
افزودن GenAI به برنامه شما میتواند قدرت و ارزش فوقالعادهای را برای کاربران شما به ارمغان بیاورد، اما برای حفظ ایمنی و حفظ حریم خصوصی مورد انتظار کاربران نیز نیاز به یک نگاه دقیق دارد.
طراحی برای ایمنی
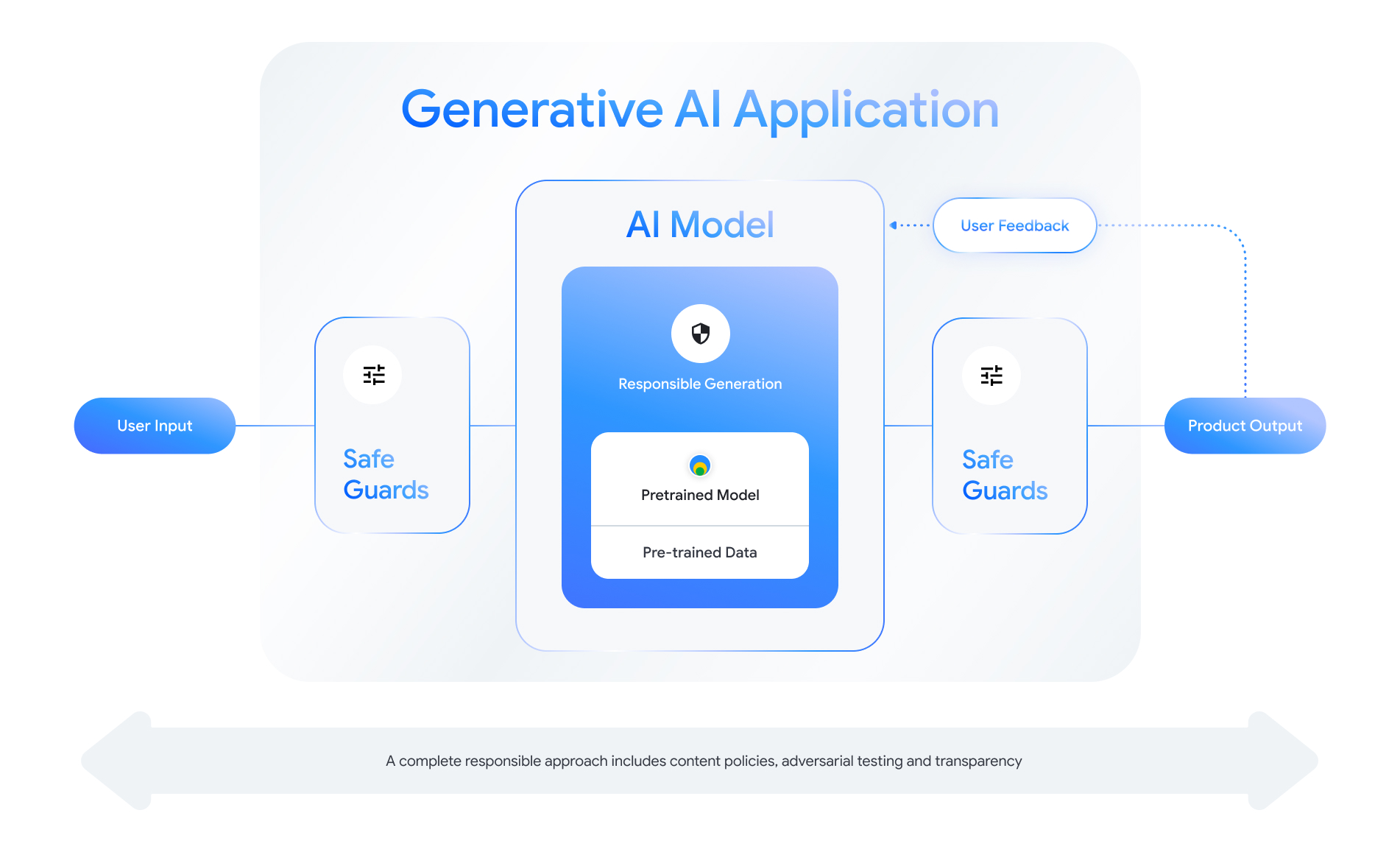
هر ویژگی GenAI-enable فرصت هایی را برای طراحی لایه های ایمنی ارائه می دهد. همانطور که در شکل زیر نشان داده شده است، یکی از راه هایی که می توانید در مورد ایمنی فکر کنید، قرار دادن مدل هوش مصنوعی است که این ویژگی را در مرکز قرار می دهد. این مدل باید:
- تراز برای انجام وظیفه محول شده خود؛
- حفاظت شده توسط پادمان برای اطمینان از اینکه ورودی ها و خروجی های خارج از محدوده رد می شوند. و
- برای ارزیابی نحوه پاسخگویی مدل و سیستم به تعاملات تأثیرگذار بر ایمنی، به صورت کلی ارزیابی شد .
جلسه «ایجاد محصولات هوش مصنوعی مسئول» از Google I/O 2024 را بررسی کنید تا درباره ملاحظات طراحی، تمرینهای فکری، و روشهای نمونهسازی که میتوانند به تسریع شیوههای توسعه مسئولانه شما کمک کنند، بیشتر بدانید.
