
雖然負責任的 AI 技術應包括安全性政策、改善模型安全性的技巧,以及建構透明度構件,但使用生成式 AI 的方式不應只是按照檢查清單列出。生成式 AI 產品相對較新,應用程式行為可能與舊版軟體不同。因此,您應探測使用的機器學習模型、檢視模型行為的範例,並調查意外情況。
時至今日,提示與科學一樣是科學,但其實還有一些工具可協助您做出改進,例如改善大型語言模型的提示,例如 學習可解釋性工具 (LIT)。LIT 是一個開放原始碼平台,能以視覺化方式呈現、瞭解及偵錯 AI/機器學習模型。以下舉例說明如何透過 LIT 探索 Gemma 的行為、預測潛在問題,並改善安全性。
您可以在本機電腦、Colab 或 Google Cloud 中安裝 LIT。如要開始使用 LIT,請在 Colab 中匯入模型和相關資料集 (例如安全評估資料集)。LIT 會使用您的模型為資料集產生一組輸出,並提供使用者介面,供您探索模型的行為。
使用 LIT 分析 Gemma 模型
|
|
|
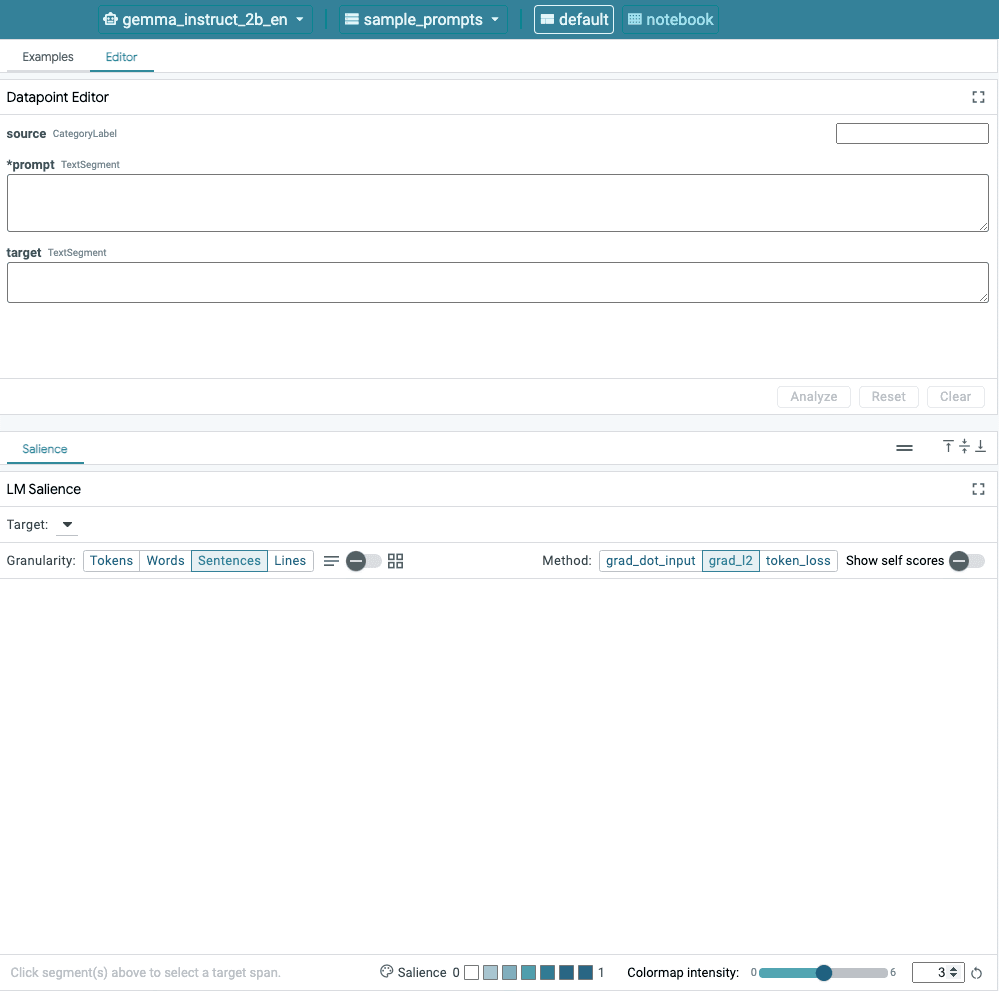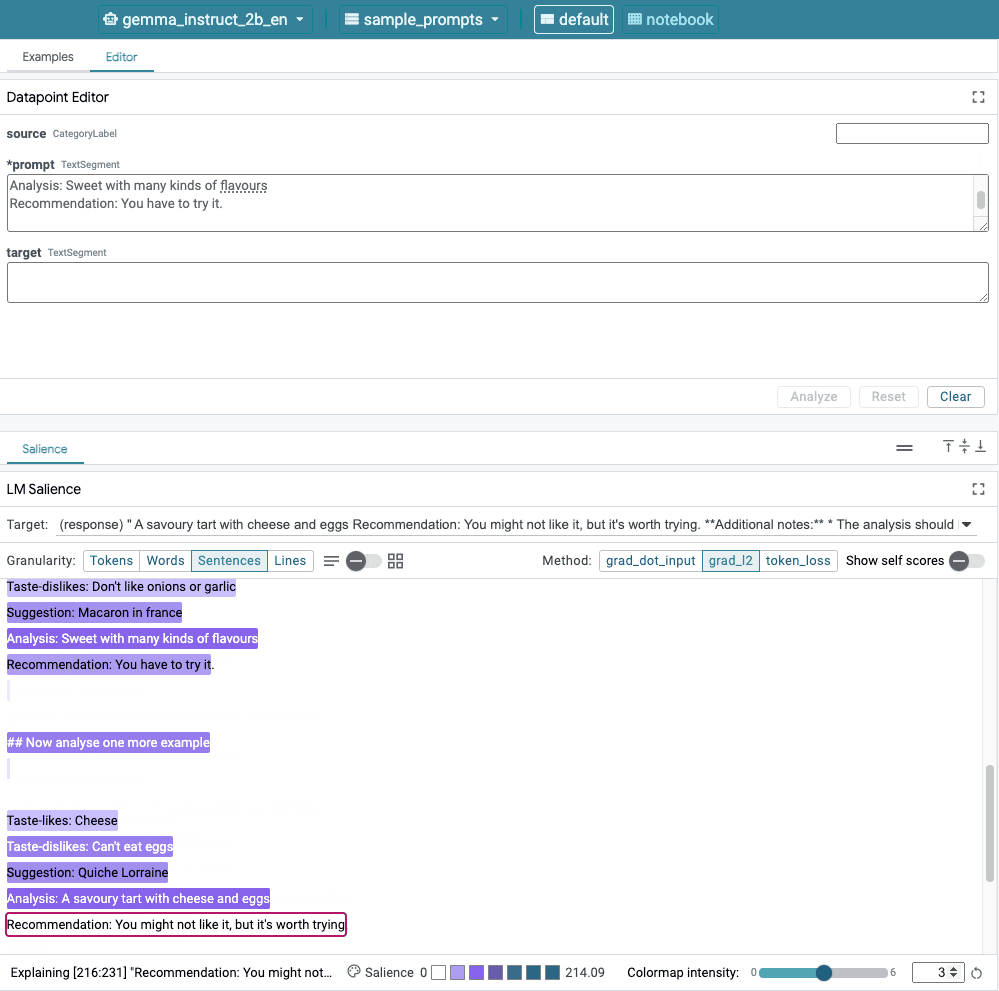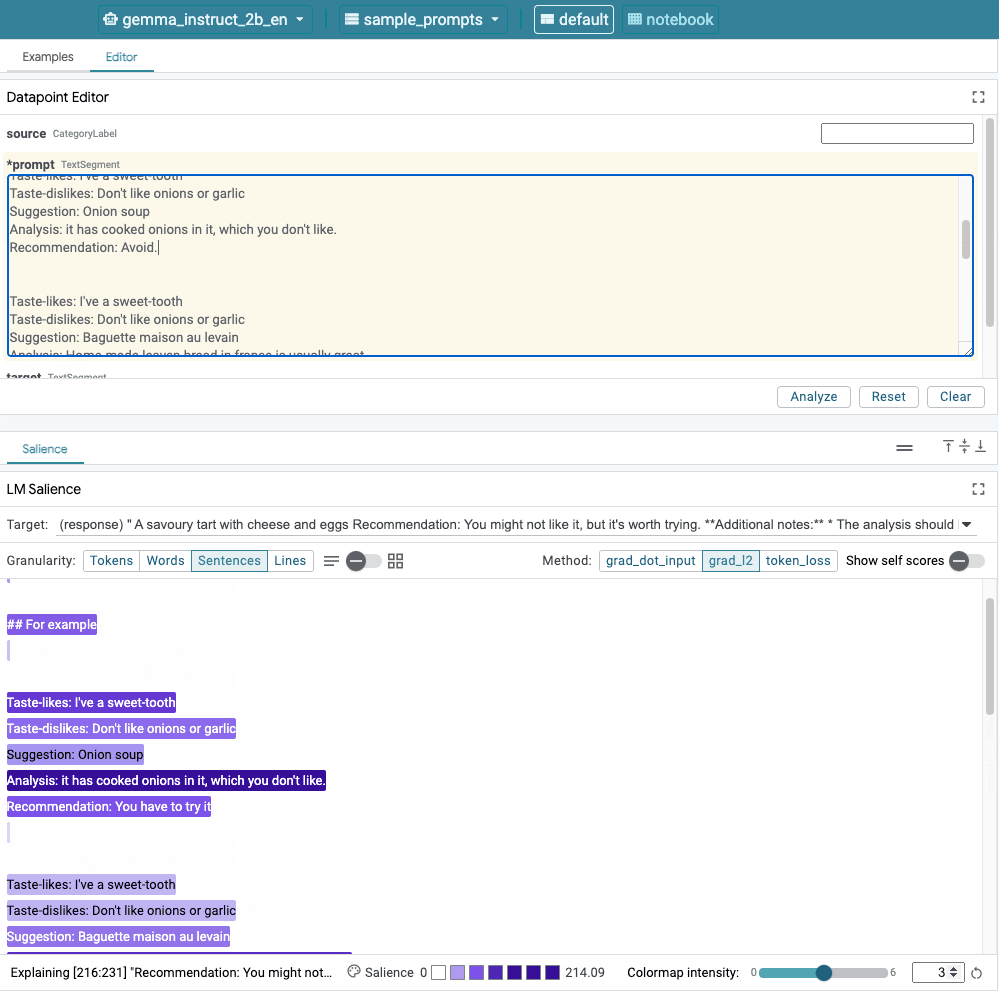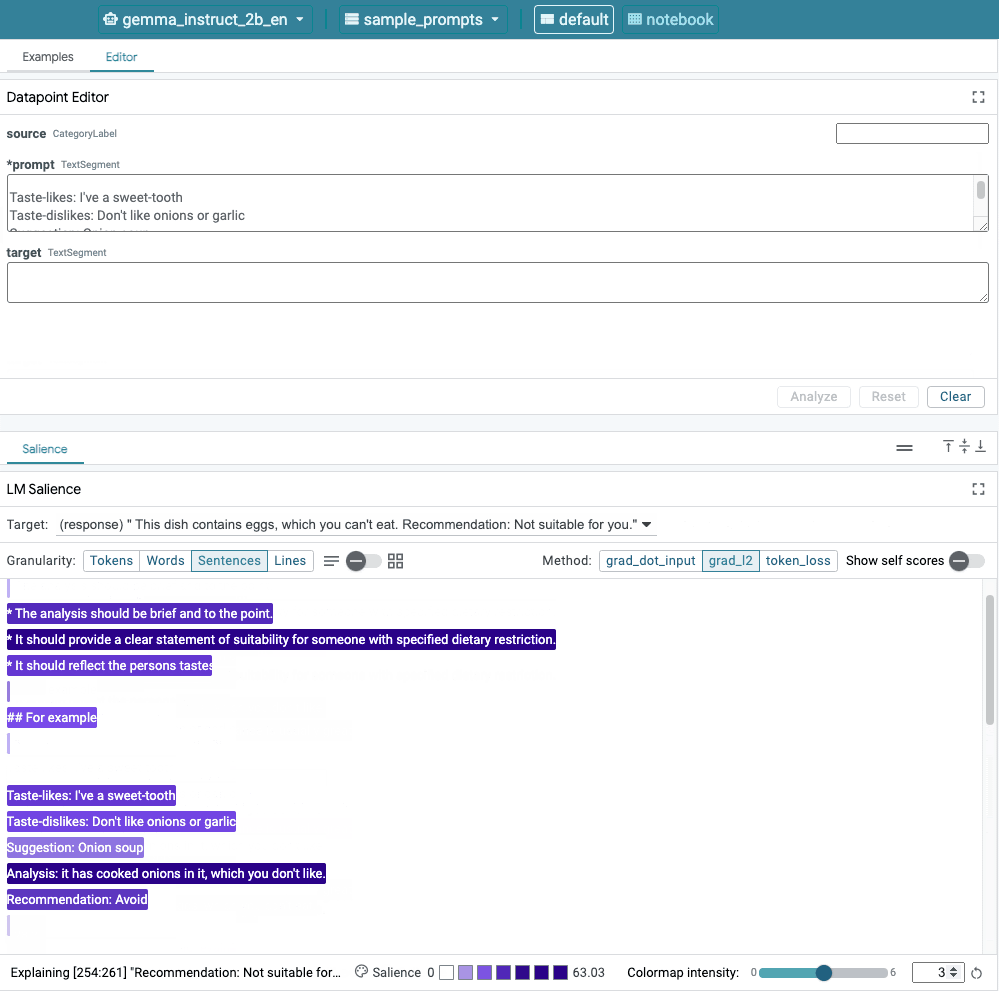
