
Halaman model: CodeGemma
Referensi dan dokumentasi teknis:
Persyaratan Penggunaan: Persyaratan
Penulis: Google
Informasi model
Ringkasan model
Deskripsi
CodeGemma adalah sekumpulan model kode terbuka yang ringan dan dibuat berdasarkan Gemma. Model CodeGemma adalah model khusus dekoder teks ke teks dan teks ke kode, serta tersedia sebagai varian terlatih sebanyak 7 miliar yang berspesialisasi dalam tugas penyelesaian kode dan pembuatan kode, varian yang disesuaikan dengan petunjuk parameter sebanyak 7 miliar untuk chat kode dan mengikuti petunjuk, serta varian terlatih parameter sebanyak 2 miliar untuk penyelesaian kode yang cepat.
Input dan output
Input: Untuk varian model terlatih: awalan kode dan opsional akhiran untuk skenario penyelesaian dan pembuatan kode atau teks/perintah bahasa alami. Untuk varian model yang disesuaikan dengan petunjuk: teks atau perintah bahasa alami.
Output: Untuk varian model terlatih: penyelesaian kode mengisi bagian tengah, kode, dan bahasa alami. Untuk varian model yang disesuaikan dengan petunjuk: kode dan bahasa alami.
Pengutipan
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
Model data
Set data pelatihan
Dengan menggunakan Gemma sebagai model dasar, varian pralatihan CodeGemma 2B dan 7B dilatih lebih lanjut pada 500 hingga 1.000 miliar token tambahan yang sebagian besar merupakan data bahasa Inggris dari set data matematika open source dan kode yang dibuat secara sintetis.
Pemrosesan data pelatihan
Teknik prapemrosesan data berikut diterapkan untuk melatih CodeGemma:
- FIM - Model CodeGemma terlatih berfokus pada tugas fill-in-the-middle (FIM). Model dilatih agar berfungsi dengan mode PSM dan SPM. Setelan FIM kami adalah rasio FIM 80% hingga 90% dengan PSM/SPM 50-50.
- Teknik Packing Berbasis Grafik Dependensi dan Packing Leksikal Berbasis Pengujian Unit: Untuk meningkatkan penyelarasan model dengan aplikasi dunia nyata, kami menyusun contoh pelatihan di tingkat project/repositori untuk menempatkan bersama file sumber yang paling relevan dalam setiap repositori. Secara khusus, kami menggunakan dua teknik heuristic: pengepakan berbasis grafik dependensi dan pengepakan leksikalis berbasis pengujian unit.
- Kami mengembangkan teknik baru untuk membagi dokumen menjadi awalan, tengah, dan akhiran agar akhiran dimulai pada titik yang lebih alami secara sintaksis, bukan distribusi yang sepenuhnya acak.
- Keamanan: Serupa dengan Gemma, kami menerapkan pemfilteran keamanan yang ketat, termasuk pemfilteran data pribadi, pemfilteran CSAM, dan pemfilteran lainnya berdasarkan kualitas dan keamanan konten sesuai dengan kebijakan kami.
Informasi penerapan
Hardware dan framework yang digunakan selama pelatihan
Seperti Gemma, CodeGemma dilatih pada hardware Tensor Processing Unit (TPU) generasi terbaru (TPUv5e), menggunakan JAX dan ML Pathways.
Informasi evaluasi
Hasil benchmark
Pendekatan evaluasi
- Benchmark penyelesaian kode: HumanEval (HE) (Pengisian Baris Tunggal dan Multibaris)
- Benchmark pembuatan kode: HumanEval, MBPP, BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
- Tanya Jawab: BoolQ, PIQA, TriviaQA
- Natural Language: ARC-Challenge, HellaSwag, MMLU, WinoGrande
- Penalaran Matematika: GSM8K, MATH
Hasil benchmark coding
| Benchmark | 2 M | 2B (1.1) | 7B | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37,8 | 44,5 | 56,1 | 60,4 |
| MBPP | 43,6 | 49,2 | 56,2 | 54,2 | 55,6 |
| Baris Tunggal HumanEval | 78,4 | 79,3 | 76,1 | 68,3 | 77,4 |
| HumanEval Multi Line | 51,4 | 51,0 | 58,4 | 20.1 | 23,7 |
| BC HE C++ | 24,2 | 19,9 | 32,9 | 42,2 | 46,6 |
| BC HE C# | 10.6 | 26,1 | 22,4 | 26,7 | 54,7 |
