
หน้าโมเดล: CodeGemma
แหล่งข้อมูลและเอกสารทางเทคนิค:
ข้อกำหนดในการใช้งาน: ข้อกำหนด
ผู้เขียน: Google
ข้อมูลรุ่น
สรุปโมเดล
คำอธิบาย
CodeGemma เป็นกลุ่มโมเดลโค้ดแบบเปิดที่มีน้ำหนักเบาซึ่งสร้างขึ้นจาก Gemma โมเดล CodeGemma เป็นโมเดลเฉพาะตัวแปลงข้อความเป็นข้อความและข้อความเป็นโค้ด และพร้อมใช้งานในรูปแบบตัวแปรที่ผ่านการฝึกล่วงหน้า 7 พันล้านรายการซึ่งเชี่ยวชาญในงานเติมโค้ดและการสร้างโค้ด ตัวแปรที่ปรับแต่งคำสั่ง 7 พันล้านรายการสำหรับแชทโค้ดและการปฏิบัติตามคำสั่ง และตัวแปรที่ผ่านการฝึกล่วงหน้า 2 พันล้านรายการสำหรับการเติมโค้ดอย่างรวดเร็ว
อินพุตและเอาต์พุต
อินพุต: สำหรับตัวแปรของโมเดลที่ผ่านการฝึกล่วงหน้า: คำนำหน้าโค้ดและคำต่อท้าย (ไม่บังคับ) สำหรับสถานการณ์การเติมโค้ดและการสร้างโค้ด หรือข้อความ/พรอมต์ที่เป็นภาษาธรรมชาติ สําหรับตัวแปรโมเดลที่ปรับตามวิธีการ: ข้อความหรือพรอมต์ที่เป็นภาษาธรรมชาติ
เอาต์พุต: สำหรับตัวแปรของโมเดลที่ผ่านการฝึกล่วงหน้า: การเติมโค้ดกลางประโยค การเติมโค้ด และภาษาธรรมชาติ สําหรับตัวแปรโมเดลที่ปรับตามวิธีการ ให้ใช้โค้ดและภาษาธรรมชาติ
การอ้างอิง
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
ข้อมูลโมเดล
ชุดข้อมูลการฝึก
เมื่อใช้ Gemma เป็นโมเดลพื้นฐาน ตัวแปร CodeGemma 2B และ 7B ที่ผ่านการฝึกล่วงหน้าจะได้รับการฝึกเพิ่มเติมด้วยข้อมูลภาษาหลักๆ คือภาษาอังกฤษอีก 500-1, 000 พันล้านโทเค็นจากชุดข้อมูลคณิตศาสตร์แบบโอเพนซอร์สและโค้ดที่สร้างขึ้นจากการสังเคราะห์
การประมวลผลข้อมูลการฝึก
เทคนิคการเตรียมข้อมูลเบื้องต้นต่อไปนี้ใช้เพื่อฝึก CodeGemma
- FIM - โมเดล CodeGemma ที่ผ่านการฝึกล่วงหน้าจะมุ่งเน้นที่งานเติมคำกลางประโยค (FIM) โมเดลได้รับการฝึกให้ทำงานได้กับทั้งโหมด PSM และ SPM การตั้งค่า FIM ของเราคืออัตรา FIM 80-90% พร้อม PSM/SPM 50-50
- เทคนิคการจัดแพ็กตามกราฟ Dependency และการจัดแพ็กตามคําศัพท์ตามการทดสอบหน่วย: เราจัดโครงสร้างตัวอย่างการฝึกที่ระดับโปรเจ็กต์/ที่เก็บข้อมูลเพื่อจัดวางไฟล์ต้นฉบับที่เกี่ยวข้องมากที่สุดไว้ด้วยกันภายในที่เก็บข้อมูลแต่ละแห่ง เพื่อปรับปรุงการปรับแนวโมเดลให้สอดคล้องกับการใช้งานจริง โดยเฉพาะอย่างยิ่ง เราใช้เทคนิคการหาค่าประมาณ 2 เทคนิค ได้แก่ การแพ็กตามกราฟความเกี่ยวข้องและการแพ็กตามคลังคำที่ใช้ทดสอบหน่วย
- เราได้พัฒนาเทคนิคใหม่ในการแยกเอกสารออกเป็นส่วนนำหน้า ส่วนกลาง และส่วนต่อท้ายเพื่อให้ส่วนต่อท้ายเริ่มต้นในจุดที่เป็นไปตามหลักไวยากรณ์มากกว่าการกระจายแบบสุ่ม