علاوه بر این، میتوانید بهترین شیوهها را بیاموزید و نمونههایی برای موارد زیر ببینید:
- تعیین خط مشی هایی که بر نحوه رفتار هوش مصنوعی در برنامه شما حاکم است.
- ایجاد مصنوعات شفافیت برای انتقال رویکرد مسئولانه خود به کاربرانتان؛ و
- ایمن سازی برنامه خود در برابر استفاده مخرب
مهمتر از همه، به یاد داشته باشید که رویکرد صحیح به ایمنی و مسئولیت، رویکردی است که خود انعکاسی باشد و با چالش های فنی، فرهنگی و فرآیندی سازگار باشد. برای اطمینان از بهترین نتایج، خود و تیمتان را در بررسیهای انتقادی منظم رویکرد خود درگیر کنید.
سیاست های سطح سیستم را تعریف کنید
خطمشیهای ایمنی محتوا تعریف میکنند که چه نوع محتوای مضری در یک پلتفرم آنلاین مجاز نیست. ممکن است با خطمشیهای محتوای پلتفرمهایی مانند YouTube یا Google Play آشنا باشید. خطمشیهای محتوا برای برنامههای هوش مصنوعی مولد مشابه هستند: آنها تعریف میکنند که برنامه شما چه نوع محتوایی را تولید نمیکند و نحوه تنظیم مدلها و موارد حفاظتی مناسب را راهنمایی میکند.
خطمشیهای شما باید منعکس کننده موارد استفاده برنامه شما باشد. به عنوان مثال، یک محصول مولد هوش مصنوعی که برای ارائه ایدههایی برای فعالیتهای خانوادگی بر اساس پیشنهادات جامعه طراحی شده است، ممکن است خطمشی داشته باشد که تولید محتوای خشونتآمیز را ممنوع میکند، زیرا میتواند برای کاربران مضر باشد. برعکس، برنامهای که ایدههای داستان علمی تخیلی پیشنهاد شده توسط کاربران را خلاصه میکند ممکن است بخواهد اجازه تولید خشونت را بدهد، زیرا موضوع داستانهای بسیاری در این ژانر است.
خطمشیهای ایمنی شما باید تولید محتوای مضر برای کاربران یا غیرقانونی را ممنوع کند و باید مشخص کند که چه نوع محتوای تولید شده با آن نوار برای برنامه شما مطابقت دارد. همچنین ممکن است بخواهید استثناهایی را برای محتوای آموزشی، مستند، علمی یا هنری در نظر بگیرید که در غیر این صورت ممکن است مضر تلقی شوند.
تعریف خط مشی های روشن با سطح جزئیات بسیار دقیق، از جمله استثنائات خط مشی با مثال، برای ساختن یک محصول مسئولیت پذیر ضروری است. خط مشی های شما در هر مرحله از توسعه مدل شما استفاده می شود. برای تمیز کردن یا برچسبگذاری دادهها، عدم دقت میتواند منجر به برچسبگذاری نادرست دادهها، حذف بیش از حد یا حذف کمتر داده شود که بر پاسخهای ایمنی مدل شما تأثیر میگذارد. برای اهداف ارزیابی، خطمشیهای نامشخص منجر به واریانس بین ارزیابها میشود و تشخیص اینکه آیا مدل شما با استانداردهای ایمنی شما مطابقت دارد یا نه.
خط مشی های فرضی (فقط برای مثال)
در زیر نمونههایی از خطمشیهایی است که میتوانید برای برنامهتان استفاده کنید، مشروط بر اینکه با مورد استفاده شما مطابقت داشته باشند.