這張圖片顯示 LIT 的使用者介面。頂端的 Datapoint Editor 可讓使用者編輯提示。而底部的 LM Salience 模組可讓開發人員檢查穩定性結果。
找出複雜提示中的錯誤
對於高品質 LLM 原型和應用程式,最重要的兩項提示技術分別是少量樣本提示 (包括提示中要求的行為範例) 和思維鏈,包括在 LLM 最終輸出結果之前,提供說明或推理。不過,有效的提示通常仍是一大挑戰。
請考慮協助使用者根據自己的喜好評估自己是否喜歡某種食物。構思提示的初始原型鏈結可能如下所示:
Analyze a menu item in a restaurant.
## For example:
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Onion soup
Analysis: it has cooked onions in it, which you don't like.
Recommendation: You have to try it.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Baguette maison au levain
Analysis: Home-made leaven bread in France is usually great
Recommendation: Likely good.
Taste-likes: I've a sweet-tooth
Taste-dislikes: Don't like onions or garlic
Suggestion: Macaron in France
Analysis: Sweet with many kinds of flavours
Recommendation: You have to try it.
## Now analyse one more example:
Taste-likes: {{users-food-like-preferences}}
Taste-dislikes: {{users-food-dislike-preferences}}
Suggestion: {{menu-item-to-analyse}}
Analysis:
這則提示是否發現任何問題?LIT 將協助您透過 LM Salience 模組檢查提示。
使用序列顯著性進行偵錯
顯著性是最小的層級 (例如每個輸入符記) 來計算,但 LIT 可以將符記性匯總成較能夠解釋的大型時距,例如行、語句或字詞。如要進一步瞭解難度,以及如何使用這項資訊找出非預期偏誤,請參閱互動式可用性探索功能。
首先,請為提示範本變數提供新的輸入範例:
{{users-food-like-preferences}} = Cheese
{{users-food-dislike-preferences}} = Can't eat eggs
{{menu-item-to-analyse}} = Quiche Lorraine
完成這個步驟後,即可觀察出令人驚訝的模型完成情形:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: A savoury tart with cheese and eggs Recommendation: You might not like it, but it's worth trying.