| BC HE Go | 20,5 | 18,0 | 21,7 | 28,6 | 34,2 |
| BC HE Java | 29,2 | 29,8 | 41,0 | 48,4 | 50,3 |
| JavaScript BC HE | 21,7 | 28,0 | 39,8 | 46,0 | 48,4 |
| BC HE Kotlin | 28,0 | 32.3 | 39,8 | 51,6 | 47,8 |
| BC HE Python | 21,7 | 36,6 | 42,2 | 48,4 | 54,0 |
| BC HE Rust | 26,7 | 24,2 | 34,1 | 36,0 | 37,3 |
| BC MBPP C++ | 47,1 | 38,9 | 53,8 | 56,7 | 63,5 |
| BC MBPP C# | 28,7 | 45,3 | 32,5 | 41,2 | 62,0 |
| BC MBPP Go | 45,6 | 38,9 | 43,3 | 46,2 | 53,2 |
| BC MBPP Java | 41,8 | 49,7 | 50,3 | 57,3 | 62,9 |
| JavaScript BC MBPP | 45,3 | 45,0 | 58.2 | 61,4 | 61,4 |
| BC MBPP Kotlin | 46,8 | 49,7 | 54,7 | 59,9 | 62,6 |
| BC MBPP Python | 38,6 | 52,9 | 59,1 | 62,0 | 60.2 |
| BC MBPP Rust | 45,3 | 47,4 | 52,9 | 53,5 | 52,3 |
Benchmark bahasa alami (pada model 7B)
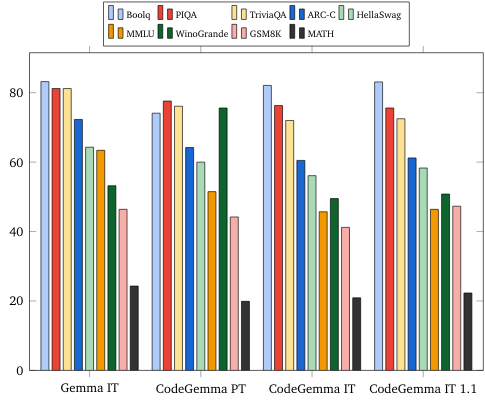
Etika dan keamanan
Evaluasi etika dan keamanan
Pendekatan evaluasi
Metode evaluasi kami mencakup evaluasi terstruktur dan pengujian red team internal terhadap kebijakan konten yang relevan. Tim red-teaming dilakukan oleh sejumlah tim yang berbeda, masing-masing dengan sasaran dan metrik evaluasi manusia yang berbeda. Model ini dievaluasi berdasarkan sejumlah kategori berbeda yang relevan dengan etika dan keamanan, termasuk:
Evaluasi manual pada perintah yang mencakup keamanan konten dan kerugihan representasional. Lihat Kartu model Gemma untuk mengetahui detail selengkapnya tentang pendekatan evaluasi.
Pengujian khusus terhadap kemampuan pelanggaran cyber, yang berfokus pada pengujian kemampuan peretasan otonom dan memastikan potensi bahaya dibatasi.
Hasil evaluasi
Hasil evaluasi etika dan keamanan berada dalam batas yang dapat diterima untuk memenuhi kebijakan internal untuk kategori seperti keselamatan anak, keselamatan konten, bahaya representasi, mengingat, bahaya berskala besar. Lihat kartu model Gemma untuk mengetahui detail selengkapnya.
Penggunaan dan batasan model
Batasan umum
Model Bahasa Besar (LLM) memiliki batasan berdasarkan data pelatihannya dan batasan bawaan teknologi. Lihat kartu model Gemma untuk mengetahui detail selengkapnya tentang batasan LLM.
Pertimbangan dan risiko etis
Pengembangan model bahasa besar (LLM) menimbulkan beberapa masalah etika. Kami telah mempertimbangkan beberapa aspek dengan cermat dalam pengembangan model ini.
Lihat diskusi yang sama di kartu model Gemma untuk mengetahui detail model.
Penggunaan yang dimaksudkan
Aplikasi
Model Gemma kode memiliki berbagai aplikasi, yang bervariasi antara model IT dan PT. Daftar potensi penggunaan berikut tidak lengkap. Tujuan daftar ini adalah untuk memberikan informasi kontekstual tentang kemungkinan kasus penggunaan yang dipertimbangkan pembuat model sebagai bagian dari pelatihan dan pengembangan model.
- Penyelesaian Kode: Model PT dapat digunakan untuk menyelesaikan kode dengan ekstensi IDE
- Pembuatan Kode: Model IT dapat digunakan untuk membuat kode dengan atau tanpa ekstensi IDE
- Percakapan Kode: Model IT dapat mendukung antarmuka percakapan yang membahas kode
- Pendidikan Kode: Model IT mendukung pengalaman belajar kode interaktif, membantu dalam koreksi sintaksis atau memberikan praktik coding
Manfaat
Pada saat rilis, kelompok model ini menyediakan implementasi model bahasa besar berfokus kode terbuka berperforma tinggi yang dirancang dari awal untuk pengembangan Responsible AI dibandingkan dengan model berukuran serupa.
Dengan menggunakan metrik evaluasi benchmark coding yang dijelaskan dalam dokumen ini, model ini telah terbukti memberikan performa yang lebih baik dibandingkan alternatif model terbuka lainnya yang berukuran sebanding.