- ความปลอดภัย: เช่นเดียวกับ Gemma เราได้ติดตั้งใช้งานการกรองเพื่อความปลอดภัยที่เข้มงวด ซึ่งรวมถึงการกรองข้อมูลส่วนบุคคล การกรอง CSAM และการกรองอื่นๆ ตามคุณภาพและความปลอดภัยของเนื้อหา ซึ่งสอดคล้องกับนโยบายของเรา
ข้อมูลการใช้งาน
ฮาร์ดแวร์และเฟรมเวิร์กที่ใช้ระหว่างการฝึกอบรม
เช่นเดียวกับ Gemma CodeGemma ได้รับการฝึกอบรมบนฮาร์ดแวร์ Tensor Processing Unit (TPU) รุ่นล่าสุด (TPUv5e) ใช้ JAX และ ML Pathways
ข้อมูลการประเมิน
ผลลัพธ์การเปรียบเทียบ
แนวทางการประเมิน
- เกณฑ์การเปรียบเทียบการเติมโค้ด: HumanEval (HE) (การเติมโค้ดแบบบรรทัดเดียวและหลายบรรทัด)
- การเปรียบเทียบการสร้างโค้ด: HumanEval, MBPP, BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
- ถามและตอบ: BoolQ, PIQA, TriviaQA
- ภาษาธรรมชาติ: ARC-Challenge, HellaSwag, MMLU, WinoGrande
- เหตุผลเชิงคณิตศาสตร์: GSM8K, MATH
ผลลัพธ์การเปรียบเทียบการเขียนโค้ด
| เปรียบเทียบ | 2 พันล้าน | 2B (1.1) | 7B | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37.8 | 44.5 | 56.1 | 60.4 |
| MBPP | 43.6 | 49.2 | 56.2 | 54.2 | 55.6 |
| HumanEval บรรทัดเดียว | 78.4 | 79.3 | 76.1 | 68.3 | 77.4 |
| HumanEval Multi Line | 51.4 | 51.0 | 58.4 | 20.1 | 23.7 |
| BC HE C++ | 24.2 | 19.9 | 32.9 | 42.2 | 46.6 |
| BC HE C# | 10.6 | 26.1 | 22.4 | 26.7 | 54.7 |
| BC HE Go | 20.5 | 18.0 | 21.7 | 28.6 | 34.2 |
| BC HE Java | 29.2 | 29.8 | 41.0 | 48.4 | 50.3 |
| BC HE JavaScript | 21.7 | 28.0 | 39.8 | 46.0 | 48.4 |
| BC HE Kotlin | 28.0 | 32.3 | 39.8 | 51.6 | 47.8 |
| BC HE Python | 21.7 | 36.6 | 42.2 | 48.4 | 54.0 |
| BC HE Rust | 26.7 | 24.2 | 34.1 | 36.0 | 37.3 |
| BC MBPP C++ | 47.1 | 38.9 | 53.8 | 56.7 | 63.5 |
| BC MBPP C# | 28.7 | 45.3 | 32.5 | 41.2 | 62.0 |
| BC MBPP Go | 45.6 | 38.9 | 43.3 | 46.2 | 53.2 |
| BC MBPP Java | 41.8 | 49.7 | 50.3 | 57.3 | 62.9 |
| BC MBPP JavaScript | 45.3 | 45.0 | 58.2 | 61.4 | 61.4 |
| BC MBPP Kotlin | 46.8 | 49.7 | 54.7 | 59.9 | 62.6 |
| BC MBPP Python | 38.6 | 52.9 | 59.1 | 62.0 | 60.2 |
| BC MBPP Rust | 45.3 | 47.4 | 52.9 | 53.5 | 52.3 |
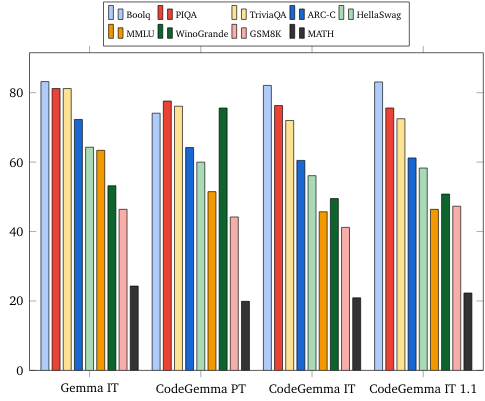
การเปรียบเทียบภาษาธรรมชาติ (ในโมเดล 7B)
จริยธรรมและความปลอดภัย
การประเมินด้านจริยธรรมและความปลอดภัย
แนวทางการประเมิน
วิธีการประเมินของเราประกอบด้วยการประเมินที่มีโครงสร้างและการทดสอบนโยบายเนื้อหาที่เกี่ยวข้องโดยทีมจำลองการโจมตีภายใน ทีมจำลองการโจมตีดำเนินการโดยทีมต่างๆ ซึ่งแต่ละทีมมีเป้าหมายและเมตริกการประเมินของมนุษย์แตกต่างกัน โมเดลเหล่านี้ได้รับการประเมินตามหมวดหมู่ต่างๆ ที่เกี่ยวข้องกับจริยธรรมและความปลอดภัย ซึ่งรวมถึงหมวดหมู่ต่อไปนี้
