
Offene Gemma-Modelle
Eine Familie leichter, hochmoderner offener Modelle, die auf derselben Forschung und Technologie basieren wie die Gemini-Modelle
Von Grund auf verantwortungsvoll
Durch umfassende Sicherheitsmaßnahmen tragen diese Modelle dazu bei, durch ausgewählte Datensätze und eine strenge Optimierung verantwortungsbewusste und vertrauenswürdige KI-Lösungen zu gewährleisten.
Unerreichte Leistung bei Größe
Gemma-Modelle erzielen bei den Größen 2B, 7B, 9B und 27B hervorragende Benchmark-Ergebnisse und übertreffen sogar einige größere offene Modelle.
Flexible Bereitstellung
Mit Keras, JAX, MediaPipe, PyTorch, Hugging Face und anderen Tools nahtlos auf Mobilgeräten, im Web und in der Cloud bereitstellen
Gemma 2 testen
Gemma 2 wurde für eine überragende Leistung und unübertroffene Effizienz neu entwickelt und optimiert für blitzschnelle Inferenzen auf verschiedener Hardware.
5-Shot
MMLU
Der MMLU-Benchmark ist ein Test, mit dem das Wissen und die Problemlösungsfähigkeiten gemessen werden, die Large Language Models während des Vortrainings erwerben.
25 Aufnahme
ARC-C
Der ARC-c-Benchmark ist eine fokussiertere Teilmenge des ARC-e-Datasets, die nur Fragen enthält, die von gängigen Algorithmen (Retrieval-basierte und Wortkooccurrence) falsch beantwortet wurden.
5-Shot
GSM8K
Mit dem GSM8K-Benchmark wird die Fähigkeit eines Sprachmodells getestet, Mathematikaufgaben auf der Grundschulebene zu lösen, die häufig mehrere Schritte der Argumentation erfordern.
3-5-Shot
AGIEval
Der AGIEval-Benchmark testet die allgemeine Intelligenz eines Sprachmodells anhand von Fragen, die aus realen Prüfungen stammen, die die intellektuellen Fähigkeiten von Menschen bewerten sollen.
3-Shot, CoT
BBH
Der BBH-Benchmark (BIG-Bench Hard) konzentriert sich auf Aufgaben, die über die Fähigkeiten der aktuellen Sprachmodelle hinausgehen, und testet ihre Grenzen in verschiedenen Bereichen der Argumentation und des Verständnisses.
3-Shot, F1
DROP
DROP ist ein Leseverständnis-Benchmark, der diskretes Denken über Absätze hinweg erfordert.
5-Shot
Winogrande
Mit dem Winogrande-Benchmark wird die Fähigkeit eines Sprachmodells getestet, mehrdeutige Lückenfüllungsaufgaben mit binären Optionen zu lösen, die allgemeines gesundes Menschenverstand erfordern.
10-Shot
HellaSwag
Der HellaSwag-Benchmark stellt die Fähigkeit eines Sprachmodells auf die Probe, gesunden Menschenverstand zu verstehen und anzuwenden, indem es das logischste Ende einer Geschichte auswählt.
4-Shot
MATH
MATH prüft die Fähigkeit eines Sprachmodells, komplexe mathematische Textaufgaben zu lösen, die Schlussfolgerungen, mehrstufige Problemlösungen und das Verständnis mathematischer Konzepte erfordern.
0-Shot
ARC-e
Der ARC-e-Benchmark testet die Fähigkeiten eines Sprachmodells bei der Beantwortung fortgeschrittener Fragen mit echten Multiple-Choice-Fragen aus der Grundschule.
0-Shot
PIQA
Der PIQA-Benchmark testet die Fähigkeit eines Language Models, physikalisches Allgemeinwissen zu verstehen und anzuwenden, indem es Fragen zu alltäglichen physischen Interaktionen beantwortet.
0-Shot
SIQA
Der SIQA-Benchmark bewertet das Verständnis eines Sprachmodells für soziale Interaktionen und sozialen gesunden Menschenverstand, indem Fragen zu den Handlungen von Menschen und ihren sozialen Auswirkungen gestellt werden.
0-Shot
Boolq
Mit dem BoolQ-Benchmark wird die Fähigkeit eines Sprachmodells getestet, natürlich vorkommende Ja/Nein-Fragen zu beantworten. So wird die Fähigkeit des Modells getestet, in der Praxis Aufgaben zur natürlichen Sprachinference auszuführen.
5-Shot
TriviaQA
Der TriviaQA-Benchmark testet das Leseverständnis mit Dreiergruppen aus Frage, Antwort und Beleg.
5-Shot
NQ
Mit dem NQ-Benchmark (Natural Questions) wird die Fähigkeit eines Sprachmodells getestet, Antworten in vollständigen Wikipedia-Artikeln zu finden und zu verstehen. Dabei werden realistische Szenarien für die Beantwortung von Fragen simuliert.
pass@1
HumanEval
Der HumanEval-Benchmark testet die Codegenerierungsfähigkeiten eines Sprachmodells, indem er bewertet, ob seine Lösungen funktionale Unit-Tests für Programmierprobleme bestehen.
3-shot
MBPP
Mit dem MBPP-Benchmark wird die Fähigkeit eines Sprachmodells getestet, grundlegende Python-Programmierprobleme zu lösen. Dabei liegt der Schwerpunkt auf grundlegenden Programmierkonzepten und der Verwendung der Standardbibliothek.
100 %
75 %
50 %
25 %
0 %
100 %
75 %
50 %
25 %
0 %
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
LLAMA 3
8 Mrd.
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
LLAMA 3
8 Mrd.
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
LLAMA 3
8 Mrd.
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
LLAMA 3
8 Mrd.
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
LLAMA 3
8 Mrd.
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
LLAMA 3
8 Mrd.
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
LLAMA 3
8 Mrd.
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
LLAMA 3
8 Mrd.
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
Gemma 1
2,5 Mrd.
Gemma 2
2,6 Mrd.
Mistral
7B
Gemma 1
7B
Gemma 2
9 Mrd.
Gemma 2
27B
*Dies sind die Benchmarks für die vorab trainierten Modelle. Details zur Leistung mit anderen Methoden finden Sie im technischen Bericht.
Forschungsmodelle
Die erweiterte Gemma-Modellfamilie
PaliGemma 2 Neu
Gemma-Umfang

