
Gemma Open Models
Rodzina lekkich, najnowocześniejszych otwartych modeli opartych na tych samych badaniach i technologiach, które posłużyły do stworzenia modeli Gemini.
Odpowiedzialna konstrukcja
Dzięki kompleksowym środkom bezpieczeństwa modele te pomagają zapewnić odpowiedzialne i godne zaufania rozwiązania AI dzięki starannie dobranym zbiorom danych i rygorystycznej regulacji.
Niezrównana wydajność
Modele Gemma osiągają wyjątkowe wyniki w przypadku rozmiarów 2B, 7B, 9B i 27B, a nawet przewyższają wyniki niektórych większych otwartych modeli.
Elastyczne wdrażanie
Bezproblemowo wdrażaj modele na urządzenia mobilne, w internecie i w chmurze, korzystając z Keras, JAX, MediaPipe, PyTorch, Hugging Face i innych narzędzi.
Wypróbuj Gemma 2
Gemma 2 została zaprojektowana z myślą o wyjątkowej wydajności i niespotykanej efektywności. Optymalizuje szybkie wnioskowanie na różnych rodzajach sprzętu.
5-shot
MMLU
Test MMLU to test, który mierzy zakres wiedzy i zdolności do rozwiązywania problemów nabytych przez duże modele językowe podczas wstępnego treningu.
25-shot
ARC-C
Punkt odniesienia ARC-c to bardziej skoncentrowany podzbiór zbioru danych ARC-e, zawierający tylko pytania, na które prawidłowe odpowiedzi podają zwykłe algorytmy (oparte na wyszukiwaniu i współwystępowaniu słów).
5-shot
GSM8K
Test porównawczy GSM8K sprawdza zdolność modelu językowego do rozwiązywania zadań matematycznych na poziomie szkoły podstawowej, które często wymagają kilkuetapowego rozumowania.
3–5 strzałów
AGIEval
Benchmark AGIEval sprawdza ogólną inteligencję modelu językowego za pomocą pytań pochodzących z egzaminów rzeczywistych, które mają na celu ocenę ludzkich zdolności intelektualnych.
3-shot, CoT
BBH
Benchmark BBH (BIG-Bench Hard) koncentruje się na zadaniach, które wykraczają poza możliwości obecnych modeli językowych, testując ich możliwości w różnych domenach rozumowania i rozumienia.
3-shot, F1
UPUŚĆ
DROP to test czytania ze zrozumieniem, który wymaga logicznego myślenia na podstawie akapitów.
5-shot
Winogrande
W ramach testu porównawczego Winogrande sprawdza się zdolność modelu językowego do rozwiązywania niejednoznacznych zadań typu „uzupełnij luki” za pomocą opcji binarnych, co wymaga ogólnego rozumowania zdroworozsądkowego.
10 ujęć
HellaSwag
Wyzwanie HellaSwag sprawdza umiejętność modelu językowego do zrozumienia i zastosowania zdrowego rozsądku, wybierając najbardziej logiczne zakończenie historii.
4-shot
MATH
MATH ocenia zdolność modelu językowego do rozwiązywania złożonych zadań tekstowych z matematyki, które wymagają rozumowania, wieloetapowego rozwiązywania problemów i rozumienia pojęć matematycznych.
0-shot
ARC-e
Testowanie ARC-e sprawdza zaawansowane umiejętności modela językowego w rozwiązywaniu pytań za pomocą autentycznych pytań jednokrotnego wyboru z zakresu nauki o świecie.
0-shot
PIQA
W ramach testu PIQA sprawdzamy, czy model językowy potrafi zrozumieć i zastosować wiedzę o rzeczywistości fizycznej, odpowiadając na pytania dotyczące codziennych interakcji fizycznych.
0-shot
SIQA
W ramach testu SIQA ocenia się, jak dobrze model językowy rozumie interakcje społeczne i zmysł społeczny, zadając pytania o działania ludzi i ich konsekwencje społeczne.
0-shot
Boolq
Test porównawczy BoolQ sprawdza zdolność modelu językowego do udzielania odpowiedzi na pytania typu tak/nie, testując jego zdolność do wykonywania zadań związanych z rozpoznawaniem języka naturalnego w rzeczywistych warunkach.
5-shot
TriviaQA
Benchmark TriviaQA sprawdza umiejętności czytania ze zrozumieniem za pomocą trójek pytanie-odpowiedź-dowód.
5-shot
NQ
W ramach testu porównawczego NQ (Natural Questions) sprawdzana jest zdolność modelu językowego do znajdowania i rozumienia odpowiedzi w całych artykułach w Wikipedii, co symuluje rzeczywiste scenariusze udzielania odpowiedzi na pytania.
pass@1
HumanEval
Test porównawczy HumanEval sprawdza możliwości generacji kodu przez model językowy, oceniając, czy jego rozwiązania przechodzą testy jednostkowe funkcjonalności dotyczące problemów z programowaniem.
3-shot
MBPP
Test MBPP sprawdza, czy model językowy jest w stanie rozwiązywać podstawowe problemy związane z programowaniem w Pythonie, koncentrując się na podstawowych koncepcjach programowania i używaniu standardowych bibliotek.
100%
75%
50%
25%
0%
100%
75%
50%
25%
0%
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
LLAMA 3
8B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
Gemma 1
2,5 mln
Gemma 2
2,6 mln
Mistral
7B
Gemma 1
7B
Gemma 2
9 B
Gemma 2
27B
*To punkty odniesienia dla wstępnie wytrenowanych modeli. Szczegółowe informacje o wydajności w przypadku innych metod znajdziesz w raporcie technicznym.
Modele badań
Poznaj rozszerzoną rodzinę modeli Gemma
PaliGemma 2 Nowość
DataGemma
Zakres Gemma