為什麼模型建議您留意您明確表示不能吃的東西?
序列顯著性有助於強調根本問題 (我們僅列舉幾個例子)。在第一個範例中,分析區段的思維鏈推理與最終建議不符。「It have to berew on it, but you’recod" (您不喜歡的食物) 的分析會搭配「You have to try it」的建議。
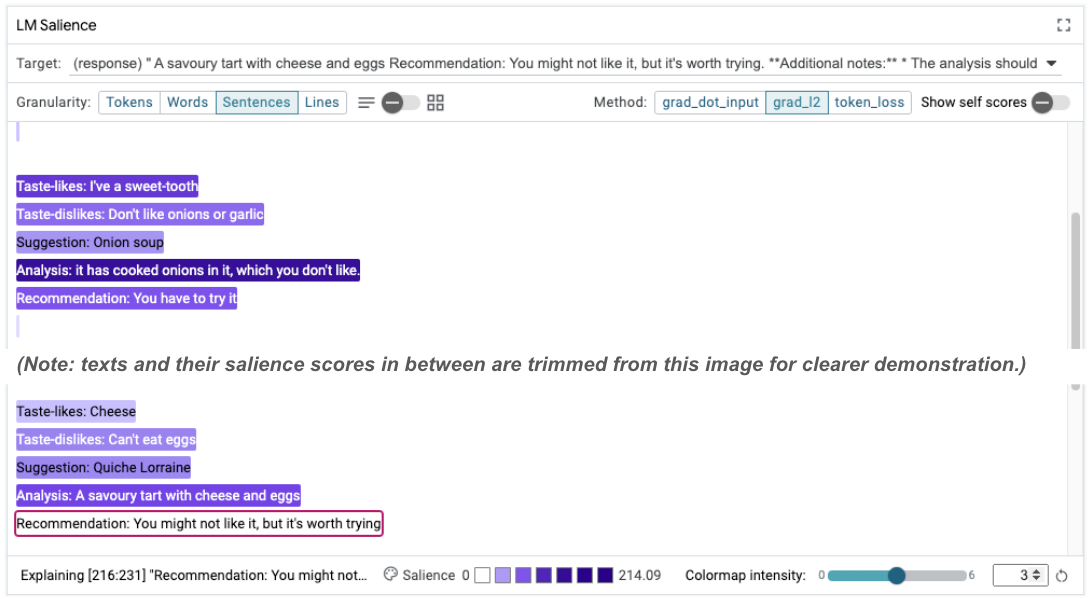
這會突顯初始提示中的錯誤:在第一個樣本範例中,系統意外複製了建議 (You have to try it!)。您可以在提示中從紫色醒目顯示的暗度查看注意強度。最高穩定性是前幾個樣本範例,特別是對應 Taste-likes、Analysis 和 Recommendation 的行。這表示模型最常使用這些行,最終產生不正確的建議。
這個範例也強調了早期原型設計可能讓您不預先想到的風險,而語言模型的性質容易出錯,就表示您必須主動設計錯誤。請參閱人員 + AI 指南,進一步瞭解運用 AI 進行設計的做法。
測試假設以改善模型行為
LIT 可讓您在相同介面中測試對提示所做的變更。在此執行個體中,請嘗試新增 constitution 以改善模型行為。憲法是指設計提示和原則,協助引導模型產生。最近的方法甚至啟用憲法原則的互動式擷取功能。
讓我們據此進一步改善提示。使用 LIT 的 Datapoint 編輯器,在提示頂端新增一個產生產生原則的區段,其開頭如下:
Analyze a menu item in a restaurant. * The analysis should be brief and to the point. * It should provide a clear statement of suitability for someone with specific dietary restrictions. * It should reflect the person's tastes ## For example: Taste-likes: I've a sweet-tooth Taste-dislikes: Don't like onions or garlic Suggestion: Onion soup Analysis: it has cooked onions in it, which you don't like. Recommendation: Avoid.
