completado de una y varias líneas)
- Comparativas de generación de código: HumanEval, MBPP, BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
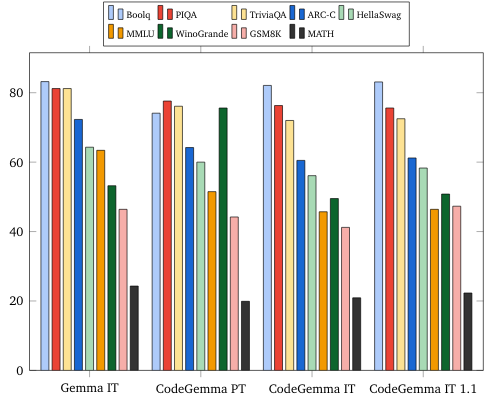
- Preguntas y respuestas: BoolQ, PIQA, TriviaQA
- Lenguaje natural: ARC-Challenge, HellaSwag, MMLU, WinoGrande
- Razonamiento matemático: GSM8K, MATH
Resultados de las comparativas de codificación
| Comparativa | 2,000 M | 2,000 millones (1.1) | 7B | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37.8 | 44.5 | 56.1 | 60.4 |
| MBPP | 43.6 | 49.2 | 56.2 | 54.2 | 55.6 |
| HumanEval de una sola línea | 78.4 | 79.3 | 76.1 | 68.3 | 77.4 |
| HumanEval de varias líneas | 51.4 | 51.0 | 58.4 | 20.1 | 23.7 |
| BC HE C++ | 24.2 | 19.9 | 32.9 | 42.2 | 46.6 |
| BC HE C# | 10.6 | 26.1 | 22,4 | 26.7 | 54.7 |
| BC HE Go | 20.5 | 18.0 | 21.7 | 28.6 | 34.2 |
| BC HE Java | 29.2 | 29.8 | 41.0 | 48.4 | 50.3 |
| JavaScript de BC HE | 21.7 | 28.0 | 39.8 | 46.0 | 48.4 |
| BC HE Kotlin | 28.0 | 32.3 | 39.8 | 51.6 | 47.8 |
| BC HE Python | 21.7 | 36.6 | 42.2 | 48.4 | 54.0 |
| BC HE Rust | 26.7 | 24.2 | 34.1 | 36.0 | 37.3 |
| BC MBPP C++ | 47.1 | 38.9 | 53.8 | 56.7 | 63.5 |
| BC MBPP C# | 28.7 | 45.3 | 32.5 | 41.2 | 62.0 |
| BC MBPP Go | 45.6 | 38.9 | 43.3 | 46.2 | 53.2 |
| Java de BC MBPP | 41.8 | 49.7 | 50.3 | 57.3 | 62.9 |
| JavaScript de BC MBPP | 45.3 | 45.0 | 58.2 | 61.4 | 61.4 |
| BC MBPP Kotlin | 46.8 | 49.7 | 54.7 | 59.9 | 62.6 |
| BC MBPP Python | 38.6 | 52.9 | 59.1 | 62.0 | 60.2 |
| BC MBPP Rust | 45.3 | 47.4 | 52.9 | 53.5 | 52.3 |
Comparativas de lenguaje natural (en modelos de 7,000 millones)
Ética y seguridad
Evaluaciones de ética y seguridad
Enfoque de las evaluaciones
Nuestros métodos de evaluación incluyen evaluaciones estructuradas y pruebas internas de equipo rojo de las políticas de contenido relevantes. Varios equipos diferentes realizaron el equipo rojo, cada uno con diferentes objetivos y métricas de evaluación humana. Estos modelos se evaluaron en función de varias categorías relevantes para la ética y la seguridad, como las siguientes:
Evaluación humana de instrucciones sobre la seguridad del contenido y los daños de representación Consulta la tarjeta de modelo de Gemma para obtener más detalles sobre el enfoque de evaluación.
Pruebas específicas de las capacidades de ciberdelincuencia, que se enfocan en probar las capacidades de hackeo autónomo y garantizar que los posibles daños sean limitados.
Resultados de la evaluación
Los resultados de las evaluaciones de ética y seguridad están dentro de los umbrales aceptables para cumplir con las políticas internas de categorías como seguridad infantil, seguridad del contenido, daños de representación, memorización y daños a gran escala. Consulta la tarjeta de modelo de Gemma para obtener más detalles.
Uso y limitaciones del modelo
Limitaciones conocidas
Los modelos de lenguaje grandes (LLM) tienen limitaciones basadas en sus datos de entrenamiento y las limitaciones inherentes de la tecnología. Consulta la tarjeta de modelo de Gemma para obtener más detalles sobre las limitaciones de los LLM.
Consideraciones y riesgos éticos
El desarrollo de modelos grandes de lenguaje (LLM) plantea varias inquietudes éticas. Consideramos cuidadosamente varios aspectos en el desarrollo de estos modelos.
Consulta la misma explicación en la tarjeta de modelo de Gemma para obtener detalles.
Uso previsto
Aplicación
Los modelos de Code Gemma tienen una amplia variedad de aplicaciones, que varían entre los modelos de TI y PT. La siguiente lista de usos potenciales no es exhaustiva. El objetivo de esta lista es proporcionar información contextual sobre los posibles casos de uso que los creadores del modelo consideraron como parte del entrenamiento y desarrollo del modelo.
- Finalización de código: Los modelos de PT se pueden usar para completar código con una extensión de IDE.
- Generación de código: El modelo de TI se puede usar para generar código con o sin una extensión de IDE.
- Conversación de código: El modelo de TI puede potenciar interfaces de conversación que analizan el código.
- Educación en programación: El modelo de TI admite experiencias de aprendizaje de código interactivas, ayuda a corregir la sintaxis o proporciona práctica de programación.
Beneficios
En el momento del lanzamiento, esta familia de modelos proporciona implementaciones de modelos de lenguaje grandes de alto rendimiento centradas en código abierto diseñadas desde cero para el desarrollo de IA responsable en comparación con modelos de tamaño similar.
Con las métricas de evaluación de comparativas de programación que se describen en este documento, estos modelos demostraron proporcionar un rendimiento superior a otras alternativas de modelos abiertos de tamaño similar.