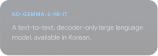

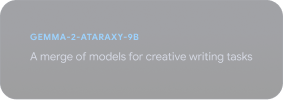
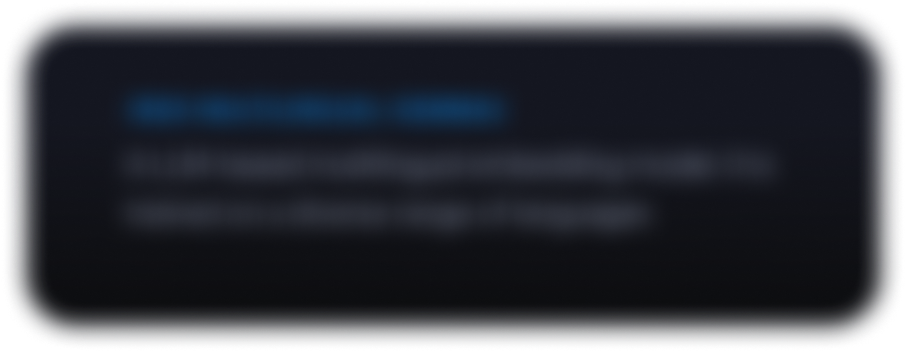
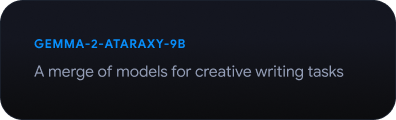

Poznaj Gemmaverse
Ogromny ekosystem modeli i narzędzi Gemma stworzonych przez społeczność, które ułatwiają innowacje i inspirują do ich tworzenia
Kompilacja
Zacznij tworzyć za pomocą Gemma




Wdrażanie modeli
Wybierz cel wdrożenia
![]() Urządzenia mobilne
Urządzenia mobilne
Wdrażanie na urządzeniu za pomocą Google AI Edge
Wdróż bezpośrednio na urządzeniach, aby korzystać z funkcji offline z minimalnym opóźnieniem. Idealne do zastosowań wymagających szybkiego działania i prywatności w czasie rzeczywistym, takich jak aplikacje mobilne, urządzenia IoT i systemy wbudowane.
![]() Internet
Internet
Bezproblemowa integracja z aplikacjami internetowymi
Udostępniaj zaawansowane funkcje AI, aby wzbogacać swoje strony internetowe i usługi internetowe o funkcje interaktywne, treści spersonalizowane i inteligentną automatyzację.
![]() Cloud
Cloud
Łatwe skalowanie dzięki infrastrukturze w chmurze
Korzystaj z skalowalności i elastyczności chmury, aby obsługiwać wdrożenia na dużą skalę, wymagające zbiory zadań i złożone aplikacje AI.


Otwieranie komunikacji globalnej
Weź udział w globalnym konkursie Kaggle. Utwórz warianty modelu Gemma dla konkretnego języka lub unikalnego aspektu kulturowego