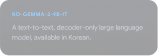

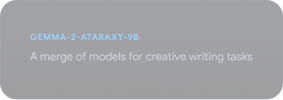
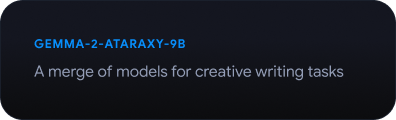

Gemmaverse
Ein umfangreiches Ökosystem aus von der Community erstellten Gemma-Modellen und ‑Tools, die Sie bei der Entwicklung innovativer Lösungen unterstützen
Build
Jetzt mit Gemma loslegen




Modelle bereitstellen
Bereitstellungsziel auswählen
![]() Mobilgeräte
Mobilgeräte
On-Device-Bereitstellung mit Google AI Edge
Direkt auf Geräten bereitstellen, um eine geringe Latenz und Offlinefunktionen zu ermöglichen. Ideal für Anwendungen, die Echtzeitreaktionsfähigkeit und Datenschutz erfordern, z. B. mobile Apps, IoT-Geräte und eingebettete Systeme.
![]() Web
Web
Nahtlose Integration in Webanwendungen
Nutzen Sie erweiterte KI-Funktionen für Ihre Websites und Webdienste, um interaktive Funktionen, personalisierte Inhalte und intelligente Automatisierung zu ermöglichen.
![]() Cloud
Cloud
Mühelos mit Cloud-Infrastruktur skalieren
Nutzen Sie die Skalierbarkeit und Flexibilität der Cloud, um große Bereitstellungen, anspruchsvolle Arbeitslasten und komplexe KI-Anwendungen zu bewältigen.