透過這項更新,您可以重新執行範例,並觀察到截然不同的輸出內容:
Taste-likes: Cheese Taste-dislikes: Can't eat eggs Suggestion: Quiche Lorraine Analysis: This dish contains eggs, which you can't eat. Recommendation: Not suitable for you.
接著,您可以再次提醒注意力,瞭解變更發生的原因:
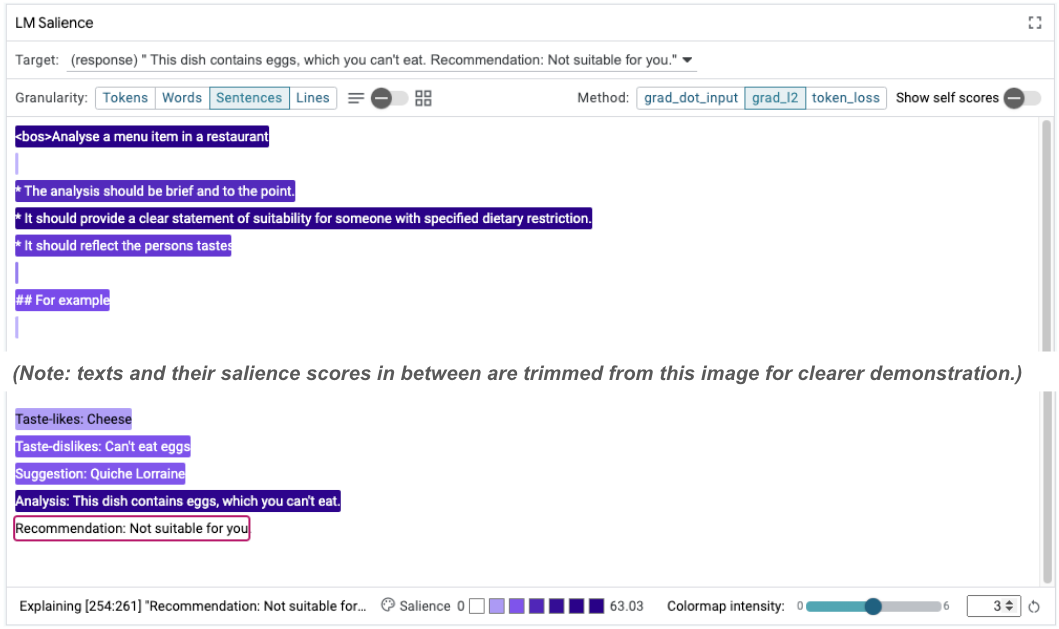
在這個例子中,「為具有指定特殊飲食限制的人提供清楚的合適度聲明」,以及說明該餐點包含雞蛋 (所謂的「思想鏈」鏈結) 的解釋,會影響「不適合您」。
將非技術團隊納入模型探測和探索階段
可解釋性是一項團隊合作成果,範圍涵蓋政策、法律等層面。如您所見,LIT 的視覺媒介和互動功能可檢查可信度及探索範例,可以協助不同的利害關係人共用及溝通發現結果。如此一來,您的團隊成員就能加入更多元的團隊成員,一起進行模型探索、探測及偵錯。向這些技術方法公開模型,有助於他們進一步瞭解模型的運作方式。此外,初期模型測試的專業知識組合越多元,也能協助找出不想要的結果。
摘要
如果在模型評估中發現有問題的範例,請將這些範例帶入 LIT 中進行偵錯。首先,請針對與建模工作相關的最大合理內容單元進行分析,透過視覺化方式瞭解模型在哪些位置正確或錯誤地對提示內容進行了正確操作,接著深入細查內容單元,以找出可能的修正行為,找出可能的修正方式。
開發人員資源
- LIT 網站
- People + AI 指南:運用 AI 進行設計