การประเมินโดยเจ้าหน้าที่เกี่ยวกับพรอมต์ที่เกี่ยวข้องกับความปลอดภัยของเนื้อหาและอันตรายจากการนำเสนอ ดูรายละเอียดเพิ่มเติมเกี่ยวกับแนวทางการประเมินได้ที่การ์ดรูปแบบ Gemma
การทดสอบความสามารถที่เฉพาะเจาะจงในการกระทําความผิดทางไซเบอร์ โดยมุ่งเน้นที่การทดสอบความสามารถในการแฮ็กแบบอัตโนมัติและตรวจสอบว่าอันตรายที่อาจเกิดขึ้นถูกจํากัด
ผลการประเมิน
ผลการประเมินด้านจริยธรรมและความปลอดภัยอยู่ในเกณฑ์ที่ยอมรับได้เพื่อปฏิบัติตามนโยบายภายในสำหรับหมวดหมู่ต่างๆ เช่น ความปลอดภัยของเด็ก ความปลอดภัยของเนื้อหา อันตรายจากการนำเสนอ การจดจำ อันตรายในวงกว้าง ดูรายละเอียดเพิ่มเติมได้ในการ์ดรูปแบบ Gemma
การใช้งานและข้อจํากัดของโมเดล
ข้อจำกัดที่ทราบ
โมเดลภาษาขนาดใหญ่ (LLM) มีข้อจำกัดตามข้อมูลการฝึกและข้อจำกัดโดยเนื้อแท้ของเทคโนโลยี ดูรายละเอียดเพิ่มเติมเกี่ยวกับข้อจํากัดของ LLM ได้ในการ์ดรูปแบบ Gemma
ข้อควรพิจารณาด้านจริยธรรมและความเสี่ยง
การพัฒนาโมเดลภาษาขนาดใหญ่ (LLM) ทำให้เกิดข้อกังวลด้านจริยธรรมหลายประการ เราได้พิจารณาหลายแง่มุมอย่างรอบคอบในการพัฒนารูปแบบเหล่านี้
โปรดดูรายละเอียดของโมเดลในการสนทนาเดียวกันในการ์ดโมเดล Gemma
วัตถุประสงค์การใช้งาน
แอปพลิเคชัน
โมเดล Code Gemma มีแอปพลิเคชันหลากหลายรูปแบบ ซึ่งแตกต่างกันไประหว่างโมเดล IT และ PT รายการการใช้งานที่เป็นไปได้ต่อไปนี้เป็นเพียงตัวอย่างบางส่วนเท่านั้น วัตถุประสงค์ของรายการนี้คือเพื่อให้ข้อมูลตามบริบทเกี่ยวกับกรณีการใช้งานที่เป็นไปได้ซึ่งครีเอเตอร์โมเดลได้พิจารณาไว้เป็นส่วนหนึ่งของการฝึกและพัฒนาโมเดล
- การเติมโค้ด: ใช้รูปแบบ PT เพื่อเติมโค้ดให้สมบูรณ์ด้วยส่วนขยาย IDE
- การสร้างโค้ด: โมเดลไอทีสามารถใช้สร้างโค้ดได้โดยมีหรือไม่มีส่วนขยาย IDE
- การสนทนาเกี่ยวกับโค้ด: โมเดลไอทีสามารถขับเคลื่อนอินเทอร์เฟซการสนทนาซึ่งพูดถึงโค้ด
- การศึกษาโค้ด: โมเดลไอทีรองรับประสบการณ์การเรียนรู้โค้ดแบบอินเทอร์แอกทีฟ ช่วยแก้ไขไวยากรณ์ หรือให้การฝึกเขียนโค้ด
ประโยชน์
ขณะเปิดตัว กลุ่มโมเดลนี้จะให้บริการโมเดลภาษาขนาดใหญ่ที่เน้นโค้ดแบบเปิดที่มีประสิทธิภาพสูง ซึ่งออกแบบมาตั้งแต่ต้นเพื่อการพัฒนา AI อย่างมีความรับผิดชอบเมื่อเทียบกับโมเดลขนาดใกล้เคียงกัน
เมื่อใช้เมตริกการประเมินการเปรียบเทียบการเขียนโค้ดที่อธิบายไว้ในเอกสารนี้ โมเดลเหล่านี้มีประสิทธิภาพดีกว่าโมเดลเปิดทางเลือกอื่นๆ ขนาดใกล้เคียงกัน