| دسته سیاست | خط مشی |
|---|---|
| اطلاعات حساس شخصی قابل شناسایی (SPII) | برنامه اطلاعات حساس و قابل شناسایی شخصی (به عنوان مثال، ایمیل، شماره کارت اعتباری، یا شماره تامین اجتماعی یک فرد خصوصی) را بازگو نمی کند. |
| سخنان تنفرآمیز | این برنامه محتوای منفی یا مضری را تولید نمی کند که هویت و/یا ویژگی های محافظت شده را هدف قرار دهد (به عنوان مثال، توهین های نژادی، ترویج تبعیض، دعوت به خشونت علیه گروه های محافظت شده). |
| آزار و اذیت | این برنامه محتوای مخرب، ارعابکننده، قلدری یا توهینآمیز با هدف قرار دادن فرد دیگری تولید نمیکند (مثلاً تهدیدات فیزیکی، انکار رویدادهای غمانگیز، تحقیر قربانیان خشونت). |
| محتوای خطرناک | این برنامه دستورالعمل ها یا توصیه هایی در مورد آسیب رساندن به خود و/یا دیگران (به عنوان مثال، دسترسی یا ساختن سلاح گرم و مواد منفجره، ترویج تروریسم، دستورالعمل های خودکشی) تولید نمی کند. |
| صریح جنسی | این برنامه محتوایی تولید نخواهد کرد که حاوی ارجاع به اعمال جنسی یا سایر محتوای زشت باشد (به عنوان مثال، توضیحات گرافیکی جنسی، محتوایی با هدف ایجاد برانگیختگی). |
| فعال کردن دسترسی به کالاها و خدمات مضر | این برنامه محتوایی تولید نمیکند که کالاها، خدمات و فعالیتهای بالقوه مضر را تبلیغ یا امکان دسترسی به آنها را فراهم کند (به عنوان مثال، تسهیل دسترسی به تبلیغ قمار، مواد دارویی، آتش بازی، خدمات جنسی). |
| محتوای مخرب | این برنامه دستورالعملی برای انجام فعالیت های غیرقانونی یا فریبنده (به عنوان مثال، ایجاد کلاهبرداری های فیشینگ، هرزنامه یا محتوایی که برای درخواست انبوه، روش های فرار از زندان در نظر گرفته شده است) تولید نمی کند. |
مصنوعات شفافیت
مستندسازی روشی کلیدی برای دستیابی به شفافیت برای توسعهدهندگان، دولتها، سیاستگذاران و کاربران نهایی محصول شما است. این امر میتواند مستلزم انتشار گزارشهای فنی دقیق یا کارتهای مدل، دادهها و سیستم باشد که بهطور مناسب اطلاعات ضروری را بر اساس ارزیابیهای ایمنی و سایر مدلها عمومی میسازد. مصنوعات شفافیت بیشتر از وسایل ارتباطی هستند. آنها همچنین راهنمایی هایی را برای محققان هوش مصنوعی، توسعه دهندگان و توسعه دهندگان پایین دستی در مورد استفاده مسئولانه از مدل ارائه می دهند. این اطلاعات برای کاربران نهایی محصول شما نیز مفید است که میخواهند جزئیات مدل را بفهمند.
برخی از دستورالعمل های شفافیت که باید در نظر گرفته شود:
- هنگامی که کاربران با یک فناوری هوش مصنوعی مولد آزمایشی درگیر هستند، با کاربران واضح باشید و احتمال رفتار مدل غیرمنتظره را برجسته کنید.
- مستندات کاملی در مورد نحوه عملکرد سرویس یا محصول هوش مصنوعی مولد با استفاده از زبان قابل فهم ارائه دهید. انتشار مصنوعات شفافیت ساختاریافته مانند کارت های مدل را در نظر بگیرید. این کارت ها استفاده مورد نظر از مدل شما را ارائه می دهند و ارزیابی هایی را که در طول توسعه مدل انجام شده اند، خلاصه می کنند.
- به افراد نشان دهید که چگونه می توانند بازخورد ارائه دهند و چگونه کنترل می کنند، مانند:
- ارائه مکانیسم هایی برای کمک به کاربران برای اعتبارسنجی سوالات مبتنی بر واقعیت
- نمادهای شست بالا و پایین برای بازخورد کاربر
- پیوندهایی برای گزارش مشکلات و ارائه پشتیبانی برای پاسخ سریع به بازخورد کاربر
- کنترل کاربر برای ذخیره یا حذف فعالیت کاربر
سیستم های هوش مصنوعی ایمن
برنامههای کاربردی مجهز به GenAI سطوح حمله پیچیدهتری را ارائه میکنند که نسبت به برنامههای معمولی به کاهشهای متنوعتری نیاز دارند. چارچوب هوش مصنوعی ایمن گوگل (SAIF) یک چارچوب مفهومی کل نگر برای در نظر گرفتن نحوه طراحی برنامه کاربردی مجهز به GenAI برای استفاده ایمن ارائه می دهد. این چارچوب میتواند به شما کمک کند تا نحوه به کارگیری همترازی ، ارزیابی خصمانه و پادمانها را برای کمک به ایمن کردن برنامهتان ارزیابی کنید، هرچند به یاد داشته باشید که اینها تنها بلوکهای شروع هستند. احتمالاً برای دستیابی به اهداف امنیتی شما در مورد استفاده و زمینه خاص شما، تغییرات اضافی در شیوههای سازمان، نظارت و هشدار لازم است.
منابع توسعه دهنده
نمونه هایی از سیاست های هوش مصنوعی مولد:
- Cloud Gemini API و PalM API فهرستی از ویژگیهای ایمنی را ارائه میکنند که میتواند به عنوان مبنایی برای ایجاد سیاستهای ایمنی باشد.
- نمونهای از خطمشیهای گنجانده شده در بهروزرسانی پیشرفت اصول هوش مصنوعی Google در سال ۲۰۲۳ .
- انجمن MLCommons ، یک کنسرسیوم مهندسی که بر اساس فلسفه همکاری باز برای بهبود سیستمهای هوش مصنوعی ساخته شده است، به 6 خطر اشاره میکند که براساس آنها مدلهای ایمنی هوش مصنوعی را به عنوان بخشی از معیار ایمنی هوش مصنوعی ارزیابی میکنند.
هیچ الگوی واحدی برای مصنوعات شفافیت در سراسر صنعت وجود ندارد، اما کارتهای مدل موجود میتوانند به عنوان نقطه شروعی برای ایجاد الگوی خود عمل کنند: