
Soluzione Google Cloud di AI Edge per test e benchmarking del machine learning (ML) on-device su larga scala.
Ottimizzare il rendimento del modello ML su diversi dispositivi mobili può essere difficile. I test manuali sono lenti, costosi e spesso inaccessibili alla maggior parte degli sviluppatori, il che porta a incertezze nelle prestazioni del modello nel mondo reale. Google AI Edge Portal risolve questo problema consentendo il benchmarking del modello LiteRT su un'ampia gamma di dispositivi mobili, aiutando gli sviluppatori a trovare le configurazioni migliori per il deployment di modelli di ML su larga scala.
Ottimizzazione del deployment di ML mobile
Semplifica e accelera i cicli di test nel variegato panorama hardware: valuta facilmente le prestazioni del modello su centinaia di dispositivi mobili rappresentativi in pochi minuti.
Garantisci in modo proattivo la qualità del modello e identifica i problemi in anticipo: individua variazioni o regressioni delle prestazioni specifiche dell'hardware (ad esempio su chipset o dispositivi con memoria limitata) prima del deployment.
Costi di test dei dispositivi inferiori e accesso all'hardware più recente: esegui test su una flotta diversificata e in continua crescita di dispositivi fisici (attualmente oltre 100 modelli di dispositivi di vari OEM Android) senza le spese e la complessità della manutenzione del tuo laboratorio.
Prendi decisioni efficaci basate sui dati e ottieni informazioni strategiche di business: Google AI Edge Portal fornisce dati e confronti dettagliati sul rendimento, offrendo le informazioni strategiche di business fondamentali per guidare con sicurezza l'ottimizzazione del modello e convalidare la preparazione al deployment.
Benchmark di esempio:
In che modo Google AI Edge Portal ti aiuta a confrontare i modelli LiteRT
Seleziona dispositivi: seleziona i dispositivi di destinazione dal nostro ampio pool utilizzando filtri hardware specifici, tra cui supporto NPU, livello del dispositivo, brand, chipset e RAM. In alternativa, utilizza le nostre scorciatoie curate per accedere immediatamente agli elenchi di dispositivi più popolari.
Crea configurazioni: scegli tra acceleratori CPU, GPU o NPU per le attività di benchmarking.
Personalizzazione avanzata: regola le impostazioni specifiche dell'hardware per l'acceleratore selezionato o procedi con i valori predefiniti.
Supporto NPU: le funzionalità di accelerazione hardware ora includono le NPU, con una flotta di oltre 30 dispositivi Qualcomm.
- Compilazione Ahead-Of-Time (AOT): consigliata per prestazioni a livello di produzione, in quanto offre un'inizializzazione molto più rapida e un footprint di memoria inferiore. Questa modalità richiede la fornitura di modelli compilati per ogni SoC univoco nella selezione del dispositivo.
- Compilazione Just-In-Time (JIT): supporta un singolo modello per la compilazione su tutti i dispositivi selezionati.
Carica modelli: carica il file del modello utilizzando la UI o puntalo nel bucket Google Cloud Storage.
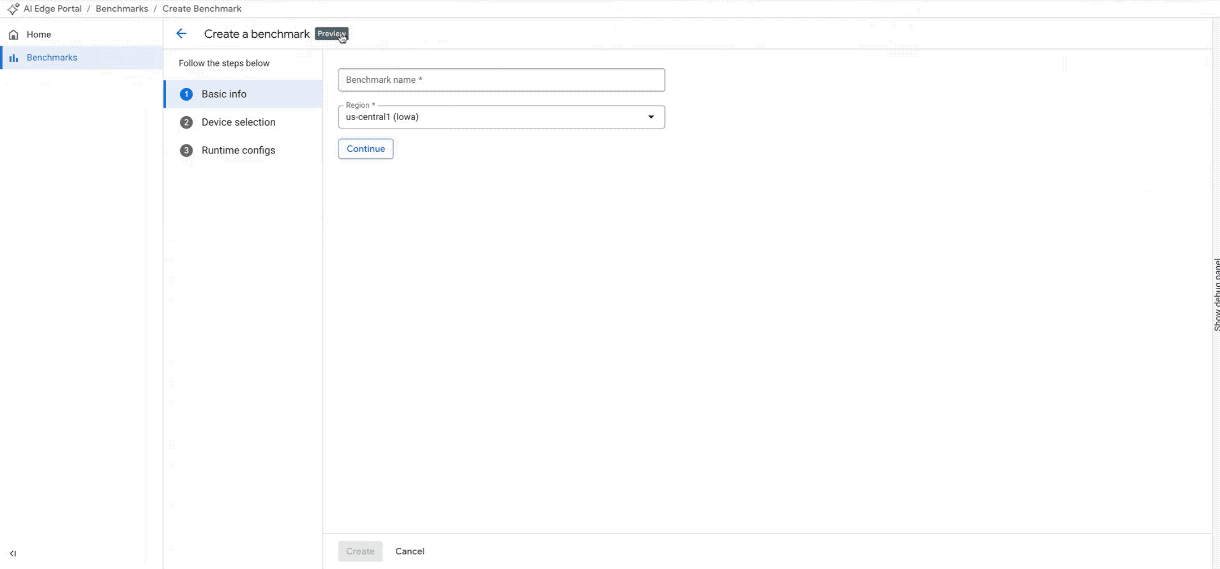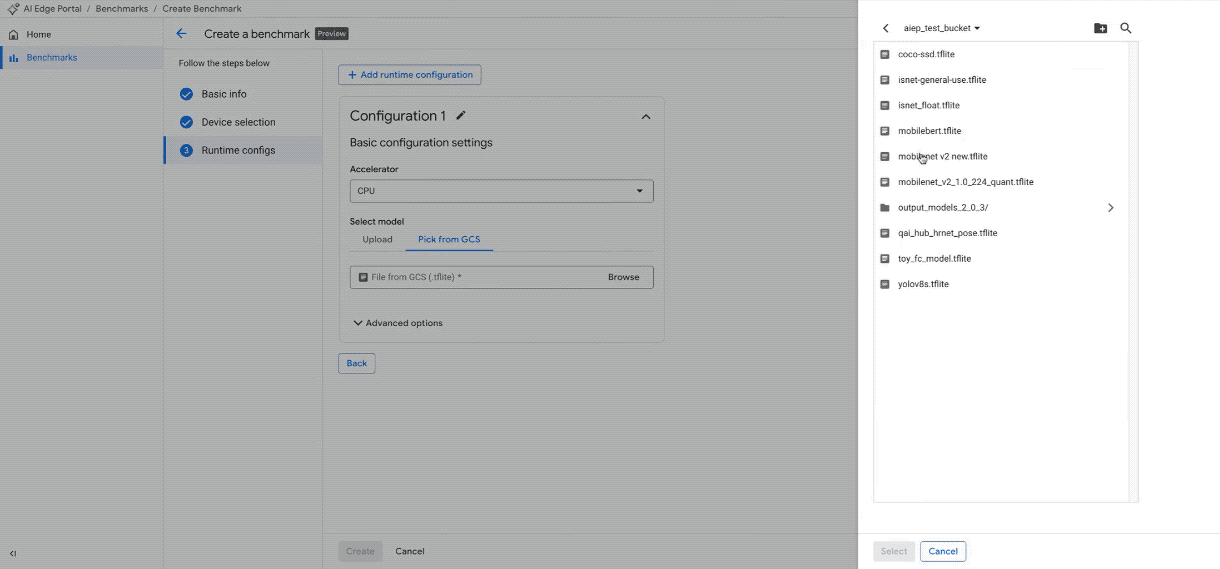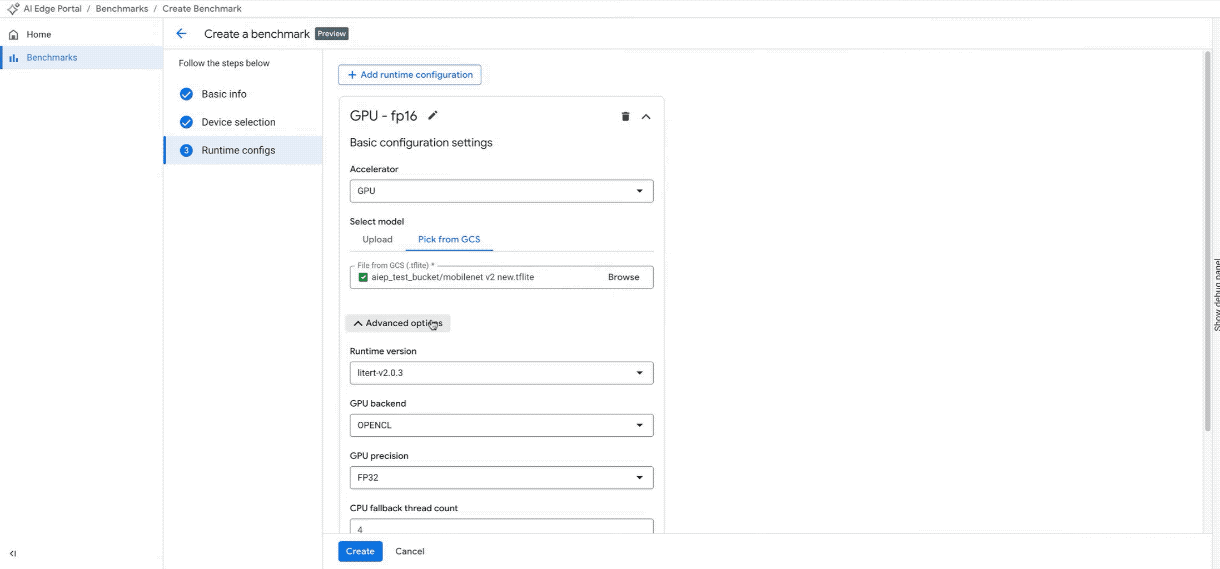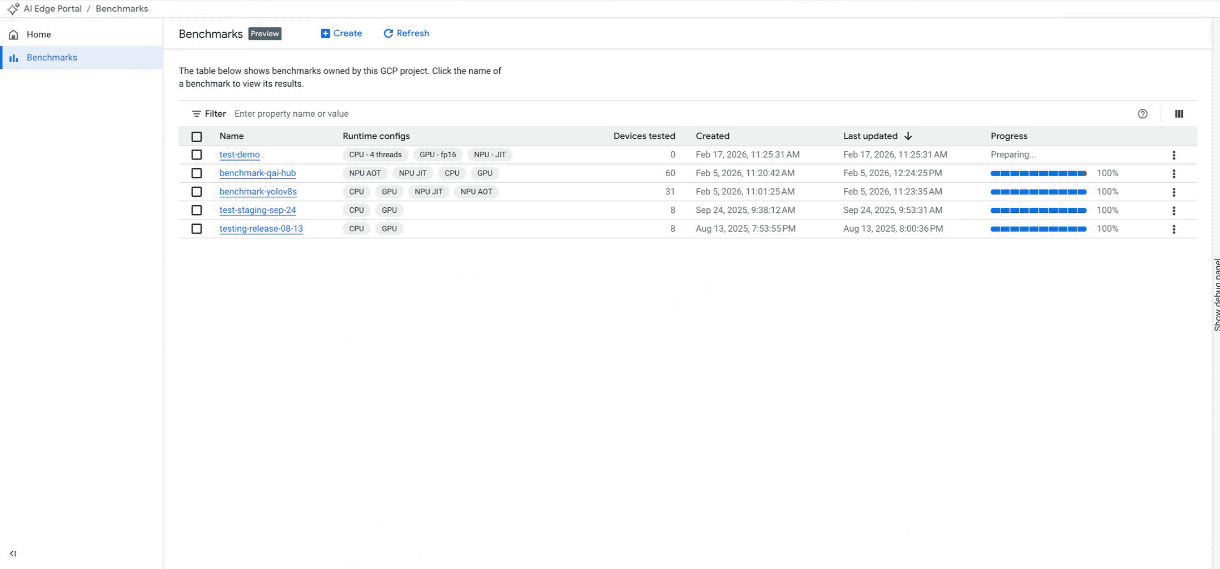
Crea un nuovo job di benchmark su più di 100 dispositivi. (Nota: la GIF è accelerata e modificata per brevità)
Da qui, invia il job e attendi il completamento. Quando è tutto pronto, esplora i risultati nella dashboard interattiva:
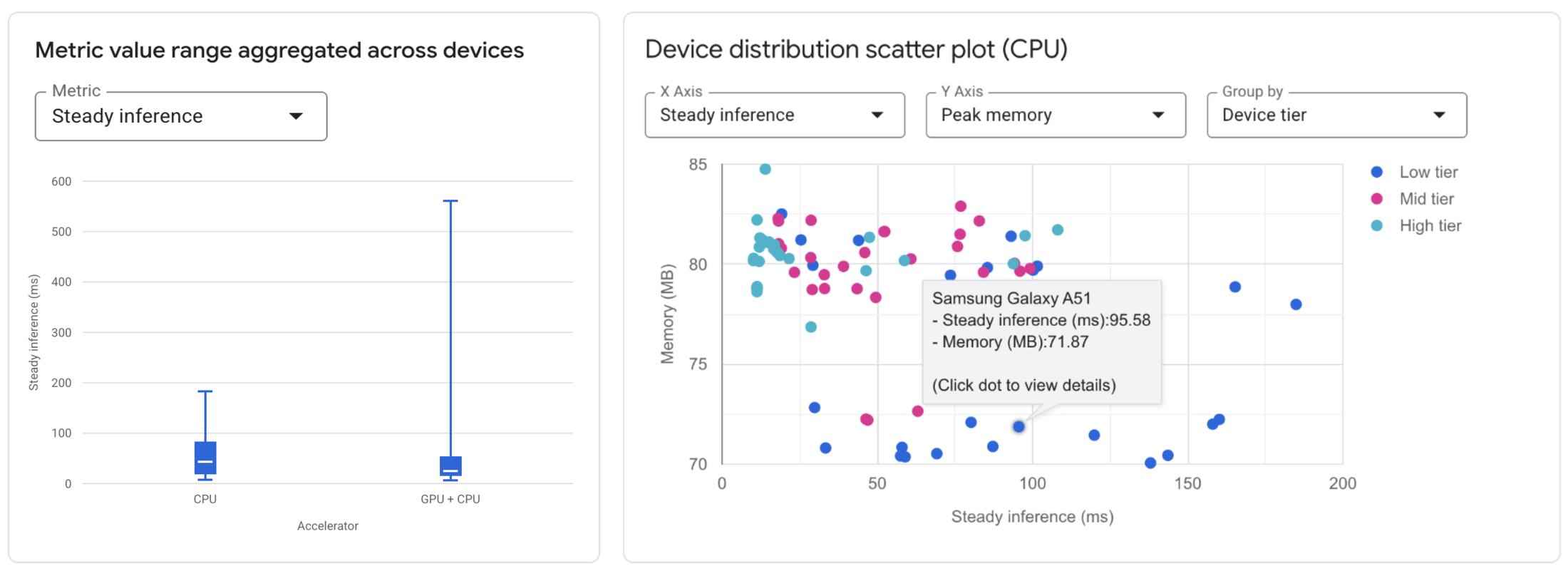
Confronta le configurazioni: visualizza rapidamente le differenze tra le metriche di rendimento (ad es. latenza media, memoria di picco) quando utilizzi acceleratori diversi su tutti i dispositivi testati.
Analizza l'impatto del dispositivo: scopri il rendimento di una configurazione di modello specifica nell'intervallo di dispositivi selezionati. Utilizza istogrammi e grafici a dispersione per identificare rapidamente le variazioni di rendimento correlate alle caratteristiche del dispositivo.
Metriche dettagliate: accedi a una tabella dettagliata e ordinabile che mostra metriche specifiche (tempo di inizializzazione, latenza di inferenza, utilizzo della memoria) per ogni singolo dispositivo, insieme alle relative specifiche hardware. Verifica l'utilizzo dell'hardware con la tabella Allocazione acceleratore, che mostra come le operazioni del modello sono distribuite tra i kernel (disponibile per CPU e GPU, con supporto NPU in arrivo a breve).
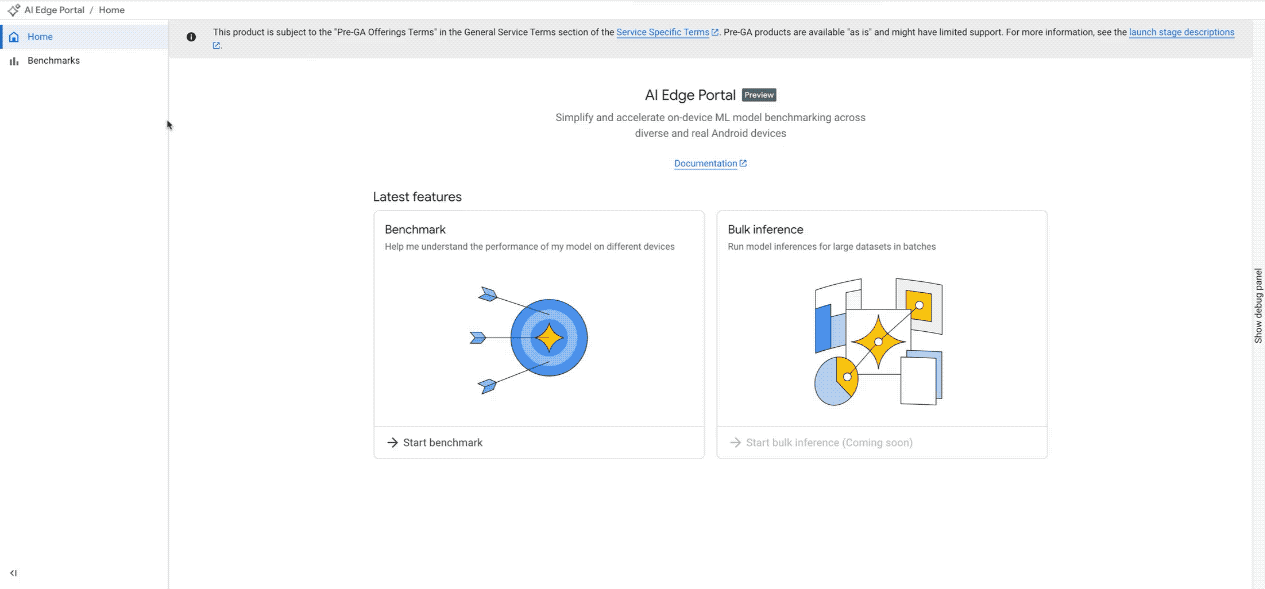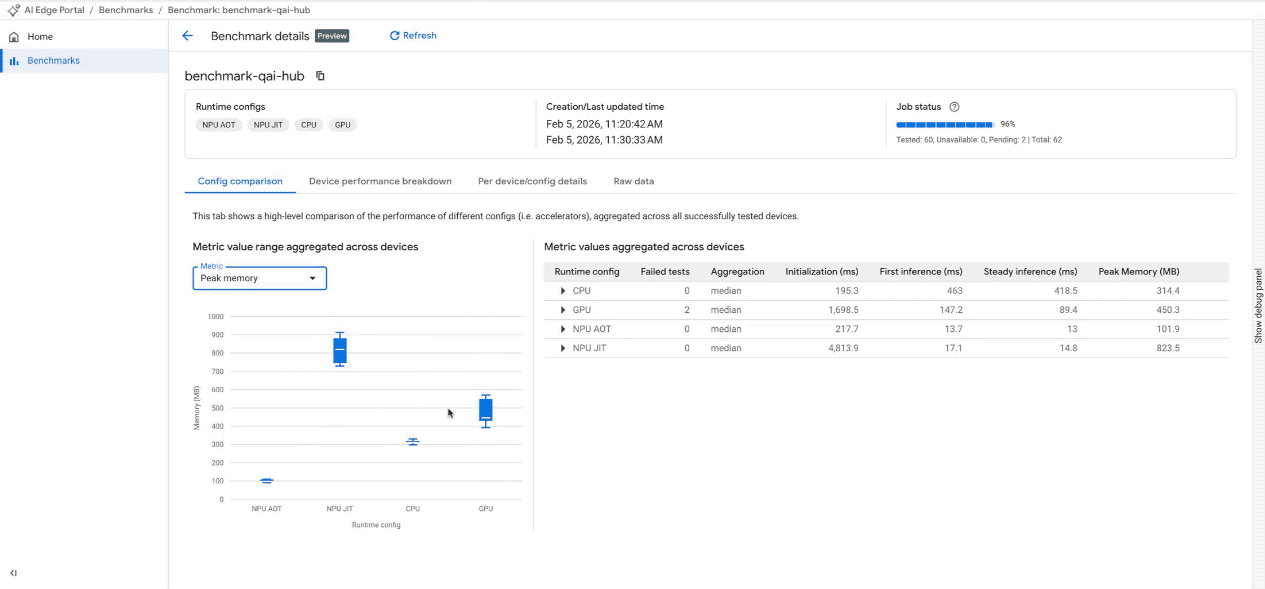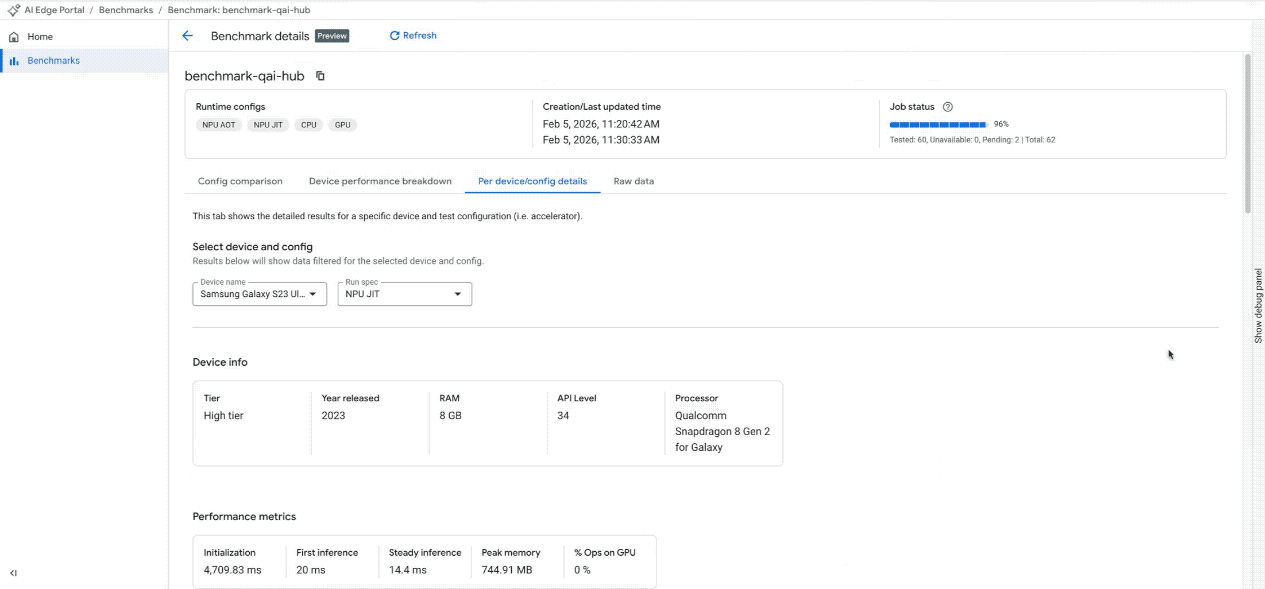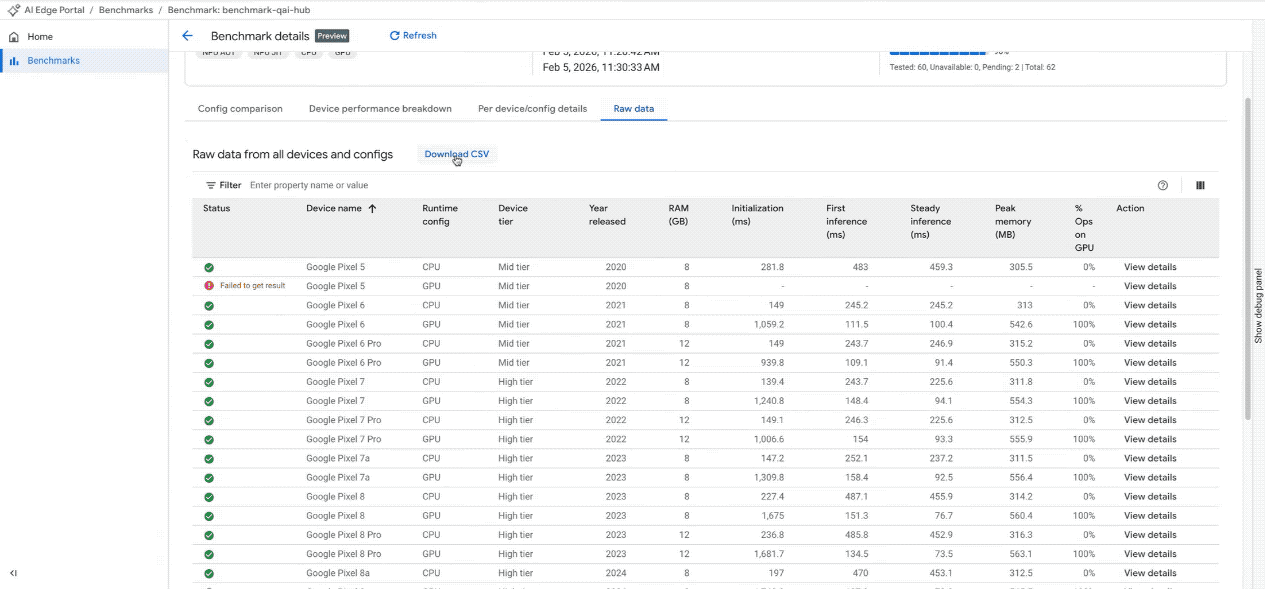
Visualizza i risultati del benchmark nella dashboard interattiva. (Nota: la GIF è accelerata e modificata per brevità)
Partecipare all'anteprima privata di Google AI Edge Portal
Google AI Edge Portal è disponibile in anteprima privata per i clienti Google Cloud inclusi nella lista consentita. Durante questo periodo di anteprima privata, l'accesso è fornito senza costi, in base ai termini dell'anteprima.
Questa anteprima è ideale per gli sviluppatori e i team che creano applicazioni ML mobile con LiteRT che hanno bisogno di dati di benchmarking affidabili su diversi hardware Android e sono disposti a fornire feedback per contribuire a plasmare il futuro del prodotto. Per richiedere l'accesso, compila il nostro modulo di registrazione qui per esprimere il tuo interesse. L'accesso viene concesso tramite l'inserimento nella lista consentita.